

Is it Possible to Make Machine Learning Algorithms without Coding?
source link: https://towardsdatascience.com/is-it-possible-to-make-machine-learning-algorithms-without-coding-cb1aadf72f5a
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Is it Possible to Make Machine Learning Algorithms without Coding?
I prepared a simple application to show you how this is possible with a little help of an interesting tool called Orange.
I am a firm believer that the previous step to making your own Machine Learning Algorithms or any predictive model with code is understanding the basics and knowing how to rationally interpret the model.
Many times we believe that building a machine learning or data analytics model is such a difficult task when we associate it with coding. There you have another obstacle to sort! But that’s not necessarily the case if you focus on understanding the theory behind it in the first place. Here’s a little guide to help you go through that process.
Table of Contents:
1. Importance of Data Analytics. (1 min read)
2. Machine Learning Contribution. (1 min read)
3. Understanding the Basics: Data-validation process, imbalanced datasets, supervised and unsupervised methods. (2 min read)
4. Introduction to Decision Trees and Random Forest. (2 min read)
5. Application using Orange. (6 min read)
1. Why Data Analytics?
Thousands of data sources exist nowadays from which we can extract, transform and load data ranging stock prices, medical records, surveys, population census, and logged behaviors, among others. Also, there’s a huge variety of fields in which we can apply these techniques and a wide range of useful applications inside each field, such as fraud detection, credit scoring and asset allocation in relation to the finance domain.
But how much can I contribute with this knowledge to a company? A LOT! Just put yourself in the situation of a credit risk analyst at a bank. “Should I lend money to this client or should I reject his application? How much information should I request him or her without risking to lose the interest rate associated with the lending? Are his periodical payslips enough? Or should I also ask him credit records from other financial institutions to guarantee the repayment?”. Data Analytics and machine learning models play a major role in automating routine tasks such as this one, handling bulks of information and optimizing metrics to enhance the business sustainability.
The ultimate goal is to make meaningful and interpretable inferences about data, extract relationships between variables and detect patterns to forecast the outcome of a variable.
Let’s see the case of tech companies. In order to perform and grow their business value, their focus must be set on improving business metrics and delighting users. Data analysis provides these companies with insights and metrics that are constantly changing and that allow them to build even better products. The mission: Understand users, how the offered product fits into their life, what motivates them and how was their experience in order to improve it. All this and much more can be attained with the use of data.
2. What role plays Machine Learning in all of this?
Truth to be told, there’s probably not a need for Machine Learning in your company budget. Why is that? Because the majority of the companies need improvements in processes, customer experience, costs reductions and decisions making, all of which can easily be attained with the implementation of traditional data analysis models, without the need of recurring to more complex ML applications.
Despite the above mentioned, traditional data analytics models are static and have limited use with fast-changing unstructured data inputs that are rapidly and constantly suffering changes. That’s when the need for automated processes with capacity to analyze tens of inputs and variables emerges.
In addition, the resolution process differs greatly between both methods, as ML models focus on receiving the input of a determined goal from the user and learning from the rapid-changing data which factors are important in achieving that goal, instead of being the user who sets the factors that will determine the outcome of the target variable.
Not only it allows the algorithm to make predictions, but also compare against its predictions and adjust the accuracy of the outcome.
3. Understanding the Basics:
Data-validation process:
In the process of performing a machine learning algorithm and selecting the best way in which we can analyze data, we split it into two subsets: training subset and testing subset, in order to fit our model on the train data and make predictions on the test data as an emulation of real-life problems.
How we perform the splitting of data is not trivial as we don’t want to bias any of the subsets. For e.g., while processing data of a sample of a company’s clients, we don’t want to split train and test subsets without including an equally-represented sample of each category in both of the subsets. As a result, we say that data splitting must be performed in a stratified way and randomly.
Imbalanced Datasets:
Data is said to be imbalanced when instances of one class outnumber the other(s) by a large proportion. In the process of data classification, the model might not have enough instances of a class to learn about it, and as a result will bias the analysis.

There are several sampling methods to deal with this issue including Undersampling, Oversampling, Synthetic Data Generation and Cost Sensitive Learning. In this article, I’ll dig into Oversampling moving forward.
Supervised and Unsupervised Models:
- Supervised Learning: Consists of manually telling the model what labels we want to predict for the training dataset.
- Unsupervised Learning: As we don’t know the labels, we ask the model to group elements from the dataset based on the more distinct features each element has.
4. Introduction to Decision Trees and Random Forest
Decision Trees algorithms are structured as a hierarchy of questions and answers about the observations in a dataset in order to help the model to make classifications. An example would be the following scheme, which is a simplification of a basic structure of questions to determine the salary of a Baseball player:
Decision Tree Example— Image by AuthorIn the graph, we see the representation of a two-level decision tree in which the first-step classification is related to the number of years as a professional player that an individual had, and conditional to the response to that question is the number of hits per season. In the example, the determination of the salary of each player in the league will be made following the guidelines of this model.
The most suitable model will be the one that better represents the actual relation among the variables under study (if the salary of a baseball player and years of experience were linearly correlated, probably a linear regression would be the most suitable model to use). Random Forest is one of a variety of techniques that allow us to represent more complex relations between variables that are not necessarily linear, exponential or logarithmic.
For e.g., in the scenario of having a player with less than 4.5 years of experience, the decision-making of his salary is uniquely dependent on his professional experience, not on the amount of hits.
The ultimate goal of the scheme of questions is to split the observations in a way that the resulting groups are as different from each other as possible. Observations will finally be organized in sections according to which different conditions are met:

Random Forest
Classification mechanisms utilizing Decision Trees are based on “ensembles” of a large number of individual trees. Let’s use a simple metaphor to illustrate the concept:

Each blind man has a task: Deduce the animal based on the part of the body that he touches. For the purpose of the article, the metaphor would mean that each blind man is a model and the elephant is the value to predict. Were they to be all touching the same part, they‘d probably deduce incorrectly which is the animal. As a consequence, it would be better to have them distributed to be able “learn” from different sets of “information”. Furthermore, we’ll try to combine the models (or blind men), that independently are not effective in their predictions, in order to optimize the output of the model.
Instead of touching a part of an animal, the model will actually analyze a selected dataset (with reposition of samples), obtained with Bootstrapping. Unfortunately, this method doesn’t guarantee that the selected datasets are not correlated mainly because “strong” predictors generally prime over other indicators. That’s where Random Forest comes to play as its main feature is randomly selecting datasets ignoring “strong” predictors.
5. What tool are we going to use?
Orange is an open-source tool that allows us to perform a wide range of data-manipulation tasks such as data visualization, exploration, preprocessing and modeling creation without the need to use Python, R or any other piece of code. It’s ideal if you’re taking your first steps in this long learning-path.
It’s also suitable for more advanced users as it includes Python widgets to input Python scripts to complement the widgets it has to offer. Go to the following link to proceed with the installation of the program.
1. Open a new file

2. Drag the File widget to the canvas and browse the dataset in your local server by double clicking in the File widget.
In this case, I’ll be utilizing a dataset containing a sample of 150.000 clients of a financial institution. The column “SeriousDlqin2yrs” will be the target variable upon preparing our model.
You can find the dataset in this link to my GitHub.
Note: Don’t worry about the gray “Apply” button as it’s only used to confirm changes made to the values in each feature, for e.g. after modifying “Role” or “Values” tabs.
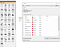
3. Visualize default features and distributions of the dataset
Drag the “Feature Statistics” and “Distribution” widgets from the “Data” and “Model” and “Visualize” from the left-side panels. With these tools, you’ll get a better view of the descriptive statistics of each feature in the dataset, such as mean, dispersion, minimum, maximum and missing values.


4. Select Rows
Filter columns data to avoid incorrect values that interfere in the accuracy of the analysis. We can set conditions for the features such as values below X amount of equal to Y amount.
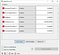
5. Select Columns
Select important features for your analysis from the original dataset and create a new dataset with only those features utilizing the widget “Select Columns”. This is the widget in which you can determine selected columns and indicate target variable for further analysis.
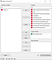
6. Data Sampler
Data Sampler widget is used to split the filtered dataset into train and test subsets. In Orange’s interface we can select a “Sampling Type” to input our desired sampling method. Particularly, I selected 70% of the entire data to be included as “Train sample” leaving the remaining 30% as “Test sample”. As mentioned earlier in the article, data-selection for the subsets is performed randomly and with stratified samples, as Orange’s interface reflects.

7. Imbalanced Dataset Resolution
In order to solve the Imbalanced Dataset problem explained above, I decided to perform the Oversampling technique instead of a SMOTE as I believe that the widget for this feature is not included in Orange.
1 . Select “Default” values, which are the minority class from the training subset, as we want to randomly replicate the observations to balance the dataset. In the visualization, you will see that links or edges between the widgets have legends, in which you must indicate what data you want to pass to the “receiving” widget. In this case, “Select Rows” widget contains a Train subset, from which “Matching data” or “Defaults” will be sent. On the other hand, we find “Unmatched data” , which are “No defaults” from the Train subset, that are directly sent to the “Concatenate ”widget.
An advantage of Oversampling method is that it leads to no information loss in relation to Undersampling. Its disadvantage is that, since it simply adds replicated observations in the original data set, it ends up adding multiple observations of several types, thus leading to overfitting.
2. Data Sample widget randomly replicates a fixed number of observations
3. Concatenate widget joins both new observations with “old” ones, in order to finally obtain a balanced dataset to submit to our model.

8. Perform prediction on balanced train dataset with Random Forest
Let’s move on to the fun part: Modeling Random Forest. To perform this task, select the widget “Random Forest” from the “Models” sections and link it to the balanced train dataset.
We will test the “depth ” Hyperparameter in an effort to optimize the model. Hyperparameters are a sort of “setting ” of the model that can be adjusted to enhance performance. In the case of Random Forest, Hyperparameters include:
- Number of decision trees in the forest
- Number of features considered by each tree when splitting a node, also known as “depth” or “growth” of the model.
As it’s shown in the images below, the first model has a 3-tree depth limit and the second has no limit in how “deep” the model will grow in the optimization.
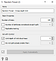
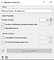
9. Test & Score widget
This widget is used to evaluate the results of the model based on the training dataset. It will perform cross-validation based on the number of folds defined. These folds are the number of subsets created from the train sample which will run on rounds to evaluate the whole dataset.
The resulting interface is a listing of the utilized models as a comparison of performance with the metrics obtained. In the next step I’ll explain the meaning of each metric.
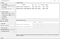
10. Confusion Matrix
To simplify the exercise, I’ll explain using the most effective model from the two we ran. Confusion Matrix is a performance-measurement tool that it’s utilized to evaluate a machine learning model based on predetermined metrics. The output is a table with a combination of values as follows:

- True Positive results (TP): The model correctly predicted the positive outcome (e.g. It predicted it would “Not Default” and ended not doing so).
- True Negative results (TN): The model correctly predicted the negative outcome (e.g. It predicted it would “Default” and ended doing so).
- False Positive results (FP): The model failed to predict the positive outcome (e.g. It predicted it would “Default” and ended not doing so).
- False Negative results (FN): The model failed to predict the negative outcome (e.g. It predicted it would “Not Default” and ended doing so).
This Matrix is included as a widget in Orange and has the following interface:
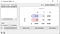
It is extremely useful for measuring Recall, Precision, F1 Score, Accuracy and AUC-ROC Curve:
- Accuracy: Proportion of predictions that the models successfully classified.

- Precision: Portion of correctly predicted outcomes among all positive predictions.
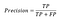
- Recall: Portion of positive outcomes that the model predicted correctly.

- F1 Score: It’s a combination of both precision and recall, also used to measure test’s accuracy.

Conclusion
The motivation of this article was to show how to apply sophisticated Machine Learning algorithms without a single line of code, but I additionally ended up considering it as a theory facilitator that hopefully serves as a motivator for everyone that reads this post.
References
- [1] Imbalanced Classification Problems.
- [2] Orange Workflows from the official website.
- [3] Supervised and Unsupervised Learning - Sklearn Documentation.
- [4] Sarang Narkhede, Understanding Confusion Matrix (2018), Towards Data Science.
- [5] Gareth James, Trevor Hastie and Robert Tibshirani, (2014), “An Introduction to Statistical Learning”
Thanks for taking the time to read my article! Any question, suggestion or comment, feel free to contact me: [email protected]
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK