

数据并行:提升训练吞吐的高效方法 |深度学习分布式训练专题
source link: https://my.oschina.net/u/4067628/blog/5392102
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

数据并行:提升训练吞吐的高效方法 |深度学习分布式训练专题
数据并行是大规模深度学习训练中非常成熟和常用的并行模式。本文将介绍数据并行的原理和主流实现方案,使用数据并行加速训练过程中需要注意的问题,以及如何优化数据并行进一步提高训练速度。希望能帮助用户更好的理解和使用数据并行策略。
什么是数据并行
在近年来的深度学习模型训练中,使用更多的训练数据和更大的模型趋势未改。更大的模型和数据量意味着更多的计算量和存储需求,也意味着更久的训练时间。那么如何将计算和存储需求分布到多个训练设备来提升训练速度,是关键问题。
数据并行(data parallelism)是解决上述问题的的一种并行策略,其主要逻辑遵循Single Program Multiple Data的原则,即在数据并行的模型训练中,训练任务被切分到多个进程(设备)上,每个进程维护相同的模型参数和相同的计算任务,但是处理不同的数据(batch data)。通过这种方式,同一全局数据(global batch)下的数据和计算被切分到了不同的进程,从而减轻了单个设备上的计算和存储压力。
*Single Program Multiple Data:
https://en.wikipedia.org/wiki/SPMD
在深度学习模型训练中,数据并行可作为通过增加并行训练设备来提高训练吞吐量(global batch size per second) 的方法。以常见的ResNet50 模型使用32GB V100卡训练为例。假设训练时单卡最大能支持的local batch size为256,训练一个step的耗时为1秒。则单卡训练时的吞吐为256 imgs/s。
如果我们使用32张V100做数据并行训练,假设没有损耗,那么理论上的训练吞吐可达到32 x 256 = 8192 imgs/。实际上由于数据并行时多机多卡的通信消耗等,实际加速效率会有折扣,但在加速效率为0.8时,训练吞吐也可达到32 x 256 x 0.8 = 6554 imgs/s。如果使用更多的GPU,并行训练的速度将会更高,大大减少训练需要的时间。
深度学习训练中数据并行的实现方式可以有多种,下文介绍的数据并行是基于Distributed Synchronous SGD的梯度同步数据并行,这是目前主流深度学习训练框架中数据并行的实现方式。此外,还会介绍数据并行实现所需要注意的问题以及如何优化来让数据并行实现更高的加速比,提升训练速度。
*Distributed Synchronous SGD:
https://arxiv.org/pdf/1602.06709.pdf
在飞桨框架中进行数据并行训练的示例可以参考飞桨数据并行接口文档。
*飞桨数据并行接口文档:
https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/api/paddle/DataParallel_cn.html#dataparallel
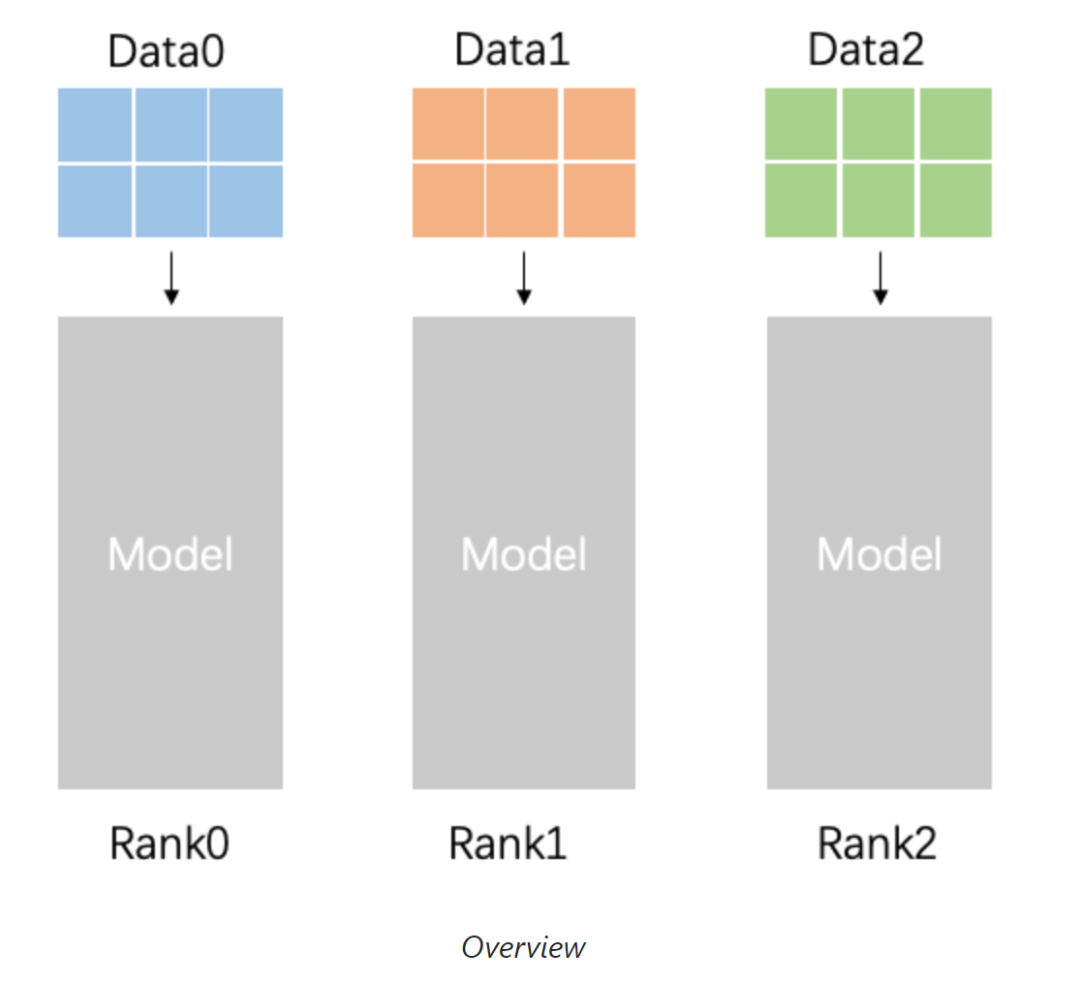
数据并行的过程
相比其它的并行模式,数据并行的实现过程比较简单,关键是实现Single Program Multiple Data并行模式中的要求:
Single Program: 在深度学习训练中single program可以理解为每个进程上模型的组网和参数相同。
Multiple Data: 在深度学习训练中为每个进程上模型处理不同mini-batch的数据。
2.1输入数据切分
第二个条件 —— 输入数据切分实现上比较简单,一般有两种常用的实现方式:
方式一:在每个训练Epoch开始前,将整个训练数据集根据并行进程数划分,每个进程只读取自身切分的数据。
方式二: 数据的读取仅由具体某个进程负责(假设为rank0)。rank0在数据读取后同样根据并行进程数将数据切分成多块,再将不同数据块发送到对应进程上。
方式一相对方式二不需要进行数据通信,训练效率更高,飞桨框架中默认的数据并行使用方式一完成数据在不同进程上的切分。
2.2模型参数同步
数据并行实现的关键问题在于如何保证训练过程中每个进程上模型的参数相同。
因为训练过程的每一个step 都会更新模型参数,每个进程处理不同的数据会得到不同的Loss。由Loss计算反向梯度并更新模型参数后,如何保证进程间模型参数正确同步,是数据并行需要解决的最主要问题。根据下面中的梯度更新公式,只要保证以下两点就能解决这个问题:

保证每个进程模型参数初始相同有两种常用的实现方法:
方法一:所有进程在参数初始时使用相同的随机种子并以相同的顺序初始化所有参数。
方法二:通过个具体进程初始化全部模型参数,之后由该进程向其他所有进程广播模型参数。
基于上述任意一种方法使每个进程得到一份相同的模型初始化参数后,梯度同步的数据并行训练就可以进一步拆解为如下三个部分:
2.2.1 前向计算
每个进程根据自身得到的输入数据独立前向计算,因为输入数据不同每个进程会得到不同的Loss。
2.2.2 反向计算
每个进程根据自身的前向计算独立进行反向计算,因为每个进程上的Loss不同,每个进程上在反向中会计算出不同的梯度。这时一个关键的操作是要在后续的更新步骤之前,对所有进程上的梯度进行同步,保证后续更新步骤中每个进程使用相同的全局梯度更新模型参数。
这一个梯度同步过程是用一个Allreduce sum同步通信操作实现的,对梯度使用Allreduce sum操作后每个进程上得到的梯度是相同的,这时候的梯度值等于所有进程上梯度对应位置相加的和,然后每个进程用Allreduce后的梯度和除以数据并行中的进程数,这样得到的梯度是同步之前所有进程上梯度的平均值。如下图所示。

2.2.3 参数更新
每个进程经过上述步骤后得到相同全局梯度,然后各自独立地完成参数更新。因为更新前模型各进程间的参数是相同的,更新中所使用的梯度也是相同的,所以更新后各进程上的参数也是相同的。
上述是主流框架中数据并行的实现过程。和单卡训练相比,最主要的区别在于反向计算中的梯度需要在所有进程中进行同步,保证每个进程上最终得到的是所有进程上梯度的平均值。
数据并行训练中的注意问题
3.1 SyncBatchNorm
前面提到,一般情况下各进程前向计算是独立的,不涉及同步问题。但使用批归一化(Batch Normalization)技术的场景下有新的挑战。
批归一化通过对输入tensor 在batch size 维度做归一化来提升训练过程的数值稳定性。但是数据并行训练中global batch size 被切分到不同的进程之上,每个进程上只有部分的输入数据,这样批归一化在计算输入tensor batch维度的平均值(Mean)和方差(Variance) 时仅使用了部分的batch而非global batch,会导致部分对batch size 比较敏感的模型(e.g. 图像分割)的精度下降。
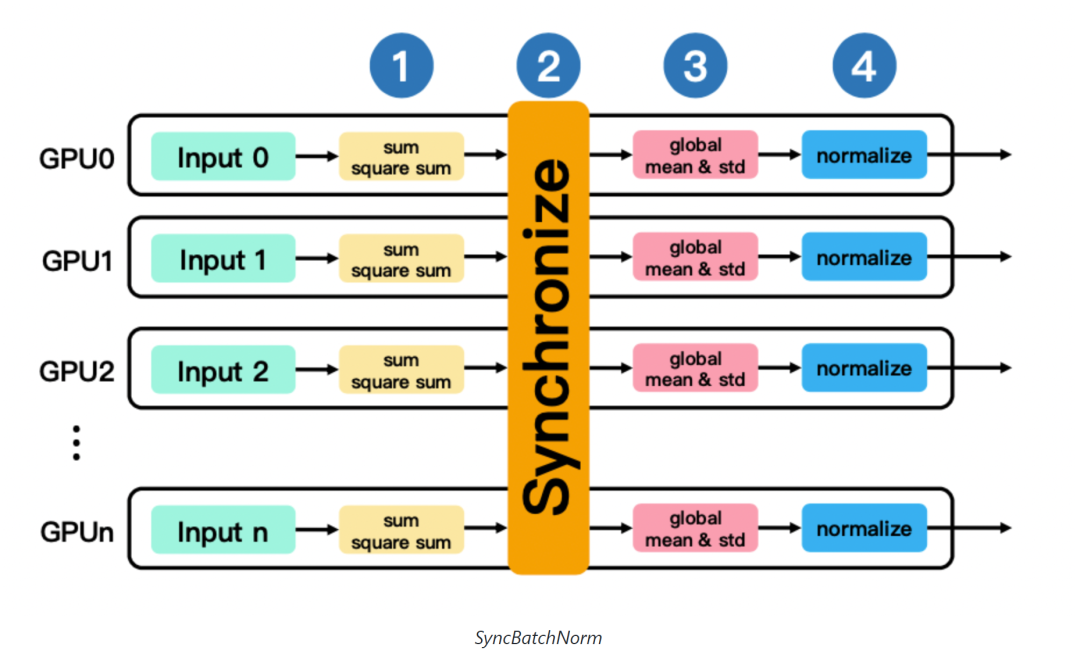
这类模型在数据并行训练中可以使用SyncBatchNorm策略来保证模型精度,该策略在模型训练前向BN层计算mean和variance时加入额外的同步通信,使用所有数据并行进程上的tensors而非自身进程上的tensor来计算tensor batch维度的mean和variance。具体过程如下图所示:
每个进程根据自己部分的数据计算batch维度上的local sum和local square sum值。
在所有卡间同步得到global sum和global square sum。
使用global sum和 global square sum计算global mean和global standard deviation。
最后使用global的mean和standard deviation对batch data进行归一化。
像语言类模型中主要使用的Layer Normalization,是在单个数据而非批数据的维度输入tensor 计算mean 和 variance,数据并行并不会影响其计算逻辑,不需要像Batch Normalization 一样做专门的调整。
3.2 数据切分均匀
目前主流训练框架数据并行训练中使用Allreduce同步通信操作来实现所有进程间梯度的同步,这要求数据在各进程间的切分要做到尽量均匀,这个问题看起来很简单,但在实际实现中也要特别注意以下两点:
1.要求所有进程每个训练step 输入的local batch size 大小相同。这是因为模型训练时需要的是所有样本对应梯度的全局平均值。如果每个进程的local batch size不相同,在计算梯度平均值时,除了要在所有进程间使用Allreduce同步梯度,还需要要同步每个进程上local batch size。
当限制所有进程上的local batch size相同时,各进程可以先在本地计算本进程上梯度的local平均值,然后对梯度在所有进程间做Allreduce sum同步,同步后的梯度除以进程数得到的值就是梯度的全局平均值。这样实现可以减少对local batch size同步的需求,提升训练速度。
2.要保证所有进程上分配到相同的batch 数量。因为Allreduce是同步通信操作,需要所有进程同时开始并同时结束一次通信过程。当有的进程的batch数量少于其它进程时,该进程会因为没有新的数据batch 而停止训练,但其他进程会继续进行下一batch的训练;当进入下一batch训练的进程执行到第一个Allreduce通信操作时,会一直等待其他所有进程到达第一个Allreduce一起完成通信操作。
但因为缺少batch的进程,已经停止训练不会执行这次allreduce操作,导致其它进程将会一直等待,呈现挂死态。数据并行中batch数量在进程的均匀切分通常是由data loader来保障的,如果训练数据集样本数无法整除数据并行进程数,那么有一种策略是部分拿到多余样本的进程可以通过抛弃最后一个batch来保证所有进程batch数量的一致。
数据并行的优化技巧
4.1 通信融合(Fuse Allreduce)
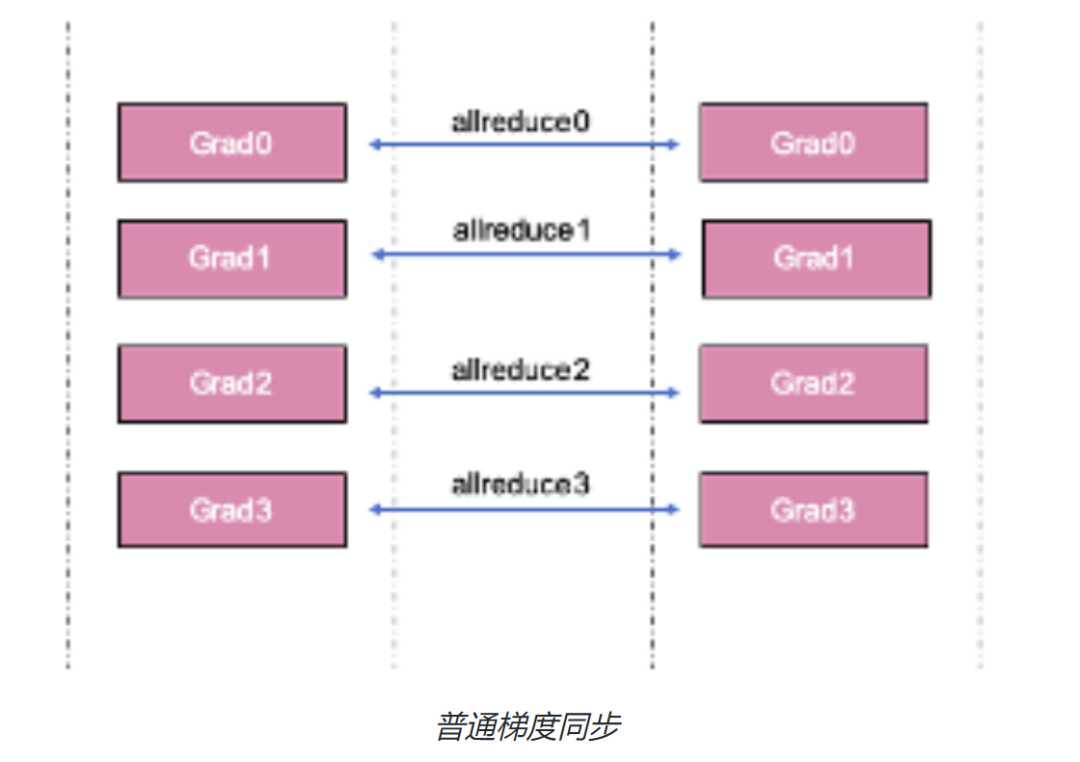
从上文我们知道数据并行中需要同步每一个模型梯度,这是通过进程间的Allreduce 通信实现的。如果一个模型有非常多的参数,则数据并行训练的每一个step 中会有非常多次的Allreduce 通信。
通信的耗时可以从通信延迟(lantency)和数据传输时间消耗两方面考虑。单次通信延迟时间相对固定,而传输时间由通信的数据量和带宽决定。减少总的通信消耗,可以通过减少通信频率来实现,通信融合是一个可行的手段,通过将N个梯度的Allreduce 通信合并成一次Allreduce 通信,可以减少N-1 次通信延迟时间。
常用的Allreduce 融合实现方式是在通信前将多个梯度tensors 拼接成一个内存地址连续的大tensor,梯度同步时仅对拼接后的大tensor 做一次Allreduce 操作。参数更新时将大tensor切分还原回之前的多个小tensors, 完成每个梯度对应参数的更新。
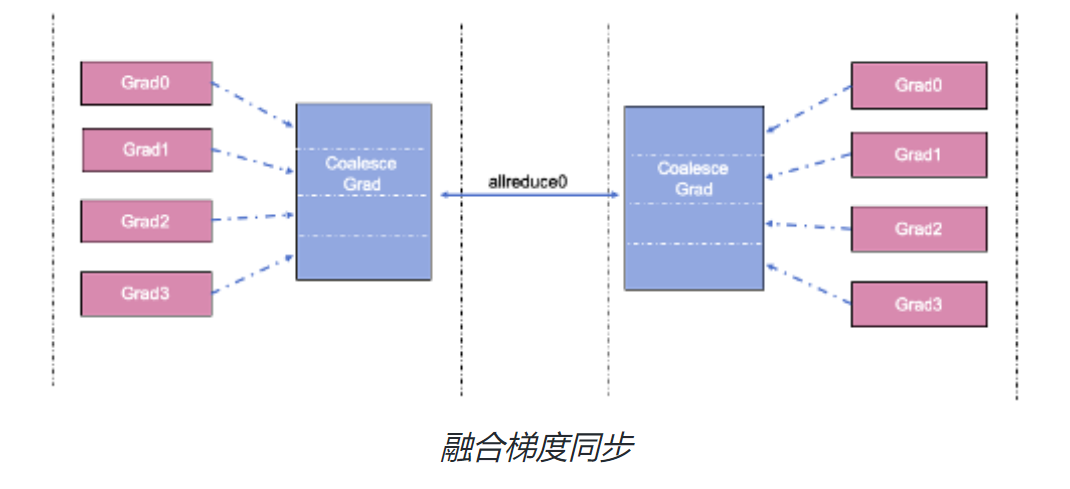
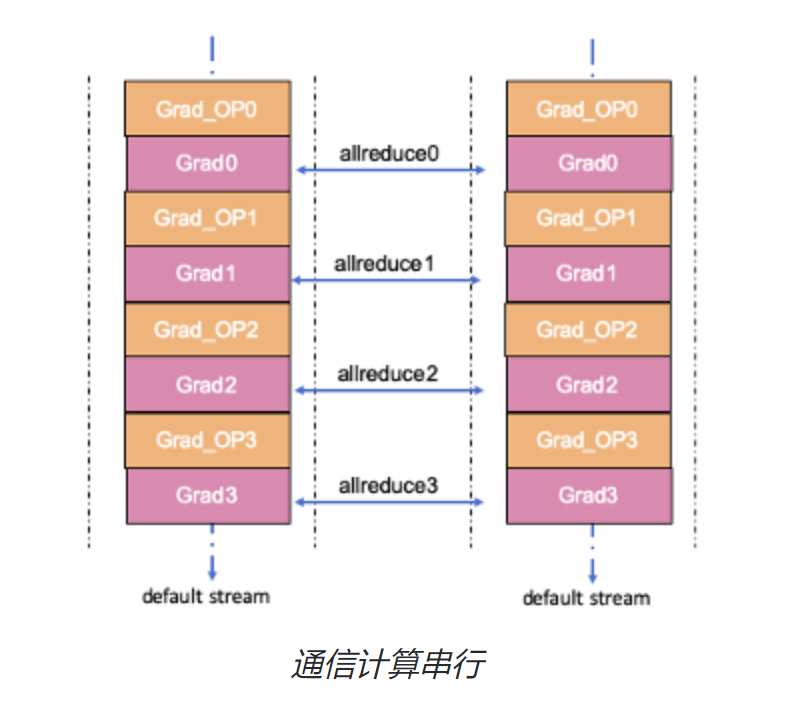
4.2 通信计算重叠(Overlapping)
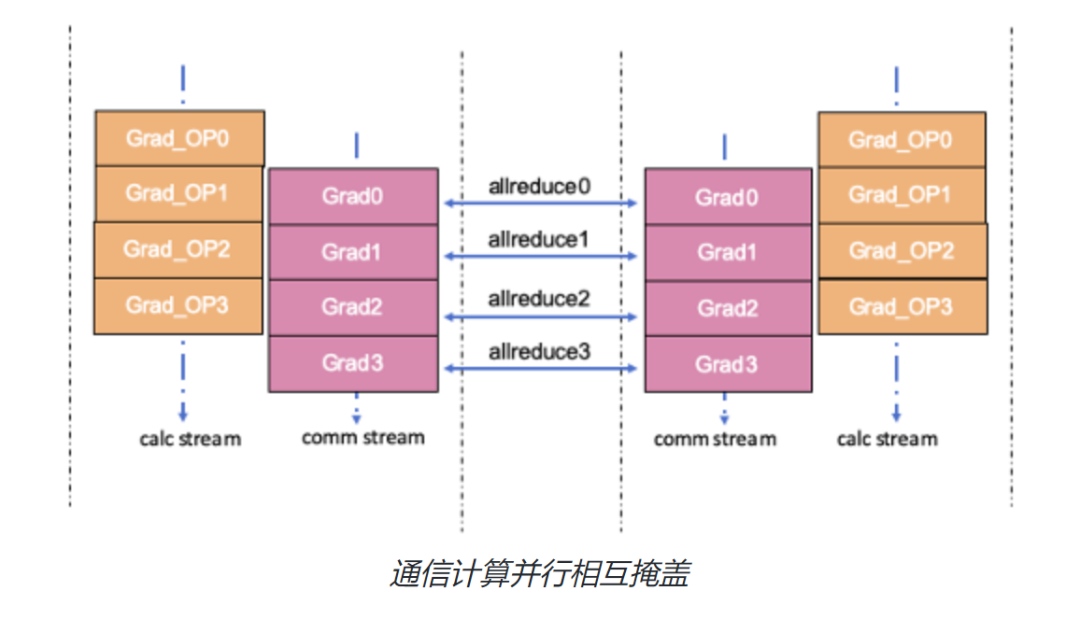
除了降低绝对的通信耗时,还可以从降低整体训练耗时角度来优化,可以考虑通信和计算的异步流水实现。数据并行中的梯度同步Allreduce通信是在训练的反向过程中进行的,而Allreduce 后得到的同步梯度是在训练的更新过程中才被使用,在反向中并没有被使用。也就是说上一个梯度的通信和下一个梯度的计算间并没有依赖,通信和计算可以并行,让两者的耗时相互重叠掩盖,减少反向的耗时。
通信和计算的重叠通常是将通信和计算算子调度到不同的流(stream)上实现的。通信算子调度到通信流,计算算子调度到计算流,同一个流上的算子间是顺序执行的,不同流上的算子可以并行执行,从而实现反向中梯度通信和计算的并行重叠。需要注意的是,当通信和计算被调度在不同的流上执行时,需要考虑两个流之间依赖和同步关系。
在梯度同步的数据并行场景中,开发者需要需要通过stream间的同步功能保证:
某个梯度Allreduce通信进行前,该梯度的反向计算已经完成。
某个梯度对应参数的更新计算开始前,该梯度的Allreduce 通信已经完成。
以上两个方法是数据并行中常用的减少通信时间消耗,提高并行加速比的优化策略。如果能做到通信和计算的重叠程度越高,那么数据并行的加速比越接近100%,多卡并行对训练吞吐提升的效率也就越高。
总结与结论
本文介绍了深度学习训练中的数据并行,介绍了基于distributed synchronous SGD 的梯度同步数据并行实现方式和训练前向、反向、更新的过程;另外还介绍了使用数据并行中批归一化结合使用时需要注意的问题和常用的数据并行训练速度优化技巧。这些都是工程上实现数据并行时需要考虑的主要问题,希望能帮助读者在工程实现角度更进一步理解数据并行。
但是在另一方面,数据并行在增大训练的global batch size 后,虽然增加了模型的训练吞吐,但模型的收敛可能会受到影响。这是数据并行在算法层面需要解决的大batch size 收敛问题。针对这类算法问题,感兴趣的读者可以参考LARS 和 LAMB 等 layer-wise-lr-adaptive 优化算法。

关注公众号,获取更多技术内容~
本文同步分享在 博客“飞桨PaddlePaddle”(CSDN)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK