

A Data Pipeline for Go Trains Delay Analysis — ML in Action with Rust
source link: https://towardsdatascience.com/a-data-pipeline-for-go-trains-delay-analysis-ml-in-action-with-rust-b294e80eede9
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

A Data Pipeline for Go Trains Delay Analysis — ML in Action with Rust
Welcome back to Part 3, the final article of this Go Train Delay Analysis series. Previously, we built the UI dashboard and the API integration with the elastic capabilities and deployed it to Heroku, and published it to the Rapid API.
If you just landed on this article, please read Part 1 and Part 2.
This final episode will focus on the ML Engine(pipeline) based on consistently collected data with Rust.
First, let's refresh our overall high-level architecture and data flow.
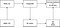
This episode will be based on the functional and no functional requirements to flush out our application design. As part of the objective of this article, we want to show you that, in most of the ML projects:
ML model is ONLY a part of the ML project, a successful ML project SHALL have the overall architecture design, application design, selection of the right model based on the problem you want to resolve, consistent model improvement/learning, model deployment, and overall operation efficiency, which sometimes lead to an operating model (org structure) definition based on your company's context.
Let's start with SFR…
System Functional Requirements
- ML Engine SHALL access the DataStore to use the data to perform the model training consistently.
- ML Engine SHALL can use K fold cross-validate to evaluate a limited data sample of machine learning models.
- ML Engine SHALL uses a suitable model to predict delay mins based on the given dataset. (Note)
- ML Engine SHALL build the model and deploy the model to the target API server.
- ML Engine Built model should integrate with the built API to perform the predict function as #3 and #4.
Non-Functional Requirements
- The ML Engine SHOULD be Scalable for different datastore, in the context/condition of the metadata IS consistently the same.
- The ML Engine SHOULD perform the data training consistently and efficiently. (SLA per defined per data volume growth)
- The ML Engine SHOULD be separated deploy to a different server than API services to reduce the Single Point of Failure, impacting the API operation.
- The ML Engine SHOULD easily maintain to add on a different model for future ML requirements.
- The ML Engine SHOULD run in the user per defined cadences, daily, monthly, weekly, or yearly.
As now we have a good enough requirement capture, the idea behind is to make sure we have the right expectation for your requester, and it may be your client, maybe your business counterpart, and also for us to measure the success.
Note: in the real world requirement in this use case, we may first need to predict if there will be a delay in the pre-given date, but this prediction will be need the dateset for all the Go Train Schedules, which means we will need more data sources and data cleaning and mapping, then we can leverage the supervised classification to predicte.
However, we only focus on the end-to-end ML pipeline for this article. We will spend more time talking about using Rust for Machine Learning in the future.
ML Engine Design
Next, let start mapping the requirement to our application design.
If we carefully read the SFR, #1 is relative with the design pattern, #2 to #4 are the function we need in the Engine, and #5 is the deployment strategy (infra platform relative).
So let's think more profoundly. ML Engine's functions should NOT be different from the datastore we connect, which aligns with the strategy pattern.
According to the strategy pattern, the behaviors of a class should not be inherited. Instead, they should be encapsulated using interfaces. This is compatible with the open/closed principle (OCP), which proposes that classes should be open for extension but closed for modification.
In Rust, the interface is the Trait, which means it holds functions that should be encapsulated to meet our #2 to #4 requirements, with different DataStore as our data source Strategy.
Let's draw for a more detailed understanding.

Let's translate this to our code, which can also meet our #4 in our NFR.
Copyright by AuthorIn the Trait, you can see the sequence of logical order as follow:
Data Extract
This function is responsible for connecting to the database to extract the data, as some target format depends on the storage we decide on.
We have multiple options, such as tradition, Hadoop data lake, cloud storage bucket (s3, ADLS gen2, GCP storage).
For the simplicity of this project, and it seems the data volume is minimal, let's keep it in the csv format.
Another exciting decision point will be how to get the data consistently and efficiently, which meets one of our NFR, such as incremental or batch load.
However, instead of the batch load (SQL select *) and then write to file in a for loop, we will consider using the COPY out for performance needed, why? In general, there are several factors here:
- Network latency and round-trip delays
- Per-statement overheads in PostgreSQL
- Context switches and scheduler delays
Writecosts, if for people doing one write per iterator (you aren't)COPY-specific optimizations for bulk loading.
Read CSV to DataFrame
In the Python ML world, the panda dataframe is the most popular lib for data analysis, which dataframe is one of the critical components. Rust requires more work than Pandas, but Rust is way more flexible and performant. Today, I would like to introduce Polars.
Polars is a blazingly fast DataFrames library implemented in Rust using Apache Arrow Columnar Format as a memory model.
It has some significant benchmarks.
So we will leverage this crate for our dataframe build to prepare the ML model training and build.
Read the CSV — Code Snippet by AuthorML training and model build
We are all set; we have data been loaded to the file system as csv, we read the file to the dataframe. Next will start our ML model selection and training.
Rust has some perfect and handy ML crates/frameworks, most of which you can find here.
My choice will be the SmartCore, a comprehensive library for machine learning and numerical computing with Rust for our use case. The library provides linear algebra, numerical computing, and optimization tools and enables a generic, powerful, yet still efficient approach to machine learning.
Based on our SFR, we want to predict the delay mins based on the pre-given dataset. The algorithms we will focus on should be Linear Regression, a statistical supervised learning technique to predict the quantitative variable by forming a linear relationship with one or more independent features.
For SmartCore, to train the Linear Regression model based on our dataset. It will need 2 DataFrames. One is features, which identifies and selects a subset of the most relevant input variables; the other is the prediction target.
Get feature and target — Code Snippet by Author.Once we have both feature and target dataframe, the next will be to convert the feature and target to the readable format for smartcore model training.
Convert dataframe to matrixThe next step will be by leveraging the smartcore linear regression to build the model.
Build RL model — Code Snippet by AuthorAs of now, the Model Train and Build are finished:
Main flow — Code Snippet by AuthorML Model Deployment
Once the model is built, we will have to deploy it to the API service for the API endpoint(we made in part 2) to pick it up and use it.
For the deployment, we will leverage the Github Action to trigger the ML pipeline deployment, which copies the sources models from the ML pipeline repo to the API repo, which will start API repo build based on the rule you defined in the Github Action workflow.
For all my projects, I will start the build with the development branch, which considers is the UAT, and then the main branch will be the Prod.
ML Model in Action
If you still remember Part 2, when we build the API, we prepare the flexibility for the extend any new endpoint, so in this case, we will add one endpoint as follow:
Predict API load the model— Code Snippet by Author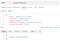
Final words
We primarily learned how to start from an idea to reality in this series of articles.
- We start with the use case, analysis, conception, solution-ing, and of course, the coding and build.
- UI Dashboard build
- API integration layer build.
- ML Pipeline builds with Rust.
- Extend the API for the ML endpoint.
Disclaimer: This is a unique build and learns project; the number, the analysis, the dashboard shown within the series of articles it's not relative to any services or API provided by Metrolinx, and it's ONLY my analysis comment and for my learning used.
I have been starting my writing journey for almost three years now. Your support is the most important motivation to keep me moving forward and write more exciting learning and sharing.
Also, you can buy me a coffee with the link below to keep me motivated for more weekend build and learn.

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK