

R3LIVE:一个实时鲁棒、带有RGB颜色信息的激光雷达-惯性-视觉紧耦合系统(香港大学)
source link: https://zhuanlan.zhihu.com/p/415884551
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
R3LIVE:一个实时鲁棒、带有RGB颜色信息的激光雷达-惯性-视觉紧耦合系统(香港大学)
作者:chaochaoSEU |来源:微信公众号:3D视觉工坊
注:文末附有【视觉SLAM、激光SLAM】交流群加入方式
注1:彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
注2:彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM+LIO-SAM)
注3:激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
注4:彻底搞懂视觉-惯性SLAM:基于VINS-Fusion
R3LIVE: A Robust, Real-time, RGB-colored, LiDAR-Inertial-Visual tightly-coupled state Estimation and mapping package
作者:Jiarong Lin and Fu Zhang(香港大学)
摘要: 本文中,我们提出了一种称为 R3LIVE 的新型 LiDAR-Inertial-Visual 传感器融合框架,它利用 LiDAR、惯性和视觉传感器的测量来实现鲁棒和准确的状态估计。R3LIVE 包含两个子系统,即激光雷达-惯性里程计 (LIO) 和视觉-惯性里程计 (VIO)。LIO 子系统 (FAST-LIO) 利用 LiDAR 和惯性传感器的测量结果构建全局地图(即 3D 点的位置)的几何结构。VIO 子系统利用视觉-惯性传感器的数据来渲染地图的纹理(即 3D 点的颜色)。更具体地说,VIO 子系统通过最小化帧到地图的光度误差来直接有效地融合视觉数据。开发的系统 R3LIVE 是在我们之前的工作 R2LIVE 的基础上开发的,经过精心的架构设计和实现。实验结果表明,所得到的系统在状态估计方面比现有系统具有更强的鲁棒性和更高的精度。
R3LIVE 是一个面向各种可能应用的多功能且精心设计的系统,它不仅可以作为实时机器人应用的 SLAM 系统,还可以为测绘等应用重建密集、精确的 RGB 彩色 3D 地图 。此外,为了使 R3LIVE 更具可扩展性,我们开发了一系列用于重建和纹理化网格的离线实用程序,这进一步缩小了 R3LIVE 与各种 3D 应用程序(如模拟器、视频游戏等)之间的差距。
I 引言
最近,激光雷达传感器越来越多地用于各种机器人应用,例如自动驾驶汽车 [1]、无人机 [2]-[4] 等。尤其是随着低成本固态激光雷达的出现(例如,[5] ),更多基于这些 LiDAR 的应用 [6]-[10] 推动了机器人领域的发展。然而,对于基于 LiDAR 的 SLAM 系统,它们很容易在没有足够几何特征的情况下失败,特别是对于通常具有有限视场 [11] 的固态 LiDAR。为了解决这个问题,将 LiDAR 与相机 [12]-[15] 和超宽带 (UWB) [16, 17] 等其他传感器融合可以提高系统的鲁棒性和准确性。特别是,最近在机器人领域中提出了各种 LiDAR-Visual 融合框架 [18]。
Zhang and Singh提出的 V-LOAM [19] 是 LiDAR-Inertial-Visual 系统的早期作品之一,它利用松散耦合的视觉-惯性测距 (VIO) 作为初始化 LiDAR 映射子系统的运动模型。类似地,在 [20] 中,作者提出了一种立体视觉惯性 LiDAR SLAM,它结合了紧耦合的立体视觉-惯性里程计与 LiDAR 建图和 LiDAR 增强的视觉闭环。最近,Wang 提出了 DV-LOAM [21],这是一个直接的 Visual-LiDAR 融合框架。该系统首先利用两阶段直接视觉里程计模块进行有效的粗略状态估计,然后使用 LiDAR 建图模块细化粗略姿态,最后利用闭环模块来校正累积漂移。上述系统在松耦合的水平上融合了 LiDAR 惯性视觉传感器,其中 LiDAR 测量没有与视觉或惯性测量一起联合优化。
最近提出了紧耦合的 LiDAR-Inertial-Visual 融合框架。例如,Zuo 等提出的 LIC-fusion [14] 是一个紧耦合的 LiDARInertial-Visual 融合框架,它结合了 IMU 测量、稀疏视觉特征、LiDAR 特征以及多状态约束卡尔曼滤波器内的在线空间和时间校准( MSCKF) 框架。为了进一步增强 LiDAR 扫描匹配的鲁棒性,他们的后续工作称为 LIC-Fusion 2.0 [15] 提出了一种跨滑动窗口内多个 LiDAR 扫描的平面特征跟踪算法,并细化窗口内的姿态轨迹。Shan 等在 [13] 中提出 LVI-SAM 通过紧密耦合的平滑和建图框架融合 LiDAR-Visual-Inertial 传感器,该框架构建在因子图之上。LVI_SAM 的 LiDAR-Inertial 和 Visual-Inertial 子系统可以在其中之一检测到故障时独立运行,或者在检测到足够多的特征时联合运行。我们之前的工作 R2LIVE [12] 将 LiDAR-Inertial-Visual 传感器的数据紧密融合,提取 LiDAR 和稀疏视觉特征,通过在误差状态迭代卡尔曼滤波器框架内最小化特征重投影误差来估计状态,以实现实时性能,同时通过滑动窗口优化提高整体视觉映射精度。R2LIVE 能够在具有剧烈运动、传感器故障的各种具有挑战性的场景中运行,甚至可以在具有大量移动物体和小型 LiDAR FoV 的狭窄隧道状环境中运行。
在本文中,我们解决了基于 LiDAR、惯性和视觉测量的紧耦合融合的实时同步定位、3D 建图和地图渲染问题。我们的贡献是:
我们提出了一个实时同步定位、建图和着色框架。所提出的框架包括用于重建几何结构的 LiDAR 惯性里程计 (LIO) 和用于纹理渲染的视觉惯性里程计 (VIO)。整个系统能够实时重建环境的稠密 3D RGB 色点云(图 1(a)),
我们提出了一种基于 RGB_colored 点云图的新型 VIO 系统。VIO 通过最小化观察到的地图点的 RGB 颜色与其在当前图像中的测量颜色之间的光度误差来估计当前状态。这样的过程不需要环境中的显着视觉特征并节省相应的处理时间(例如特征检测和提取),这使得我们提出的系统更加健壮,尤其是在无纹理环境中。
我们将所提出的方法实施到一个完整的系统 R3LIVE 中,该系统能够实时且低漂移地构建环境的稠密、精确、3D、RGB 彩色点云图。整个系统已在各种室内和室外环境中得到验证。结果表明,我们的系统在行驶 1.5 公里后,平移仅漂移 0.16 米,旋转漂移仅 3.9 度。
我们在 Github 上开源我们的系统。我们还开发了几种离线工具,用于从彩色点云重建和纹理化网格(见图 1(b)和(c))。我们设备的这些软件实用程序和机械设计也是开源的,以使可能的应用程序受益。
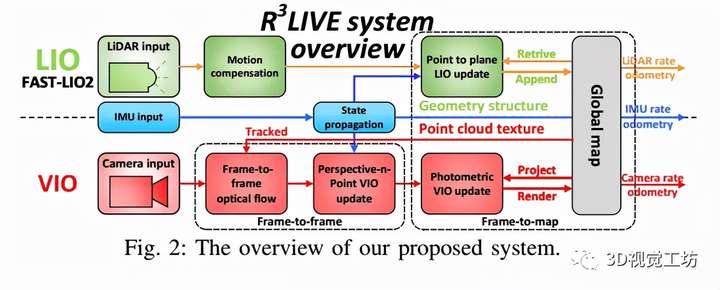
II 系统框架
我们系统的概述如图 2 所示,我们提出的框架包含两个子系统:LIO 子系统(上部)和 VIO 子系统(下部)。LIO 子系统构建了全局地图的几何结构,它记录了输入的 LiDAR 扫描,并通过最小化点到平面的残差来估计系统的状态。VIO 子系统构建贴图的纹理,用输入图像渲染每个点的 RGB 颜色,通过最小化帧到帧 PnP 重投影误差和帧到贴图光度误差来更新系统状态。
III. 数学符号
在整篇论文中,我们使用表 I 中所示的符号,这些符号已在之前的工作 R2LIVE [12] 中引入。
A.state
在我们的工作中,我们将完整状态向量 xϵ ℝ29 定义为:
其中 Gg ϵ ℝ3是在全局帧(即第一个 LiDAR 帧)中表示的重力矢量,ItC是 IMU 和相机之间的时间偏移,同时假设 LiDAR 已经与 IMU 同步,φ 是相机内参矩阵。
B. Maps representation
我们的地图由体素和点组成,其中点包含在体素中并且是地图的最小元素。
1) 体素:为了在我们的 VIO 子系统中快速找到地图中的点以进行渲染和跟踪(参见 Section.V-C 和 Section.V-D),我们设计了一个固定大小(例如 0.1m *0.1m *0.1m) 名为体素的容器。如果一个体素最近附加了点(例如最近 1 秒),我们将这个体素标记为已激活。否则,该体素被标记为停用。
2)point:在我们的工作中,点P是一个大小为6的向量(坐标和颜色RGB)
IV. 激光-惯性里程计子系统
如图 2 所示,R3LIVE 的 LIO 子系统构建了全局地图的几何结构。对于传入的 LiDAR 扫描,由于帧内连续移动而导致的运动失真由 IMU 反向传播补偿,如 [6] 所示。然后,我们利用误差状态迭代卡尔曼滤波器 (ESIKF) 最小化点对平面残差来估计系统的状态。最后,在收敛状态下,该扫描的点被附加到全局地图上,并将相应的体素标记为激活或停用。全局地图中累积的 3D 点形成几何结构,也用于为我们的 VIO 子系统提供深度。R3LIVE中LIO子系统的详细实现,请读者参考我们之前的相关工作[12, 22]。
V.视觉-惯性里程计子系统
我们的 VIO 子系统渲染全局贴图的纹理,通过最小化光度误差来估计系统状态。更具体地说,我们将全局地图中的一定数量的点(即跟踪点)投影到当前图像,然后通过最小化这些点的光度误差来迭代估计 ESIKF 框架内的系统状态。为了提高效率,跟踪的地图点是稀疏的,这通常需要构建输入图像的金字塔。然而,金字塔对于也需要估计的平移或旋转不是不变的。在我们提出的框架中,我们利用单个地图点的颜色来计算光度误差。在 VIO 中同时渲染的颜色是地图点的固有属性,并且不受相机平移和旋转的影响。为了确保稳健且快速的收敛,我们设计了如图 2 所示的两步框架,我们首先利用帧到帧光流来跟踪地图点并通过最小化 Perspective-n-Point (PnP)来优化系统状态跟踪地图点的投影误差(第 VA 部分)。然后,我们通过最小化跟踪点之间的帧到地图光度误差来进一步细化系统的状态估计(第 V-B 部分)。使用收敛状态估计和原始输入图像,我们执行纹理渲染以更新全局地图中点的颜色(第 V-C 部分)。
A. Frame-to-frame Visual-Inertial odometry
残差(4)中的测量噪声有两个来源:一是中的像素跟踪误差,二是地图点位置误差
(12)中第一项的详细推导可以在R2LIVE [12]的E节中找到。
B. Frame-to-map Visual-Inertial odometry
我们还考虑了 γs 和 cs 的测量噪声:
结合(19)、(20)和(21),我们得到真零残差
的一阶泰勒展开式:
2)Frame-to-map VIO ESIKF更新:方程(22)构成了
的另一个观测分布,它与来自IMU传播的先验分布相结合,得到
的最大后验(MAP)估计:
然后,我们执行类似于(17)和(18)的状态更新。这个帧到地图 VIO ESIKF 更新(第 V-B1 部分到第 V-B2 部分)被迭代直到收敛。然后将收敛状态估计用于:(1) 渲染地图的纹理(第 V-C 部分);(2) 更新当前跟踪点集 P 以供下一帧使用(Section V-D);(3) 在 LIO 或 VIO 更新的下一帧中作为 IMU 传播的起点
C. 渲染全局贴图的纹理
在frame-to-map VIO更新之后,我们有了当前图像的精确位姿,然后我们执行渲染函数来更新地图点的颜色。
D. Update of the tracking points of VIO subsystem
纹理渲染完成后,我们对跟踪点集 P 进行更新。不落入Ik。其次,我们将 ζ 中的每个点投影到当前图像 Ik,如果附近没有其他跟踪点(例如在 50 个像素的半径内),则将其添加到 P。
VI. 实验与结果分析
A.Equipment setup
the onboard DJI manifold-2c5 computation platform (equipped with an Intel i7-8550u CPU and 8 GB RAM), a FLIR Blackfly BFS-u3-13y3c global shutter camera, and a LiVOX AVIA6 LiDAR. The FoV of the camera is 82.9°*66.5°, while the FoV of the LiDAR is 70.4°* 77.2°.
B. Experiment-1: Robustness evaluation in simultaneously LiDAR degenerated and visual texture-less environments
如图 7 所示,我们的传感器穿过狭窄的“T”形通道,同时偶尔面对侧壁。当面对仅施加单个平面约束的墙壁时,众所周知,LiDAR 对于完整姿态估计会退化。同时,白色墙壁上的视觉纹理非常有限(图 7(a)和图 7(c)),尤其是墙壁,它只有光照变化。这种场景对于基于 LiDAR 和基于视觉的 SLAM 方法都具有挑战性。
图 8 显示了我们估计的姿势,通过“wall-1”和“wall-2”的阶段分别用蓝色和黄色阴影表示。估计的协方差也显示在图 8 中,它在整个估计轨迹上有界,表明我们的估计质量在整个过程中是稳定的。传感器移动到起始点,在那里使用 ArUco 标记板获取起始和结束姿势之间的真实相对姿势。与地面真实端位姿相比,我们的算法旋转漂移 1.62°,平移漂移 4.57 厘米。
C. Experiment-2: High precision mapping large-scale indoor & outdoor urban environment
我们在香港科技大学 (HKUST) 校园内以不同的行驶轨迹(即 Traj 1-4)收集了 4 次数据,它们的总长度分别为 1317、1524、1372 和 1191 米。这些轨迹的鸟瞰图(即在 X´Y 平面上的投影)如图 10 所示,它们的高度变化如图 11 所示。没有任何额外的处理(例如闭环),所有这四个轨迹都可以闭环(见图9(e))。使用放置在起点的 ArUco 标记板,里程计漂移如表 II 所示,这表明我们提出的方法具有高精度,在长轨迹和复杂环境中漂移很小。最后,我们在图 9 中的“Traj-1”中展示了重建的地图。项目页面上提供了更多可视化结果。
D. Experiment-3: Quantitative evaluation of precision using D-GPS RTK
我们将 R3LIVE 估计的轨迹与两种不同的配置(“R3LIVE-HiRES”和“R3LIVERT”,见表 III)、“LVI-SAM”(为 Livox Avia LiDAR 修改其 LiDAR 前端)、“R2LIVE”进行比较 [12]、“VINSMono”(IMU+相机)[26]、“Fast-LIO2”(IMU+LiDAR)[22] 与图 12 中的真实情况,我们可以看到我们估计的轨迹最符合 两个序列中的真实情况。为了进行更多的定量比较,我们计算了所有可能的长度为 (50,100,150,...,300) 米的子序列的相对旋转误差 (RPE) 和相对平移误差 (RTE) [27],如表 III 所示。
E. Run time analysis
我们调查了我们系统在两个不同平台上的所有实验的平均时间消耗:台式机(具有 Intel i7-9700K CPU 和 32GB RAM)和无人机机载计算机(“OB”,具有 Intel i7-8550u CPU 和 8GB 内存)。详细统计数据列于表四。我们的 VIO 子系统的时间消耗受两个主要设置的影响:图像分辨率和点云图分辨率(“Pt res”)。
VII. 应用
A. Mesh reconstruction and texturing
在 R3LIVE 实时重建彩色 3D 地图的同时,我们还开发了软件实用程序来离线对重建的地图进行网格划分和纹理化(见图 13)。对于网格划分,我们使用了在 CGAL [29] 中实现的 Delaunay 三角剖分和图切割 [28]。网格构建后,我们使用顶点颜色对网格进行纹理化,由我们的 VIO 子系统渲染。
我们开发的实用程序还可以将 R3LIVE 的彩色点图或离线网格图导出为常用的文件格式,如“pcd”、“ply”、“obj”等。因此,R3LIVE 重建的地图可以通过 各种 3D 软件,包括但不限于 CloudCompare [30]、Meshlab [31]、AutoDesk 3ds Max 等。
B. Toward various of 3D applications
借助开发的软件实用程序,我们可以将重建的 3D 地图导出到 Unreal Engine 19 以启用一系列 3D 应用程序。例如,在图 14 中,我们使用 AirSim [32] 构建了汽车和无人机模拟器,在图 15 中,我们使用重建的地图为台式 PC 和移动平台开发视频游戏。有关我们演示的更多详细信息,我们建议读者在 YoutuBe 上观看我们的视频。
欢迎加入【3D视觉工坊】交流群,方向涉及3D视觉、计算机视觉、深度学习、vSLAM、激光SLAM、立体视觉、自动驾驶、点云处理、三维重建、多视图几何、结构光、多传感器融合、VR/AR、学术交流、求职交流等。工坊致力于干货输出,为3D领域贡献自己的力量!欢迎大家一起交流成长~
添加小助手微信:CV_LAB,备注学校/公司+姓名+研究方向即可加入工坊一起学习进步。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK