

带你了解几种二进制代码相似度比较技术
source link: https://my.oschina.net/u/4526289/blog/5371540
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

带你了解几种二进制代码相似度比较技术 - 华为云开发者社区的个人空间 - OSCHINA - 中文开源技术交流社区
摘要:二进制分析技术通常被用来对应用进行安全审计、漏洞检测等,通过分析学术界近20年发表的上百篇学术论文来分析二进制代码相似度比较都有采用了哪些具体技术,二进制代码相似度比较的技术挑战是什么,后续的研究方向是什么,希望此文能给做这方面技术研究人做参考。
本文分享自华为云社区《二进制代码相似度比较研究技术汇总》,作者:安全技术猿 。
在对二进制应用程序进行安全分析过程中,二进制代码相似度比较技术是重要的技术手段之一,基于此技术,可以实现对恶意代码极其变种的追踪,已知漏洞检测、补丁存在性检测。该技术基础理论依据是如果源代码中存在的属性(恶意代码、已知漏洞、漏洞修复补丁)即使相同源代码编译出不同的二进制代码(cpu架构、OS、编译选项等会直接导致编译出来的二进制会存在较大的差别),这些属性在二进制代码中也是存在的(好像是废话,不然编译构建工具就有问题了)。因此若在一个样本二进制文件中已知存在上述类型的属性,如果发现另外一个待检测二进制代码和样本二进制代码相似,那么可以认为待检测二进制代码也存在相同类型的属性。
我们知道编译生成二进制代码的影响因素非常的多,同一套源代码基于不同因素的组合可以生成非常多不同二进制程序。
CPU架构:X86、ARM、MIPS、PPC、RISC-V;
架构位数:32bits、64bits;
OS:Linux、Windows、Android、鸿蒙、VxWork;
编译选项:O0~O3;
安全编译选项:BIND_NOW、NX、PIC、PIE、RELRO、SP、FS、Ftrapv等;
按这些选项可以有5x2x5x4x8 =1600个组合,从中可以看出二进制代码相似度比较技术不管是学术界还是工业界来说都是一个挑战技术。但是基于广阔的应用前景,20多年来学术界一直在不停的探索和研究新的方法想来解决这个技术挑战,并且也取得了一定的成果,下面就该方面的技术进行一些梳理,让大家对二进制代码相似度比较技术有一个大致的了解。
源代码到二进制代码的生成过程
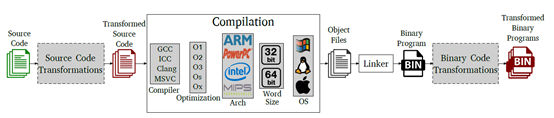
从源代码编译生成二进制过程中,有很多有助于理解代码意图的信息会被丢失,比如:函数名称、变量名称、数据结构定义、变量类型定义、注释信息等;因为二进制代码是给CPU运行用的,因此这些信息对计算机来说不是必须的,但这些信息对人类来理解代码是有很大帮助的,这就大大的提升了二进制代码语义理解的难度。其次,为了更好的保护二进制代码的知识产权或最大程度的提升对二进制代码的理解难度,还会对二进制代码进行混淆处理,使得混淆后的二进制代码与编译器编译出来的二进制之间又存在很大的不同。
从历史发表的二进制代码相似度比较技术论文统计来看,有61种二进制代码相似性比较方法,这些在不同研究场所发表的数百篇论文涵盖了计算机安全、软件工程、编程语言和机器学习等计算机科学领域,主要发表在IEEE S&P、ACM CCS、USENIX Security、NDSS、ACSAC、RAID、ESORICS、ASIACCS、DIMVA、ICSE、FSE、ISSTA、ASE、MSR等顶级刊物上。根据上述论文得到如下统计数据:
输入比较:一对一(21种)、一对多(30种)、多对多(10种);
比较方法:大多数方法使用单一类型的比较:相似性(42种)、等效性(5种)和相同(2种);即使方法中仅使用一种类型的比较,它也可能有不同的输入比较不同;
分析粒度:分为输入粒度、方法粒度;有8中不同的比较粒度,分别是指令级、基本快、函数以及相关集合、执行轨迹、程序。最常见的输入粒度是函数(26个),然后是整个程序(25个)和相关的基本块(4)。最常见的方法粒度是函数(30个),然后是基本块(20);
语法相似性:通过语法方法来捕获代码表示的相似性,更具体地说,它们比较指令序列。最常见的是序列中的指令在虚拟地址空间中是连续的,属于同一函数。
语义相似性:语义相似性是指所比较的代码是否具有类似的效果,而语法相似性则是指代码表示中的相似性。其中有26种计算语义相似度的方法。它们中的大多数以基本块粒度捕获语义,因为基本块是没有控制流的直线代码。有三种方法用于捕获语义:指令分类、输入-输出对和符号公式。
结构相似度:结构相似性计算二进制代码的图表示上的相似性。它位于句法和语义相似性之间,因为图可以捕获同一代码的多个句法表示,并可以用语义信息注释。结构相似性可以在不同的图上计算。常见的有控制流图CFG、过程间控制流图ICFG、调用图CG;(子)图同构—大多数结构相似性方法是检查图同构的变化,其中涉及到方法有K子图匹配、路径相似性、图嵌入。
基于特征的相似度:计算相似性的常见方法(28种)是将一段二进制代码表示为向量或一组特征,使得类似的二进制代码具有相似的特征向量或特征集。这里应用最多的是利用机器学习来实现。
Hash匹配相似度:对于多维向量数据相似度快速匹配,通常使用局部敏感hash算法LSH来实现。
跨架构比较方法:对不同CPU架构二进制代码的相似度比较,通常跨体系结构方法通过计算语义相似性来实现。方法之一是通过转换成与架构无关的中间语言IR来处理(7种),另外一种是使用基于特征的相似性方法(9种)。
分析类型:从分析类型来看有:静态分析、动态分析、数据流分析3种类型;
归一化方法:语法相似性方法通常会对指令进行规范化,来尽量减少语法上的差异;有33种方法使用指令规范化。具体的包括操作数移除法、操作数归一化法、助记符归一化法。
论文发表的时间、发表刊物、技术方法汇总
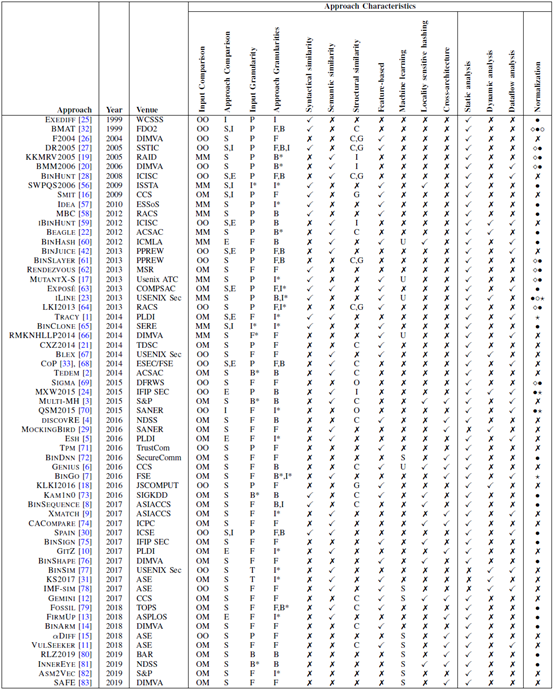
不同二进制代码相似度比较方法的具体应用情况
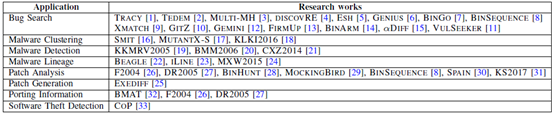
从上表中可以看出二进制代码相似度比较主要应用于漏洞查找,其次是补丁分析和恶意代码分析;
针对上述不同的技术方法,分别从鲁棒性、准确度评估与比较、性能指标3个维度进行评测,结果如下:
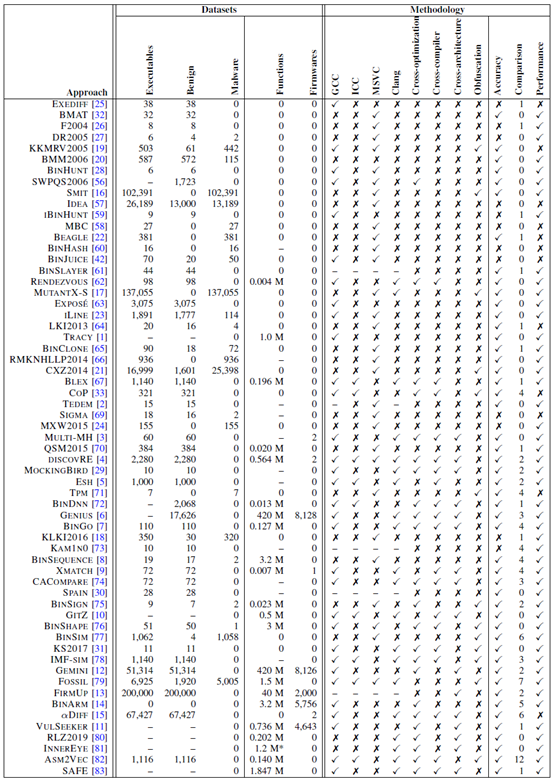
总结:
二进制代码相似性比较技术随着研究的持续进行,学术界虽然取得的一定的进步和成果,但仍然还有很多挑战在等着攻克,小片段的二进制代码比较,源代码与二进制的相似度比较、数据相似度比较、语义关系、可扩展性、混淆、比较方法等等都是后续需要持续研究的方向。
参考文献:
《A Survey of Binary Code Similarity》
可以试试下面的漏扫服务,看看系统是否存在安全风险:>>>漏洞扫描服务
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK