

存储空间降为MySQL的1/10,TDengine在货拉拉数据库监控场景的应用
source link: https://my.oschina.net/u/4248671/blog/5395715
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

存储空间降为MySQL的1/10,TDengine在货拉拉数据库监控场景的应用 - 涛思数据TDengine的个人空间 - OSCHINA - 中文开源技术交流社区
 作者:马祥荣
小 T 导读:作为一家业务遍及多个国家及地区的物流公司,货拉拉面临的技术环境是非常复杂的,在云时代浪潮下基于混合云快速构建环境搭建系统成为其必然的选择。但是在混合云上如何对基于各家云构建的系统进行有效的管理是个挑战,尤其对处于系统最底层的数据库层面临的问题、业务诉求、各方痛点,是货拉拉DBA团队现下所需要重点解决的。
作者:马祥荣
小 T 导读:作为一家业务遍及多个国家及地区的物流公司,货拉拉面临的技术环境是非常复杂的,在云时代浪潮下基于混合云快速构建环境搭建系统成为其必然的选择。但是在混合云上如何对基于各家云构建的系统进行有效的管理是个挑战,尤其对处于系统最底层的数据库层面临的问题、业务诉求、各方痛点,是货拉拉DBA团队现下所需要重点解决的。
目前DBA团队管理的数据存储包括MySQL、Redis、Elasticsearch、Kafka、MQ、Canal等,为了保证监控采样的实时性,我们自研的监控系统设置的采样间隔为10秒,这样每天都会产生庞大的监控数据,监控指标的数据量达到20亿+。前期由于管理实例少,监控数据量也少,所有数据都被存放到了MySQL中;之后随着管理实例越来越多,使用MySQL来存储规模日益庞大的监控数据越发力不从心,急需进行升级改造。结合实际具体需求,通过对不同时序数据库进行调研,最终我们选择了TDengine,顺利完成了数据存储监控的升级改造。
一.
监控系统开发中遇到的问题
从存储路径来看,每种数据存储都分布在多个区域,每个区域将监控采样数据投递上报到消息总线,然后由消费程序统⼀消费,消费程序会将必要的告警数据更新到告警表,同时将监控原始数据存储到MySQL。比如,针对Redis这款数据存储,监控采样间隔设置10秒,那么每天实例采样次数就会达到3000万+,监控指标累计6亿+,数据量之庞大可见一斑。早期为了将数据存储到MySQL中,同时也能很好地支持监控绘图的使用,每⼀次实例监控采样时都会计算出该实例全量监控项采样数据,然后将本次采样的结果作为⼀条记录存储下来。
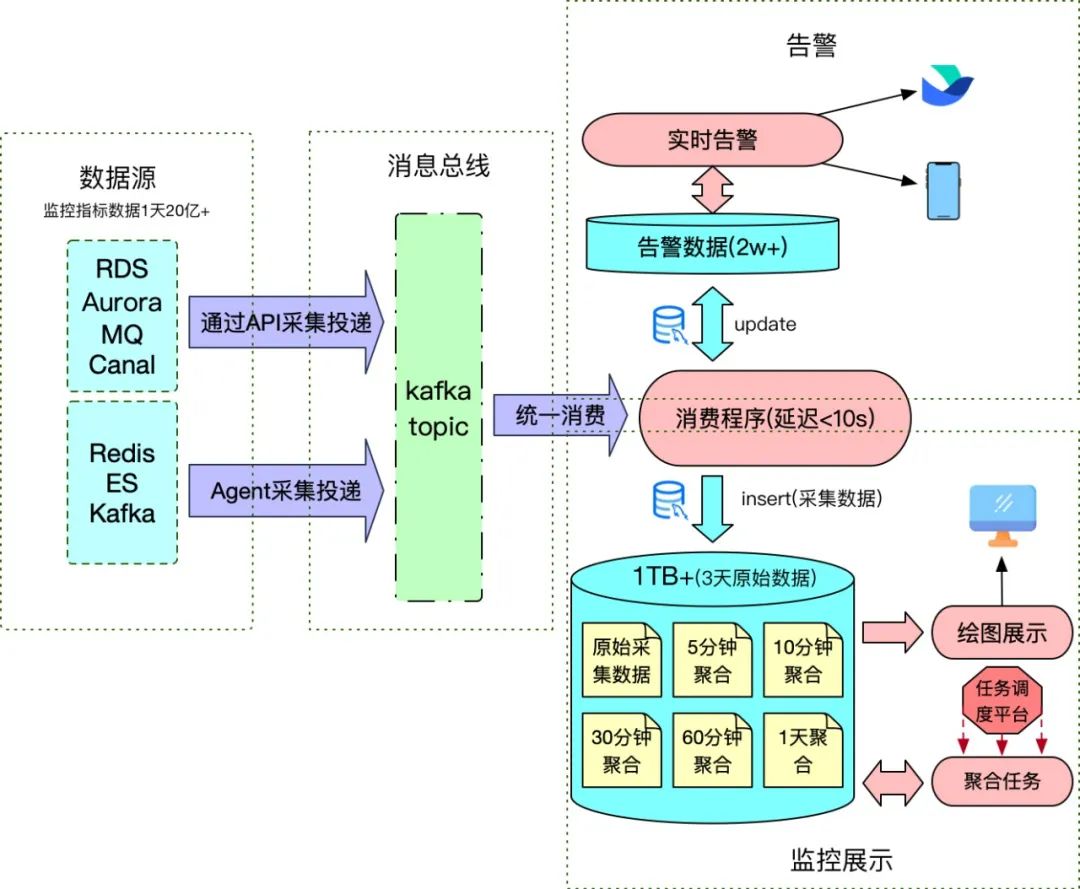
即使通过这样的优化处理,在做时间跨度大的监控绘图时,前端依然会出现延迟卡顿的问题,后端监控数据存储的MySQL也压力山大,经常满载,天天被吐槽。因此针对这种时间跨度大的查询,我们专门开发了⼀系列的数据聚合调度任务——按照不同的时间跨度,提前将10秒采集间隔的监控数据做好聚合,监控绘图程序再根据不同的时间跨度选取不同的聚合数据表绘图,以此解决长时间跨度监控绘图展示延迟卡顿的问题。
但这仍然治标不治本。为了压缩监控数据存储空间,原始10秒间隔的监控数据表只能归档保留3天时间的监控数据,但存储大小也将近有200GB, 加上与之相关的不同时间段的数据聚合表,存储一下子突破300GB。这还只是Redis监控数据的存储大小,加上其它数据存储的监控数据,至少需要1TB+空间的MySQL存储。
数据集合任务管理复杂、后期监控原数据回溯缺失、MySQL存储空间日益增长带来的隐患,都是亟待解决的问题。
二.
时序数据库选型
为了解决MySQL监控数据存储的问题,我们把注意力转移到了适合存储监控数据的时序数据库上。市面上各种时序数据库产品琳琅满目,有老牌的,也有后起之秀,经过⼀系列调研选型,我们选择了TDengine,主要是因为其具备的如下几大优点:
- 采用分布式架构,可支持线性扩展
- 数据存储压缩率超高
- 集群模式支持多副本,无单点故障
- 单机模式性能强悍
- 安装部署维护简单
- SQL⽀持时间维度聚合查询
- 客户端支持RESTful API
三.
改造过程
TDengine用于存储监控数据的超级表设计原则就是简单高效,字段⼀般都比较少,每⼀种监控项类型(INT、FLOAT、NCHAR等)的数据存储都需要单独建立⼀个超级表,超级表⼀般都有关键的ts、type、value字段,具体监控项由type字段标识,加上必要的tag及少量其它字段构成。
之前监控数据存储在MySQL的时候,每条数据记录包含了该实例⼀次监控采样的所有监控项(25+)数据。如果采用通用的监控超级表设计原则,就需要改造采样的数据结构,改造方式有两种:
- 改造监控数据投递的数据结构
- 改造消费程序消费逻辑重组数据结构
但消费端有时效性要求,改造难度大,生产端涉及范围大阻力也不小。经过综合考量,最后我们决定采用类似MySQL数据存储的表结构来设计超级表,这样的改造对原来系统入侵最少,改造难度系数最低,改造大致过程如下:
- TDengine,每种数据存储的监控数据单独建库存放
taos> create database redis;taos> create database es;... ... ...
- TDengine,建超级表,以Redis为例
taos> use redis;taos> create table redis_node_meters (created_at TIMESTAMP, qps INT, . ..) TAGS (region NCHAR(10), cluster_name NCHAR(50), ip NCHAR(20), port INT, role NCHAR(15));
- 监控数据消费,由于新增的实例节点是不确定的,比如Redis的节点资源是由Agent自动发现注册后自动进行监控指标采集,这时写入数据并不确定某个子表是否存在,就需要TDengine的自动建表语法来创建不存在的子表,若该子表已存在则不会建立新表只会写入数据。
taos > INSERT INTO tablename USING redis_node_meters TAGS ('China', 't est', '127.0.0.3', 9200, 'master') VALUES ('2021-12-02 14:21:14', 6490 , ...)- 绘图展示,绘图程序没有安装客户端驱动,直接使用了TDengine提供的RESTful API,采用HTTP的方式进行数据查询。在SQL查询上大量使用了TDengine提供的时间维度聚合函数INTERVAL,长时间跨度的数据查询,只需要合理选择聚合间隔,基本都是毫秒级响应,保障了前端绘图的流畅稳定。
四.
改造后的落地效果
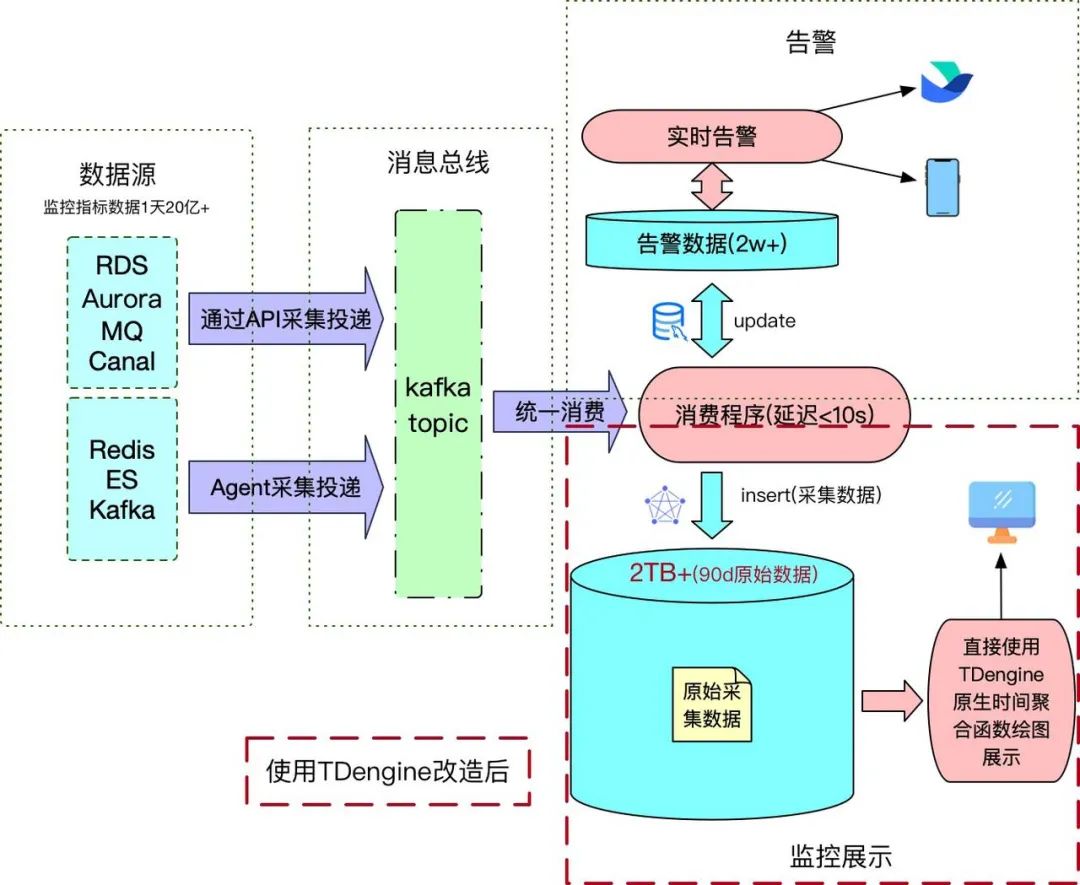
将监控的数据存储由MySQL改造为TDengine后,不仅顶住了监控数据增长所带来的压力,还节约了存储空间,成本压缩到了原来的十分之⼀甚至更低。历史原生监控数据可回溯时间也变得更长,之前存储3天原生数据及聚合数据的空间,现在可供原始数据存储45天。
此外,改造之后不再需要维护复杂的数据聚合调度任务,大幅降低了监控系统、监控数据管理复杂度,同时前端绘图数据查询也变得更加简洁高效。
五.
写在最后
随着对TDengine越发深入的了解及经验累积,后续我们也会逐步考虑将货拉拉大监控系统、业务数据(行车轨迹)等时序数据均迁移至TDengine。为了方便有需要的朋友更好地使用TDengine,在此也分享一下我们的一些使用经验:
- 由于TDengine不支持太复杂的SQL查询语法,在设计超级表tag的时候需要充分考虑清楚,目前只有tag的字段支持函数运算结果的分组(GROUP BY)查询,普通字段是不支持的。
- 子表tag的值是可以改变的,但是同⼀个子表tag的值是唯⼀的,建议用子表tag的组合值来生成子表名。
⬇️ 点击图片了解活动详情, iPhone 13 Pro/AirPods Pro/阅读器 等你带回家!
👇点击阅读原文,了解体验TDengine!
本文分享自微信公众号 - TDengine(taosdata_news)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK