

ScaleFlux郑宁:可计算型存储的应用案例研究
source link: http://www.dostor.com/p/78927.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

ScaleFlux郑宁:可计算型存储的应用案例研究-存储在线
11月23日-25日,由百易传媒(DOIT)主办,中国计算机学会信息存储专委会、中国计算机行业协会信息存储与安全专委会、华中科技大学武汉光电国家研究中心、固态技术协会(JEDEC) 等机构支持,主题为“数据觉醒”的“2021(十七届)中国数据与存储峰会”盛大召开。
此次峰会首次改为全程线上举办,活动为期三天,在第二天数据智能论坛上,ScaleFlux软件系统负责人郑宁发表了《可计算型存储的应用案例研究》主题演讲围绕透明压缩,专用硬件下的可计算存储及通用硬件下的可计算存储介绍可计算存储在实际应用中的案例研究。

以下内容根据速记整理,未经本人审定:
可计算存储是这几年热门讨论的话题。通常IT系统主要功能部件包括三大部分——计算、网络、存储。计算部分,主要指CPU,随着摩尔定律的失效,每年CPU的算力增长非常有限,无法满足应用需求,因此才有了各种加速卡的出现,这些加速卡可能是基于FPGA或者基于GPU、TPU,为了在某个特定领域极大卸载CPU计算压力,从而提升整个系统能效比。
网络也面临同样的问题,传统网络需要CPU运行一系列网络协议实现网络传输,但这一方面浪费CPU计算资源,另一方面也使网络带宽受限,智能网卡的出现大大缓解了这个问题,卸载CPU网络相关功能,同时又把网络传输带宽提升了一个数量级。
再看存储,物联网时代已经到来,每天都有海量数据产生,如何对这些数据进行存储和访问,对系统而言是非常重要的一环。可喜的是随着高性能、大容量的SSD逐渐普及,现在的一台机器上可以部署十几张存储卡,整体可提供几十甚至上百TB存储空间,存储带宽和访问延迟相比HDD都得到了极大改善。
随之而来的问题就是如何对这些海量数据进行处理,这就对CPU提出非常大的挑战,可计算存储便应运而生。
ScaleFlux作为可计算存储领域的先驱厂商,一直致力于提升应用及基础设施附加值,具体来说我们希望产品可以在以下三个方面达成一个目标。
第一,扩展负载容量的同时,也能够线性扩展性能;第二,优化基础设施的成本;第三,能够灵活适配应用,紧跟应用需求。
可计算存储设备本质上重新定义了存储和计算的软硬件边界,在把可计算存储推向实际应用的过程中,我们必须要解决以下几个问题。
第一,存储设备内的计算能力到底有多少,因为我们本质上是想把主机端CPU的计算能力卸载到近存储这一边,所以说如果这个存储设备没有足够算力,那么属于无效卸载。
第二,可计算存储到底能给我们整个系统带来多少性能收益,这与我们所卸载的计算紧密相关,我们希望卸载的计算对整个系统来讲占有比较大的权重,这样性能收益才会比较明显。
第三,我们使用可计算存储设备所解决的这个问题,适用范围到底有多广。最后一点,ScaleFlux重新划分了软硬件的边界,顶层底层需要协同设计,这个协同设计的复杂度到底有多高,如果复杂度高,很可能会成为可计算存储设备落地的一个障碍。
下面我们就具体的从几个方面来介绍一下ScaleFlux在可计算存储方面所做得一些尝试。
第一点,透明压缩。此前实现压缩功能最常见的办法是软件压缩,就是使用CPU运行软件代码实现压缩效果。通常我们可以看到应用中已经集成了多种多样的压缩算法,本质上是在压缩率和压缩吞吐之间做一个取舍,压缩率很好的算法如ZLIB,GZIP压缩复杂度比较高,所以说相对来说它的压缩吞吐会比较低,还有压缩比较快的那些算法,像SNAPPY,LZ4的压缩效果又不太好。
整体来讲,这些软件压缩的缺点是占用CPU资源,如果我们想用压缩效果比较好的压缩算法,其速度就往往较慢,很可能会成为整个系统的瓶颈。既想达到比较好的压缩效果,又能够使压缩带宽较大,就需要压缩加速卡。压缩加速卡是把压缩和解压缩功能从CPU卸载到专门的压缩卡上,以此实现压缩率和压缩吞吐间比较好的平衡。
但单张压缩加速卡的压缩吞吐有上限,基本远低于存储系统所能够提供的带宽,因此为了进一步提升压缩带宽,我们需要在一台机器里插入多张压缩加速卡,占用额外的槽位,也就是要减少相应存储设备数量,导致系统可能得不偿失。
为了解决这个问题,ScaleFlux提出了透明压缩,把压缩和解压缩功能直接集成到SSD的主控里,当主机端向存储设备写入数据时,这些数据首先会在主控里进行压缩,压缩完再写入NAND,当主机端需要读取数据,主控首先会从NAND上读取压缩后的数据,经过解压缩再返回到上层应用。
所以从应用端来讲,整个压缩和解压缩的过程,是完全透明的,这就是为什么我们叫它透明压缩。当然透明压缩已经具备了之前压缩加速卡的一些特性,比如压缩带宽较高,其自身的额外优势是不需要额外的槽位,因此在增加存储设备时,其压缩和解压缩的能力,也就得到了相应的扩展,而真正落到NAND上的数据量减少,相对延长了SSD的使用寿命,另外还可以提升应用性能,后面我们会专门介绍到这一部分。
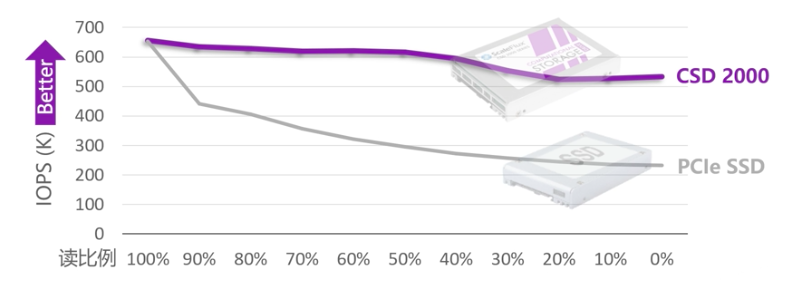
使用透明压缩,具体有什么效果,这张图给了我们一个量化的说明,我们对比了具有透明压缩功能的CSD 2000和市面上普通的PCIe SSD两种产品,测试场景是2.5:1的数据压缩比,8个jobs,32个队列深度的4KB稳态性能下的对比,然后通过这个图我们可以看到,图中纵轴是IOPS,也就是每秒操作数,这个数值越高越好,横轴代表读写操作中读的比例,最左边的100%对应的是纯读的场景,最右边的0%对应的是纯写的场景。
可以看出,使用了透明压缩的CSD 2000,性能上具有很大的优势,尤其是在读写混合的场景下,当我们的写比例超过50%的时候,基本上CSD 2000在稳态下的性能是普通PCIeSSD的2倍左右,所以也希望借着透明压缩可以给用户提供更优秀的混合读写性能,更低的单位存储价格以及更简单的顶层应用集成。
针对数据库上的应用,我们对比了MySQL和PostgreSQL两款最常见数据库的场景,使用透明压缩后可以节约50%以上的存储空间,同时也可以提供更好的性能。
我们还希望可计算存储可以承担一些其他的计算逻辑,这些计算逻辑可以由专用的硬件来完成,也可以由通用的硬件完成,专用硬件是面向特定领域专门设计而成,因此可以比较容易的实现更高的并行度和吞吐率,这里的以行存数据库中间的数据过滤作为例子,对专用硬件下的可计算存储做一个说明。
这里专用硬件主要承担的是列投影和行过滤的功能,列投影主要指是在扫描数据的时候,选择出那些上层查询感兴趣的列,不敢去的列直接过滤掉,行过滤主要指当某一行不满足上述的查询条件直接过滤掉,如果有可能满足,再选上。
我们右边通过了一个简单的查询语句,对列投影和行过滤的概念做一个说明,在查询语句中,我们是选择了三个列,ORDERKEY、EXTENDEDPRICE和DISCOUNT,上层只对这三个列感兴趣,这三个列在可计算存储内部就直接被过滤掉了,所以叫做列投影。
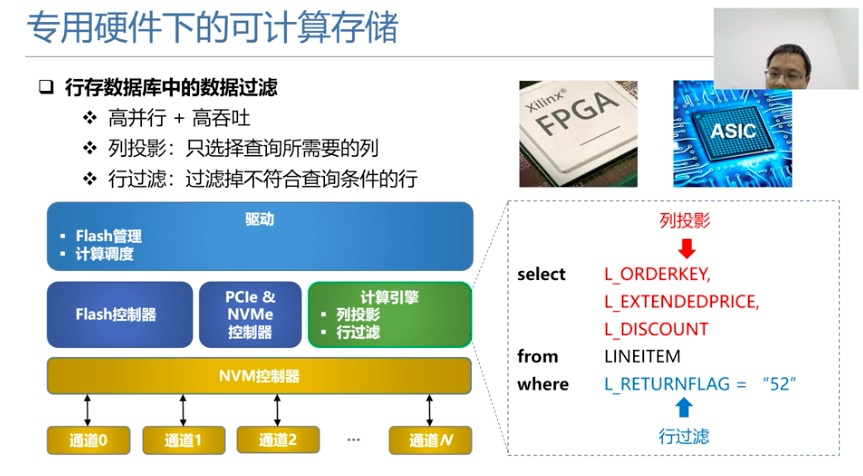
同时我们查询,还有一条额外的条件语句,也就是RETURNFLAG的值必须是52,如果不是52也就是不满足上层的查询条件,我们也会在扫描的时候,把这一行整个过滤掉,这个就叫做行过滤。
那么通过列投影和行过滤,我们希望可计算存储达到这样一个效果,首先就是可以极大减少从可计算存储内部传输到主机端的数据量,第二个就是减少PCIe带宽和内存带宽的占用,第三就是大大减轻主机端CPU在后续处理时的压力。
专用硬件虽然可以实现较好的计算卸载功能,但设计复杂度高,所以我们也要思考在通用硬件下是否能实现类似的近存储计算。具体到可计算存储设备,这里的通用硬件指的是ARM处理器或RISC-V处理器,但相对现有主机CPU计算力较弱。
如果我们想通过计算卸载来获得整个系统性能的提升,承担计算卸载的计算单元,其计算能力一般是要大于主机端CPU计算能力,只有在这种情况下,才有可能使整个系统产生一个比较好的效率。但是现在我们所面临的情况,我们可计算存储设备内的计算单元,有可能它的计算能力是弱于主机端CPU的,在这种情况下,还有没有可能实现一个比较有效的近存储计算呢?
这里我们以列存数据库中的数据作为例子进行探讨,列存数据库,就是把数据按照列的形式,紧密的排列,进而进行存储,通过这种方式,一是有利于数据压缩,第二,当上层查询需要访问数据的时候,可以直接访问感兴趣的那些列,不感兴趣的列不需要过滤,就直接不读了。
那么现在由于可计算存储设备内部的计算单元计算能力比较弱,所以我们尽量需要避免对数据元素依次进行扫描,否则其计算逻辑与主机端的CPU相同,很可能导致整体性能不升反降。
取而代之的,我们不对单个元素进行过滤,而是对数据段进行过滤,一个数据段包含多个数据元素,如果某个数据段内有满足上层查询条件,我们就把整个数据段进行选择,如果不满足上层的查询条件,整个数据段就会被舍弃,如何快速对数据段进行一个判断,这里所给出的一种方法,就是引入了国外的辅助元数据,这些辅助元数据在当初写数据的时候,我们就已经嵌入到列存数据库里,辅助元数据就包含数据段内数据分布的一个总结。
通过这种方式,我们也可以达到像之前专用硬件下的数据过滤类似的效果,在可计算存储设备内部进行一些预过滤,实现从存储设备返回到主机端的数据量也会减少。
本质上这种方法是在过滤的精确度或带宽之间做了一个取舍,最终目的就使得我们虽然可计算存储设备内的计算能力比较弱,但能够提供的扫描吞吐依然可以匹配,甚至大于上层主机端的扫描速度。
我们也对这种方法进行了一些评估,这里所使用的原始数据还是TPC-H Lineitem表,数据库使用的是列存数据库,当前比较热的一款引擎Click House,处理器是ARM Cortex A53处理器。
我们今天的分享到此结束,谢谢大家。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK