

如何构建一个流量无损的在线应用架构
source link: https://www.51cto.com/article/700980.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

这一篇主要从数据交换的维度阐明数据交换的过程如何影响到线上流量;最后会引入两个常用的防范措施:全链路压测和安全生产演练。我们先来说说数据交换部分:

当流量在应用集群中流转完毕之后,他行至的终点一般是将数据与各种类型的数据服务进行交换,如:从缓存读取数据返回、将订单记录存储在数据库中、将交易数据与外围的支付服务进行数据交换等。但是只要是和外面的服务进行数据访问,就会出现外围服务不可用的情况,常见的一些情况比如:因为被依赖过重或数据过载而导致雪崩,因为数据中心整体不可用导致大面积瘫痪。比如最近一个比较有名的事件就是 Meta 公司的大规模宕机事件,其原因正是下发了一条错误的配置切断了数据中心之间的主干路由。
1. 常用解决方案:分库分表
针对国内互联网公司海量数据的场景,当我们的业务成长到一定的阶段就会带来缓存或者 DB 的容量问题,以 MySQL 举例子,当单表的容量在千万级别的时候,如果这张表还需要和其他表进行关联查询,就会出现数据库在 IO、CPU 各方面的压力。此时就需要开始考虑分库分表的方案。但是分完了之后并不是一蹴而就,他会引入诸如分布式事务、联合查询、跨库 Join 等新的问题,每个问题如果人肉去搞定会更加的棘手,不过好在市面上针对这些领域也出现了很多优秀的框架,比如社区的 Sharding JDBC,阿里云刚刚开源的 PolarDB-X 等。
2. 常用解决方案:数据中心容灾
为防止数据中心出现整体不可用的情况,一个常规的思路是需要针对性建设好容灾多活的高可用能力,数据中心级别的容灾常见的是同城和异地,但一个数据中心部署的服务很可能是分布式服务,针对每一个分布式服务的容灾策略都略有不同,本篇以常见的 MySQL 来举例子说一些常见的思路。
容灾的核心是需要解决 CAP 中的两个问题,即:C(数据一致性)、A(服务可用性),但是根据 CAP 理论我们只能保 CP 和 AP 中的一个,所以这里到底选择什么样子的策略,其实是需要根据业务形态来制定的。对于同城 IDC 级别的容灾而言,由于他的 RT 一般都很小,数据一致性上能最大的得以满足。只是在 Paxos(MySQL 中的一致性算法)的 Master 节点所在的机房如果挂掉的情况下,会面临再次选主,如果集群较大可能会因为选主造成的几十秒级别 DB 不可用的情况。而对于异地场景而言,由于数据链路太长的问题,他的数据一致性基本上不可能满足,所以业务必须配合改造,做到业务级别的横向切分,如:华南数据中心服务华南客户群体,华北数据中心服务华北客户群体。而分片的数据再通过数据同步的方式做到最终一致性。
到这里基本上说完了在线上应用的四个核心环节中,尤其提及了容易由于架构设计、基础设施脆弱等原因而造成的流量有损的点,也列举了对应场景下的解决方案。不过站在安全生产的角度上,一切安全生产的目的都是防范于未然。在互联网的系统中相比较于传统的软件产品,我们推荐两个在生产级别进行防范的方法:全链路压测和安全生产线上演练(也叫故障演练)。
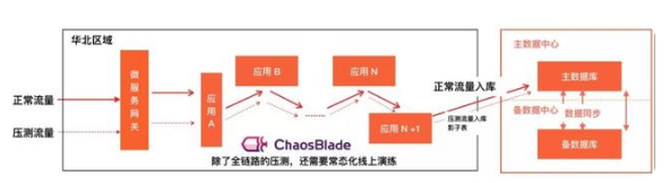
1. 全链路压测
在软件产品的生产体系中,任何一个即将上线的系统,我们都会进行各种目标的测试,其中就包括压力测试,即:使系统处于一个颇为严苛的环境中,来观看系统的表现。而一般的压力测试,只会针对性的构造相应的接口对线下部署的环境服务进行相应的压力测试,而且测试报告不出意外都是很完美的;但这样的压力测试会有几个问题:
- 由于线上线下的依赖环境差异很大,而评估不到真实的线上系统容量。
- 压测过程的数据不丰富,覆盖面窄而造成场景遗漏。
- 由于压测的流量或者工具不够健全,只能评估到单台机器或服务,而非整个生产集群。
如果要做到全面、系统、且真实的流量评估,我们推荐直接使用生产环境针对性的进行性能压测,但要想做到这样的全链路的压力测试,有很多的技术瓶颈需要突破,其中包括:
- 有一套能力强大能构建出丰富场景的工具体系或产品。
- 整体服务链路上,支持从流量入口开始的压测标示传递。
- 系统中使用的中间件能识别正常流量与压测流量。
- 业务需要针对压测流量作出业务改造(如影子表),以免压测数据影响到线上的真实数据。
但是在执行过程中,由于全链路的影响面太大,在正式开始大流量的压测之前,需要逐步实施前期的准备工作,其中包括:压测方案制定、预跑验证、压测预热,最后才是正式压测。压测完毕还需要针对压测结果进行分析,以确保整个系统符合预先设定的目标。
2. 安全生产演练
与全链路压测的思路类似,为了尽可能的贴近生产环境,安全生产演练我们也是推荐在线上完成。演练的目的是检验系统在各种不可预知的服务不可用、基础实施故障或者依赖失效的情况下,来检验系统的行为表现是否依然健壮。通常演练的范围从单应用到服务集群,甚至到整机房基础设施依次上升。演练场景可以从进程内(如:请求超时)、进程级别(如:FullGC)、容器(如:CPU 高),再到 Kubernetes 集群(如:Pod驱逐、ETCD 故障等)各个场景叠加,根据业务系统的反脆弱能力,针对性的作出选择。
文中很多场景和技术点都是来源于真实的线上系统的真实故障。我们将这些年在每一个环节中的相应解决方案,以产品化的方式沉淀到企业级分布式应用服务(EDAS)中。EDAS 致力于解决在线应用的全流程流量无损,经过 6 年的精细打磨,已经在流量接入与流量服务两个关键位置为我们的客户提供了流量无损的关键能力,我们接下来的主要目标也是将这一能力贯穿应用的全流程,让您的应用默认能具备全流程的流量无损,极力保障商业能力的可持续性。


 分享到微信
分享到微信  分享到微博
分享到微博Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK