

B站员工猝死,审核员之殇,谁该反省?谁该惭愧?技术层面解构内容安全审核系统(python...
source link: https://v3u.cn/a_id_205
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

B站员工猝死,审核员之殇,谁该反省?谁该惭愧?技术层面解构内容安全审核系统(python3)
猝死,又见猝死,可怜无定河边骨,犹是春闺梦里人!每当有年轻的生命逝去,我们就会感到心中某种撕裂的感觉,惆怅万千,疼痛不已。审核专员,一个我们既熟悉又陌生的岗位,他们的疲惫,不仅仅体现在肉体上重复工作的折磨,而更多的,是精神上处于一种无知无觉的疲惫,想象一下,作为审核员,千帆阅尽之后,感动过你的一切不再感动你,吸引过你的一切不再吸引你,甚至激怒过你的一切都不再激怒你,麻木和怅惘充斥着你的工作和生活,只剩下疲于奔命,惨淡经营。而造成审核员审核过劳的因素之一,就是海量内容审核系统的设计问题。
谁也不能否认,对于UGC(User Generated Content,即用户产出内容)内容类产品来说,内容审核是必不可少的环节之一。因为UGC在产出大量优质内容的同时,也会产生诸如政治敏感、色情低俗、暴恐血腥等风险内容,所以,对于产出的数据,需要对应的审核员对其进行审批,而审核效率低下往往是因为审核系统的低效设计导致,而低效的诱因又往往是因为没有审核的“缓冲区”。
关于“缓冲区”的概念,我们可以举个实际生活中的例子,每天早上,大街上随处可见的早点摊:

是的,排队买早点,就算您不食人间烟火,也应该在全国大街小巷中见识过此类情景,油条虽然好吃,但是不能马上就能吃到,需要排队,这里油条是被早点摊老板生产出来的,而顾客则需要消费这些油条,但在消费过程中出现了问题,也就是在早点摊这一场景中,生产者生产油条的速度如果过慢,那么消费者会出现空闲闲置的情况,导致资源浪费;而如果生产者生产油条的速度过快,消费者消费油条的速度很慢,那么生产者就必须等待消费者消费完了油条才能够继续生产油条,这就是最朴素的生产者消费者问题。
而审核系统恰恰就契合生产者消费者模型,平台用户负责产生数据,这些数据由另一个模块来负责处理(此处的处理是广义的,可以是审核、发布等动作)。产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者。
单单抽象出生产者和消费者,还够不上是生产者消费者模型。该模式还需要有一个上文提到的“缓冲区”处于生产者和消费者之间,作为一个中介。生产者把数据放入缓冲区,而消费者从缓冲区取出数据。
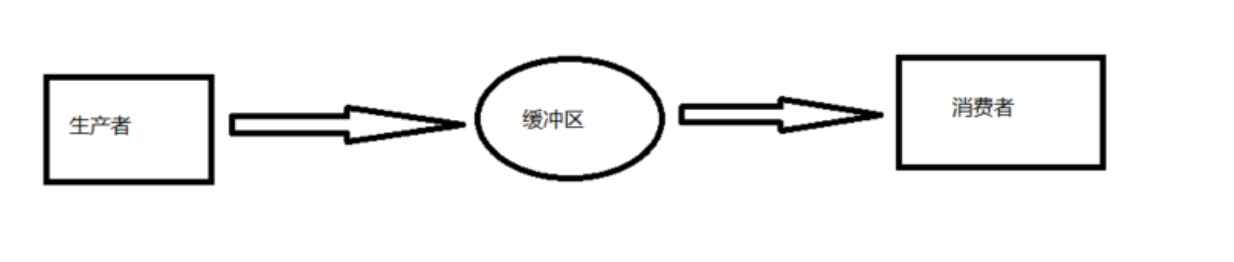
如此一来,缓冲区的出现可以帮我们解决下面的问题:
解耦:降低消费者和生产者之间的耦合度。有了缓冲区,生产者不必和消费者一一对应,用户产生的内容人不对审核员产生任何依赖,如果某一天审核员换人了,对于需要内容审核的用户也没有影响。假设生产者和消费者分别是两个对象。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。将来如果消费者的逻辑发生变化,可能会真接影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合度也就相应降低了。
并发:生产者消费者数量不对等,依然能够保持正常良好的通信。由于方法调用是同步的(或者叫阻塞的),在消费者的方法没有返回之前,生产者只好一直等在那边。万一消费者处理数据很慢,生产者只能等着浪费时间。使用了生产者消费者模式之后,生产者和消费者可以是两个独立的并发主体。生产者把制造出来的数据直接放到缓冲区,就可以再去产生下一条内容。基本上不用依赖消费者的处理速度。即炸油条的人直接把油条扔进缓冲区之后就不用管了。
缓存:生产者的生产速度和消费者的消费速度不匹配,可以将产出的内容进行暂存。如果平台用户的账号同时在两台电脑上发布多条内容,而审核专员无法同时进行审批动作,就可以把多出来的内容暂存在缓存区。也就是生产者短时间内生产数据过快,消费者来不及消费,未处理的数据可以暂时存在缓冲区中。
这里,我们以redis作为缓冲区媒介,制作一个缓冲区容器:
import redis
class AuditQueue:
def __init__(self,name,**redis_kwargs):
self.r = redis.Redis(**redis_kwargs,decode_responses=True)
self.key = name
# 审核任务入队
def put(self,item):
# 用列表实现
self.r.rpush(self.key,item)
# 返回队列长度
def qsize(self):
return self.r.llen(self.key)
# 查看队列是否存在
def exist(self):
return self.r.exists(self.key)
# 审核任务出队
def get_wait(self,timeout=None):
# 取值
item = self.r.blpop(self.key,timeout=timeout)
return item当用户产出内容后,并不直接进行审批动作,而是进入“缓冲区”,遵循FIFO(first in first out)原则,无论消费者的消费速度如何,任务全部会保存在“缓冲区”中,直到任务被消费者消费。
当然了,该容器队列并非唯一,因为“先进先出”只是相对而言,如果有加急任务也可以进行加权处理:
import redis
class AuditQueue:
def __init__(self,name,**redis_kwargs):
self.r = redis.Redis(**redis_kwargs,decode_responses=True)
self.key = name
# 审核任务入队
def put(self,item):
# 用列表实现
self.r.rpush(self.key,item)
# 返回队列长度
def qsize(self):
return self.r.llen(self.key)
# 查看队列是否存在
def exist(self):
return self.r.exists(self.key)
# 审核任务出队
def get_wait(self,timeout=None):
# 取值
item = self.r.blpop(self.key,timeout=timeout)
return item
# 加权入队
def put_vip(self,key,item):
# 用列表实现
self.r.rpush(key,item)
# 加权 出队
def get_wait_vip(self,key,timeout=None):
# 取值
item = self.r.blpop([key,self.key],timeout=timeout)
return item这样多个队列之间会有“顺序”,方便控制出队的逻辑。
接着看看消费的问题,这里我们可以采取“并发”出队的业务逻辑,即一个生产者产出可以被多个消费者进行消费:
import threading
rq = AuditQueue("rq")
# 异步出队
def doout(id):
print("出队")
uid = rq.get_wait(1)
print("处理审批逻辑")
# 多线程消费
def dojob_threads():
threads = []
for x in range(2):
t = threading.Thread(target=doout,args=(x,))
threads.append(t)
# 执行批量消费
[x.start() for x in threads]
[x.join() for x in threads]
dojob_threads()
这样的缓冲区设计中,我们的生产者和消费者都持有一个对缓冲区对象AuditQueue的引用,这样的设计模式实际上在很多设计模式都有用到,比如我们的装饰者模式等等,它们共同的目的都是为了达到解耦和复用的效果。
但是,这样的设计方案也会引发另外一些问题:怎样保证缓冲容器中数据状态的一致性,当一个消费者执行了rq.get_wait(1)方法之后,如果此时容器为空,但是还没来得及更新容器的size,那么另外一个消费者来了之后以为size不等于0,那么继续执行rq.get_wait(1),从而就造成了了状态的不一致性。
为了保证当缓冲容器里面没有任务的时候,消费者不会继续rq.get_wait(1),此时消费者释放锁,容器处于阻塞状态;并且一旦生产者添加了一条任务之后,此时重新唤醒消费者,消费者重新获取到容器的锁,继续执行rq.get_wait(1):
rq = RedisQueue("rq")
lock = threading.Lock()
# 异步出队方法
def doout(id):
# 获取锁
lock.acquire()
uid = rq.get_wait(1)
# 处理审批逻辑
# 出对后释放锁
lock.release()令人遗憾的是,Python3的多线程由于全局解释器锁的存在并不能并行,而是单线程执行的分时复用模式。藉此,系统的多核CPU就成了摆设,而我们知道,一个线程可以拥有多个协程,这样在Python中就能使用多核CPU,协程同时能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态,线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位,所以我们可以考虑使用协程来进行消费动作:
import asyncio
async def doout(id=1):
print(id)
rq = RedisQueue("rq")
uid = rq.get_wait(1)
print("开始出队")
# 消费动作
async def main():
# 建立协程对象
task1 = asyncio.ensure_future(doout(4))
task2 = asyncio.ensure_future(doout(7))
tasks = [task1,task2]
# 异步执行
await asyncio.gather(*tasks)以上,一个简单的内容审核系统的雏形就搭建完成了,该设计通过缓冲区概念平衡生产者的生产能力和消费者的消费能力来提升整个系统的运行效率,这是生产者消费者模型最重要的作用。
随后,产品结构确定之后,一些功能上的细节也可以帮助我们提高审核效率。
针对平台用户:
可以通过平台用户的账号进行处理,平台用户的所有行为都能说明用户想干什么,是什么样的用户,所见即所得,针对用户可以建立一套账号基础信息、用户分值系统、用户风险监控系统。用户基础信息可以有用户年龄、性别、地理位置、设备、ip地址、使用时长、交易信息、用户发布各类信息等。用户数据是对用户进行分析的基础,有些数据可以在一定程度上反映用户信用。用户分值系统则是通过用户基础数据进行分析,并数值化,可以按权重累加、按总分值加总均可。
发布过一个违规内容的用户,则分值降低等。仅分值系统可能不够,比如分值高的用户,但是还是有可能发布不好的内容。因此需要再通过其他策略处理,比如高中低风险用户制度、黑白名单制度等。
一个用户发布了一个违规内容被检测出来后,和分值解耦的另外一个平台定义其为高风险用户,该用户后续内容将多次放到人工审核机制中。
针对审批专员:
也可以对审批专员的账号进行用户画像,留存和分析审批员的行为,研究审批人的审批动作喜好以及工作效率或者审批的频率,当审批效率下降后,可以针对该审批人的账号进行“冷冻”处理,强制审核员进行休息,类似高速公路上的休息区,防止“疲劳驾驶”。
诚然,时代在发展,人工智能技术针对图像、文本、语音、视频等多媒体内容,覆盖涉政、涉黄、涉恐、广告检测等全方位的智能AI审核能力可以有效地提升审批效率,但是,最终审批权还是在审核员手里,尤为涉及有些“合规”的内容,AI暂时并不能代替人类。
举个例子,上世纪七十年代,文怀沙先生曾经写了一首诗送给江青,《供奉李公衔女士命招抚,诗以报之。》:
"沙翁敬谢李龟年, 无尾乞摇女主前。九死甘心了江壑 ,不随鸡犬上青天。"
这首藏锋诗后两句,分别含"江","青"二字,正对应前面说的"女主",表明自己不愿学汉代的李龟年,在女主面前无尾乞摇,宁愿死也不当江青身边因一人升天而得道的鸡犬,同时,每句后两字连起来赫然正是“龟主江青”四个字。试问这种既藏锋又藏尾的“讽诗”,那种算法能够识别出来?就算有对应的模型,训练集和测试集又去哪里找呢?
结语:罗翔老师曾经表达过一种观点:“我觉得人最大的痛苦,就是无法跨越知道和做到的那个鸿沟”。陀思妥耶夫斯基也说过:“要爱具体的人,不要总是想着爱抽象的人”,没错,每一个在电脑前苦苦寻求答案的,并不是那个头像,并不是那三两行代码,而是一个活生生的,有血有肉的,有自己三观的,经历了大风大浪的,在社会上苟延残喘的人,而每一个审核专员,他们的近况,他们的诉求,我们知道,但是我们能做什么?回到猝死的问题上,如果说生活中还有什么确定的事情,如果说历史教会了我们什么,那就是:活下去。同时,作为一个简简单单的普通人,也许能做的,就是在宏大叙事之外,关注弱势群体,给他们以希望,最后,以一句话和诸君共勉:
如果活着的人都还活着,那么死去的人就不会死去。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK