

Natural Language Processing (NLP)and CountVectorizer
source link: https://medium.com/sanrusha-consultancy/natural-language-processing-nlp-and-countvectorizer-5571cf9205e4
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


Natural Language Processing (NLP)and CountVectorizer
Natural Language Processing (NLP) is how we make machines learn human language of communication.
In this article, my purpose is to show you how sklearn library CountVectorizer can be used in converting human readable English text into a language machine can understand.
Let’s begin with a very simple text.
text=["Tom's family includes 5 kids 2 dogs and 1 cat",
"The dogs are friendly.The cat is beautiful",
"The dog is 11 years old",
"Tom lives in the United States of America"]
How can we make machine understand this?
Token
First step is to take the text and break it into individual words (tokens). We are going to use sklearn library for this.
Import CountVectorizer class from feature_extraction.text library of sklearn. Create an instance of CountVectorizer and fit the instance with the text.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer=CountVectorizer()
vectorizer.fit(text)
CountVectorizer has several options to play around.
CountVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=<class 'numpy.int64'>, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern='(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
Notice that by default lowercase is True.
That means, while creating tokens, CountVectorizer will change all the words in lowercase.
Call get_feature_names function to get the list of tokens.
print(vectorizer.get_feature_names())
Result:
['11', 'america', 'and', 'are', 'beautiful', 'cat', 'dog', 'dogs', 'family', 'friendly', 'in', 'includes', 'is', 'kids', 'lives', 'of', 'old', 'states', 'the', 'tom', 'united', 'years']
Make note of few things here
a. As mentioned all the tokens are in small case
b. Single character words like number 5, 2, 1 are not there in the list of tokens/features. This is happening because, by default CountVectorizer considers only words with at least two characters. If you want to include single character words, you need to change the token_pattern option.
c. Instead of Tom’s the token has tom. That means the punctuation is not considered.
d. United States of America is tokenized as four different words. What if you want to tell Machine to check if a document contains United States of America as a country? We will handle this scenario later in this article.
vectorizer=CountVectorizer(token_pattern=u’(?u)\\b\\w+\\b’)
vectorizer.fit(text)
print(vectorizer.get_feature_names())
Result:
['1', '11', '2', '5', 'america', 'and', 'are', 'beautiful', 'cat', 'dog', 'dogs', 'family', 'friendly', 'in', 'includes', 'is', 'kids', 'lives', 'of', 'old', 's', 'states', 'the', 'tom', 'united', 'years']
In real world project, when your model has to read several thousand documents to categorize or humongous number of emails to filter spam emails regular words like ‘is’, ‘the’, ‘a’, ‘an’, ‘and’, ‘are’ don’t add any value. It is better to not tokenize them. In order to not consider them use the option stop_words as shown below
vectorizer=CountVectorizer(token_pattern=u'(?u)\\b\\w+\\b',stop_words=['is','are','and','in','the'])
vectorizer.fit(text)
print(vectorizer.get_feature_names())
Result:
['1', '11', '2', '5', 'america', 'beautiful', 'cat', 'dog', 'dogs', 'family', 'friendly', 'includes', 'kids', 'lives', 'of', 'old', 's', 'states', 'tom', 'united', 'years']
Encoding
So far the tokens are still human readable text. Machine cannot understand them. These tokens have to be encoded. This encoding is done by CountVectorizer while fitting the text. You can see the encoded values by calling vocabulary_
print(vectorizer.vocabulary_)
Result:
{'tom': 18, 's': 16, 'family': 9, 'includes': 11, '5': 3, 'kids': 12, '2': 2, 'dogs': 8, '1': 0, 'cat': 6, 'friendly': 10, 'beautiful': 5, 'dog': 7, '11': 1, 'years': 20, 'old': 15, 'lives': 13, 'united': 19, 'states': 17, 'of': 14, 'america': 4}There are twenty one tokens encoded with numbers ranging from 0 to 20. The sequence of words in text is not considered while encoding the tokens.
Frequency
After tokens and encoding comes counting how many times each word appeared in the text.
Call transform method of CountVectorizer instance.
vector=vectorizer.transform(text)
Check the shape of vector
print(vector.shape)
Result:
(4, 21)
Very good!
The text has been encoded into sparse matrix. Convert this sparse matrix into numpy array by calling toarray method.
vector.toarray()
Result:
array([[1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0]],
dtype=int64)
Can you understand this array?
There are twenty four (representing twenty four words considered) ‘1’ spread across four rows. Each one represent a word in the text as per encoded value. To understand this array better, convert it into pandas dataframe
import pandas as pd
pd.DataFrame(vector.toarray(),columns=vectorizer.get_feature_names())
Result:
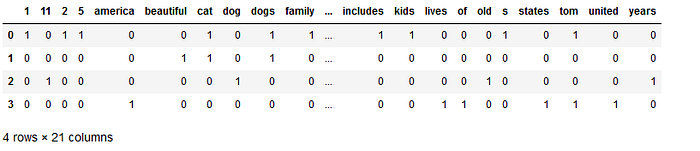
Now compare the token numbers with the values to understand which word appeared how many times.
For example token 0 is for number 1. Number 1 appeared once in first row, hence it shows 1 for column 0 and row 0 in above data frame. For all other rows column 0 contains 0.
Vocabulary
Now coming back to the scenario we discussed in point d of Tokenization section. Suppose you are only interested in knowing whether or not the text contain United States of America.
You can achieve this by using ngram_range and vocabulary option.
ngram_range indicates how many words will be considered together for tokenization. Default value is [1,1], that’s why it considered every word as new token.
Run below line of code to understand how ngram_range works.
vectorizer=CountVectorizer(token_pattern=u’(?u)\\b\\w+\\b’,stop_words=[‘is’,’are’,’and’,’in’,’the’],ngram_range=[1,4])
vectorizer.fit(text)
print(vectorizer.get_feature_names())
Result:
['1', '1 cat', '11', '11 years', '11 years old', '2', '2 dogs', '2 dogs 1', '2 dogs 1 cat', '5', '5 kids', '5 kids 2', '5 kids 2 dogs', 'america', 'beautiful', 'cat', 'cat beautiful', 'dog', 'dog 11', 'dog 11 years', 'dog 11 years old', 'dogs', 'dogs 1', 'dogs 1 cat', 'dogs friendly', 'dogs friendly cat', 'dogs friendly cat beautiful', 'family', 'family includes', 'family includes 5', 'family includes 5 kids', 'friendly', 'friendly cat', 'friendly cat beautiful', 'includes', 'includes 5', 'includes 5 kids', 'includes 5 kids 2', 'kids', 'kids 2', 'kids 2 dogs', 'kids 2 dogs 1', 'lives', 'lives united', 'lives united states', 'lives united states of', 'of', 'of america', 'old', 's', 's family', 's family includes', 's family includes 5', 'states', 'states of', 'states of america', 'tom', 'tom lives', 'tom lives united', 'tom lives united states', 'tom s', 'tom s family', 'tom s family includes', 'united', 'united states', 'united states of', 'united states of america', 'years', 'years old']
ngram_range is mentioned as 1 to 4, hence CountVectorizer considers single word to four word combination as separate token. Now if you add vocabulary option to this, it will meet the requirement.
vectorizer=CountVectorizer(token_pattern=u'(?u)\\b\\w+\\b',stop_words=['is','are','and','in','the'],ngram_range=[1,4],vocabulary=['united states of america'])
vectorizer.fit(text)
print(vectorizer.get_feature_names())
Result:
['united states of america']
It returns only one token as it found the word mentioned in vocabulary.
If the text doesn’t contain united states of america, it will not return any thing. This way you can filter a document based on content you are looking for.
Natural Language Processing (NLP) is fun!
Reference:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK