

Stating P=NP Without Turing Machines
source link: https://rjlipton.wpcomstaging.com/2010/06/26/stating-pnp-without-turing-machines/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Stating P=NP Without Turing Machines
A statement of P=NP that uses only linear equations and their generalizations
George Dantzig is famous for the invention of the simplex method for solving linear programming problems.
Today I plan on presenting a definition and explanation of P=NP, but avoid the usual technical details that seem to be needed to explain the problem. The approach will depend greatly on the famous linear programming problem and its generalizations.
Dantzig is a source of the “legend” that a student once solved an open problem that he thought was just a hard homework problem. I heard various versions over the years, but his story is apparently genuine. I quote his own words:
During my first year at Berkeley I arrived late one day to one of Neyman’s (Jerzy Neyman) classes. On the blackboard were two problems which I assumed had been assigned for homework. I copied them down. A few days later I apologized to Neyman for taking so long to do the homework – the problems seemed to be a little harder to do than usual. I asked him if he still wanted the work. He told me to throw it on his desk. I did so reluctantly because his desk was covered with such a heap of papers that I feared my homework would be lost there forever.
About six weeks later, one Sunday morning about eight o’clock, Anne and I were awakened by someone banging on our front door. It was Neyman. He rushed in with papers in hand, all excited: “I’ve just written an introduction to one of your papers. Read it so I can send it out right away for publication.” For a minute I had no idea what he was talking about. To make a long story short, the problems on the blackboard which I had solved thinking they were homework were in fact two famous unsolved problems in statistics. That was the first inkling I had that there was anything special about them.
I do wonder sometimes if P=NP will be solved this way. Not knowing that a problem is “impossible” must have some psychological advantage. Can we forget that P=NP is hard and take a fresh look at the problem? I wish.
Let’s turn to the explanation. If you know what a linear equation is, then I believe you will be able to follow my explanation of what “P” is, what “NP” is, and what “P=NP?” means. There will be no Turing machines mentioned anywhere—except here. This mention does not count. Even if you are an expert on P=NP, I hope you will like the approach I take here.
Linear Equations
In high school we all learned how to solve linear equations—at least we were “taught” how to solve such equations. No doubt given the equations
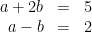
we could all solve the linear equations and get that 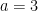

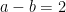
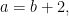
which implies
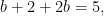
by substitution. This shows that 

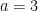
There is a systematic method of eliminating one variable at a time that was known to Carl Gauss over 200 years ago, and today we call his method Gaussian Elimination (GE). This algorithm (GE) is used everywhere, it is one of those fundamental algorithms that are central to computations of many kinds. If Gauss were alive today between royalties on GE and the Fast Fourier Transform, he would be very wealthy.
One of the central questions we need to understand the P=NP question is how to measure the efficiency of algorithms. One way to calculate the time GE requires is to count only the major operations of addition and multiplication that are performed. Let’s say we have 


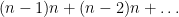
which adds up to order 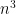
Linear Equations Over Non-Negative Numbers
In the above example of equations we did not say it explicitly, but we allowed rationals for the solution. The solutions for 

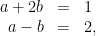
now has the solution 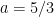
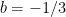
Many linear systems that arise in practice require that the solutions be non-negative. Suppose a company is trying to calculate how many trucks will be needed to haul their products, it is highly likely that that the values of the variables must be non-negative. It does not make any sense to use 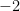
There is a fundamental difference and a fundamental similarity between plain linear equations (LE) and LP. You probably did not learn in school how to solve such systems. Even with a few variables the task of solving such a problem can be a challenge.
The surprise is we know something the great Gauss did not know. We have a method for solving LP instances that is fast—almost as fast as GE—for solving linear equations. The result is quite beautiful, was discovered after many doubted it existed, and is used today to solve huge systems. Just as GE has changed the world and allows the solution of linear systems, the ability to solve LP has revolutionized much of science and technology. The method is called the simplex method, and was discovered by George Dantzig in 1947.
One measure of the importance of the LP is it is one of the few mathematical results whose inventors were awarded a Nobel Prize. In 1975 Tjalling Koopmans and Leonid Kantorovich received this great honor. You might note that Dantzig did not win, and the reason for that is another story—see here for some insights. Another measure is the dozens of implementations of the algorithm that are available on the web—see this.
The computational cost of the simplex algorithm is surprisingly not much more than GE’s cost. In practice the running time is close to 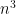
- The simplex algorithm is really a family of algorithms. The algorithms all move from vertex to vertex of a certain geometric object: usually there is a choice for the next step, and the running time is sensitive to this choice. For some choices it is known to be slow, and for other choices it works well in practice. Even more complex there are choices that are open whether they always run fast.
- The simplex algorithm is not the only way to solve LP’s in practice or in theory. I will not get into a discussion of the algorithms that have provable fast running times.
Linear Equations Over Natural Numbers
Linear systems can model even more interesting problems if we allow the solutions to only be natural numbers. Now the variables must take on values from
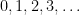
The reason this is so useful is one of the great insights of complexity theory. It was discovered by Gödel, Cook, Karp, and Levin. These problems are called Integer Programming Problems (IP). They can express almost any practical or theoretical problem. In many linear problems you can only allocate a whole number of something: try assigning 

We know more than Gauss, since we can solve LP’s. But we are not that smart. We are stuck at IP’s. We do not know how to solve these problems. The central point of the P = NP question is, does there exist an algorithm for these problems like there does for rational linear systems?
Put another way, does there exist an algorithm for IP’s that is like those for Gaussian Elimination and LP? This is the central question. A solution would have to take polynomial time—recall LE uses order 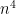
This fundamental question goes by the name of the “P=NP” question. The name is easy to say, “the P equal N P question,” and you can write it down quickly. Often we typeset it as
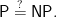
There are T-shirts for sale, in men’s and women’s sizes, that have this on their front. Alan Selman, a complexity theorist, has the license plate
P NE NP
Where I used to be a faculty member at Princeton, the Computer Science building has encoded in the bricks of the back of the building “P=NP?” in ASCII code. A flush brick stands for a 

You might want to know why the problem is called “P=NP?” and not the “Is there a fast way to solve integer programs problem?” Okay that would an awful name, but why not something better?
In mathematics there are several ways that problems get named. Sometimes the first person who states the problem gets it named after them; sometimes the second person. Sometimes problems are named in other ways.
Programming IP
We call LP, linear programming, and we call IP, integer programming. Both are real programming languages, even if they are different from standard programming languages.
A programming language allows one to express computational problems. The difference with LP and IP is that they are not universal languages, which means they cannot express all computations. They are not universal in the sense of Church—there are computations they cannot express.
Languages like C, C++, Perl, Python, and Java are universal languages. Anything can be expressed in them. This is both their advantage and their disadvantage. A universal language is great since it can do anything, but it also is subject to what Alan Perlis used to call the “Turing tar-pit.” Beware of the Turing tar-pit in which everything is possible but nothing of interest is easy.
The dilemma is that if a language is more powerful, then many more problems are expressible in the language, but fewer properties can be efficiently checked. If a problem can be written as a LP problem, than we know we can determine efficiently if it has a solution. If, on the other hand, a problem can only be written as an IP problem, then we cannot in general determine if the problem has a solution. This is the dilemma: one trades power of expression for ease of solution. But both LP and IP are much more powerful then you might think.
LP can solve many important problems exactly, and even more problems can solved approximately. IP can do just about anything that arises in practice. For example IP can be programmed to do all of the following:
- Break the AES encryption standard.
- Factor an integer, and thus break the RSA public key system.
- Find a 3-edge coloring of a graph, if one exists.
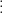
Programming Tricks
Just like any other programming language there are “tricks” in programming IP. To be a master IP programmer is not trivial, and I would like to present just a few simple tricks, and then show how to use them to solve 3-edge coloring on a cubic graph.
As an IP programmer one trick is to be able use inequalities. This is really simple: if we want the inequality
then we add a new variable 
Clearly, (1) is true if and only if (2) is true. A common use of this is to force variable 
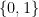
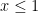
Here is another cool trick. Suppose we want to constrain 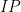

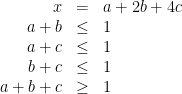
where 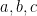
Now suppose 



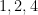
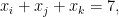
where 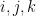
Suppose there is a solution 


Limits on the Power of IP
I have said that IP can handle just about any problem you can imagine. There are some limits on its power. For example, there is no way to add constraints so that variables 
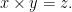
This is a curious result that seems “obvious,” but I do not know a simple proof. I would be interested in a simple proof, but for now let’s just say that there is no way to define multiplication.
Complexity Theory
For those who know some complexity theory, the approach I have taken to explain P=NP may seem a bit strange. I hope even if you are well versed in complexity theory you will still enjoy the approach I have taken here.
In complexity theory the class of problems solved by LP is essentially all of P, and the class of problems solved by IP is all of NP. The advantage of the approach here is that P=NP can be viewed as asking the question: Can all IP problems be programmed as LP problems? Note, to make this a precise question does require the notion of reduction. I will not define that precisely here, but imagine that the changing an IP problem to an LP problem must be a reasonable type of transformation.
Conventional Wisdom
Most theorists seem to be sure that IP cannot be solved efficiently. One of the many reasons for this is the power of IP as a programming language. There is just too much power, which means that if it were easy to solve, then too many problems would be easy.
I wonder before GE was discovered would many have thought that LE’s are hard to solve, or before simplex was discovered would many have thought that LP’s were impossible to solve?
One approach that many have tried to resolve P=NP is to encode IP problems into LP problems. The obvious difficulty is that a solution to a set of equations may have some of its variables set to proper rationals. The idea many have tried is to make the linear equations so “clever” that there is no way that solutions can be fractional. No one has yet shown a general method for doing this, which does not mean it is impossible, but it does mean it is hard.
Open Problems
Does this discussion help? Or is it better to present P=NP in the normal way? What do you think?
Here is what we know,
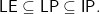
Most believe that all these subset relationships are strict, but it is possible that they all are equal. This is one of the great mysteries of complexity theory.
[fixed typo]
Like this:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK