

Elasticsearch(一) 入门
source link: https://zhouj000.github.io/2021/10/18/es1/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Elasticsearch(一) 入门
Elasticsearch(二) 搜索
Elasticsearch(三) API调用
Elasticsearch是一个开源的、实时的分布式搜索引擎,建立在全文搜索引擎库Lucene的基础之上(倒排索引)。Elasticsearch使用Java编写,内部使用Lucene做索引与搜索,由于Lucene仅仅只是一个库,为了使全文检索变得简单,ElasticSearch隐藏了Lucene的复杂性,取而代之的提供了一套简单一致的RESTful API
Elasticsearch的特点有:
1、一个分布式的实时文档存储,每个字段可以被索引与搜索
2、一个分布式实时分析搜索引擎
3、能胜任上百个服务节点的扩展,并支持PB级别的结构化或者非结构化数据
与Slor区别
- ES基本是开箱即用,非常简单。Solr安装略微复杂一点
- Solr利用Zookeeper进行分布式管理,而Elasticsearch自身带有分布式协调管理功能(ZK or zen)
- Solr支持更多格式的数据,比如JSON、XML、CSV,而Elasticsearch仅支持json文件格式
- Solr官方提供的功能更多,而Elasticsearch本身更注重于核心功能,高级功能多由第三方插件提供,例如图形化界面需要kibana
- Solr查询快,但更新索引时慢(即插入删除慢),多用于电商等查询多的应用;而ES建立索引快(即查询慢),即实时性查询快,多用于facebook新浪等搜索
- Solr是传统搜索应用的有力解决方案,而Elasticsearch更适用于新兴的实时搜索应用
- Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而Elasticsearch相对开发维护者较少、更新快
更多… Solr 6.2.1 vs Elasticsearch 5.0
结论:如果除了搜索文本之外,还需要用来处理分析查询、复杂的搜索时间聚合的应用程序,ElasticSearch是一个更好的选择。同时Solr的架构不适合实时搜索的应用场景
与Mongodb区别
- 相同点
- 都是以json格式管理数据的nosql数据库
- 都支持CRUD操作
- 都支持聚合和全文检索
- 都支持分片和复制
- 都支持阉割版的join操作
- 都支持处理超大规模数据
- 目前都不支持事务或者叫支持阉割版的事务
- 不同点
- ES是java编写,通过RESTful接口操作数据。Mongodb是C++编写,通过driver操作数据
- Mongodb的分片有hash和range两种方式,ES只有hash一种
- ES是天生分布式,主副分片自动分配和复制,开箱即用。Mongodb的分布式是由”前置查询路由 + 配置服务 + shard集合”,需要手动配置集群服务
- 内部存储ES是”到排索引 + docvalues + fielddata”,Mongodb为MMAPV1存储引擎(弃用)、wiredTiger插件式引擎(默认)
- ES全文检索有强大的分析器且可以灵活组合,查询时智能匹配。Mongodb的全文检索字段个数有限制
- ES所有字段自动索引,Mongodb的字段需要手动索引
- ES非实时有数据丢失窗口。Mongodb实时理论上无数据丢失风险
总结:ES偏向于检索、查询、数据分析,适用于OLAP系统。Mongodb偏向于大数据规模下的CRUD,适用于对事务要求不强的OLTP系统
前提:安装Java
官网下载最新版本的Elasticsearch。执行bin/elasticsearch,可带上-p作为一个守护进程在后台运行。通过访问http://localhost:9200/?pretty确认是否启动成功,这意味着已经启动并运行一个Elasticsearch节点了
一个集群具有一组拥有相同cluster.name的节点,他们能一起工作并共享数据,提供容错与可伸缩性,可以通过修改elasticsearch.yml来实现
Sense是一个Kibana应用,它提供交互式的控制台,可以通过浏览器直接向Elasticsearch提交请求。在安装Kibana后执行./bin/kibana plugin --install elastic/sense来下载并安装Sense app。然后通过./bin/kibana来启动Kibana。就可以通过http://localhost:5601/app/sense来访问了
Java可以使用Elasticsearch内置的两个客户端:节点客户端(Node client)和传输客户端(Transport client)。两个Java客户端都是通过9300端口并使用Elasticsearch的原生传输协议和集群交互。同理集群中的节点也是通过端口9300彼此通信,如果这个端口没有打开,节点将无法形成一个集群
注意:Java客户端作为节点必须和Elasticsearch有相同的主要版本
除此之外,RESTful API通过端口9200和Elasticsearch进行通信。可以用Postman或curl请求
curl -XGET http://localhost:9200/tmdb/_search?pretty -H "Content-Type: application/json" -d '{"query":{"match_all":{}}}'
Elasticsearch是面向文档的,而且索引每个文档的内容,使之可以被检索。可以对文档进行索引、检索、排序和过滤,这也是Elasticsearch能支持复杂全文检索的原因。ES使用JSON作为文档的序列化格式,JSON被大多数编程语言所支持,并且已经成为NoSQL领域的标准格式
默认一个文档中的每一个属性都是被索引的(有一个倒排索引)和可搜索的。一个没有倒排索引的属性是不能被搜索到的
例如:使用默认设置在megacorp索引内添加一个员工类型的文档(id为1):
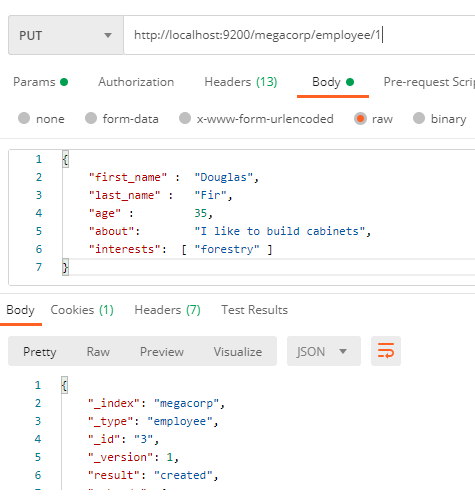
那么我们就可以查询这个文档了:GET http://localhost:9200/megacorp/employee/1,或者查询全部文档GET http://localhost:9200/megacorp/employee/_search
再添加几个文档后,可以尝试一下简单的搜索:
// 查询姓氏是Smith的员工
GET http://localhost:9200/megacorp/employee/_search?q=last_name:Smith
或使用领域特定语言(DSL),使用JSON构造请求body查询:
GET http://localhost:9200/megacorp/employee/_search
// 和前面一样,查询姓氏是Smith的员工
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}
// 姓氏是Smith,并且年龄大于30的员工
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith"
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
}
// 在about属性上搜索。全文搜索会根据相关性得分排序
// ES中的"相关性"概念非常重要,而传统关系型数据库中的一条记录要么匹配要么不匹配
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}
// 精确短语查询。并且高亮显示
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}
ES有一个功能叫聚合(aggregations),类似于Mongodb的聚合,也类似于group by。也可以和前面的query共同使用
GET http://localhost:9200/megacorp/employee/_search
// 挖掘出员工中最受欢迎的兴趣爱好
{
"aggs": {
"all_interests": {
"terms": { "field": "interests" }
}
}
}
// 分级汇总:查询特定兴趣爱好员工的平均年龄
{
"aggs" : {
"all_interests" : {
"terms" : { "field" : "interests" },
"aggs" : {
"avg_age" : {
"avg" : { "field" : "age" }
}
}
}
}
}
一个分片是一个Lucene的实例,它本身就是一个完整的搜索引擎
我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互的
ES是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。当集群规模扩大或者缩小时,ES会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里
在ES中,”文档”指最顶层或者根对象, 这个根对象被序列化成JSON并存储到ES中,拥有唯一的ID
一个文档除了包含它的数据,也包含元数据:
- _index
- 必须、文档的存放位置
- 一个索引应该是因为共同的特性而被分组到一起的文档集合
- 实际上数据是存储在分片中,索引仅仅是逻辑上的命名空间,这个命名空间由一个或者多个分片组合在一起。但是使用时不需要关心分片,只需要关心索引就行,ES会处理所有的细节
- 索引名必须小写,且不能以下划线开头、不能包含逗号
- _type
- 必须、文档表示的对象类别
- types类型允许在索引中对数据进行逻辑分区,可以对一些数据进行子分区
- 类型名可以是大写或者小写,但是不能以下划线或者句号开头,不应该包含逗号,并且长度限制为256个字符
- _id
- 必须、文档唯一标识
- ID是一个字符串,_id和_index以及_type的组合可以唯一确定ES中的一个文档
- 创建一个新的文档可以自己提供id,也可以让ES帮你生成
PUT /{index}/{type}/{id}POST /{index}/{type}/- 自动生成的ID是URL-safe,为Base64编码且长度为20个字符的GUID字符串
- _version
- 每个文档都有一个版本号
- 当每次对文档进行修改时(包括删除),_version的值都会递增
- 防止更新冲突,不匹配会更新失败
在获取文档时,会返回整个文档
GET /test/blog/123
{
"_index" : "test",
"_type" : "blog",
"_id" : "123",
"_version" : 1,
"found" : true, // 表示找到
"_source" : {
"title": "My first blog",
"text": "hello",
"date": "2021/10/10"
}
}
也可以指定返回的内容
GET /test/blog/123?_source=title,text
GET /test/blog/123/_source
ES的文档不可改变,但是可以使用同索引(index+type+id)进行替换,之后version+1。ES内部则是进行了删除旧文档(不会立即消失,只是标记为删除状态,之后随着不断索引更多数据,ES会再后台清理已删除文档),添加新文档的操作
使用update API可以进行”检索-修改-重建索引”来实现部分更新,整个过程发生在ES内部,节省了多次请求开销。内容和原有对象进行合并,覆盖已有字段,增加新字段。如果原文档不存在,那么更新会失败,可以使用upsert参数,这样如果不存在会先创建
并发冲突时,可使用乐观并发控制,即通过_version号来确保应用中相互冲突的变更不会导致数据丢失。所有文档的更新或删除API都接受version参数
使用version_type=external来处理外部版本号,这时检查当前_version是否小于指定的版本号。如果请求成功,外部的版本号作为文档的新_version进行存储
mget可以批量获取,bulk可以批量变更(create、index、update、delete)
当索引一个文档的时候,文档会被存储到一个主分片中,ES根据shard = hash(routing) % number_of_primary_shards来确定路由到哪个分片上,routing默认是文档的_id,也可以设置自定义的值,number_of_primary_shards为主分片的数量
所有的文档API都接受routing的路由参数,通过这个参数可以自定义文档到分片的映射。这样可以确保所有相关的文档都被存储到同一个分片中
我们可以发送请求到集群中的任一节点。每个节点都能处理任意请求、都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上
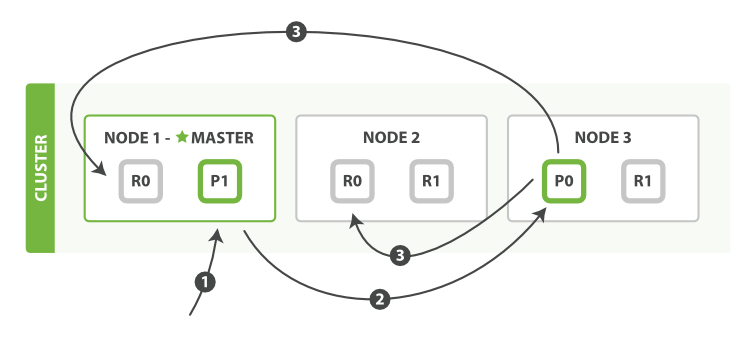
- 客户端向
Node 1发送新建、索引或者删除请求 - 节点使用文档的_id确定文档属于分片0,请求会被转发到
Node 3 Node 3在主分片上面执行请求。如果成功了,它将请求并行转发到Node 1和Node 2的副本分片上。一旦所有的副本分片都报告成功,Node 3将向协调节点报告成功,协调节点向客户端报告成功
可使用consistency参数和timeout参数影响整个过程,会以数据安全为代价提升性能,一般不推荐使用
当主分片把更改转发到副本分片时,它不会转发更新请求。它会转发完整文档的新版本。因为这些更改将会异步转发到副本分片,是不能保证它们会以发送相同的顺序到达。所以如果ES仅转发更改请求,就可能以错误的顺序更改,导致得到损坏的文档
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK