

What is a research repository and what to consider before building one?
source link: https://uxstudioteam.com/ux-blog/what-is-a-research-repository-and-what-to-consider-before-building-one/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

What is a research repository and what to consider before building one?
A centralized system is required to develop a good understanding of your users across teams and across your firm. Here's when research repositories come in handy. They bring together various points of user input and feedback. So, whether you're a user experience researcher, a user experience designer, or a product manager, this post is for you.
In this course, we’ll cover everything you need to know about research repositories for UX research. This includes everything from the basics, starting with:
- What’s a research repository?
- What are the key guiding principles for Research repositories?
- How to build one that fits your needs?
- How to get your teammates on board?
- And last, but not least – how to keep the research repository going once you’re up and running?
We’ll go through all you need to know about research repositories for UX research in the coming weeks. This comprises all of the fundamentals, beginning with understanding what is a research repository, then continuing with learning about its key guiding principles and guiding you through building a research system that is easy to maintain for long-term success.
What is a research repository?
Over the years, we’ve worked on various research projects at UX Studio. Some were broader, some were smaller. However, at some point, we needed more than just weekly presentations to share the insights from our research with our clients. We needed the means to organize and concentrate our study findings and observations, particularly for long-term projects. We should be able to share study findings with stakeholders using this solution.
We’ll take a closer look at what a research repository is. We’ll also look at how it grew in popularity among the UX community.
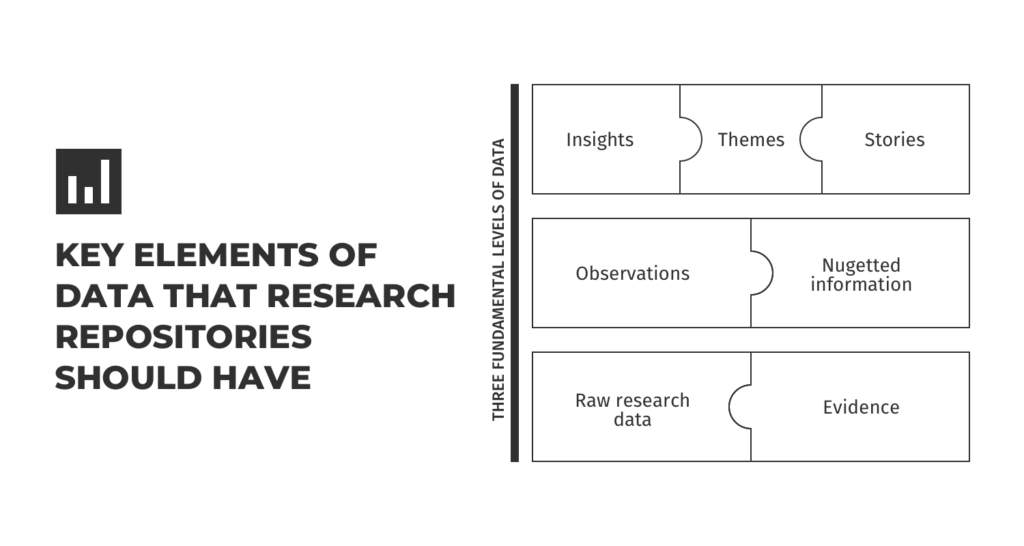
Any system that keeps research data and notes that can be quickly retrieved, accessed, and used by the entire team is referred to as a research repository (or research library). Let’s look at the key components of this definition.
Storage system.
A system of this type is any tool you use to store and organize your research data. This can take various forms and structures. It could be an all-in-one application, a file-sharing system, a database, or a wiki.
Research data.
Any information that helps you understand your users can be considered research data. It makes no difference what format is used. Text, images, videos, or recordings can all be used to collect research data. Notes, transcripts, or snippets of customer feedback can also be used.
Ease of use.
Anyone on your team can access, search, explore, and combine research data if it is simple to use. Developers, designers, customer success representatives, and product managers are all examples of this. Any of them can gain access to the research repository in order to learn more about users. The researcher is no longer the gatekeeper when it comes to understanding users.
Since it’s a massive collection of research, the research repository is also the team’s go-to place for learning about users and their pain points. Instead of searching three different locations for reports, all research information is centralized in one single place.
 source: www.questionpro.com/
source: www.questionpro.com/How did research repositories become a tool for UX research?
First – companies started doing more and more user research. This means more studies, more reports, and a whole lot of information that you cannot really access unless you know who worked on what.
Let’s say you wanted information about some secondary insights from a past usability study. In the current report-heavy setup, you would have to:
- Find the researcher who ran the study.
- Reach out to schedule a call or a meeting
- Hope that they remember the answer for your question.
Realistically speaking, that would take at least a day – if not more.
Or – if you’re the one who performed the research, you’d have to go through many different reports until you find the one you’re looking for.
The second reason is often attributed to Tomer Sharon – now Managing director, Head of user research at Goldman Sachs, then VP, Head of User Experience at WeWork ran into a similar issue. To solve it, he came up with a new approach, based on atomic design principles. Tomer applied those to UX research, breaking down reports into small, easily digestible bits of information. That pretty much led to what we now call research repositories.
Why do you need a research repository?
We briefly mentioned these points when we wrote about how it’s difficult to find information when research piles up. Searchability, losing reports, traceability of data, and difficulties regarding the comparison of data are issues a well-thought-out research system can help solve.
Searchability is an issue
The biggest problem when you have a lot of reports is searching through them. Often, the report content is not accessible by search. This means that you have to shift through a lot of documents to find the one you need. And this is the case for pretty much any file management system you’re using: Dropbox, OneDrive, Sharepoint or Google Drive to name a few of the most popular. Additionally, if multiple files match the phrase you’re searching for, you have to check a few of them to find the one you’re looking for. This becomes more of a problem as new researchers join and they have to search through other people’s reports.
No one actually reads reports and they get lost
Even if they’re the go-to format for sharing research results, reports often go unread. What’s more, they have a short shelf-life after the deadline passes for turning them in. Once reviewed, research reports often get lost in Google Drive, Dropbox, or whatever document management system you’re using. If they don’t get lost there, research reports end up as an attachment in a full inbox or in a chat window. The problem is that none of your teammates would think about searching there in case they want to learn more about users.
Reports are disconnected from the raw data
Reports present the conclusions or the findings from a study. More often than not, this means they leave out the raw data and the evidence that supports those findings. For skeptical product managers or executives, the lack of hard proof can make them doubt the conclusions since there is no hard evidence present in the report.
Secondary insights get lost
The main purpose of these reports is to answer the initial research question. In reality, while you’re running a study, you probably find additional insights and observations. These could be very valuable later on. But if you don’t have a system to track them, you cannot reuse them. Still, it’s pretty much a Catch-22 situation. If you add the secondary insights, you might distract attention from the main research objective.
Comparing insights is time-consuming
Reports and the information they convey become buried and lost in file-sharing networks. At some point, someone conducted research on a feature. Let’s say another team member comes and wants to learn more about that functionality. Researchers begin a new investigation for the same question without any prior knowledge of previous research. If, on the other hand, all the research data is centralized, you can see what questions have already been asked. It is almost impossible to see whether observations or insights from different reports are connected or different.
Silos within departments.
Whether they know it or not, every department collects information, one way or another. Customer success learns about the users’ problems during help chats or calls. Sales probably do the same on pitches and sales calls. Most likely, marketing and analytics also have a fair knowledge of users. And as Tomer Sharon suggests, they’re probably all doing surveys without the others knowing. Don’t laugh – there’s a big chance that that’s true.
Now, by default, each of these departments presents their findings every now and then in a report or over an in-person presentation for upper management. Another issue with silos is that no one connects the dots between the different bits of information that each department collects. It’s a bit like that old saying: you walk through the forest, looking at trees one by one. In this case, you can not see the forest because it’s broken down into too many trees.
Repeated research
Repeated research can happen in two situations.
First, when a new researcher joins the team and they start performing studies. Chances are they will come back with something that is already known. This is understandable in a way – they’re new to the team and they didn’t know. For experienced researchers, this is a waste of time. In time, this can chip away at the effectiveness and the usefulness of performing user research.
The second situation is where someone – either a product manager or a designer asks if anyone has information about a specific topic. If it hasn’t been too long since the study, probably someone will answer that they do. However, it will take some time to track down the information and see if it can be used to answer that particular question. If the results of the original study cannot be repurposed, that means going back to square one to answer the new research question.
We have covered all the reasons why you need a research repository. But how will one actually help you?
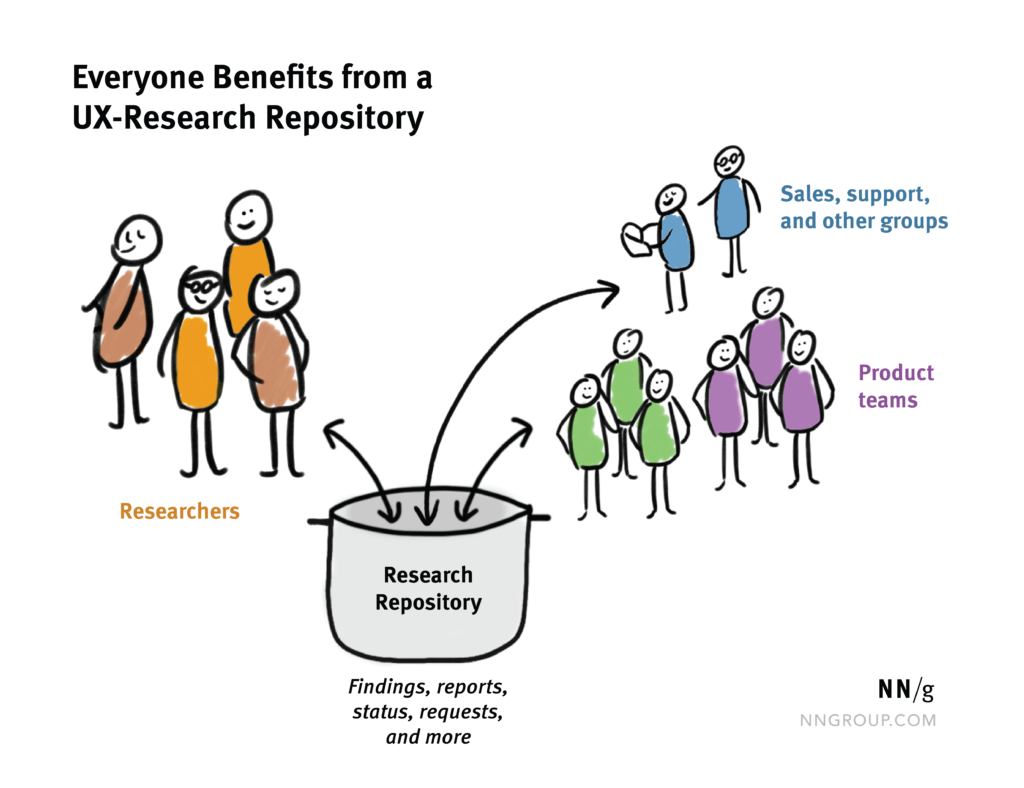
How research repositories save the day?
From onboarding new colleagues to speeding up research, capacitating user-based decision making, and bringing user-centric work culture into the entire organization, a well-maintained research repository brings value to any organization in the long term.
It’s the #1 go-to resource for learning about users.
Having all the research knowledge in one official place will make it easier to actually find information about users. You don’t have to wonder where the information is. You know where to go look for it. No more searching for reports across Google Drive, Dropbox, inboxes, or chats. Also, this can be helpful for newcomers to the team.
Speeding up research.
Whenever you have a new research question, you can start by reviewing existing data. Since it’s all organized according to tags, you don’t have to go through multiple reports to find it. This way, if there’s relevant information, you get the answers faster.
Get more value from original research.
If research observations are no longer tied to report findings, they can be reused to answer other questions. Of course, if they’re relevant. This builds on the previous point of speeding up research. Also, it allows you to get more value from original studies.
No more repeated research.
As reports get buried and lost in file-sharing systems, so does the information they contain. We briefly mentioned this before. But you’re probably familiar with the situation. Someone performed a study on a feature at some point. Let’s say that another person joins the team and wants to learn about that feature. Without any knowledge of existing research, researchers start a new study for the same question. If, on the other hand, all the research data is centralized, you can see what questions have already been asked.
Enable evidence-based decisions.
Probably this is one of the biggest wins for a research repository. It allows teams to see the big issues that need to be solved. Also, teams get to see on their own, how these issues come up. On top of that, they can now use that data to prioritize projects and resources. This makes it easier than using gut feelings or personal opinions.
Anyone can learn about users.
By default, the researcher is the person who knows everything about users and their problems. A research repository opens up this knowledge to anyone who is interested. With a bit of time and patience, everybody can get to know users.
You can prioritise your roadmap.
Putting all the data together will give you an overall view of the user experience. This, in turn, will help you see what areas you need to prioritize on your roadmap.
Yes, it takes time and resources to set up and maintain a research repository. But the benefits are clearly worth that investment. Even more so since information, along with access to it are essential for high-performing teams. Besides research, it is about building trust and transparency across your team and giving them what they need to make the right decisions.
When to use a research repository?
Whether you are thinking about setting up a research system for an ongoing project, or you would like to organize your existing insights, there are a few things to consider.
Long term, ongoing research.
This is common for in-house research. It may also occur if the user research is outsourced to a third party. Data will begin to pile up at some point in long-term, ongoing research. It will become more difficult to locate information as it accumulates. We’ve also discussed the issues that may arise if you only rely on reports. In this case, you will undoubtedly require a solution to organize and structure all of the research findings.
This is the first major scenario in which you should strongly consider establishing a research repository. Even if you’re a one-person team, and you’re the only one doing the research, it’s a good idea to start promoting research repositories. Explain your situation to your manager or team.
Multiple researchers are working on the same project.
It doesn’t really matter whether this is a short-term or long-term project. When multiple researchers are working on the same project, they require a solution that will assist them in compiling all of the data. You can collect all of the observations using a research repository. Even if the two researchers discuss their findings, using a research repository increases the likelihood that important data will not be overlooked
There are a few instances where establishing a research repository may not be the best idea.
Short projects with only one researcher.
What exactly do we mean when we say “short project”? Basically, anything from a few days to a month. The amount of research required for a one- or two-week research project does not justify the time required to put up a research inventory. If it’s a one-person research team, the case against research repositories is considerably stronger. In this situation, the time and resources required to build up a research repository would be better spent on the research itself.
There is no ongoing research.
You probably have a limited amount of data if you conduct minimal user research every two to three months. Large amounts of data can be easily organized using research repositories. A research repository, on the other hand, isn’t necessary if there isn’t much, to begin with.
Keep in mind that the research repository is just that: a tool. Its goal is to assist you in organizing research data so that you can reuse it.
Don’t add it only to have a research repository or to stay current with the latest trends if it doesn’t serve your team’s needs.
The truth is that setting up a research repository will take some time. For ongoing research, especially for an in-house setting, the effort is totally worth it. When you have a large amount of data to go through, an organized system will make the task a lot easier.
Popular examples of research repositories
To get a better idea of what a research repository looks like in practice, let’s look at a few examples.
Uber Kaleidoscope
Uber’s research repository brings together data from all its teams around the world. What’s more, it integrates observations both from science-based discipline as well as from operation-based roles. According to Uber, all insights are valuable. With this in mind, the main goals behind Uber’s Kaleidoscope were to enable information sharing across teams from all over the world and to inform decisions about how projects and resources should be prioritized.
In creating the research repository, the team in charge followed the step-by-step process. They started with an MVP using an external database, tested, and iterated on it. Once they arrived at a stable solution, they integrated other internal collaboration tools to facilitate working with insights. Their nuggets come with a predefined format: an insight statement containing who + where + what + why happened, accompanied by facts, evidence supporting the statement, and potential solutions for that insight.
The repository also features two main roles: insight creators and insights consumers. For more details, check the link in the recommended links section. (link)
GitLab’s UXR Insights repository
GitLab’s research team started with a team of 1 in 2017. Back then, research was mostly feedback that came from different sources. Since then, research grew to a project with more than 50.000 issues. As reports weren’t efficient, GitLab decided to use its own tool to build a research repository.
Instead of nuggets, they use the platform’s issue functionality to report observations. They have also adjusted other default GitLab features to organize these and to tell which research projects are ongoing. Sarah O’Donnell shared their experience on the GitLab blog. You can find the link to that post in the recommended reading section. (link to article) You can preview the research repository yourself (link to article).
So, with this blog post, we’ve covered the key theories about research repositories.
Next Wednesday, we will continue with an introduction to Atomic research principles.
Stay tuned!
Looking for an affordable web design agency?
UX studio has successfully handled over 250 collaborations with clients worldwide.
Should you want to improve the design and performance of your digital product, contact us.
We will walk you through our design processes and suggest the next steps. Our experts would be happy to assist with the UX strategy, product and user research, UX/UI design, and UX training.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK