

ClickHouse集群数据均衡方案分享
source link: https://segmentfault.com/a/1190000041100691
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

ClickHouse集群数据在写入时,虽然可以通过Distributed引擎的sharding_key指定策略,从而保证一定程度的数据均衡,但这并不是最终解决方案。
比如rand()均衡策略虽然可以保证数据的相对均衡,但是可能会破坏数据的内在业务逻辑。举个简单的例子,我们想要将kafka的数据写入clickhouse集群,如果采用rand()的策略,则可能将同一个partition的数据拆分到clickhouse集群不同的shard中,为后续的数据分析等造成了一定的麻烦。
虽然有类似clickhouse-sinker之类的数据导入工具,可以做到数据导入时的均衡,但是一旦集群扩展了节点,仍然无法将存量数据均衡到新增加的节点中去。这样就造成了存量节点的数据仍然很多,新增节点的数据相对较少,并不能起到很好的负载均衡的作用。
数据均衡方案探讨
我们在讨论数据均衡方案的时候,首先需要明确两个前提:
- 针对
clickhouse集群,而不是单点 - 针对
MergeTree家族的引擎数据(其他引擎的数据表由于无法通过分布式表去读写,因此也不具备数据均衡的意义)
我们知道,clickhouse存储数据是完完全全的列式存储,这也就意味着,在同一个partition下,数据很难再一条条的进行拆分(虽然可以做到,但比较麻烦)。因此,数据均衡最科学的方案是以partition为单位,整个partition进行搬迁。这也就意味着,分区的粒度越小,最终的数据越接近均衡。
另一个我们要思考的问题就是,如果其中某一个分区我们一直在写入数据,我们是无法获取该分区的实际大小的(因为一直在变化)。那么,如果该分区数据也参数数据均衡的话,可能参与均衡的partition并不是一个完整的分区,就会导致分区数据被拆散,从而造成不可预知的问题。所以,我们希望最新的一个分区,不参与数据均衡的运算。
如何能获取到最新的分区呢?其实可以通过SQL查询到:
SELECT argMax(partition, modification_time) FROM system.parts WHERE database='?' AND table='?'
以上SQL查询出来的,就是指定的数据库表最新的分区。将这个分区排除在外,那么剩下的分区就是都可以参与数据均衡的分区了。
另一个核心问题是,如何将partition数据在不同节点之间进行移动?我们很容易想到 attach 和detach,但attach和detach的前提是,我们必须要设置配置文件中当前操作用户allow_drop_detached标志为1。对于带副本的集群,我们总能通过zookeeper的路径非常方便地将分区数据在不同节点间fetch过来。
-- 在目标节点执行
ALTER TABLE {{.tbname}} FETCH PARTITION '{{.partition}}' FROM '{{.zoopath}}'
ALTER TABLE {{.tbname}} ATTACH PARTITION '{{.partition}}'
-- 在原始节点执行
ALTER TABLE {{.tbname}} DROP PARTITION '{{.partition}}'但是对于非副本模式的集群则没那么简单了。因为我们无法知道zoopath,所以不能通过fetch的方式获取到数据,因此,只能使用物理的方式将数据进行传输(比如scp, rsync等)到指定节点上。考虑到传输效率,这里我们使用rsync的方式。
-- 原始节点执行
ALTER TABLE {{.tbname}} DETACH PARTITION '{{.partition}}'# 原始节点执行
rsync -e "ssh -o StrictHostKeyChecking=false" -avp /{{.datapath}}/clickhouse/data/{{.database}}/{{.table}}/detached dstHost:/{{.datapath}}/clickhouse/data/{{.database}}/{{.table}}/detached
rm -fr /{{.datapath}}/clickhouse/data/{{.database}}/{{.table}}/detached-- 目标节点执行
ALTER TABLE {{.tbname}} ATTACH PARTITION '{{.partition}}'
-- 原始节点执行
ALTER TABLE {{.tbname}} DROP DETACHED PARTITION '{{.partition}}'但是,通过rsync的方式需要有前提,那就是首先必须在各个节点上已经安装过rsync工具了,如果没有安装,可通过下面的命令安装:
yum install -y rsync
其次,需要配置各节点之间的互信(主要是moveout的节点到movein节点之间的互信,但其实我们并不知道数据在节点间数如何移动的,因此最好全部配置)。
以上问题解决后,那么就剩下最核心的一个问题了。数据如何均衡?
这里需要说明的是,由于是整个partition的移动,因此,无法做到绝对的均衡,而是只能做到相对的数据均衡。partition的粒度越小,均衡越精确。
一种比较科学的方案是,将各个节点的分区数据按大小排列之后,将最大的节点数据移动到最小的节点中去,次大的节点移到次小的节点,以此类推,不断向中间靠拢,直到满足某一个阈值,则不再移动。
这一段的代码实现我们已经通过ckman项目开源出来了,如果感兴趣的朋友可以通过下面的链接阅读源码:ckman:rebalancer。
因此,不难发现,数据均衡的过程中,分区数据由于可能已经被
detach,但是还没来得及在新的节点上attach,这时候去做查询,可能存在一定几率的不准确。所以,在做数据均衡的过程中,最好不要有查询操作。
插入操作反而不受影响,因为我们已经排除了最新的分区不参与均衡运算。
ckman如何实现数据均衡
ckman作为一款管理和监控ClickHouse集群的可视化工具,天然集成了数据均衡的功能。只需要点击集群管理页面的"均衡集群"按钮,即可实现数据均衡的操作。
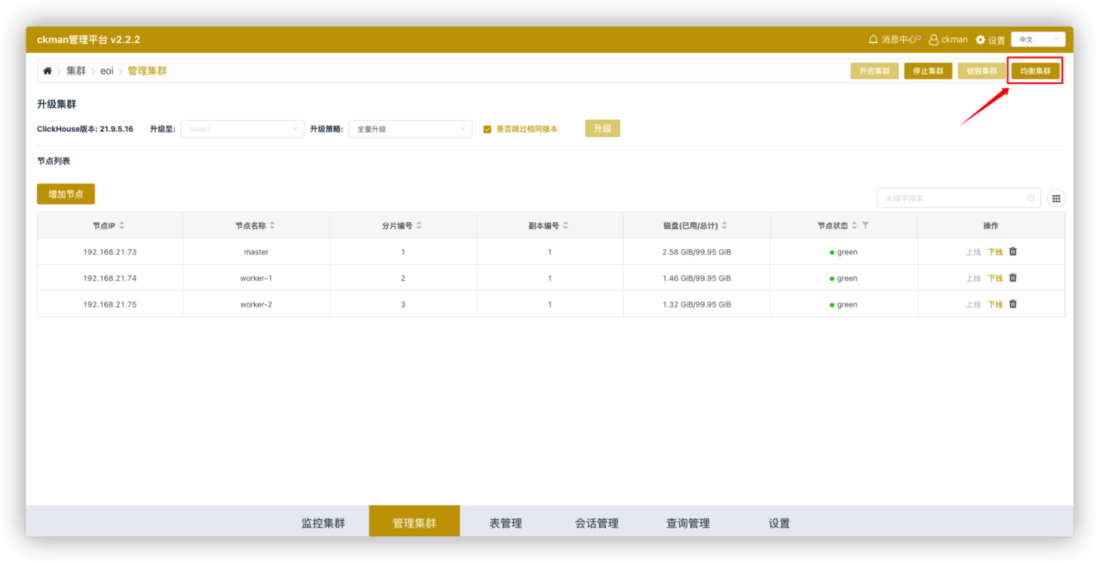
与此同时,ckman还提供了命令行方式的数据均衡工具rebalancer, 其参数如下:
-ch-data-dir
clickhouse集群数据目录
-ch-hosts
- 节点列表(每个
shard只需列出一个,如果shard有多个副本,无需全部列出)
-ch-password
clickhouse用户密码
-ch-port
clickhouse的TCP端口,默认9000
-ch-user
clickhouse的用户,界面操作时,使用default用户
-os-password
- 节点的
ssh登录密码(非副本模式时需要)
-os-port
- 节点的
ssh端口,默认22(非副本模式时需要)
-os-user
- 节点的
ssh用户(非副本模式时需要)
rebalancer -ch-data-dir=/var/lib/ --ch-hosts=192.168.0.1,192.168.0.2,192.168.0.3 --ch-password=123123 --ch-port=9000 --ch-user=default --os-password=123456 --os-port=22 --os-user=root
我们在ckman中准备了一个名为eoi的集群,该集群有三个节点,分别为192.168.21.73,192.168.21.74,192.168.21.75,集群为非副本模式。
我们从官方文档给出的数据集中导入如下数据:https://clickhouse.com/docs/e...
该数据是从2019年1月到2021年5月,共计30个月的航空数据,为了更直观地展示数据均衡,本文将官方的建表语句做了微调,按照月进行分区,并且在集群各个节点都创建表:
CREATE TABLE opensky ON CLUSTER eoi
(
callsign String,
number String,
icao24 String,
registration String,
typecode String,
origin String,
destination String,
firstseen DateTime,
lastseen DateTime,
day DateTime,
latitude_1 Float64,
longitude_1 Float64,
altitude_1 Float64,
latitude_2 Float64,
longitude_2 Float64,
altitude_2 Float64
) ENGINE = MergeTree
PARTITION BY toYYYYMM(day)
ORDER BY (origin, destination, callsign);并创建分布式表:
CREATE TABLE dist_opensky ON CLUSTER eoi AS opensky ENGINE = Distributed(eoi, default, opensky, rand())
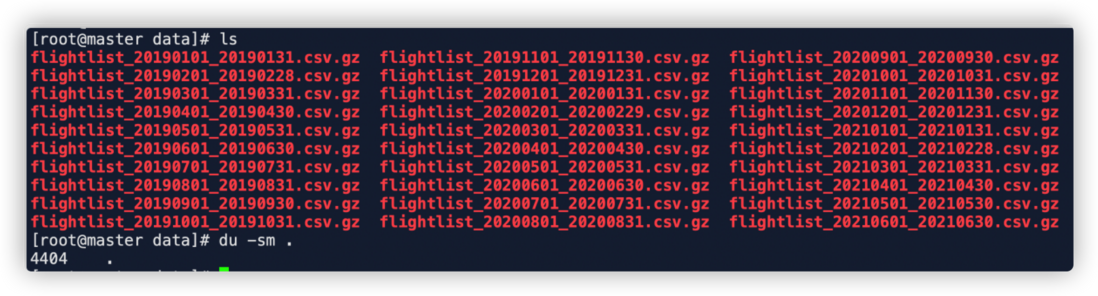
下载数据:
wget -O- https://zenodo.org/record/5092942 | grep -oP 'https://zenodo.org/record/5092942/files/flightlist_\d+_\d+\.csv\.gz' | xargs wget
数据下载完成大约4.3G。
使用下面的脚本将数据导入到其中一个节点:
for file in flightlist_*.csv.gz; do gzip -c -d "$file" | clickhouse-client --password 123123 --date_time_input_format best_effort --query "INSERT INTO opensky FORMAT CSVWithNames"; done
导入完成后,分别查看各节点数据如下:
-- 总数据 master :) select count() from dist_opensky; SELECT count() FROM dist_opensky Query id: b7bf794b-086b-4986-b616-aef1d40963e3 ┌──count()─┐ │ 66010819 │ └──────────┘ 1 rows in set. Elapsed: 0.024 sec. -- node 21.73 master :) select count() from opensky; SELECT count() FROM opensky Query id: 5339e93c-b2ed-4085-9f58-da099a641f8f ┌──count()─┐ │ 66010819 │ └──────────┘ 1 rows in set. Elapsed: 0.002 sec. -- node 21.74 worker-1 :) select count() from opensky; SELECT count() FROM opensky Query id: 60155715-064e-4c4a-9103-4fd6bf9b7667 ┌─count()─┐ │ 0 │ └─────────┘ 1 rows in set. Elapsed: 0.002 sec. -- node 21.75 worker-2 :) select count() from opensky; SELECT count() FROM opensky Query id: d04f42df-d1a4-4d90-ad47-f944b7a32a3d ┌─count()─┐ │ 0 │ └─────────┘ 1 rows in set. Elapsed: 0.002 sec.
从以上信息,我们可以知道,原始数据6600万条全部在21.73这个节点上,另外两个节点21.74和21.75没有数据。
从ckman界面可以看到如下信息:

然后点击数据均衡,等待一段时间后,会看到界面提示数据均衡成功,再次查看各节点数据:
-- 总数据 master :) select count() from dist_opensky; SELECT count() FROM dist_opensky Query id: bc4d27a9-12bf-4993-b37c-9f332ed958c9 ┌──count()─┐ │ 66010819 │ └──────────┘ 1 rows in set. Elapsed: 0.006 sec. -- node 21.73 master :) select count() from opensky; SELECT count() FROM opensky Query id: a4da9246-190c-4663-8091-d09b2a9a2ea3 ┌──count()─┐ │ 24304792 │ └──────────┘ 1 rows in set. Elapsed: 0.002 sec. -- node 21.74 worker-1 :) select count() from opensky; SELECT count() FROM opensky Query id: 5f6a8c89-c21a-4ae1-b69f-2755246ca5d7 ┌──count()─┐ │ 20529143 │ └──────────┘ 1 rows in set. Elapsed: 0.002 sec. -- node 21.75 worker-2 :) select count() from opensky; SELECT count() FROM opensky Query id: 569d7c63-5279-48ad-a296-013dc1df6756 ┌──count()─┐ │ 21176884 │ └──────────┘ 1 rows in set. Elapsed: 0.002 sec.
通过上述操作,简单演示了数据均衡在ckman中的实现,原始数据6600万条全部在node1,通过均衡之后,其中node1数据为2400万条,node2位2000万条,node3位2100万条,实现了大致的数据均衡。
虽然我们可以通过ckman之类的工具可以实现数据的大致均衡,大大改善了操作的便利性,但数据均衡本身就是一个非常复杂的命题,一旦涉及到存储策略(如数据存储在远端HDFS上),那么又会增加数据均衡的复杂性,这些都是ckman目前所不能支持的操作(远程数据做数据均衡没有意义,但是可以均衡其元数据,这样可以在查询时充分利用各节点的CPU性能)。因此,数据均衡想要做得科学而精确,仍然需要更多的努力。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK