

从TiDB 中我们能学什么?
source link: https://www.luozhiyun.com/archives/647
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/647
什么是TiDB
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式数据库产品。
五大核心特性
- 一键水平扩容或者缩容:可按需对计算、存储分别进行在线扩容或者缩容,扩容或者缩容过程中对应用运维人员透明;
- 金融级高可用:数据副本通过 Multi-Raft 协议同步事务日志,多数派写入成功事务才能提交,确保数据强一致性且少数副本发生故障时不影响数据的可用性。
- 实时 HTAP:提供行存储引擎 TiKV、列存储引擎 TiFlash 两款存储引擎,TiFlash 通过 Multi-Raft Learner 协议实时从 TiKV 复制数据,确保行存储引擎 TiKV 和列存储引擎 TiFlash 之间的数据强一致。
- 云原生的分布式数据库:可在公有云、私有云、混合云中实现部署工具化、自动化。
- 兼容 MySQL 5.7 协议和 MySQL 生态:应用无需或者修改少量代码即可从 MySQL 迁移到 TiDB。提供丰富的数据迁移工具帮助应用便捷完成数据迁移。
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:
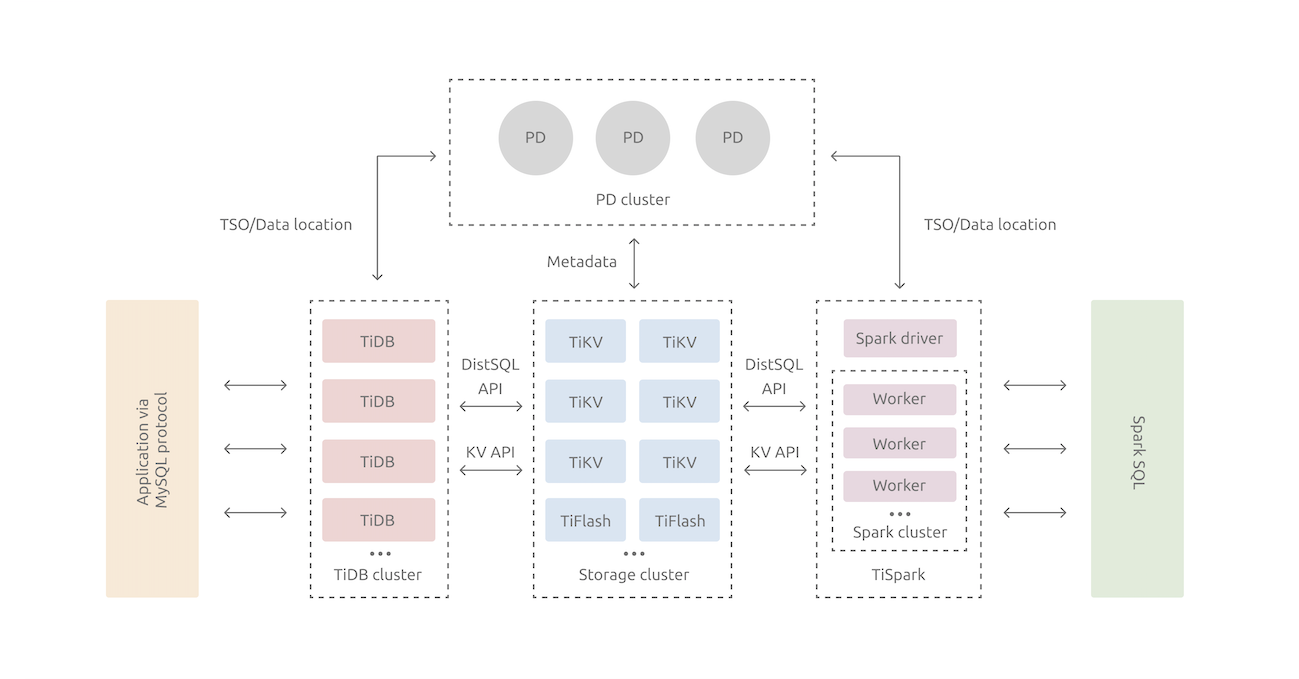
- TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
- PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。
- 存储节点 TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。
SQL 执行过程
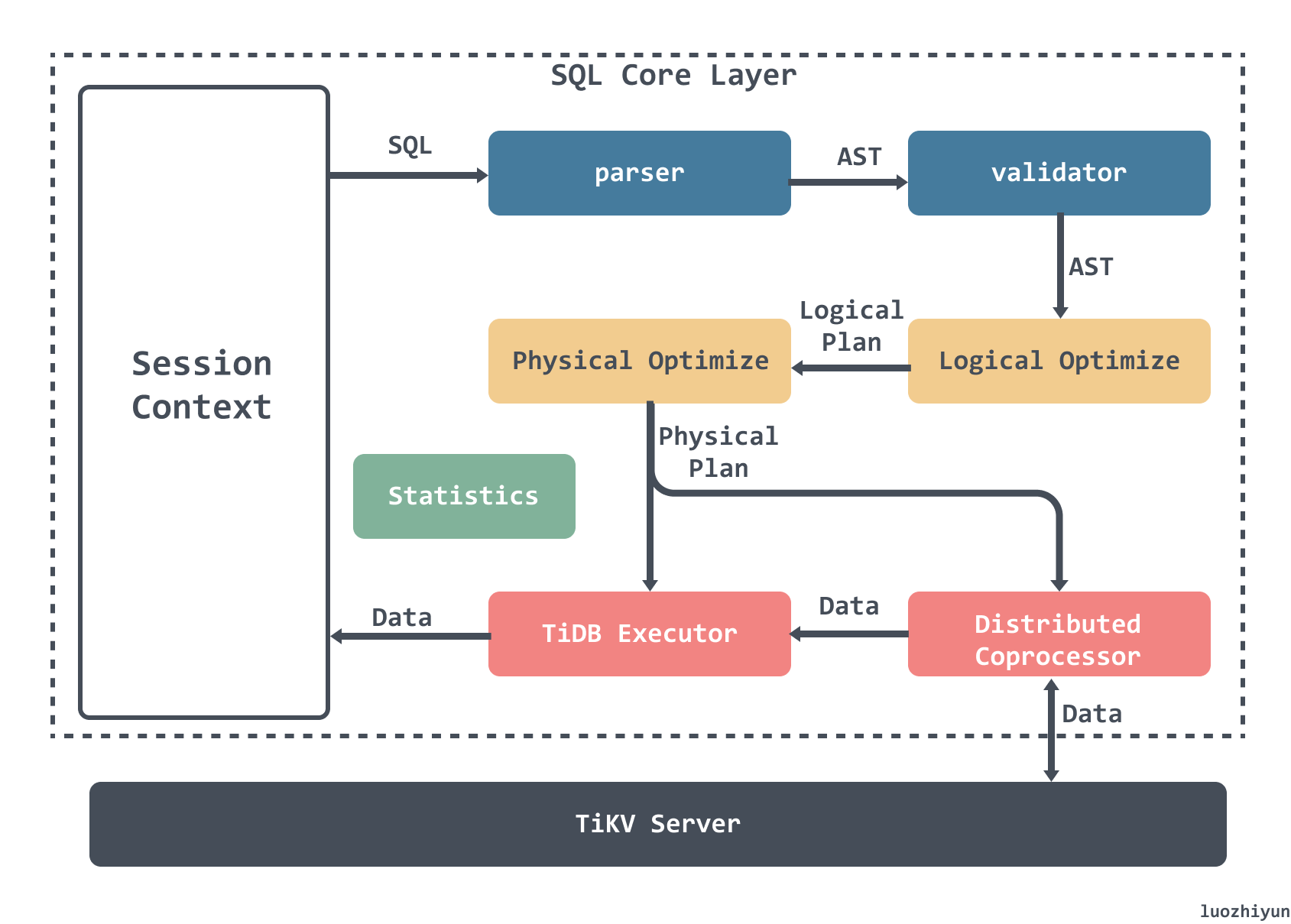
整个 SQL 的执行过程包含以下几个部分:
- Parser & validator:将文本解析成结构化数据,也就是抽象语法树 (AST),然后对 AST 进行合法性验证;
- Logical Optimize 逻辑优化:对输入的逻辑执行计划按顺序应用一些优化规则,从而使整个逻辑执行计划变得更好。例如:关联子查询去关联、Max/Min 消除、谓词下推、Join 重排序等;
- Physical Optimize 物理优化:用来为上一阶段产生的逻辑执行计划制定物理执行计划。优化器会为逻辑执行计划中的每个算子选择具体的物理实现。对于同一个逻辑算子,可能有多个物理算子实现,比如
LogicalAggregate,它的实现可以是采用哈希算法的HashAggregate,也可以是流式的StreamAggregate; - Coprocessor :在 TiDB 中,计算是以 Region 为单位进行,SQL 层会分析出要处理的数据的 Key Range,再将这些 Key Range 根据 PD 中拿到的 Region 信息划分成若干个 Key Range,最后将这些请求发往对应的 Region,各自 Region 对应的 TiKV 数据并计算的模块称为 Coprocessor ;
- TiDB Executor:TiDB 会将 Region 返回的数据进行合并汇总结算;
构建 AST 语法树
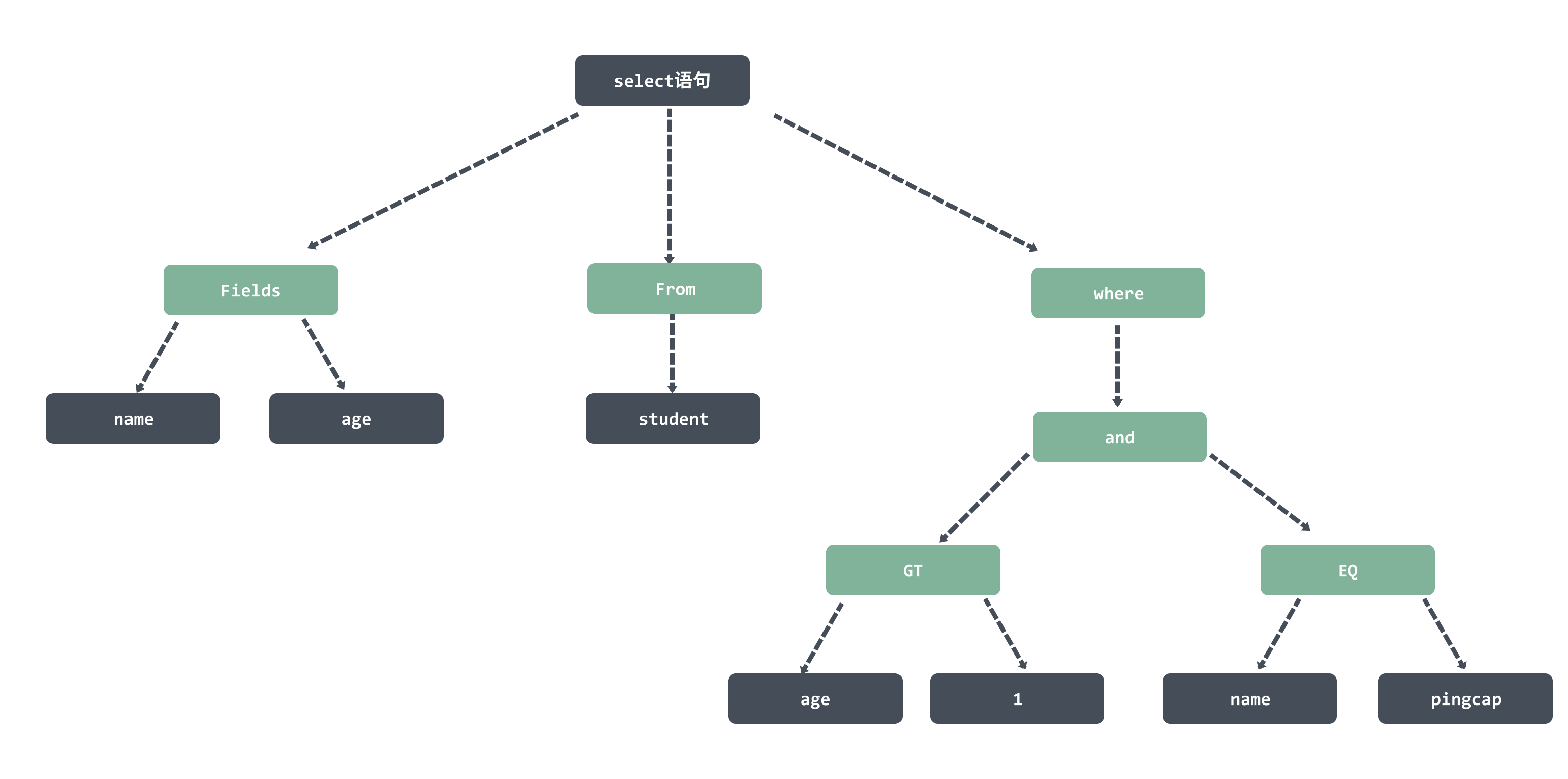
例如下面的这个 SQL 语句:
select id,name,age from student where age>1 and name='pingcap';会被解析生成一颗语法树,然后保存到ast.StmtNode这个数据结构里面。
type SelectStmt struct {
dmlNode
*SelectStmtOpts
Distinct bool
From *TableRefsClause
Where ExprNode
Fields *FieldList
GroupBy *GroupByClause
Having *HavingClause
...
}
构建执行计划
接下来会根据 ast 语法树的节点信息来构建出执行计划,由于上面的 SQL 比较简单,我们换一个有带有聚合的函数来看一下我们生成的执行计划:
select * from test1 where b=5 or ( b>5 and (b>6 or b <8) and b<12) ;然后会根据这个 SQL 生成的 ast 语法树生成我们的执行计划:
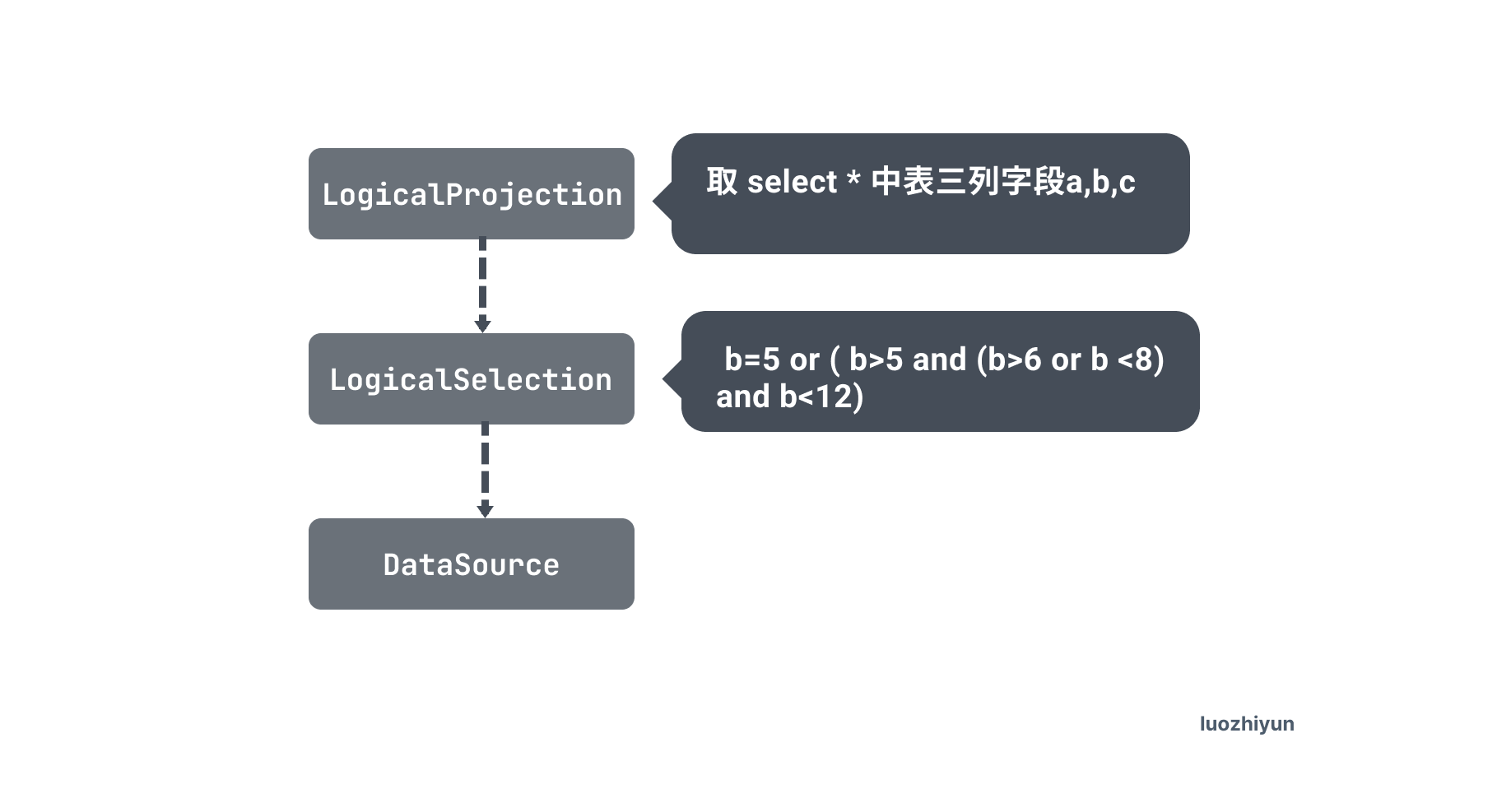
执行计划由下面各个算子构成:
- DataSource :这个就是数据源,也就是表,也就是上面的 student 表;
- LogicalSelection:这个是 where 后面的过滤条件;
- Projection:这里就是对应的 select 后面跟的字段;
逻辑优化
在执行完 logicalOptimize 逻辑优化之后,执行计划变为下面这样:
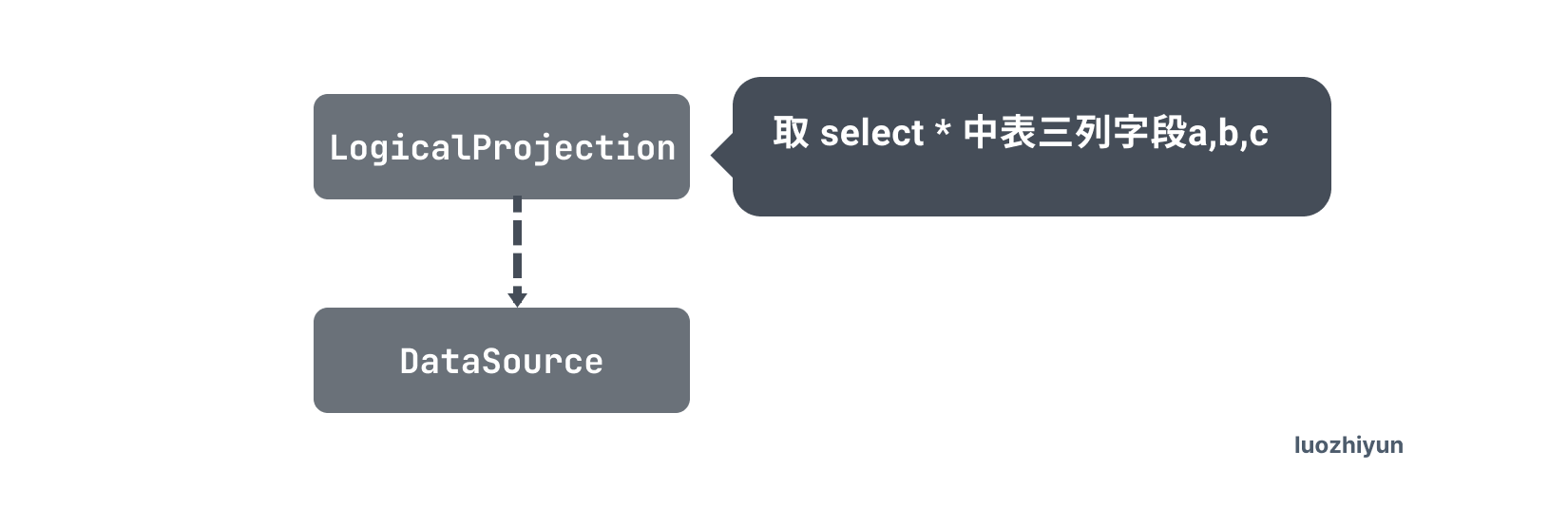
Selection算子被下推到了 DataSource 算子中,这叫谓词下推 Predicate Push Down(PDD)优化。
谓词下推的基本思想是将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据。
在 DataSource 的 pushedDownConds 中保存着下推的过滤算子,pushedDownConds 展开来是一个二叉树结构:
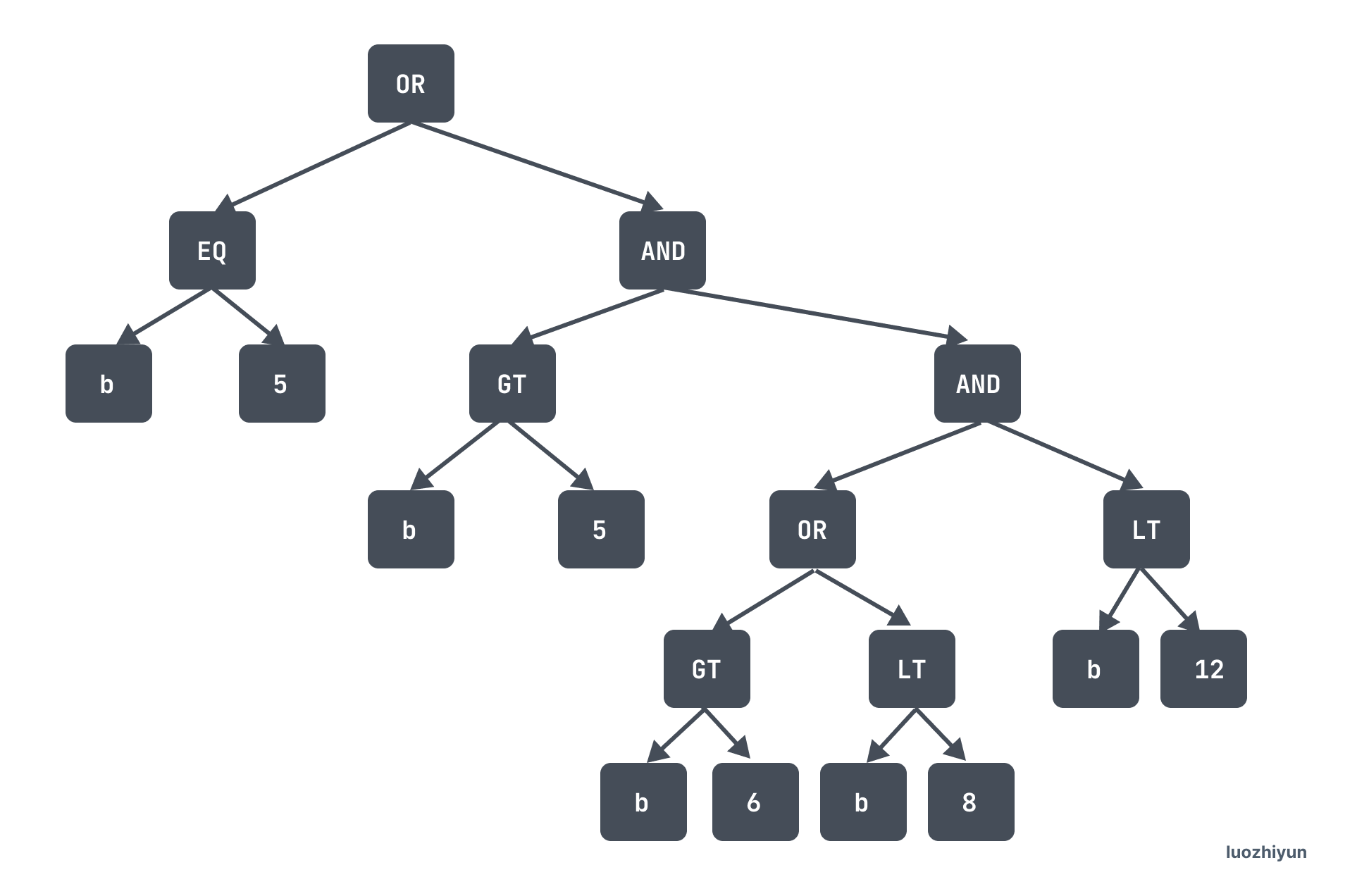
因为索引底层是顺序排列的,所以要将这颗树转为扫描区间。
除了谓词下推优化,TiDB 已经支持下列优化规则:
var optRuleList = []logicalOptRule{
&gcSubstituter{},
&columnPruner{},
&buildKeySolver{},
&decorrelateSolver{},
&aggregationEliminator{},
&projectionEliminator{},
&maxMinEliminator{},
&ppdSolver{},
&outerJoinEliminator{},
&partitionProcessor{},
&aggregationPushDownSolver{},
&pushDownTopNOptimizer{},
&joinReOrderSolver{},
&columnPruner{}, // column pruning again at last, note it will mess up the results of buildKeySolver
}这里每一行都是一种优化器,例如gcSubstituter用于将表达式替换为虚拟生成列,以便于使用索引;columnPruner用于对列进行剪裁,即去除用不到的列,避免将他们读取出来,以减小数据读取量;aggregationEliminator能够在 group by {unique key} 时将不需要的聚合计算消除掉,以减少计算量;
物理优化
这一阶段中,优化器会为逻辑执行计划中的每个算子选择具体的物理实现,以将逻辑优化阶段产生的逻辑执行计划转换成物理执行计划。
首先会调用 DetachCondAndBuildRangeForIndex 来生成扫描区间, 这个函数会递归的调用如下 2 个函数:
detachDNFCondAndBuildRangeForIndex:展开 OR 条件连接也叫析取范式 DNF (disjunctive normal form),生成扫描区间或合并扫描区间;
detachCNFCondAndBuildRangeForIndex:展开 AND 条件连接也叫合取范式 CNF (conjunctive normal form),生成扫描区间或合并扫描区间;

上面的表达式树最终生成了这样的区间:[5,12)。
然后 physicalOptimize 会递归所有的算子调用 findBestTask 函数,最后调用到 DataSoure 算子使用 Skyline-Pruning 索引裁剪,它会从 possibleAccessPaths 获取最优的执行计划。
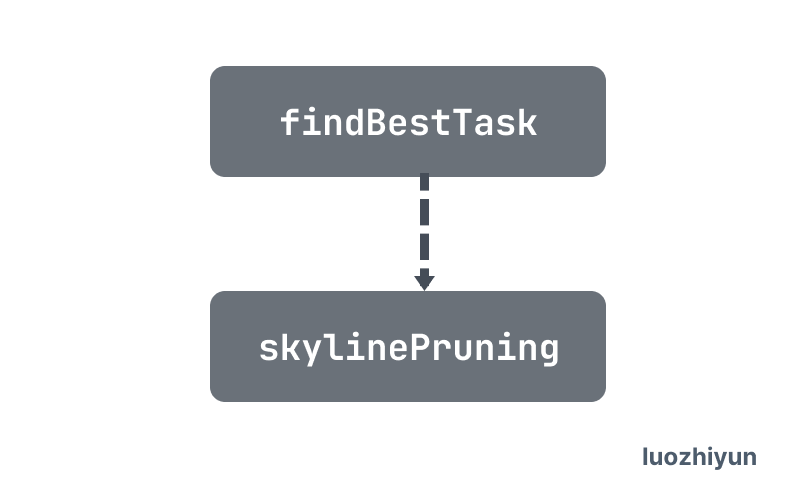
逻辑算子的不同对应的物理实现在时间复杂度、资源消耗和物理属性等方面也有不同。在这个过程中,优化器会根据数据的统计信息来确定不同物理实现的代价,并选择整体代价最小的物理执行计划。
如果一个执行计划包含了多个索引,那么 Skyline-Pruning 会判断一个索引的优劣:
- 索引的列涵盖了多少访问条件。“访问条件”指的是可以转化为某列范围的
where条件,如果某个索引的列集合涵盖的访问条件越多,那么它在这个维度上更优。 - 选择该索引读表时,是否需要回表(即该索引生成的计划是 IndexReader 还是 IndexLookupReader)。不用回表的索引在这个维度上优于需要回表的索引。如果均需要回表,则比较索引的列涵盖了多少过滤条件。过滤条件指的是可以根据索引判断的
where条件。如果某个索引的列集合涵盖的访问条件越多,则回表数量越少,那么它在这个维度上越优。 - 选择该索引是否能满足一定的顺序。因为索引的读取可以保证某些列集合的顺序,所以满足查询要求顺序的索引在这个维度上优于不满足的索引。
在使用 Skyline-Pruning 规则排除了不合适的索引之后,索引的选择完全基于代价估算,读表的代价估算需要考虑以下几个方面:
- 索引的每行数据在存储层的平均长度。
- 索引生成的查询范围的行数量。
- 索引的回表代价。
- 索引查询时的范围数量。
根据这些因子和代价模型,优化器会选择一个代价最低的索引进行读表。
最后执行完后会返回一个叫 task 的结构,TiDB 的优化器会将 PhysicalPlan 打包成为 Task。
目前 TiDB 的计算任务分为两种不同的 task:cop task 和 root task。Cop task 是指使用 TiKV 中的 Coprocessor 执行的计算任务,root task 是指在 TiDB 中执行的计算任务。
Percolator 分布式事务
TiDB 的事务模型沿用了 Percolator 的事务模型,Percolator 论文没看过的同学看这里:https://www.luozhiyun.com/archives/609 我已经双语翻译好了。
所以我们先来讲讲 Percolator 分布式事务。
Percolator实现分布式事务主要基于3个实体:Client、TSO、BigTable。
- Client是事务的发起者和协调者
- TSO为分布式服务器提供一个精确的,严格单调递增的时间戳服务。
- BigTable 是Google实现的一个多维持久化Map。
Percolator存储一列数据的时候,会在BigTable中存储多列数据:
- data列(D列): 存储 value
- lock列(L列): 存储用于分布式事务的锁信息
- write列(W列):存储用于分布式事务的提交时间(commit_timestamp)
Percolator的分布式写事务是由2阶段提交(后称2PC)实现的。不过它对传统2PC做了一些修改。一个写事务事务开启时,Client 会从 TSO 处获取一个 timestamp 作为事务的开始时间(后称为start_ts)。在提交之前,所有的写操作都只是缓存在内存里。提交时会经过 prewrite 阶段和 commit 阶段,一个写事务可以包含多个写操作。
写操作
Prewrite
- 在事务开启时会从 TSO 获取一个 timestamp 作为 start_ts;
- 在所有行的写操作中选出一个作为 primary (不仅本身是一个冲突安全保证手段,同时也是决议事务状态的标志),其他的为 secondaries;
- 对primary行写入L列,即上锁,上锁前会检查是否有冲突:
- 检查L列是否已经有别的客户端已经上锁,直接 Abort 整个事务;
- 检查W列是否在本次事务开始时间之后有事务已提交,检查 W列,是否有更新 [start_ts, +Inf) 之间是否存在相同 key 的数据 。如果存在,则说明存在 W列 conflict ,直接 Abort 整个事务;
- 如果没有冲突的话,则上锁,以 start_ts 作为 Bigtable 的 timestamp,将数据写入 data 列,由于此时 write 列尚未写入,因此数据对其它事务不可见;
Commit
如果 Prewrite 成功,则进入 Commit 阶段:
- 从TSO处获取一个timestamp作为事务的提交时间(后称为commit_ts);
- 提交primary, 如果失败,则abort事务;
- 检查primary上的lock是否还存在,如果不存在,则abort。(其他事务有可能会认为当前事务已经失败,从而清理掉当前事务的lock);
- 以commit_ts为timestamp, 写入W列,value为start_ts,清理L列的数据。注意,此时为Commit Point,“写W列”和“清理L列”由BigTable的单行事务保证ACID;
- 一旦primary提交成功,则整个事务成功。此时已经可以给客户端返回成功了,再异步的进行 secondary 提交。seconary 提交无需检测 lock 列锁是否还存在,一定不会失败;
读操作
- 检查该行是否有 L 列,时间戳为 [0, start_ts],如果有,表示目前有其他事务正占用此行,如果这个锁已经超时则尝试清除,否则等待超时或者其他事务主动解锁;
- 如果步骤 1 发现锁不存在,则可以安全的读取;
TiDB两阶段提交事务
TiDB 提交事务是通过调用 KVTxn 的 Commit 方法进行的。像 pecolator 论文中描述的协议一样,这是一个两阶段提交的过程,Prewrite 阶段与 Commit 阶段。
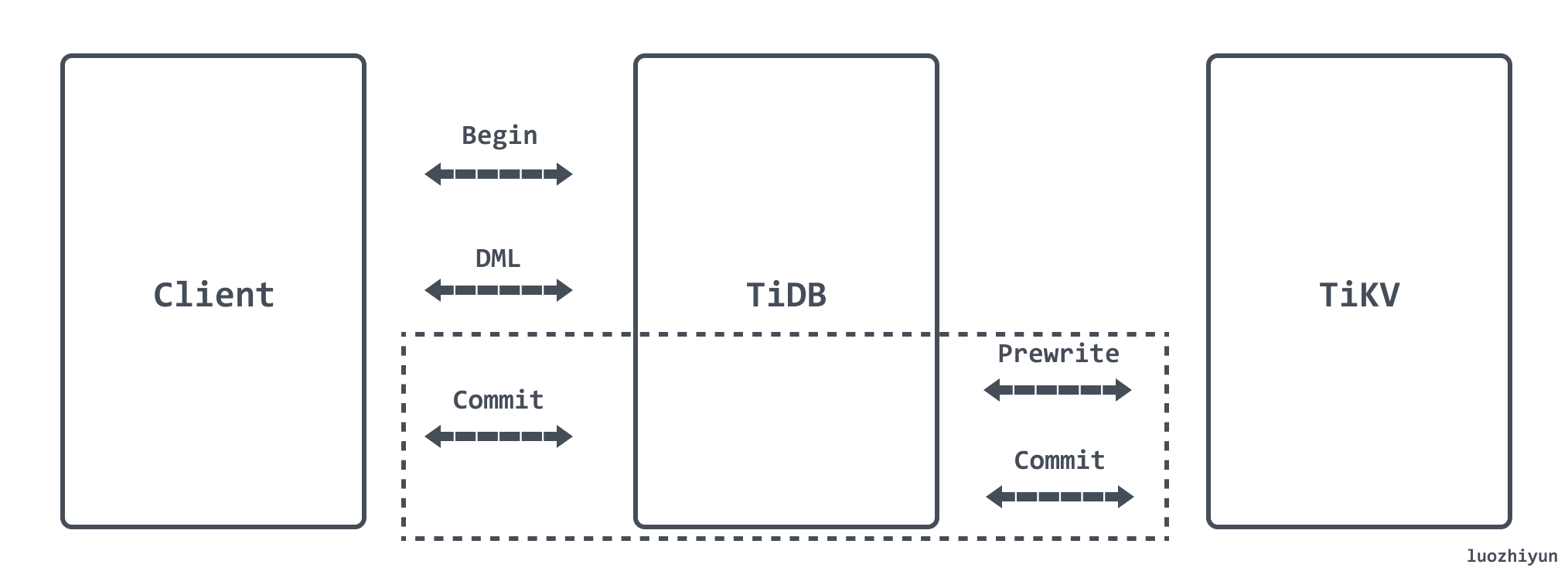
Prewrite:
- TiDB 从当前要写入的数据中选择一个 Key 作为当前事务的 Primary Key。
- TiDB 从 PD 获取所有数据的写入路由信息,并将所有的 Key 按照所有的路由进行分类。
- TiDB 并发向所有涉及的 TiKV 发起 prewrite 请求,TiKV 收到 prewrite 数据后,检查数据版本信息是否存在冲突、过期,符合条件给数据加锁,锁中记录本次事务的开始时间戳 startTs。Prewrite 流程任何一步发生错误,都会进行回滚:删除锁标记 , 删除版本为 startTs 的数据;
- TiDB 收到所有的 prewrite 成功。
当 Prewrite 阶段完成以后,进入 Commit 阶段,当前时间戳为 commitTs,TSO 会保证 commitTs > startTs。
Commit:
TiDB 向 Primary Key 所在 TiKV 发起第二阶段提交 commit 操作,TiKV 收到 commit 操作后,检查数据合法性,清理 prewrite 阶段留下的锁。
数据的存储
TiDB 的存储层是由 TiKV 实现的,可以将 TiKV 看做一个巨大的 Map,也就是存储的是 Key-Value pair,在这个 Map 中,Key 按照 Byte 数组总的原始二进制比特位比较顺序排列。
TiKV 是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。但是 RocksDB 是一个本地存储方案,作为一个分布式存储,需要保证单机失效的情况下,数据不丢失,不出错,所以 TiKV 利用 Raft 来做数据复制,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到 Group 的多数节点中。
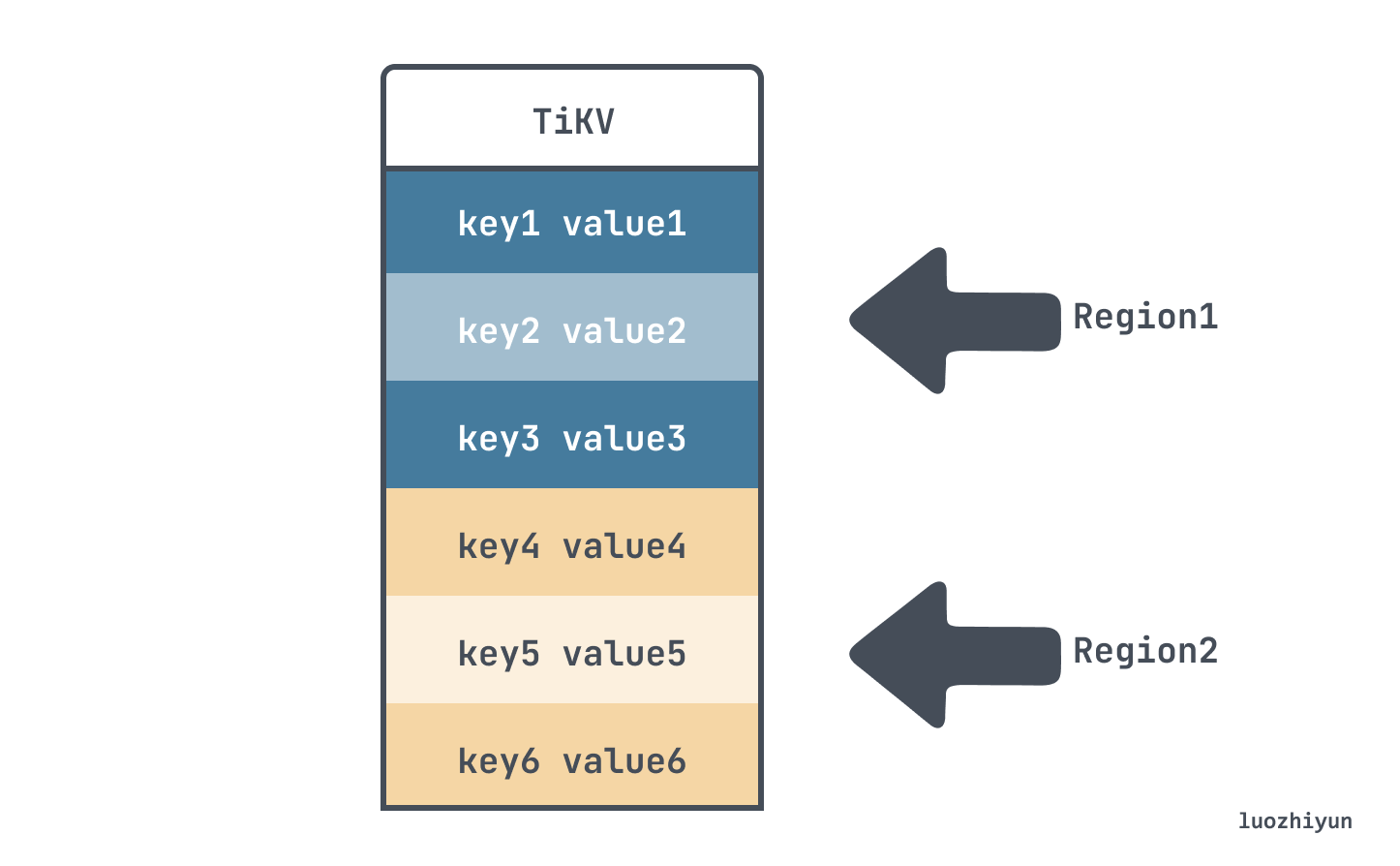
TiKV 会将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,我们将每一段叫做一个 Region,并且我们会尽量保持每个 Region 中保存的数据不超过一定的大小。每一个 Region 都可以用 StartKey 到 EndKey 这样一个左闭右开区间来描述。
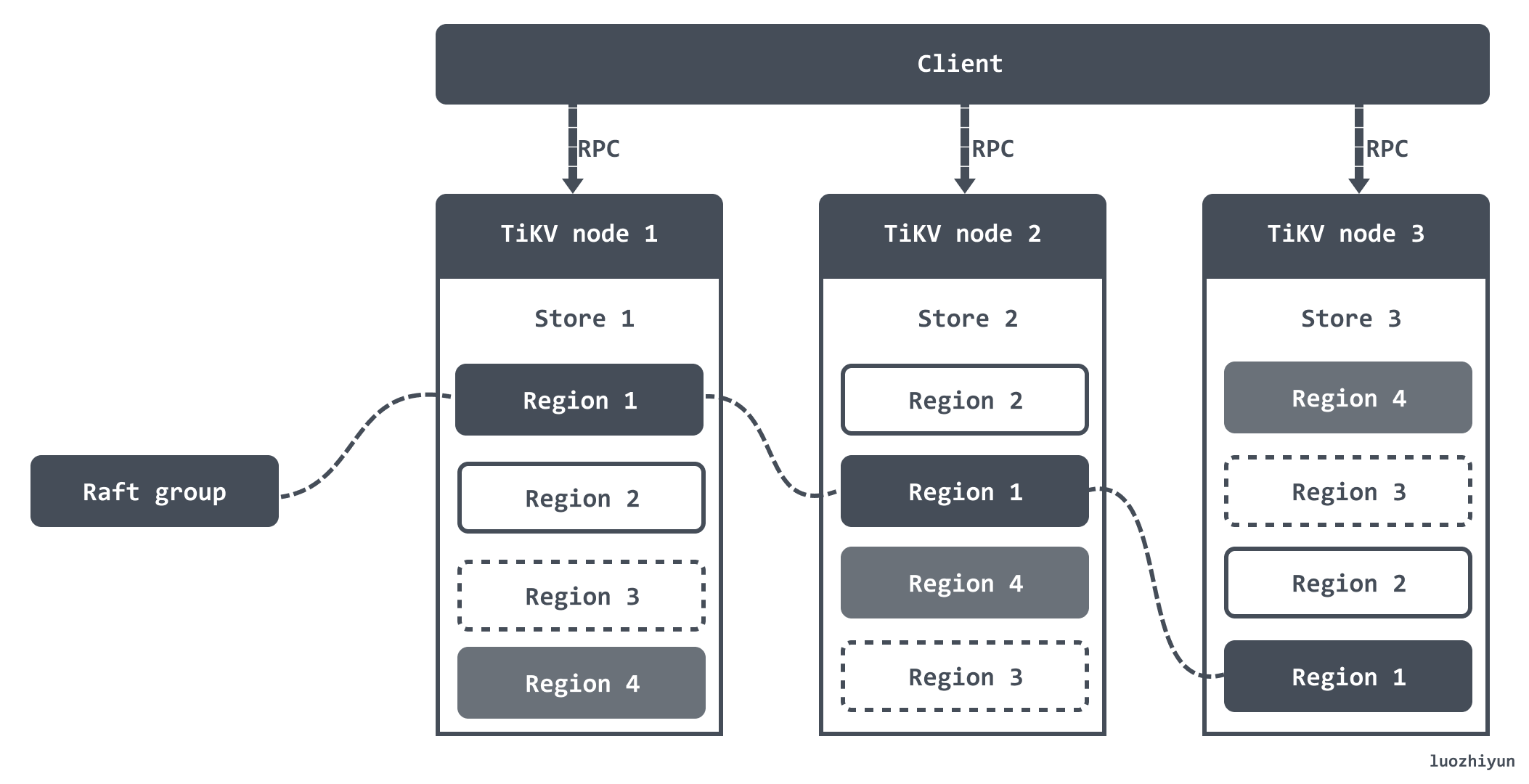
将数据划分成 Region 后,会以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多,然后以 Region 为单位做 Raft 的复制和成员管理。
集群可用性&数据一致性的保障
要做到集群以及数据的保障,那么就离不开信息收集,也就是需要知道每个 TiKV 节点的状态以及每个 Region 的状态。
简单来说,首先是信息收集,然后根据收集的信息生成调度,最后执行调度。
对于信息收集来说,TiKV 会主动向 PD 定期汇报两类消息:
-
每个 TiKV 节点会定期向 PD 汇报节点的整体信息
这个信息包括 TiKV 节点的总磁盘容量、可用磁盘容量、承载的 Region 数量、是否过载等等;
-
每个 Raft Group 的 Leader 会定期向 PD 汇报信息
这个信息主要是 Raft 相关的,比如 Leader的位置、Followers 的位置、掉线 Replica 的个数等等。
PD 不断的通过这两类心跳消息收集整个集群的信息,再以这些信息作为决策的依据生成调度计划。
比如,PD 通过某个 Region Leader 的心跳包发现这个 Region 的 Replica 数量不满足要求时,需要通过 Add/Remove Replica 操作调整 Replica 数量。那么可以通过这些信息判断是某个节点掉线还是管理员调整了副本策略。
除了上面这个 Replica 数量问题还有如:让Leader 数量在 Store 之间均匀分配、副本在 Store 之间均匀分配、访问热点数量在 Store 之间均匀分配等等。
最后根据调度的信息,将调度策略发送给 TiKV 的 Region Leader 执行,需要注意这里的调度策略只是给 Region Leader 的建议,并不保证一定能得到执行,具体是否会执行以及什么时候执行,由 Region Leader 自己根据当前自身状态来定。
Key-Value 映射数据
由于 TiDB 是通过 TiKV 来存储的,但是关系型数据库中,一个表可能有很多列,这就需要将一行中各列数据映射成一个 (Key, Value) 键值对。
TiDB 对每个表分配一个 TableID,每一个索引都会分配一个 IndexID,每一行分配一个 RowID(如果表有整数型的 Primary Key,那么会用 Primary Key 的值当做 RowID),其中 TableID 在整个集群内唯一,IndexID/RowID 在表内唯一,这些 ID 都是 int64 类型。
按照如下规则进行编码成 Key-Value pair:
Key: tablePrefix{tableID}_recordPrefixSep{rowID}
Value: [col1, col2, col3, col4]Unique Index 数据,会按照如下规则编码成 Key-Value pair:
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: rowID普通二级索引,会按照如下规则编码成 Key-Value pair:
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID
Value: null比如有这样一张表:
CREATE TABLE User (
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
KEY idxAge (Age)
);表中有三行数据:
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30那么这些数据在 TiKV 上存储的时候会构建 key。对于主键和唯一索引会在每条数据带上表的唯一 ID,以及表中数据的 RowID。如上面的三行数据会构建成:
t10_r1 --> ["TiDB", "SQL Layer", 10]
t10_r2 --> ["TiKV", "KV Engine", 20]
t10_r3 --> ["PD", "Manager", 30]其中 key 中 t 是表示 TableID 前缀,t10 表示表的唯一ID 是 10;key 中 r 表示 RowID 前缀,r1 表示这条数据 RowID 值是1,r2 表示 RowID 值是2 等等。
对于不需要满足唯一性约束的普通二级索引,一个键值可能对应多行,需要根据键值范围查询对应的 RowID。上面的数据中 idxAge 这个索引会映射成:
t10_i1_10_1 --> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null上面的 key 对应的意思就是:t表ID_i索引ID_索引值_RowID 。
Reference
https://pingcap.com/zh/blog/tidb-source-code-reading-6
https://pingcap.com/zh/blog/tidb-source-code-reading-10
https://pingcap.com/zh/blog/tidb-source-code-reading-3
https://www.luozhiyun.com/archives/609
https://pingcap.com/zh/blog/tidb-source-code-reading-19
https://asktug.com/t/topic/1495
https://pingcap.com/zh/blog/percolator-and-txn
https://pingcap.com/zh/blog/tikv-source-code-reading-12
https://github.com/tikv/sig-transaction/tree/master/design/async-commit
https://pingcap.com/zh/blog/async-commit-principle
https://zhuanlan.zhihu.com/p/59115828
http://mysql.taobao.org/monthly/2018/11/02/
https://pingcap.com/zh/blog/best-practice-optimistic-transaction
https://pingcap.com/zh/blog/tidb-transaction-model
https://pingcap.com/zh/blog/tidb-internal-1
https://pingcap.com/zh/blog/tidb-internal-2
https://pingcap.com/zh/blog/tidb-internal-3
https://pingcap.com/zh/blog/pessimistic-transaction-the-new-features-of-tidb
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK