

超越最新视频压缩标准H.266,字节跳动编码新技术让视频缩小13%
source link: https://developer.aliyun.com/article/822623
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

超越最新视频压缩标准H.266,字节跳动编码新技术让视频缩小13%
来自:机器之心 2021-12-05 19

视频编解码是视频应用的底层核心技术,作用是对图像进行压缩和数字编码,以尽可能小的带宽传送尽可能高质量的视频数据。H.264 是现在被广泛使用的视频编解码标准,在同等视频质量下,H.265/HEVC 标准可以让视频体积减小一半。H.265 尚未完全普及,新一代标准 H.266/VVC 比 H.265 让视频又减小一半。
这并不是视频编码技术的尽头。
今年初,字节跳动先进视频团队(AVG)向联合视频专家组 JVET 发起了一项 JVET-U0068 技术提案,可以为视频压缩的三个颜色分量(Y, U, V)分别实现约 10%、28%、28% 的性能增益,这是业界公开的单个智能编码工具的最佳性能增益。在优化压缩质量的同时,视频体积相比 H.266 最新标准至少还可以缩小 13%。就其实际效果而言,如果新技术得以应用,与现在主流的 H.264 标准相比,我们看同样质量的视频,大约只需要 22% 的带宽和存储空间。
这项技术名为 DAM(Deep-filtering with Adaptive Model-selection),它是通过深度学习技术构建减少视频压缩失真的滤波器,主干是基于残差单元堆叠的深度卷积神经网络,辅以自适应模型选择以最大程度适应特性复杂的自然视频。该技术由字节跳动 AVG 的美国加州研发团队实现,成员来自高通、英特尔、微软等巨头以及海内外多家顶级院校。
我们先从下图示例中对比 H.264 与 H.266+DAM 的视频压缩效果:

可以看到,相同压缩比条件下,H.266+DAM 编码压缩质量远远优于 H.264。
除了视频压缩质量提升之外,应用 DAM 技术可以比H.266再缩小 13% 的数据体积,以下图片来自国际标准组织的测试视频。其中,图(左)为原图,每像素 12 字节;图(中)使用 VTM11.0 压缩(qp=42),每像素 0.00216字节,峰值信噪比 27.78dB;图(右)使用 VTM11.0+DAM(qp=42),每像素 0.00184 字节,峰值信噪比 28.02dB。
对比图(中)和图(右)可以看出,应用 DAM 技术后,图(右)压缩比更高,峰值信噪比(客观质量)更好,主观质量也相对更好。

图1. 左:原图, 12bpp,中:VTM-11.0压缩,QP42,0.00216bpp,27.78dB,右:VTM-11.0+DAM,QP42, 0.00184bpp,28.02dB
技术细节
DAM 的构建方法
提案 JVET-U0068 所介绍的 DAM 是字节跳动 AVG 此前一项提案 JVET-T0088 的扩展版本。
在具体实现上,为了减轻深度网络的训练难度,DAM 算法利用残差单元作为基本模块,并多次堆叠来构建最终网络。所谓残差单元是指通过引入跳层连接,允许网络把注意力放在变化的残差上。为了处理不同类型的内容,新技术针对不同类型的 slice 和质量级别训练不同网络。此外,还引入了一些新特性来提高编码性能。
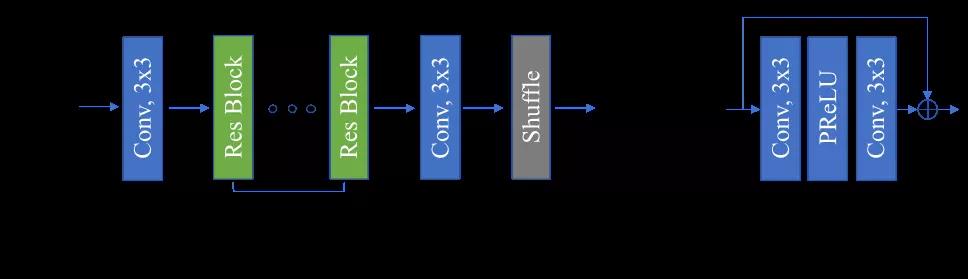
图 1:(a)是卷积神经网络滤波器的架构,M 代表特征图的数量,N 代表特征图的空间分辨率;(b)是(a)中残差块的结构。
DAM 滤波方法的主干如上图 1 所示,为了增加感受野,降低复杂度,此方法包含一个步幅为 2 的卷积层,该层将特征图的空间分辨率在水平方向和垂直方向都降低到输入大小的一半,这一层输出的特征图会经过若干顺序堆叠的残差单元。最后一个卷积层以最后一个残差单元的特征图作为输入,输出 4 个子特征图。最后,shuffle 层会生成空间分辨率与输入相同的滤波图像。
与此架构相关的其他细节如下:
- 对于所有卷积层,使用 3x3 的卷积核。对于内部卷积层,特征图数量设置为 128。对于激活函数,使用 PReLU;
- 针对不同 slice 类型训练不同的模型;
- 当为 intra slice 训练卷积神经网络滤波器时,预测和分块信息也被输入网络。
新特性:自适应模型选择
在 JVET-T0088 的卷积神经网络结构基础上,JVET-U0068 引入了以下几种新特性:
- 首先,每个 slice 或 CTU 单元可以决定是否使用基于卷积神经网络的滤波器;
- 其次,当某个 slice 或者 CTU 单元确定使用基于卷积神经网络的滤波器时,可以进一步确定使用三个候选模型中的哪个模型。为此目的,使用 {17,22,27,32,37,42} 中的 QP 数值训练不同模型。将编码当前 slice 或 CTU 的 QP 记作 q,那么候选模型由针对 {q,q-5,q-10} 训练的三个模型构成。选择过程基于率失真代价函数,然后将相关模式表征信息写入码流;
- 第三,基于卷积神经网络的滤波器在所有层都被启用;
- 最后,现有滤波器中的去块滤波和 SAO 被关掉,而 ALF(和 CCALF)则被置于基于卷积神经网络滤波器后面。
在线推断及训练
推断过程中使用 PyTorch 在 VTM 中执行 DAM 深度学习的在线推断,下表 1 是根据 JVET 建议给出的网络信息:
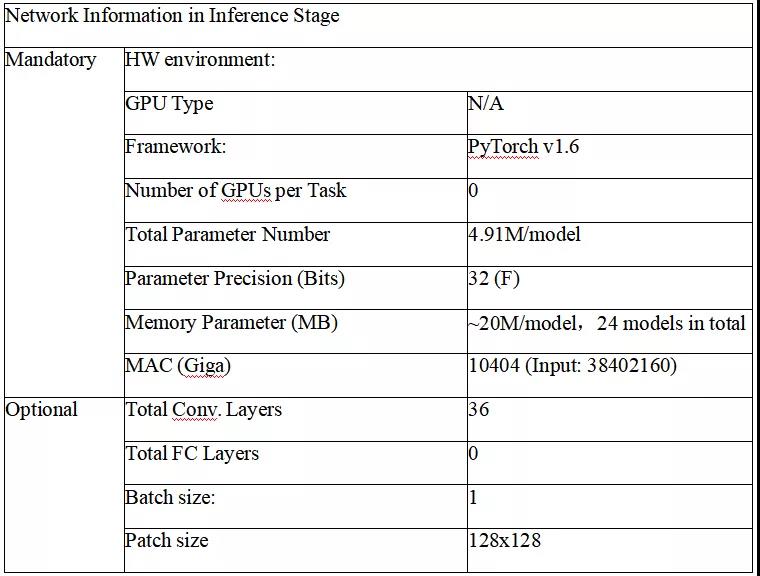
表 1。
训练过程中以 PyTorch 为训练平台,采用 DIV2K 和 BVI-DVC 数据集,分别训练针对 intra slice 和 inter slice 的卷积神经网络滤波器,并且训练不同的模型以适应不同的 QP 点,训练阶段的网络信息根据 JVET 建议列于下表 2 中。
注意,当训练 inter slice 滤波器时,预测信息也被用作输入,而在 JVET-T0088 中,它仅用于 intra slice。

表 2。
下图 2 给出了训练集和验证集损失函数的一个示例。
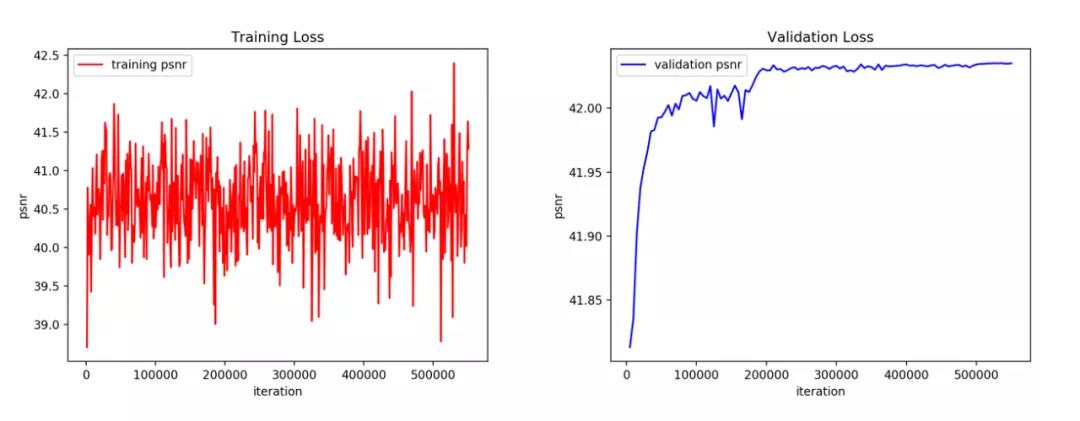
图 2。
实验结果:三个颜色分量(亮度 Y 和色度 Cb、Cr)性能增益显著
考虑到 VTM-9.0 和 VTM-10.0 之间的微小差异,并根据 JVET 定义的常规测试条件,在 VTM-9.0 上测试了字节跳动 AVG 的 DAM 技术提案,测试结果如下表 3 和表 4 所示。
结果显示,在 RA 构型下,Y、Cb 和 Cr 的 BD-rate 节省分别为 10.28%、28.22% 和 27.97%;在 AI 配置下,对 Y、Cb 和 Cr 分别可带来 8.33%、23.11% 和 23.55% 的 BD-rate 节省。
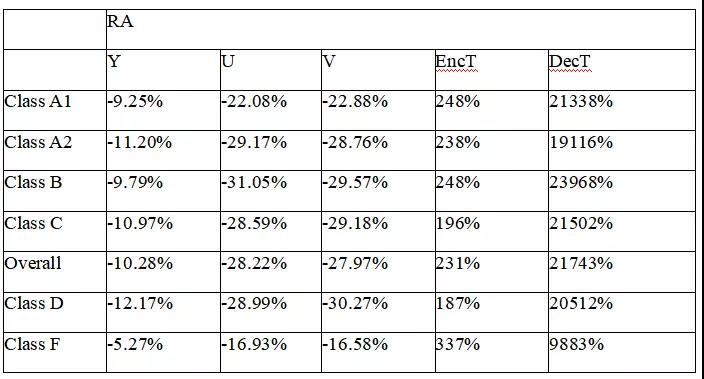
表 3:AVG 提案在 VTM9.0(RA)上的性能表现。
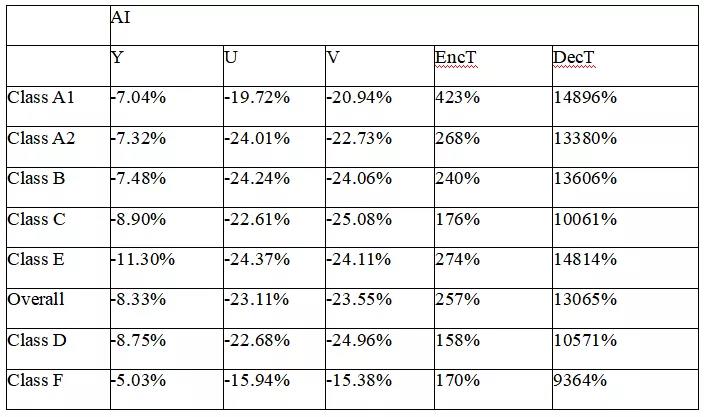
表 4:AVG 提案在 VTM9.0(AI)上的性能表现。
总结
实测证明,字节跳动 AVG 的这项视频编码技术创新,可以让视频的数据体积相比 H.266 最新国际标准再缩小 13%。对视频服务商来说,存储和带宽成本将显著降低;对用户来说,在网速较慢的情况下也可以流畅观看高清视频。
但正如前文所述,早在 2013年正式通过的 H.265,如今还没有完全普及。一方面,高昂的专利授权费用导致生产硬件设备和生产内容的厂商无法承担,用户也只能买并不支持 H.265 标准的设备;另一方面,H.265 的专利收费很复杂,想要使用 H.265 得分别多次缴专利费。因此,目前最常见的还是 18 年前的 H.264 标准。
尽管 H.266 新一代标准的推广还有很长的路要走,字节跳动 AVG 的技术探索并不会停止,其研究成果也会通过自主研发的 BVC 编码器投入应用,为抖音、西瓜视频、今日头条等 App 的视频类内容处理,以及云计算、云游戏等基础架构领域创造更高清画质、更流畅播放的视频体验。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK