

基于多源数据画像的失败用例智能分析
source link: https://my.oschina.net/u/4526289/blog/5395427
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

基于多源数据画像的失败用例智能分析 - 华为云开发者社区的个人空间 - OSCHINA - 中文开源技术交流社区
摘要:云原生分布式系统和DevOps开发模式下微服务上线节奏快,按周/按天/按需发布,失败用例的定位分析耗时达数小时或数天,无法满足快速质量反馈的诉求。
本文分享自华为云社区《华为云基于多源数据画像的失败用例智能分析》,作者:DevAI 。
作者:付求爱,华为云PaaS技术创新Lab,DevAI智能运维组负责人,北京大学计算机系毕业,研究范围主要包括日志分析、KPI异常检测和失败用例智能分析等。
云化产品上线节奏快,每天产生的失败用例规模以万计,对应产生xxTB的测试运行日志,需要投入大量人力分析测试失败用例。如果单靠人力分析测试日志数据,耗时长,可能在测试周期内都无法完成,影响产品发布。为了提升分析效率,需要标注日志数据来训练模型,从而判断失败日志的类型,这需要大量人力标注日志数据,并且仅能定位已知问题,对未知问题引发的失败用例是无法推荐根因的。
概念阐述:
- 测试用例类型:功能测试下单元测试、集成测试;
- 测试失败定义:每个用例可看做一个请求,当用例执行结果不符合预期设置的时候即失败;
- 失败可能原因:数据库结果有变、数据库连接异常、执行机性能下降响应超时、服务变更但是用例未更新、用例间冲突、配置环境问题、被测服务BUG等;
- 可用数据源:
- 用例脚本:测试人员定义的功能测试脚本(模拟输入参数,调用接口,预期结果);
- 测试日志:测试用例脚本定义的模块输出;
- 调用链日志:即调用链,每个span以日志方式存在;
- 业务运行日志:软件在执行相关功能时候输出的日志;
- 用例关联代码覆盖:软件执行时经过的代码(顺序不明);
解决问题:
异常是已知的(用例失败),目的是定位失败的细粒度根因。单个数据源有时候无法反映失败根因,或是存在多个异常信息无法锁定根因,或是只反映故障表象(如一个400返回码)。通常需要结合测试日志、调用链日志和业务日志等多源数据进行故障分析,通过识别出多个数据源因为故障导致的与历史成功时的特征差异点,进行交叉验证,筛选/推荐真正失败的原因。
2. 失败用例分析痛点
失败用例分析面临的主要痛点有:
- 同一个问题重复分析
- 数据源多,分布于各个研发系统,部分数据源获取有难度
- 依赖人工经验
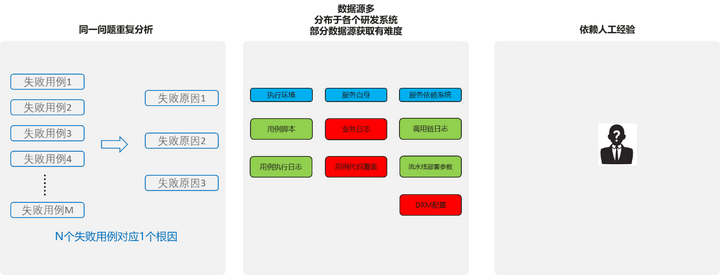
图1 失败用例分析痛点
3. 失败用例智能分析整体方案
失败用例智能分析整体方案如下图所示:

图2 失败用例智能分析整体方案
3.1 用例多源数据画像建立
依赖于多源数据建立用户画像的方案如下图所示:
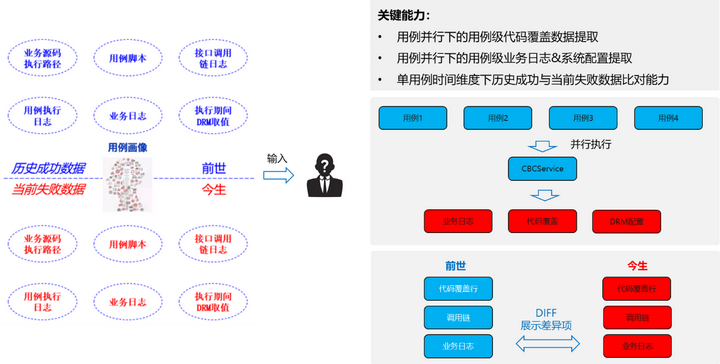
图3 用例多源数据画像建立
对于用例并行情况下多源数据获取,染色调用链,携带用例信息,基于调用链技术&字节码增强技术获取多源数据。

图4 用例并行情况下多源数据获取
3.2 失败根因智能推荐
基于多源(时间+空间)数据画像实现失败用例根因自动推荐,不依赖业务知识,无监督方式检测数据异变与根因推荐。

图5 失败根因智能推荐总体方案
- 基于单用例多源数据画像的失败根因定位(时间维度):通过对与用例关联的各个数据源(调用链、测试日志、代码覆盖、用例脚本、运行日志、配置)的历史数据不依赖业务知识建立正常数据模型(模板),形成单用例画像,识别失败用例中数据差异点,推荐为失败根因。
- 基于多用例的多源数据关联性的失败根因定位(空间维度):基于多个失败用例的多源数据异常点结果,通过聚类、谱分析、神经网络等方法挖掘之间关联性,提升推荐根因准确性。
- 基于反馈数据的排序学习模型推荐根因技术:引入基于反馈机制学习,通过学习排序模型使得推荐根因排序更加符合专家经验。
3.3 关键技术1-调用链正常数据参数级模式提取技术

图6 基于调用链参数级模板提取的失败原因智能分析方法流程图
① 数据预处理:添加父子节点ID信息,剪枝重复日志事件日志(去除重试或并行机制影响),可以合并部分调用模式;
② 调用链聚类识别不同分支:根据调用链特征(调用起始中止节点序列以及调用方法名称)将调用链聚类,分成不同正常分支;
③ 提取序列与参数级模板:不同分支形成的有向图即为服务调用序列模板。根据参数类型(时延、固定值、SQL语句、表格、字符串)进行解析,记录时延统计量和通过文本模式匹配等技术(Ratcliff-Obershelp 算法提取匹配子序列)提取参数不变量的作为正常模式(全部调用链都出现即为必要模式,部分调用链出现即为可选模式);
④ 分支匹配:计算相似度,匹配经过服务节点最相似(Jaccard相似度)以及服务调用顺序最一致(根服务节点起始的连续相同调用的数目)的分支模板;
⑤ 调用链模式差异对比:结构差异包括新增和缺失服务调用,参数差异检查耗时过长(3-sigma) ,以及SQL结果, 响应内容等内容是否包含必要或是可选的;
⑥ 根因排序:专家规则基于相应调用结束时间从早到晚结合差异类型排序;学习排序模型基于测试人员反馈数据学习更加符合专家经验的根因排序。
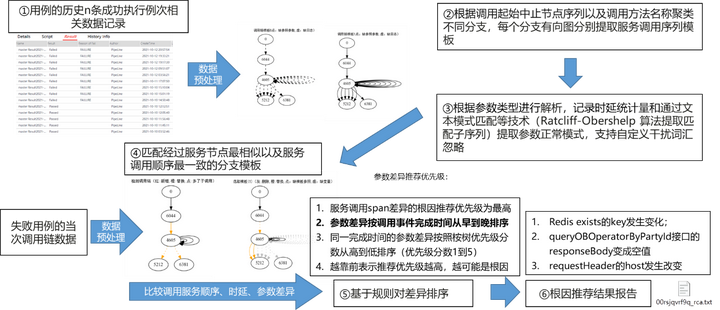
图7 调用链正常数据参数级模式提取流程图
3.4 关键技术2-基于多用例的多源数据关联性挖掘技术
基于多用例的多源数据关联性挖掘技术如下图所示:
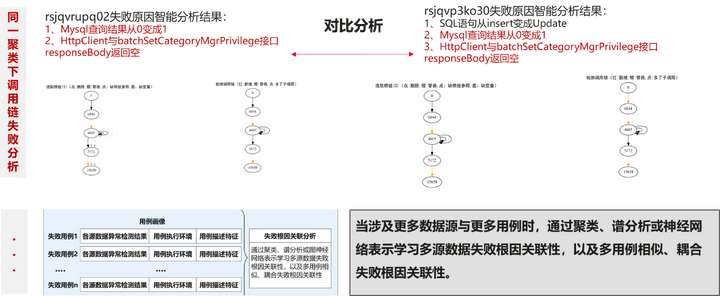
图8 基于多用例的多源数据关联性挖掘技术
3.5 关键技术3-基于反馈数据的排序学习模型推荐根因
排序学习是一个有监督的机器学习过程,对每一个给定的查询-文档对,抽取特征,通过日志挖掘或者人工标注的方法获得真实数据标注。然后通过排序模型,使得输入能够和实际的数据相似。


图9 数据驱动的排序学习模型根因推荐
云化服务如需上线则需要成功通过所有测试用例,但是目前对失败用例的分析仍较为依赖人工,面对海量微服务与快节奏开发带来的大量失败用例,无法满足快速质量反馈的需求。因此需要有基于用例执行产生的多个数据源以数据驱动的智能化手段快速定位用例失败的根因(定位至某个调用、某个数据、某个变量参数包括响应时间、某行日志、某行代码、某个配置,且能进行关联分析),做到真正帮助研发人员在开发阶段快速修复问题。
【参考资料】
- Tak, B. C., Tao, S., Yang, L., Zhu, C., & Ruan, Y. (2016, April). Logan: Problem diagnosis in the cloud using log-based reference models. In 2016 IEEE International Conference on Cloud Engineering (IC2E) (pp. 62-67). IEEE.
- Gu, J., Wang, L., Yang, Y., & Li, Y. (2018, October). Kerep: Experience in extracting knowledge on distributed system behavior through request execution path. In 2018 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW)(pp. 30-35). IEEE.
- Yang, Y., Wang, L., Gu, J., & Li, Y. (2020). Transparently capturing request execution path for anomaly detection. arXiv preprint arXiv:2001.07276.
- https://mp.weixin.qq.com/s/zMjTaNG0339b1qdyCYPeJQ
- Sambasivan, R. R., Zheng, A. X., De Rosa, M., Krevat, E., Whitman, S., Stroucken, M., ... & Ganger, G. R. (2011, March). Diagnosing Performance Changes by Comparing Request Flows. In NSDI (Vol. 5, pp. 1-1).
- https://github.com/logpai/logparser
- https://github.com/logpai/loghub
- Liu P , Xu H , Ouyang Q , et al. Unsupervised Detection of Microservice Trace Anomalies through Service-Level Deep Bayesian Networks[C]// 2020 IEEE 31st International Symposium on Software Reliability Engineering (ISSRE). IEEE, 2020.
- Liu P , Chen Y , Nie X , et al. FluxRank: A Widely-Deployable Framework to Automatically Localizing Root Cause Machines for Software Service Failure Mitigation[C]// 2019 IEEE 30th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 2019.
- Y Meng, Zhang S , Y Sun, et al. Localizing Failure Root Causes in a Microservice through Causality Inference[C]// 2020 IEEE/ACM 28th International Symposium on Quality of Service (IWQoS). ACM, 2020.
- Chen R , Zhang S , Li D , et al. LogTransfer: Cross-System Log Anomaly Detection for Software Systems with Transfer Learning[C]// 2020 IEEE 31st International Symposium on Software Reliability Engineering (ISSRE). IEEE, 2020.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK