

利用这个开源工具你也可以为 PDF 添加目录
source link: https://zhuanlan.zhihu.com/p/432097624
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

利用这个开源工具你也可以为 PDF 添加目录
作者:王轩Bryan
对于需要归档收集的人而言,PDF 无疑是一个绝佳的选择,但有些我们转换或下载的 PDF 可能出现没有目录的情况,这对于快速查找十分的不便。
本文针对影印版文件无效,一个简单的测试方式是打开文件尝试选择/复制,如果不可以选择或复制出来有错字或多余的空格则本文无效
准备
本次使用的工具是 pdf.tocgen,这是一个能够为 PDF 自动生成目录的开源命令行工具集,其由 pdfxmeta、pdftocgen、pdftocio 三个工具组成。
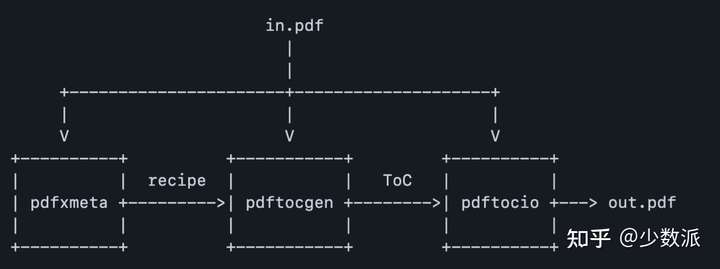
这是来自官网的介绍图,in.pdf 是我们原始没有目录的 pdf 文件,而 out.pdf 是经过工具处理后增加了目录的新文件。
pdf.tocgen 工具集的原理是 PDF 中的「标题」与「正文」的格式一般是不一样的,同样,标题的不同层级格式一般也是不一样的,pdf.tocgen 则提供了一套工具来利用这一差异半自动的生成目录。该工具集有三个软件组成,pdfxmeta 可以利用文字来查找对应的格式信息,pdftocgen 则是利用 pdfxmeta 输出的格式信息生成目录的描述,而 pdftocio 则是利用 pdftocgen 生成的目录描述为我们的原始 pdf 增加目录并输出新的 pdf 文件。当然,这么说过于抽象了一点,本文中我将使用一个真实例子(就发生在昨天,还很热乎)进行演示,相信你看完会发现听起来虽然很麻烦,但是真的上手操作起来既简单又强大灵活,可以覆盖几乎全部的需要目录的场景。
下载 pdf.tocgen 工具集
pdf.tocgen 是由 Python 编写、在 pypi 上发布的工具,因此我们需要先配置 Python 的环境然后下载这一程序。
不要被 Python 吓到,在本例中你不需要编写 Python 的程序,而只需要配置好 Python 的运行环境即可。Python 环境的配置不在本文的范围内,但你也不用担心,因为我为了今天这篇文章特意另写了一篇文章(买一送一 )以力求让非技术人员也可以很轻松的配置好环境,如果你不会配置敬请移步 为非技术人群准备的 Python 安装指南 阅读,待配置好后再继续本文操作。
无论你是 Windows 还是 Mac 用户,在配置好 Python 环境后安装只需要执行命令(执行命令的方式在环境配置文档中已经写明,简单来说就是 Windows 用户使用 Anaconda Promt(miniconda3)、Mac 用户使用系统自带的终端,然后输入下面的内容并按回车,输入时请注意拼写、英文标点、空格均不要出错)
pip install pymupdf==1.18.6 pdf.tocgen==1.2.3如果你是 Mac 用户,在终端下输入下面的命令来验证下是否安装成功
which pdfxmeta
which pdftocgen
which pdftocio你的输出与我的可能不一样,但只要不出现「not found」就没有问题
如果你是 Windows 用户,在 Anaconda Promt 下输入下面的命令来验证下是否安装成功
where pdfxmeta
where pdftocgen
where pdftocio你的输出与我的可能不一样,但只要不出现「无法找到」就没有问题
下载示例文档
为了便于你的实操,我提供了一个没有目录的 pdf 文档供你练手测试,你可以从 这里下载(提取码:ddxi)。
这篇文档来源是一个小姐姐的学习笔记,如果对投资感兴趣可以看看,另外,想要她微信可以给我发红包获得
可以看到,正常我们打开是没有目录的
(在 Mac 下的「预览」,请打开侧边栏并选择查看目录)
(在 Windows 下的 Edge,如果有目录会在页码左侧展示出显示目录的按钮,如果没有就代表没有目录)
而添加目录以后的效果则是
效果是不是很棒 让我们来一步步的生成吧
提取元数据
如果你是 Windows 用户,请在打开 Anaconda Promt 后首先输入
set PYTHONUTF8=1以避免下面的操作中出现编码问题
观察这篇文档,可以发现它的标题层级还是很简单就可以看到的
- 一级标题:「第一讲 证券投资基础」
- 二级标题:「一、了解并掌握证券投资这门艺术 」
- 三级标题:「 投资者适应性」
我们利用 pdfxmeta 工具依次获得它们的信息,它的最简单使用是
pdfxmeta -p 页码 -a 层级 文件名 "要查找的内容"对于一级标题而言,我们所使用的是
pdfxmeta -p 1 -a 1 30堂证券投资通识课_无目录版.pdf "证券投资基础"-p 1是代表这句话在第一页-a 1是代表这是一级标题30堂证券投资通识课_无目录版.pdf是我们这个文件的名字"证券投资基础"是一级标题的内容
输出结果如下
我们在同目录下创建一个名为 recipe.toml 的文件(事实上,文件名是可以任意选择的),然后将这个文件拖动到 Sublime Text 4(或其他任何你喜欢的文本编辑器)中打开,并将刚刚输出的内容粘贴进来
[[heading]]
# 第⼀讲 证券投资基础
level = 1
greedy = true
font.name = "Unnamed-T3"
font.size = 24.000001907348633
# font.size_tolerance = 1e-5
# font.color = 0x24292e
# font.superscript = false
# font.italic = false
# font.serif = false
# font.monospace = false
# font.bold = false
# bbox.left = 50.5
# bbox.top = 44.13671875
# bbox.right = 271.6211242675781
# bbox.bottom = 72.80078125
# bbox.tolerance = 1e-5然后我们输入 pdftocgen 30堂证券投资通识课_无目录版.pdf < recipe.toml 可以发现所有的一级标题都已经被提取出来了
细心的你可能发现了,我们最初写的一级标题内容是「第一讲 证券投资基础」而执行 pdfxmeta 命令时仅传递了「证券投资基础」,吞掉了「第一讲 」。这是因为示例 PDF 中的空格似乎有一些问题,如果写全了就无法匹配到任何结果。幸运的是,pdfxmeta 支持进行部分匹配,因此在输入全部的标题无法匹配到后我选择了使用标题中的一部分。
另外,也正是因为 pdfxmeta 使用了部分匹配,因此在你未来处理你自己的 PDF 时可能出现你所输入的关键字在该页面内重复出现多次,在本文的示例文档中,如果我们关键词选用「证券投资」而非「证券投资基础」,那么就会输出两个可能(可以认为输出的每个 [[heading]]是一个「可能」)
根据 [[heading]] 后的注释(这个输出格式是 TOML, # 后面的内容是注释,这个注释展示了查找到的内容所在的行的内容),我们使用「证券投资」作为搜索目标时找到了两个可能 —— 「第⼀讲 证券投资基础」和「⼀、了解并掌握证券投资这⻔艺术 」。在出现多种可能的情况下我们只将我们想要的部分复制到 recipe.toml 文件,而「我们想要的部分」是指的从内容注释上的 [[heading]] 开始(包括这个 [[heading]])到下一个 [[heading]] 之前(不包括后面的这个 [[heading]])的内容。你可以自己尝试下定位要复制的内容,最终应该是和最初利用「证券投资基础」进行搜索时的内容一致的
那么,类似的,我们查找二级标题 —— 「⼀、了解并掌握证券投资这⻔艺术 」,我们使用如下命令搜索
pdfxmeta -p 1 -a 2 30堂证券投资通识课_无目录版.pdf "⼀、了解并掌握证券投资这⻔艺术"-p参数依然是1,因为这个标题仍然在第一页-a参数则换成了2,因为这次是二级标题了
这里考虑到 Windows 用户因此搜索时没有加 Emoji,在 Mac 上加上使用「⼀、了解并掌握证券投资这⻔艺术 」也可以正常搜索到,同时你也可以尝试利用「证券投资」这一关键字来搜索并结合我上面说的出现多个结果时的筛选方式来找到正确的内容
将输出复制并粘贴到刚刚的 recipe.toml 文件的后面,目前这个文件为
[[heading]]
# 第⼀讲 证券投资基础
level = 1
greedy = true
font.name = "Unnamed-T3"
font.size = 24.000001907348633
# font.size_tolerance = 1e-5
# font.color = 0x24292e
# font.superscript = false
# font.italic = false
# font.serif = false
# font.monospace = false
# font.bold = false
# bbox.left = 50.5
# bbox.top = 44.13671875
# bbox.right = 271.6211242675781
# bbox.bottom = 72.80078125
# bbox.tolerance = 1e-5
[[heading]]
# ⼀、了解并掌握证券投资这⻔艺术
level = 2
greedy = true
font.name = "Unnamed-T3"
font.size = 18.000001907348633
# font.size_tolerance = 1e-5
# font.color = 0x24292e
# font.superscript = false
# font.italic = false
# font.serif = false
# font.monospace = false
# font.bold = false
# bbox.left = 50.5
# bbox.top = 99.22750854492188
# bbox.right = 338.5000305175781
# bbox.bottom = 119.4100112915039
# bbox.tolerance = 1e-5再次输入 pdftocgen 30堂证券投资通识课_无目录版.pdf < recipe.toml 可以发现所有的一级和二级标题都已经被提取出来了,并且标题的层级归属关系也是正确的
那么,就剩下三级标题「 投资者适应性」了,建议你先尝试下利用前面一二级的经验来自己做出这个标题的目录。
你可能已经想出来了,我们的命令是 pdfxmeta -p 1 -a 3 30堂证券投资通识课_无目录版.pdf "投资者适应性",-p 依然没变(因为我们要搜索的内容仍然在第一页)、-a 变成了 3 代表三级标题,搜索内容是没有 emoji 的「投资者适应性」
可以发现这次的输出里面有两个可能性(两个 [[heading]]),这是因为「投资者适应性」这几个字在标题和正文同时出现过,按照最开始介绍的思路,我们仅选用代表标题的,即选择
[[heading]]
# 投资者适应性
level = 3
greedy = true
font.name = "Unnamed-T3"
font.size = 15.000000953674316
# font.size_tolerance = 1e-5
# font.color = 0x24292e
# font.superscript = false
# font.italic = false
# font.serif = false
# font.monospace = false
# font.bold = false
# bbox.left = 50.5
# bbox.top = 145.73126220703125
# bbox.right = 158.927734375
# bbox.bottom = 164.37550354003906
# bbox.tolerance = 1e-5将之追加到我们的 recipe.toml 文件,这也是我们最终生成目录要用的
[[heading]]
# 第⼀讲 证券投资基础
level = 1
greedy = true
font.name = "Unnamed-T3"
font.size = 24.000001907348633
# font.size_tolerance = 1e-5
# font.color = 0x24292e
# font.superscript = false
# font.italic = false
# font.serif = false
# font.monospace = false
# font.bold = false
# bbox.left = 50.5
# bbox.top = 44.13671875
# bbox.right = 271.6211242675781
# bbox.bottom = 72.80078125
# bbox.tolerance = 1e-5
[[heading]]
# ⼀、了解并掌握证券投资这⻔艺术
level = 2
greedy = true
font.name = "Unnamed-T3"
font.size = 18.000001907348633
# font.size_tolerance = 1e-5
# font.color = 0x24292e
# font.superscript = false
# font.italic = false
# font.serif = false
# font.monospace = false
# font.bold = false
# bbox.left = 50.5
# bbox.top = 99.22750854492188
# bbox.right = 338.5000305175781
# bbox.bottom = 119.4100112915039
# bbox.tolerance = 1e-5
[[heading]]
# 投资者适应性
level = 3
greedy = true
font.name = "Unnamed-T3"
font.size = 15.000000953674316
# font.size_tolerance = 1e-5
# font.color = 0x24292e
# font.superscript = false
# font.italic = false
# font.serif = false
# font.monospace = false
# font.bold = false
# bbox.left = 50.5
# bbox.top = 145.73126220703125
# bbox.right = 158.927734375
# bbox.bottom = 164.37550354003906
# bbox.tolerance = 1e-5再次执行命令 pdftocgen 30堂证券投资通识课_无目录版.pdf < recipe.toml,非常完美!
当然,你可能会感兴趣这个 recipe.toml 文件的具体内容含义,欢迎你利用搜索引擎和官方文档自行了解学习,我简单说下经验上的内容
[[heading]]
# ⼀、了解并掌握证券投资这⻔艺术
level = 2
greedy = true
font.name = "Unnamed-T3"
font.size = 18.000001907348633
# font.size_tolerance = 1e-5
# font.color = 0x24292e
# font.superscript = false
# font.italic = false
# font.serif = false
# font.monospace = false
# font.bold = false
# bbox.left = 50.5
# bbox.top = 99.22750854492188
# bbox.right = 338.5000305175781
# bbox.bottom = 119.4100112915039
# bbox.tolerance = 1e-5这是文件中的二级标题的内容(根据 [[heading]] 下的 level = 2 确认层级),可以看到若干的选项 —— font.name font.size font.color等。默认情况下只有 font.name 和 font.size 是「开启」的(可以认为前面不是以 # 开头便为开启),因为通常情况下使用字体(font.name)和字号(font.size)便可以唯一定位好一种大纲类型了,但在某些场景下,我们可能需要依据一些其他的信息来确切定位这组元素和其他类似元素的差异,这些信息可能是字体颜色(font.color)、是否为斜体(font.italic)、是否为粗体(font.bold)等,如需使用可以将对应选项前的 #(井号 + 空格)删除
利用元数据生成目录信息
其实这一步我们之前已经执行过了 —— 就是每次测试的 pdftocgen 命令,它的作用是根据元信息描述(receipe.toml)文件生成目录,具体用法是
pdftocgen PDF文件 < 元信息文件在本例中固定为 pdftocgen 30堂证券投资通识课_无目录版.pdf < recipe.toml,因为我们的 PDF 文件就是下载好的「30堂证券投资通识课_无目录版.pdf」,而元信息描述文件则是上一步创建和维护的「receipe.toml」
而生成的内容则类似
"第⼀讲 证券投资基础" 1
"⼀、了解并掌握证券投资这⻔艺术 " 1
" 投资者适应性" 1
" 追涨杀跌为哪般" 1
" 如何培养⾦融嗅觉" 1
"⼆、股票投资ABC " 1
" 中国股市乱象" 1
" 战前总动员" 2
" 中国股票市场的特殊性" 3
" 中国股市的超凡魅⼒" 3
" 选股ABC⸺⾼⼿教你在股市淘⾦" 3
"三、基⾦投资ABC " 3
" 基⾦⾼⼿具备什么特质" 3
" 我国基⺠为何亏钱" 3
" 基⺠和股⺠的投资⽐较和市场认知" 4
" 如何⽤专业的基⾦经理帮你理财" 4
"第⼆讲 证券投资理论" 4
"⼀、资本资产定价模型 " 4
" 证券投资理论对中国股票市场有什么借鉴意义" 4
" 资本资产定价模型的假设条件" 4
" 资本市场线" 5
" 资本资产定价模型在实际投资中的应⽤β策略" 6
" 资本资产定价模型的局限性" 6
"⼆、有效市场假说 " 7
" 有效市场假说和有效市场类型" 7在 Windows 下由于历史编码问题,命令行中的 Emoji 可能会乱码,可以忽略它,按照下面使用命令保存结果到 toc.txt 文件后使用 Sublime Text 4 打开应该就不会看到乱码了
其格式很简单,由半角双引号括起来的名称 + 页码,而层级是通过「缩进」来表现的,一级标题无缩进、二级标题缩进了 4 个空格、三级标题缩进了 8 个空格,以此类推。
如果真的有极特殊的情形生成的目录无法符合你的期望,你完全可以修改这个文件来自定义。
我们将这个生成的文件保存为 toc.txt,当然,由于相关内容可能很多,选中复制或许会很困难,因此在生成后简单浏览确认没有问题时可以直接执行下面的命令将输出存储到 toc.txt
pdftocgen 30堂证券投资通识课_无目录版.pdf < recipe.toml > toc.txt你可以在执行完该代码后利用 Sublime Text 4 打开 toc.txt 文件查看它的内容是否符合预期
生成带有目录标签的 pdf
pdftocio 是用来依据目录文件(toc.txt)生成带有目录的 PDF 的。其用法是
pdftocio -t 目录文件 -o 输出文件 输入文件- 目录文件就是上一步生成的,我们命名为了 toc.txt
- 输出文件是想让生成的带有目录的 PDF 的保存地址
- 输入文件是我们原始的没有目录的 PDF 文件
在当前的例子中,我们输入
pdftocio -t toc.txt -o out.pdf 30堂证券投资通识课_无目录版.pdf没有任何输出即代表执行成功,这时打开生成的 out.pdf 文件已经可以看到目录啦
写在最后
这一套流程走完,可能第一次会觉得有些难、不适应,但如果用几次熟练掌握以后会发现给 PDF 加目录真的很简单。另外,如果你拥有 Github 账号,欢迎进入 https://github.com/Krasjet/pdf.tocgen 给原作者点个 star,这么好的作品不应该被埋没。也欢迎你将该文章推荐给更多的人。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK