

聊聊服务端架构演化
source link: https://www.lanindex.com/%e8%81%8a%e8%81%8a%e6%9c%8d%e5%8a%a1%e7%ab%af%e6%9e%b6%e6%9e%84%e6%bc%94%e5%8c%96/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

聊聊服务端架构演化
我们先从一个需求入手:需要实现一个游戏好友系统。
比较常规的做法:
(为了更清晰讲述,这里屏蔽了一些模块细节:比如接入层、服务器框架、储存读写分离、分表、分桶、集群模式等,也未考虑异地互备与大陆外数据等细节)
简单的名词解释:
- GameServer:用来接收、处理客户端常规请求的模块(根据游戏是否分区部署策略会有所不同,这里简化成单分区);
- FriendServer:用来处理所有和好友相关内容的模块,可以多进程部署进行负载均衡;
- RoleBaseInfo:用来储存用户简要信息;(这里可以简单理解成需要在好友列表上展示的信息)
那么整个处理流程如下:请求从GameServer转发至FriendServer,FriendServer根据好友列表信息拉取对应好友的RoleBaseInfo返回至客户端显示。
将来会引发的问题:
随着用户的增多,每次请求通过FriendServer去DB实时拉取系统整体负载会加大。
解决方案:所以为了成本考虑增加缓存,牺牲一定的实时性,空间换时间的策略。
新流程接入了缓存机制会把好友数据做缓存,分钟级定期更新(缓存也可以放GameServer,可以减少内网带宽消耗,但是造成模块边界模糊)。
将来会引发的问题:
好友有部分数据对实时性状态很高,比如当前状态(在线,离线,当前在干什么),这部分数据更新延迟很高是不能接受的。
解决方案:将RoleBaseInfo里面的状态数据做拆分,将这部分实时性要求高的数据单独处理。
- RoleStatusInfo:用来存储用户当前状态的数据;
那么流程会变成,每次请求的时候会去拉取RoleStatusInfo用作状态更新,甚至对于重要的状态需要内部建立Push机制达到实时的效果。
将来会引发的问题:
随着项目的持续运营与用户量级增大,即使有好友上限的约束整体好友的数据池也会不断增大,系统整体压力也会随之提高,虽然可以靠增加机器撑住,但是需要进一步优化控制成本。
解决方案:引入数据的冷热分离,根据一定规则只更新热数据。
冷数据(可以简单理解成长期未上线,已经流失的玩家)存放在成本较低的存储里,每次Cache按规则更新热数据,减少带宽与计算消耗。
自此一个还算完善的游戏好友系统演化完成了。
我们可以看到,主导这些演化的主要原因是用户量,然后新的方案会引入新的问题(缓存导致的时延),结合具体业务再解决这些问题。到了一定阶段后又会因为用户量的进一步凸显问题(其实更多的是成本与效率问题),然后再次的演化。
那么为什么不直接开始就设计一个“完善”的方案?
其实这里涉及到二个问题:成本和人
先说成本
如果我们拥有微信或者支付宝或者抖音的架构镜像,支撑十亿级的DAU,这肯定是没有问题的。但是庞大的机器成本、运维成本、开发成本是否真的值得,尤其你的产品可能只有几万的DAU。
除了这些还有从0到1的过程,这个过程花费时间与复杂度是成正比的。参考下面这个不太严谨的图表:
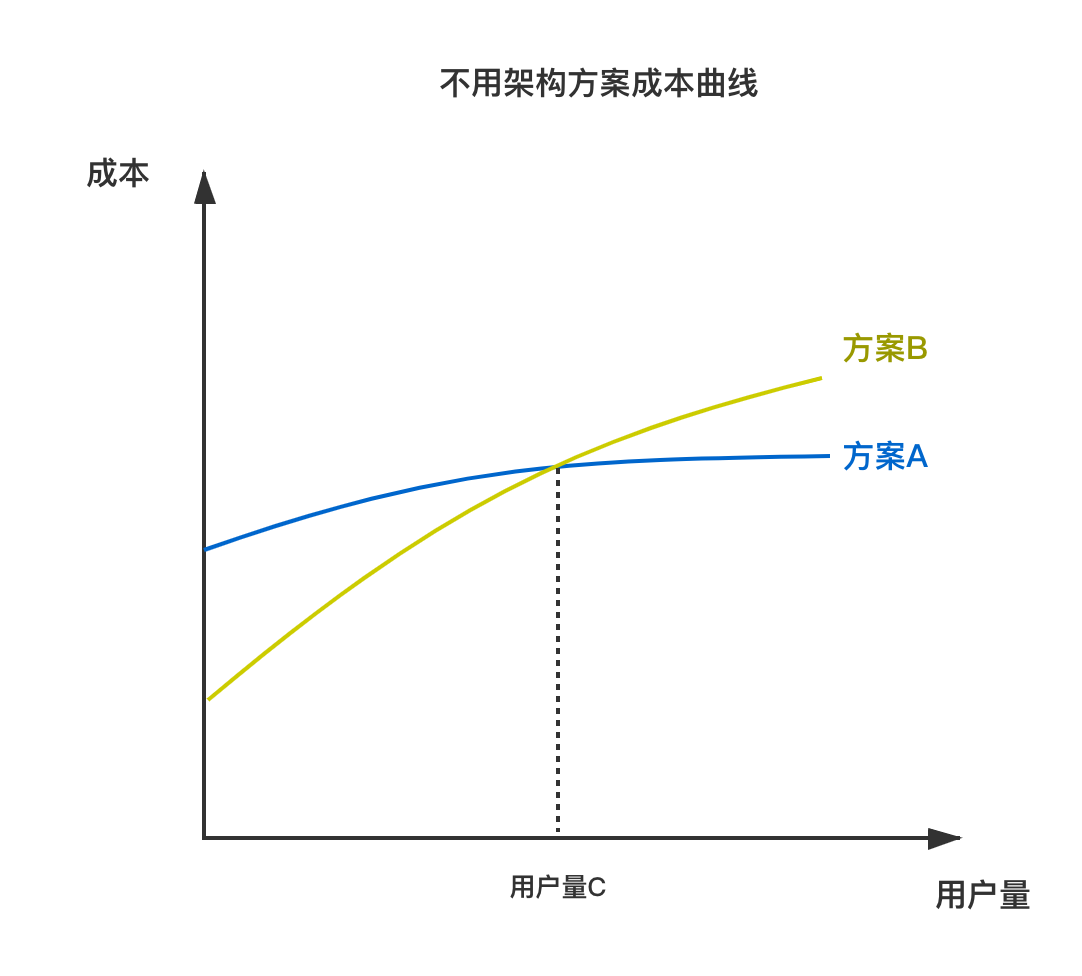
- 方案A:开始就预期朝千万DAU来设计,初使成本较高,但是随着用户量增加会减少一些架构变迁的成本;
- 方案B:百万DAU的方案,开始成本较低,但是会因为用户量增加,会有一些架构变迁成本导致成本曲线较陡;
- 用户量C:方案B成本超过方案A的用户量转折点;
这里有一个很微妙的博弈,是把筹码投入到更后期(方案A),还是着重眼前(方案B),因为毕竟要达到用户量C方案A才凸显优势。
当然以上的数据可能太理论了,未考虑开发人员因素,其实这里想表达的意思是在开始设计上不能过度,结合实际情况(资金,预期用户量,开发人员素质等等)进行落地。
不少企业服务端招聘需求里面会有“有成功项目的优先”、“有大型项目经验的优先”这类的描述。这些内容其实简单归纳成:服务过大数量级用户的优先。
从招聘这个事情来看:企业招一个人,如果有了上述经历是会是很好的背书,为什么?因为前后几个小时的面试无法全面考察一个人,那么这些亮点将为他/她兜底加分。
站在企业角度上来说:如果我要设计一个百万DAU的产品,那么我最好找一个拥有百万甚至千万DAU经验的开发,这样才稳,才能在未来随着业务发展的架构演化中避免问题。
这虽是求稳,也是人性的体现。
聊到企业,再说说企业
前段时间听了字节一场技术沙龙,分享了字节跳动研发架构的演化(链接点这里,活动已经结束)。这里配一张很有意思的图:

现在大厂都在内部开发使用容器(Container)甚至发展无服务器架构(ServerLess),为什么?
- 我们先看从物理机(Physical)到虚拟化(Virtualisation):Virtualisation能做到操作系统级的隔离,更容易的控制Physical的资源分配,并且提供一定的安全性;
- 从虚拟化(Virtualisation)到云计算(CloudCompute):CloudCompute提供了更强的手段对Virtualisation与Physical的资源进行调度和管理,并且进行了服务分层,出现了软件即服务(SaaS),平台即服务(PaaS),基础架构即服务(laaS),应用程序平台即服务(aPaaS)这些细分概念;
- 从云计算(CloudCompute)到容器(Container):Container能做到进程级的隔离,占用系统资源更少,并且出现了Kubernetes容器编排工具,能很好的与CloudCompute结合,同时实现了Java的目标,编译一次,运行所有;
- 从容器(Container)到无服务器架构(ServerLess):ServerLess能做到函数级的隔离,底层技术还是基于Container;
整个演化过程其实分为两个分支:隔离与治理。其实也是一个遇见问题解决问题,又有新问题,继续解决的演化过程。
回到企业角度,对企业有什么意义?成本。使用Container能节省大量成本,无论是开发人员、运维人员、还是机器的成本。
那是不是无脑选择容器(Container)做企业级的解决方案?
并不是,这个需要根据公司具体业务和人员来看,尤其一些公司还有“祖传代码”的情况下。
虽然现在云服务很发达,国内的云服务也都基本提供了Container相关服务,但是在选用Container还是需要考虑以下几点:
- 成本,云服务成本不低,自建的话根据使用方式会有区别,但也不少;
- 能否真正减少人工参与编译环境,运行环境的搭建与问题排查时间;
- 业务是否合适,比如生产环境的数据库服务,或者对网络要求特别高的场景就不太适合用Container;
很久没写博客了,这篇是对服务端架构演化的一些个人总结与思考。我理解演化的本质就是发现问题,解决问题的循环,这个不光在IT行业中,其他各行各业也是如此。重要的是你用什么方式来解决问题,能不能形成方法论或者通用方案供他人使用。
(全文结束)
转载文章请注明出处:漫漫路 - lanindex.com
Leave a Comment Cancel reply
Your email address will not be published.
在此浏览器中保存我的显示名称、邮箱地址和网站地址,以便下次评论时使用。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK