

Nine Rules for Writing Python Extensions in Rust
source link: https://towardsdatascience.com/nine-rules-for-writing-python-extensions-in-rust-d35ea3a4ec29
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Nine Rules for Writing Python Extensions in Rust
Practical Lessons from Upgrading Bed-Reader, a Python Bioinformatics Package
One year ago, I got fed up with our package’s C++ extension. I rewrote it in Rust. The resulting extension was as fast a C/C++ but with better compatibility and safety. Along the way, I learned nine rules that can help you create better extension code:
The word “nice” here means created with best practices and native types. In other words, the general strategy is this: At the top, write good Python code. In the middle, write a thin layer of translator code in Rust. At the bottom, write good Rust code.

This strategy may seem obvious but following it can be tricky. This article gives practical advice and examples on how to follow each rule.
Bed-Reader is a Python package for reading and writing PLINK Bed Files, a binary format used in bioinformatics to store DNA data. Files in Bed format can be as large as a terabyte. Bed-Reader gives users fast, random access to large subsets of the data. It returns a NumPy array in the user’s choice of int8, float32, or float64.
I wanted the Bed-Reader extension code to be:
- Faster than Python
- Compatible with NumPy
- Fully data-parallel multithreading
- Compatible with all other packages doing data-parallel multithreading
Our original C++ extension gave me speed, NumPy compatibility, and — with OpenMP — data-parallel multithreading. Sadly, OpenMP requires in a runtime library and different Python packages can depend on different, incompatible, versions of that runtime library.
Rust gave me everything offered by C++. Beyond that, it solved the runtime-compatibility problem by providing data-parallel multithreading without a runtime library. Moreover, the Rust compiler guarantees thread safety. (It even uncovered a race condition in the original algorithm. In Rust, “Thread safety isn’t just documentation; it’s law”.)
Creating a Python extension in Rust requires many design decisions. Based on my experience with Bed-Reader, here are the decisions I recommend. To avoid wishy-washiness, I’ll express these recommendations as rules.
Rule 1: Create a single repository containing both Rust and Python projects
The table below shows how to layout files.
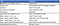
Create files Cargo.toml and src/lib.rs using Rust’s usual ‘cargo new’ command. There is no setup.py file for Python. Instead, Cargo.toml contains PyPi package information, such as the name of the package, its version number, the location of its README file, etc. To work without a setup.py, pyproject.toml must contain:
[build-system]
requires = ["maturin==0.12.5"]
build-backend = "maturin"
We’ll talk about “maturin” and file src/python_module.rs in Rule #2. We’ll talk about testing (src/tests.rs and bed_reader/tests) in Rule #9.
Python settings go in pyproject.toml when possible (and in files such as a pytest.ini when not). Python code goes in its own subfolder, here bed_reader.
Finally, we use GitHub actions to build, test, and ready deployment. That script lives in .github/workflows/ci.yml.
Rule 2: Use maturin & PyO3 to create Python-callable translator functions in Rust
Maturin is a PyPi package for (among other things) building and publishing Python extensions via PyO3. PyO3 is a Rust crate for (among other things) writing Python extensions in Rust.
In Cargo.toml, include these Rust dependencies:
[dependencies]
thiserror = "1.0.30"
ndarray-npy = { version = "0.8.1", default-features = false }
rayon = "1.5.1"
numpy = "0.15.0"
ndarray = { version = "0.15.4", features = ["approx", "rayon"] }
pyo3 = { version = "0.15.1", features = ["extension-module"] }[dev-dependencies]
temp_testdir = "0.2.3"
At the bottom ofsrc/lib.rs, include these two lines:
mod python_module;
mod tests;
Rule 3: Have the Rust translator functions call “nice” Rust functions
In src/lib.rs define “nice” Rust functions. These functions will do the core work of your package. They will input and output standard Rust types and try to follow Rust best practices. For example, for the Bed-Reader package, read_no_alloc is the nice Rust function for reading and returning values from a PLINK Bed file.
Python, however, can’t directly call these functions. So, in file src/python_module.rs define Rust translator functions that Python can call. Here is an example translator function:
#[pyfn(m)]
#[pyo3(name = "read_f64")]
fn read_f64_py(
filename: &str,
iid_count: usize,
sid_count: usize,
count_a1: bool,
iid_index: &PyArray1<usize>,
sid_index: &PyArray1<usize>,
val: &PyArray2<f64>,
num_threads: usize,
) -> Result<(), PyErr> {
let iid_index = iid_index.readonly();
let sid_index = sid_index.readonly();
let mut val = unsafe { val.as_array_mut() };
let ii = &iid_index.as_slice()?;
let si = &sid_index.as_slice()?;
create_pool(num_threads)?.install(|| {
read_no_alloc(
filename,
iid_count,
sid_count,
count_a1,
ii,
si,
f64::NAN,
&mut val,
)
})?; Ok(())
}
This function takes as input a file name, some integers related to the size of the file, and two 1-D NumPy arrays that tell which subset of the data to read. The function reads values from the file and fills in val, a preallocated 2-D NumPy array.
Notice that this function:
- translates Python NumPy 1-D arrays into Rust slices, the standard Rust 1-D data structure, via:
let iid_index = iid_index.readonly();
let ii = &iid_index.as_slice()?; - translates Python NumPy 2-D arrays into 2-D Rust ndarray objects, via:
let mut val = unsafe { val.as_array_mut() }; - calls
read_no_alloc, a nice Rust function insrc/lib.rsthat does the core work. - (Later rules will cover preallocation,
f64,PyErr,andcreate_pool(num_threads))
Doing the core work in a Rust function defined on standard Rust types lets us use Rust best practices for testing, generics, errors, etc. It also gives us a pathway to later offering a Rust version of our package.
Rule 4: Preallocate memory in Python
Preallocating the memory for our results in Python simplifies the Rust code. On the Python side, in bed_reader/_open_bed.py, we import the Rust translator function:
from .bed_reader import [...] read_f64 [...]
Then, we define a nice Python function that allocates memory, calls the Rust translator function, and returns the result.
def read([...]):
[...]
val = np.zeros((len(iid_index), len(sid_index)), order=order, dtype=dtype)
[...]
reader = read_f64
[...]
reader(
str(self.filepath),
iid_count=self.iid_count,
sid_count=self.sid_count,
count_a1=self.count_A1,
iid_index=iid_index,
sid_index=sid_index,
val=val,
num_threads=num_threads,
)
[...]
return val
(Later rules will explain reader = read_f64 and num_threads=num_threads.)
Rule 5: Translate nice Rust error handling into nice Python error handling
To see how to handle errors, let’s trace two possible errors in read_no_alloc (our nice Rust function in src/lib.rs).
Example Error 1: An error from a standard function — What if Rust’s standard File::open function can’t find the file or can’t open it? In that case, the question mark in this line:
let mut buf_reader = BufReader::new(File::open(filename)?);
will cause the function to return with some std::io::Error value. To define a function that can return these values, we give the function a return type of Result<(), BedErrorPlus>. We define BedErrorPlus to include all of std::io::Error like so:
use thiserror::Error;
...
/// BedErrorPlus enumerates all possible errors
/// returned by this library.
/// Based on https://nick.groenen.me/posts/rust-error-handling/#the-library-error-type
#[derive(Error, Debug)]
pub enum BedErrorPlus {
#[error(transparent)]
IOError(#[from] std::io::Error), #[error(transparent)]
BedError(#[from] BedError), #[error(transparent)]
ThreadPoolError(#[from] ThreadPoolBuildError),
}
This is nice Rust error handling, but Python doesn’t understand it. So, in src/python_module.rs, we translate. First, we define our translator function read_f64_py to return PyErr. Second, we implement a converter from BedErrorPlus to PyErr. The converter creates the right class of Python error (IOError, ValueError, or IndexError) with the right error message. It looks like:
impl std::convert::From<BedErrorPlus> for PyErr {
fn from(err: BedErrorPlus) -> PyErr {
match err {
BedErrorPlus::IOError(_) => PyIOError::new_err(err.to_string()),
BedErrorPlus::ThreadPoolError(_) => PyValueError::new_err(err.to_string()),
BedErrorPlus::BedError(BedError::IidIndexTooBig(_))
| BedErrorPlus::BedError(BedError::SidIndexTooBig(_))
| BedErrorPlus::BedError(BedError::IndexMismatch(_, _, _, _))
| BedErrorPlus::BedError(BedError::IndexesTooBigForFiles(_, _))
| BedErrorPlus::BedError(BedError::SubsetMismatch(_, _, _, _)) => {
PyIndexError::new_err(err.to_string())
}
_ => PyValueError::new_err(err.to_string()),
}
}
}Example Error 2: An error specific to our function — What if our nice function read_no_alloc can open the file but then realizes the file’s format is wrong? It should raise a custom error like so:
if (BED_FILE_MAGIC1 != bytes_vector[0]) || (BED_FILE_MAGIC2 != bytes_vector[1]) {
return Err(BedError::IllFormed(filename.to_string()).into());
}The custom error of type BedError::IllFormed is defined insrc/lib.rs:
use thiserror::Error;
[...]
// https://docs.rs/thiserror/1.0.23/thiserror/
#[derive(Error, Debug, Clone)]
pub enum BedError {
#[error("Ill-formed BED file. BED file header is incorrect or length is wrong. '{0}'")]
IllFormed(String),
[...]
}
The rest of the error handling is the same as in Example Error #1.
In the end, for both Rust and Python, for both standard errors and custom errors, the result is a specific error type with an informative error message.
Rule 6: Multithread with Rayon and ndarray::parallel, returning any errors
The Rust Rayon crate provides easy and lightweight data-parallel multithreading. The ndarray::parallel module applies Rayon to arrays. The usual pattern is to parallelize across the columns (or rows) of one or more 2-D arrays. One challenge is to return any error message from the parallel threads. I’ll highlight two approaches to parallelizing array operations with error handling. Both examples appear in Bed-Reader’s src/lib.rs file.
Approach 1: par_bridge().try_for_each
Rayon’s par_bridge turns a sequential iterator into a parallel iterator. Its try_for_each method will stop all processing as quickly as it can if an error is hit.
In this example, we iterate through two things zipped together:
- a DNA location’s binary data and
- the columns of our output array.
We read the binary data sequentially, but process of each column’s piece of that data in parallel. We stop on any errors.
[... not shown, read bytes for DNA location's data ...]
// Zip in the column of the output array
.zip(out_val.axis_iter_mut(nd::Axis(1)))
// In parallel, decompress the iid info and put it in its column
.par_bridge() // This seems faster that parallel zip
.try_for_each(|(bytes_vector_result, mut col)| {
match bytes_vector_result {
Err(e) => Err(e),
Ok(bytes_vector) => {
for out_iid_i in 0..out_iid_count {
let in_iid_i = iid_index[out_iid_i];
let i_div_4 = in_iid_i / 4;
let i_mod_4 = in_iid_i % 4;
let genotype_byte: u8 = (bytes_vector[i_div_4] >> (i_mod_4 * 2)) & 0x03;
col[out_iid_i] = from_two_bits_to_value[genotype_byte as usize];
}
Ok(())
}
}
})?;
Approach 2: par_azip!
The ndarray packages’s par_azip! macro lets one march through, in parallel, one or more zipped-together arrays (or array pieces). It is, in my opinion, very readable. It doesn’t, however, directly support error handling. We can add error handling by saving any error to a results list.
Here is an example from a utility function. The full utility function computes statistics (mean and variance) from three arrays of counts and sums. It does its work in parallel. If it finds an error in the data, it records that error in a result list. After all processing, it checks the result list for errors.
[...]
let mut result_list: Vec<Result<(), BedError>> = vec![Ok(()); sid_count];
nd::par_azip!((mut stats_row in stats.axis_iter_mut(nd::Axis(0)),
&n_observed in &n_observed_array,
&sum_s in &sum_s_array,
&sum2_s in &sum2_s_array,
result_ptr in &mut result_list)
{
[...some code not shown...]
});
// Check the result list for errors
result_list.par_iter().try_for_each(|x| (*x).clone())?;
[...]
Rayon and ndarray::parallel offer many other nice approaches to data-parallel processing. Feel free to use them, just be sure to gather and return any errors. (Do not just use Rust’s “panic”.)
Rule 7: Allow users to control the number of parallel threads
To play nicely with a user’s other code, the user must be able to control the number of parallel threads each function will use.
In the nice Python read function, we give the user an optional num_threadsargument. If they don’t set it, Python sets it via this function:
def get_num_threads(num_threads=None):
if num_threads is not None:
return num_threads
if "PST_NUM_THREADS" in os.environ:
return int(os.environ["PST_NUM_THREADS"])
if "NUM_THREADS" in os.environ:
return int(os.environ["NUM_THREADS"])
if "MKL_NUM_THREADS" in os.environ:
return int(os.environ["MKL_NUM_THREADS"])
return multiprocessing.cpu_count()
Next, on the Rust side, we define create_pool. This helper function constructs a Rayon ThreadPool object from num_threads.
pub fn create_pool(num_threads: usize) -> Result<rayon::ThreadPool, BedErrorPlus> {
match rayon::ThreadPoolBuilder::new()
.num_threads(num_threads)
.build()
{
Err(e) => Err(e.into()),
Ok(pool) => Ok(pool),
}
}Finally, in the Rust translator functionread_f64_py, we call read_no_alloc (the nice Rust function) from inside a create_pool(num_threads)?.install(...). This limits all Rayon functions to the num_threads we set.
[...]
create_pool(num_threads)?.install(|| {
read_no_alloc(
filename,
[...]
)
})?;
[...]
Rule 8: Translate nice dynamically-type Python functions into nice Rust generic functions
Users of the nice Python read function can specify the dtype of the returned NumPy array (int8, float32 or float64). From this choice, the function looks up the appropriate Rust translator function (read_i8(_py), read_f32(_py), or read_f64(_py)), which is then called.
def read(
[...]
dtype: Optional[Union[type, str]] = "float32",
[...]
)
[...]
if dtype == np.int8:
reader = read_i8
elif dtype == np.float64:
reader = read_f64
elif dtype == np.float32:
reader = read_f32
else:
raise ValueError(
f"dtype '{val.dtype}' not known, only "
+ "'int8', 'float32', and 'float64' are allowed."
) reader(
str(self.filepath),
[...]
)
The three Rust translator functions (insrc/python_module.rs) call the same nice Rust function,read_no_alloc, defined in src/lib.rs. Here are the relevant parts of translator function read_64 (a.k.a. read_64_py):
#[pyfn(m)]
#[pyo3(name = "read_f64")]
fn read_f64_py(
[...]
val: &PyArray2<f64>,
num_threads: usize,
) -> Result<(), PyErr> {
[...]
let mut val = unsafe { val.as_array_mut() };
[...]
read_no_alloc(
[...]
f64::NAN,
&mut val,
)
[...]
}
We define the niceread_no_alloc function generically in src/lib.rs. That is, it will work on any type TOut with the right traits. The relevant parts of its code are here:
fn read_no_alloc<TOut: Copy + Default + From<i8> + Debug + Sync + Send>(
filename: &str,
[...]
missing_value: TOut,
val: &mut nd::ArrayViewMut2<'_, TOut>,
) -> Result<(), BedErrorPlus> {
[...]
}
Organizing the code in these three levels (nice Python, translator Rust, nice Rust) lets us offer code with dynamic types to our Python users while still writing nice, generic code in Rust.
Rule 9: Create both Rust and Python tests
You might be tempted to write only Python tests that will call Rust. You should, however, also write Rust tests. The addition of Rust tests lets you run tests interactively and debug interactively. Rust tests also give you a path to later offering a Rust version of your package. In the example project, both sets of tests read test files from bed_reader/tests/data.
Where practical, I also recommend writing pure Python versions of your functions. You can then use these slow Python function to test the results of your fast Rust functions.
Finally, your CI script, for example, bed-reader/ci.yml, should run both your Rust and Python tests.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK