

深入浅出 tnpm rapid 模式 - 如何比 pnpm 快 10 秒
source link: https://zhuanlan.zhihu.com/p/455809528
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

作为一名老前端,不得不感慨,前端变得越来越复杂,依赖安装的速度很慢很慢。
前几天我们也在 蚂蚁 SEE Conf 2022 发表了主题演讲:《一种秒级安装 npm 的黑科技》。
本文从另一个角度来阐述下关于前端依赖安装提速 整个优化工作的背景、思考、结果以及未来。
黑魔法和黑科技的区别在于:前者用"又不是不能用"的脏活来实现目的,后者用跨领域的知识来实现降维打击。
npm 为什么会慢?
在现代 npm 生态体系下,模块数量和依赖关系日趋复杂化:
- 模块数量众多,截止 2021 年底,npm 包数量已经超过 180 万,数倍于其他语言的模块数量。
- 模块关系错综复杂,存在重复依赖,小文件很多,浪费磁盘空间并拖慢写入速度。
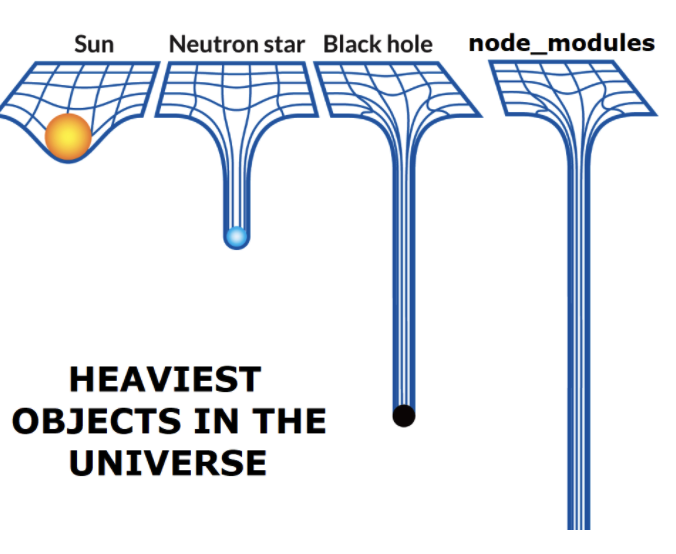
就如同一个硬币的两面,追求小而美的 Node.js 的模块生态,推动社区发展空前繁荣的同时,也使得依赖关系变得非常的复杂,一定程度上造成了依赖安装非常慢。
生态现状正确与否,不在今天我们探讨的范畴之内,让我们聚焦在当下如何来提升安装速度。
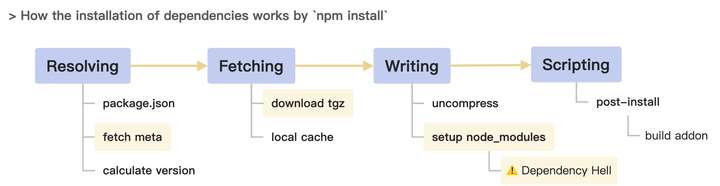
一个应用的依赖安装过程大致如上,关键操作主要有:
- 查询子依赖的包信息,获取下载地址。
- 下载 tgz 包到本地,解压安装。
- 构造 node_modules 目录结构,写入文件。
依赖包安装
我们以一个比较有代表性的测试对象 [email protected] 为例:
实际依赖数大概 1000 个左右,磁盘占用 170M,文件数量 18542 个。
但若使用 npm@2 按传统嵌套目录方式安装后,实际安装依赖数高达 3626 个,有两千多个重复的依赖,磁盘占用 523M,文件数量高达 60257 个。
然而,文件 IO,尤其是海量小文件的读写是非常耗时的。
npm@3 先提出了优化思路:『扁平化依赖』能力,所有子依赖都被拍平到了根目录的 node_modules 下,试图解决了重复依赖以及层级太深的问题。
但它也带来了额外的新问题:
- 幽灵依赖问题(phantom dependencies)。
- 多重身问题,无法彻底解决重复依赖,譬如还存在 183 个重复依赖。(doppelgangers)。
- 依赖结构的不确定性。(通过 依赖关系图 可以解决)
- 扁平化算法的复杂度和性能损耗。
鉴于扁平化依赖的诸多副作用,pnpm 提出了另一种解决思路,通过 软链接 + 硬链接 的方式:
这种方式能很好的实现了:
- 减少包的重复问题,兼容 Node.js 的寻址逻辑,未引入幽灵依赖、多重身等问题。
- 全局缓存的硬链接方式,能减少文件复制,节省磁盘占用。
从数据也看到:1109 个模块,18747 个文件,5435 个目录,3150 个软链接,磁盘占用 175M。
我们的 cnpm 当年也受到 pnpm 的启发,重构并实现了 cnpm/npminstall 这个库,同样是通过软链接方式,但没有用到硬链接,也未把子依赖提升到同级。
这种方式潜在的一些问题:
- 软链会导致一些 IDE 出现死循环的 indexing 问题。(随着 IDE 的优化,目前已经好了很多)
- 子依赖提升到同级的目录结构的兼容性问题,虽然由于 Node.js 的父目录上溯寻址逻辑,可以实现兼容。但对于类似 Egg、Webpack 的插件加载逻辑,在用到相对路径的地方,需要去适配。
- 不同应用的依赖是硬链接到同一份文件,调试时修改了文件有可能会无意中影响到其他项目。
- 软链在不同操作系统的实现不太一样,且在非 SSD 的硬盘上,还是会有一定的磁盘 IO 损耗的。
此外,yarn 也提出了 Plug'n'Play 等优化方式,但鉴于它太过于激进,无法兼容 Node.js 现存生态,在此我们不展开讨论。
包信息查询
我们再来观察下依赖安装过程:
- 每个依赖都需要 1 次包信息查询,1 次 tgz 下载,共 2 次 HTTP 请求。
- 同包不同版本时,仅查询 1 次信息,然后每个版本 tgz 下载 1 次。
由于当前生态下,依赖个数是非常多的,从而 HTTP 请求次数会对应的被放大,造成可观的耗时增加。譬如上面的例子,npm@2 会发起 2500 多次 HTTP 请求。
目前的优化共识是:通过事先计算好的依赖关系图,可以直接去下载 tgz,无需查询包信息,从而减少了一大半的网络耗时。
npm 先提出了 shrinkwrap 的概念,随即被 yarn 提出 lockfile 所代替,pnpm 也有对应的支持但配置格式不一样。虽然它们最初的出发点是锁版本,但意外地发现还可以作为 依赖关系图 来提速下载。
但它存在的问题是:
- 首次安装不会提速,除非把 lockfile 存入源码管理。
- 锁版本在大规模实践中会带来了一定的治理问题。
总结下,若要提升安装速度,我们需要思考:
- 如何更快的获取依赖关系?(解析策略)
- 如何更快的下载 tgz 包?(网络 IO)
- 如何更快的写入到硬盘?重复的依赖如何处理?(文件 IO)
目前已达成的共识:
- 通过依赖关系图,来优化网络 IO 时序,实现更高效的并发下载。
- 通过某些方式去简化 node_modules 目录,优化重复依赖带来的文件 IO 问题。
- 全局缓存,减少网络 IO 下载量。
存在的问题:
- lockfile 一定程度上会带来维护成本问题,锁版本和不锁版本都不是银弹。
- 扁平化依赖 和 软链接 方式都存在各自的一些兼容性问题。
- 全局缓存未达成共识,解压复制方式产生大量文件 IO,硬链接方式会有潜在的冲突问题。
参考阅读:JavaScript 包管理简史
tnpm 和 cnpm 是什么?
如上图,简单的说:
- cnpm 是我们开源的 npm 实现,支持官方 npm registry 的镜像同步,以及私有包能力。
- npmmirror 是社区基于 cnpm 部署的一个公益项目,为中国前端开发者提供镜像服务。
- tnpm 是我们在阿里巴巴及蚂蚁集团的企业服务,同样基于 cnpm 之上做了企业级的能力定制。
在阿里巴巴及蚂蚁集团,对工程师来说,研发效能是一个很重要的指标,而前端依赖的安装速度,是一个很大的影响因子。
因此我们在 2021 年发起了 包管理与构建专项,目标之一就是优化依赖的安装速度,最终成功地提速了 3 倍,斩获了蚂蚁集团鲁班奖。
接下来,将带大家一起剖析下tnpm rapid 模式的优化思路及结果。
性能调优法则:无度量,不优化。
PS:我们可能是业界首个把 Mac mini m1 重装为 Linux 组成前端构建集群的企业,它让我们的整体构建速度额外提升了一倍。
先不对该结果做解读,等我们对 tnpm rapid 模式的优化思路逐一讨论后,再来讨论会更有体感。
背后的数据
回忆之前我们在最开始分析慢的原因时给出的数据,完整如下:
简单解读下:
- 文件数:扁平化依赖 和 软硬链接 的数量基本上差不多,都大幅减少了磁盘占用。
- 磁盘 IO:一个重要的指标,文件写入次数直接关系到安装速度。
- 网络速度:体现的是安装过程是否能尽可能的跑满带宽,越大越好。
- 请求数:包括 tgz 下载数和查询包信息数,基本上都近似为模块个数。
从数据中可以看到,tnpm 对 磁盘 IO 和 网络 IO 都有较大的优化。
我们是如何优化的?
对于网络 IO 的优化,我们只有一个目标:如何最大化的跑满带宽?
第一个优化点是 依赖关系图(dependencies graph):
- 目前的共识都是通过它来避免在 CLI 近端侧去请求包信息,从而极大的减少了 HTTP 请求数。
- 我们的特殊之处在于:在服务端侧生成依赖关系图,并实现了多级缓存策略。
- 使用
@npmcli/arborist,遵循 npm 规范。
在我们的企业级大规模实践中的经验和理念是不提倡本地锁版本,仅在迭代推进工作流中会复用上一阶段的依赖关系图,如 开发环境 → 测试环境,或紧急迭代等。(锁不锁版本是一个时常争吵的话题,并没有银弹,根据企业团队情况寻找各自的平衡点,在此不展开讨论。)
第二个优化点是 HTTP 请求预热:
- 一次 tgz 的下载过程,会先访问 registry,然后被 302 到 oss 下载地址。
- 通过提前预热,可以提高并发度,从而减少总的 HTTP 耗时。
- 期间还踩过一个 DNS 间歇性 5 秒延迟的坑。
npm registry 是没有这一次 302 跳转的,我们把下载流量的逻辑从 registry 分离了出去,重定向到有 CDN 缓存的 OSS 存储地址,这能提升稳定性,以及支持应急止血治理等企业级诉求。
第三个优化点是合并文件:
- 我们在测试时发现无法跑满带宽,分析后发现:在海量的依赖包的情况下,小文件的频繁写入会导致文件 IO 瓶颈。
- 仅把 tgz 解压为 tar 文件,鉴于 tar 是归档文件格式,很容易在写入磁盘时适当地合并文件。
- 反复测试得到的经验值是合并为 40 个 tar 包。即 1000 多个 tgz 最终仅存储为 40 个 tar。
第四个优化是用 Rust 重新实现了下载和解压逻辑:
- 并发 40 个协程,流式下载,解压并合并写入为 tar 包(仅 unzip)。
- 由于内置的底层库有所差异,就目前而言,Rust 的下载和解压性能会优于 Node.js。于是我们用 Rust 封装了 napi 模块供 tnpm 调用。
FUSE 文件系统
我们认为 Node.js 最初的嵌套目录优于扁平化方案,但又希望能解决软链带来的兼容性问题,如何鱼与熊掌兼得呢?
先来引入一个黑科技:FUSE (FileSystem in Userspace),即 用户态文件系统。
似乎比较抽象?我们回想一个前端很熟悉的场景:使用 ServiceWorker 来精细化地定制 HTTP Cache Control 逻辑。
是的,前端同学可以把 FUSE 理解为文件系统版的 ServiceWorker,通过 FUSE 可以接管一个目录的文件系统操作逻辑。
- 我们基于 nydus 实现了 npmfs 守护进程。
- 将 npmfs 注册为操作系统的 fuse 守护进程,挂载了虚拟映射目录。
- 当读取该目录的文件时,操作系统会把控制权转交给我们的进程。
- 我们的进程通过查询
依赖关系图来从全局缓存找到并返回对应的文件内容。
通过这种方式,我们实现了:
- 所有的系统文件操作指令,都会把这个目录视为真实的目录。
- 每个文件都被视为是独立的文件,不会像硬链接那样会互相影响。
nydus 目前不支持 macOS,故我们实现 nydus 到 macfuse 的适配层,待完善后会开源出来。
冷知识:nydus 是星际里的一个兵种,负责挖洞。
OverlayFS
日常开发时,我们有可能会需要临时修改 node_modules 下的代码,以便调试。这也是软硬链接方案潜在的问题,会导致不同应用在无意间互相干扰。
FUSE 支持自定义写入操作,但实现起来比较复杂,我们直接使用了 OverlayFS 联合文件系统。
- OverlayFS 可以聚合多种不同的挂载点到一个目录。
- 常用的场景是:在一个只读层上覆盖一个读写层,达到让只读层能够读写。
- Docker 中的镜像就是这么实现的,镜像中的 layer 可以复用于不同的容器,且不互相影响。
所以,我们进一步实现了:
- 把 FUSE 目录作为 OverlayFS 的 Lower Dir,构造出一个可以读写的文件系统,并挂载为应用的
node_modules目录。 - 利用其 COW(copy-on-write) 特性,我们可以复用底层文件,达到节省空间的目的,并支持独立的文件修改,隔离不同应用的互相干扰,安全的全局复用一份缓存。
接下来我们再聊聊全局缓存,目前业界主要有 2 种方案:
- npm:把 tgz 解包成 tar 作为全局缓存,再次安装依赖时解压到 node_modules。
- pnpm:把 tgz 解压为文件,以 hash 方式全局缓存, 同个包的不同版本的同个文件也能共享,再次安装时直接硬链接过去。
它们的共同点都是会在某个阶段解压为文件,而解压产生的海量小文件会造成海量的文件 IO。
某天我们突然开了个脑洞,干脆别解压了?
所以,我们又进化了一步:
- 直接把
node_modules通过 FUSE + 依赖关系图 映射到 tar 归档文件,省去了解压的文件 IO。 - 同时基于 FUSE 的高度可控性,我们可以很容易支持
嵌套目录和扁平化两种结构,按需切换。 - 想象空间:如何未来云存储的访问性能进一步提升,我们甚至可以不用下载 tgz 了?
曾经的另一些尝试:我们一度想把 tar + gzip 转换为 stargz + lz4,但收益不是很大:stargz 比 tar 多了索引能力,但实际上独立的依赖关系图也能实现类似的目的,没必要打包在一起。lz4 比 gzip 有很高的性能提升,但在我们目前的实践中发现, ROI 不高。
任何方案都不可能是完美无缺的,我们的方案存在一些额外的成本:
第一点是 FUSE 的成本:
- 跨系统兼容性成本,虽然有各个操作系统的支持库,但兼容性上还需要时间检验。
- 企业内部场景需要支持特权容器。
- 社区场景要看 GitHub Actions 和 Travis 是否支持 FUSE。
第二点是服务端维护成本:
- 应用的依赖关系图分析能力,仅能在企业内部私有化部署的 Registry 开启。
- 由于服务端资源限制,该能力不对公共镜像站服务开放,会 fallback 到 CLI 近端侧生成方式。
PS:目前社区包括我们的方案都没法解决运行期同个依赖多份 require cache 问题,也许 esm loader 能解决,不过跟今天这个话题无关。
综上,我们的方案的核心优势:
- 服务端生成依赖树,省去元数据请求,即:
模块数 * HTTP 耗时。 - Rust 带来的性能提升。
- 合并写入 tar,节省磁盘写入次数,即:
(模块数 - 40) * 磁盘操作耗时。 - FUSE 映射,不解压文件,即
(文件个数 + 目录个数 + 软硬链个数) * 磁盘操作耗时。
- Node.js 标准目录结构,无软链,无扁平化副作用。
- 服务端生成依赖树,省去元数据请求,即:
经过上面的分析,大家应该基本清楚tnpm rapid 模式的优化思路,现在再让我们回过头来,解读下前面的测试结果数据。
注意:目前 tnpm rapid 模式还处于小范围测试和持续迭代完善阶段,故该测试数据仅供参考。
另外,表中的 yarn 比 npm@8 还慢,暂时不知道原因,但用 pnpm 的 benchmark 测试了多次,基本上是这个结果。
简单解读下:
第一点:生成依赖关系图的耗时。
- 可以通过观察 1 和 5 两项测试,它的差值即为对应的包管理器的耗时。
- pnpm 是近端侧 HTTP 分析方式,大概是 4 秒多一点(查询包信息和下载是并行的)。
- tnpm 是服务端侧分析方式,目前是 5 秒,它比 pnpm 少了网络延迟但速度却一样,后面我们还需要继续优化。
在企业场景中,依赖的模块是相对收敛的,由于 tnpm 的依赖关系图有缓存机制,故在命中缓存情况下,第一项测试 tnpm 的耗时应该为 5 秒,比 pnpm 提速 3 倍。
第二点:文件 IO 耗时。
- 在实际场景中,CI 场景和迭代场景,有依赖关系图 + 无全局缓存,可以近似认为是 测试 5。
- 该情况下主要耗时 = tgz 下载时间 + 文件 IO 时间,前者数量基本一致,故差距主要是文件 IO。
- 数据中观察到:tnpm 比 pnpm 快 4 秒,归因是 FUSE 省掉解压写入文件的耗时 + TAR 合并。
第三点:本地开发常态。
- 对于日常开发场景,有依赖关系图 + 有全局缓存。
- 对应于 测试 2(依赖未有新版本,二次开发),测试 3(二次开发,重装依赖),测试 4(新应用首次开发)。
- 从原理上分析,耗时 = 依赖关系图更新 + 写入 node_modules 文件 + 少量包的下载更新。
- 由于 tnpm 还在开发中,本次未能测试该项,不过从以上公式分析,tnpm 比 pnpm 有 IO 优势。
小结下:tnpm 比起 pnpm 的速度优势在于 依赖关系图 的 5 秒 + FUSE 免解压的 4 秒。
前端的包管理已经发展了近十年了,从 npm 拓荒时的积极进取,到 bower 等认输后 npm 的四顾茫然原地蹉跎,到鲶鱼 yarn 出现后的群雄逐鹿,再到 pnpm 的精益求精。
我们认为前端依赖的优化之路和治理之路,还任重道远,希望能和国内外同行,继续加强合作,一起推动 npm 的进化。
从 cnpm 在 2013 年开源之后,在社区的价值更多是 npmmirror 镜像站。而我们在企业级场景 tnpm 中沉淀的很多没能顺畅的下沉出来形成循环。
因此,我们后续的规划是:把我们在企业级私有化部署和治理的经验尽可能沉淀出来回馈给社区。
- 目前 cnpm/npmcore 在重构中,以便更好的支持更好的私有化部署。(欢迎参与开源)
- 在 tnpm rapid 模式完善后,将把对应的能力,以及 npmfs 套件开源出来。(因此目前社区同学还没办法体验)
- 关于 npm 在企业级实践中的经验分享,希望有时间能写成小册分享出来。
同时我们也呼吁:前端的包管理的规范化:
- 有类似 ECMA 之类的标准,来规范各个包管理器的行为。
- 有类似 Test 262 的测试用例规范。
- 处于薛定谔阶段的 ESM 和 CommonJS 规范的加速演进。
- 前端 和 Node.js 不同场景依赖的差异性的混乱局面得到解决。
经过这一年的优化,我们收获很多,也在思考和总结:为什么我们能做到这事?
我们的优势之一是 云 + 端 的全局掌控力:不仅仅是一个近端的 CLI,还比其他包管理器多了一个远端的 registry 服务,可以更深度的进行优化。
其次,我们的团队成员更加的多元化,具备来自不同领域的知识,让我们可以跳出前端视野局限,从操作系统、文件系统、网络调优等方面去碰撞灵感。
借用之前 死月 分享的一句话:黑魔法和黑科技的区别在于:前者用"又不是不能用"的脏活来实现目的,后者用跨领域的知识来实现降维打击。
在企业级应用场景里面,前端构建提速的优化之路,不仅仅是依赖安装这一环节,它是一个系统化的工程,还有非常多的优化点,欲知详情,欢迎加入我们。
这是我们坚持在知乎做了 5 年的 Node.js 科普专栏的第 100 篇文章,如果对你有帮助,来个赞~
我是天猪,目前在蚂蚁体验技术部 广州分部,负责前端基础设施的建设,团队主要以 Node.js 为主,局部会用 go 写 mesh,用 rust 写模块,开源了 eggjs, cnpm 等项目,等你加入。
『Node.js 在前端领域是一个不可或缺的基础设施,或许未来前端的变革使得一切工程问题从根本上得到解决,但不管怎样,我只是希望当下能认真记录自己以及同行者们在这个领域的所见所想,与正在经历前端工业化演进并被此过程困扰的同学交流心得。』-- by 天猪
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK