

基于算法优化及深度学习的摄像头扫码速度提升实践
source link: https://tech.youzan.com/ji-yu-suan-fa-you-hua-ji-shen-du-xue-xi-de-she-xiang-tou-sao-ma-su-du-ti-sheng-shi-jian/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

基于算法优化及深度学习的摄像头扫码速度提升实践
摄像头扫码在移动端应用得非常广泛,比如生活中,我们经常会扫付款码用于支付,在餐厅会扫码点餐,扫码添加公众号,扫快递单号,商品条码等等,应用场景几乎涵盖了生活的方方面面。所以扫码体验对于移动产品来说非常重要,直接影响了产品的转化率和用户满意度。摄像头扫码速度也一直是有赞的几个移动 App 最关注的指标之一。
随着业务快速发展,使用有赞零售的商家也越来越多,经常收到商家反馈扫码功能不好用。特别是去年下半年,频频收到相关的线上问题。 比如这几个是比较典型的例子:POS 机扫码识别速度慢、扫快递单条码不灵敏、识别不了商品,商品条码扫不上等等。这些问题可以分为两大类:一个是扫码速度慢,二是条码扫不出来。所以我们的优化目标也是针对这两点:扫码速度提升和扫码成功率提升。
有赞零售的通用扫码页面,同时支持一维码和二维码的识别。一维码的场景有收银,出入库,采购,盘点等。二维码的场景则有核销,收款码,身份/登录验证条码这些。这些扫码场景的活跃度非常高,属于零售 App 内活跃占比最高的模块之一。

我们对目前线上的数据做了下埋点统计分析,当时优化前的平均扫码时长是 4.1s(从开启摄像头到扫码成功的时间),扫码成功率是91%(针对扫码失败的定义扫码成功大于 20s 或关闭扫码页时距上次开启摄像头大于 5s),单次扫码处理时长是 516ms(摄像头传回一帧图片,我们的扫码库处理这个图片所需时长)。
关于单次扫码时长这个数据。正常速度是每 33ms 传回一帧,516ms 意味着处理1帧需要丢掉 15 帧。每秒本来能处理 30 帧图片,现在最多只能处理2帧。非常影响扫码速度和成功率。所以我们的第一个优化点目前也非常明显了,把单次处理时长优化到 33ms 以内。
优化单次扫码速度
我们扫码模块同时使用系统和 ZXing 两个扫码库。哪种方式先返回结果,就停止扫码,抛出结果给外部。这样能一定程度提升扫码速度。因为系统处理方式是黑盒的,所以做不了过多的优化,只能在 ZXing 上看看有哪些可以优化的点。
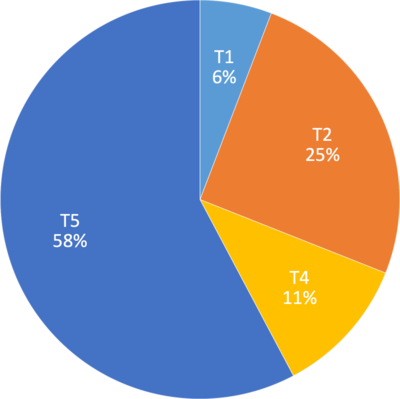
通过源码分析,从摄像头回掉图像数据到输出结果。大致分为5步:

T1.格式转换
30ms,耗时占比6%。
CVPixelBufferRef 格式转成成 CGImageRef,CVPixelBufferRef 是摄像头返回的像素图片类型,CGImageRef是像素位图,用于后续流程图片预处理。
T2.旋转图片方向
130ms,占比25%。
摄像头默输出的是横屏模式,并且条码方向会影响最后解码的识别,所以我们需要把图像转换成垂直的。
T3.剪裁扫描框
0ms,占比 0%。
使用 CGImageCreateWithImageInRect API 用于剪裁图片。剪裁图片只需要改变对应指针的偏移量即可,所以这部分几乎不耗时。在交互上也设计了扫描框,用于正确的截取图片,同时小图片有利于在后续操作的过程的花销会比较小。
T4.格式转化+灰度
58ms,占比11%。
CGImageRef 转换至 ZXLuminanceSource,ZXing 这个格式要求存储的图像数据是灰度的用于后续的解码。
T5.解码
298ms,占比 58%。
根据设定的支持的解码种类,依次解码。
策略1:减少解码种类(根据业务特性)
通过数据统计分析了在零售业务中各种条码类型的占比,得到的数据也是比较惊讶的,Top2 两种类型的条码:EAN13,Code128 占比高达 90%,第 3 大条码才是二维码只占 3%。另外在有赞零售 App 的应用场景下,二维码都是比较清晰的核销码,付款码,核身条码等,并通过埋点数据也发现二维码并不存在瓶颈。
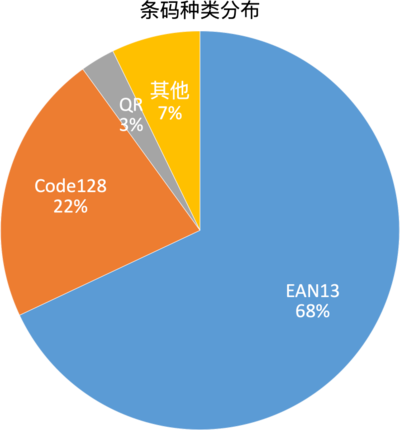
所以我们的重点优化方向是一维码的识别速度。因为 ZXing 解码速度和需要识别码种类数量线性相关,所以能想到的第一个优化点是设置 ZXing 仅识别高频的条码类型,其它未设置的低频条码识别可以用系统解码来兜底。
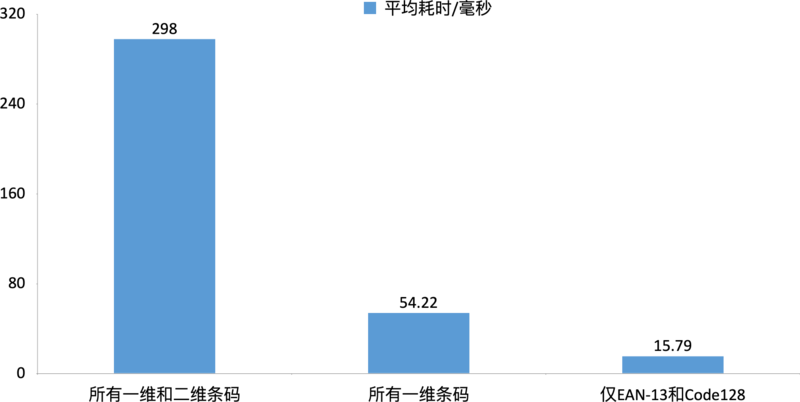
识别所有一维和二维条码需要花费 298ms,只识别所有一维条码需要花费54ms,这里已经提高了非常多倍。仅识别Top2条码,解码耗时会进一步降低,仅需 16ms。
策略2:优化/去除旋转环节
先截取再旋转
在之前的分析中,我们发现图片旋转后的截取环节几乎不需要耗时。旋转图片需要进行矩阵变换,需要依次遍历每个像素。所以图片越大,遍历的耗时也对应增大。摄像头直接返回的大图,大小是 1920x1080,而页面上扫码框标记的小图,大小是 840x636。它们之间的像素差距是3.6倍,如果我先截取图片再进行旋转的话,耗时也会降低,因为减少了遍历像素的次数。耗时从 130ms 下降至 36ms,正好是像素差距 3.6 倍左右。
去除旋转环节
系统其实是提供了对应的API(videoOrientation),可以将默认输出从横向(Landscape)改成纵向(Portrait),只需通过接口来设置视频的方向即可。那么就不需要进行图片旋转操作了,这部分的耗时就会变成 0ms。
策略3:合并/去除格式转换
之前存在较多的格式转换,CVPixelBufferRef -> CGImageRef,CGImageRef -> ZXLuminanceSouce,加起来也是蛮耗时的。可以直接 CVPixelBufferRef 转换至 ZXLuminanceSouce(并包含截取),为此我们自己实现了图片格式转化功能,直接把转化好的对象提供给 ZXing。下面是一些关键代码:
@implementation YZLuminanceSource
- (instancetype)initWithBuffer:(CVPixelBufferRef)buffer
left:(size_t)left
top:(size_t)top
width:(size_t)width
height:(size_t)height {
self = [super initWithWidth:(int)width height:(int)height];
if (self) {
size_t selfWidth = self.width;
size_t selfHeight = self.height;
size_t offsetX = (int)left;
size_t offsetY = (int)top;
size_t bytesPerRow = CVPixelBufferGetBytesPerRow(buffer);
size_t dataWidth = CVPixelBufferGetWidth(buffer);
size_t dataHeight = CVPixelBufferGetHeight(buffer);
NSAssert((offsetX + selfWidth <= dataWidth && offsetY + selfHeight <= dataHeight), @"Crop rectangle does not fit within image data.");
_data = (int8_t *)malloc(selfWidth * selfHeight * sizeof(int8_t));
CVPixelBufferLockBaseAddress(buffer,0);
int8_t *baseAddress = (int8_t *)CVPixelBufferGetBaseAddress(buffer);
CVPixelBufferUnlockBaseAddress(buffer, 0);
dispatch_apply(selfHeight, dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_LOW, 0), ^(size_t j) {
for (size_t i = 0; i < selfWidth; i++) {
size_t baseOffset = (j+offsetY)*bytesPerRow + (i+offsetX)*4;
uint32_t rgbPixelOut = 0;
uint32_t blue = baseAddress[baseOffset] & 0xFF;
uint32_t green = baseAddress[baseOffset + 1] & 0xFF;
uint32_t red = baseAddress[baseOffset + 2] & 0xFF;
if (red == green && green == blue) {
rgbPixelOut = red;
} else {
rgbPixelOut = (306 * red + 601 * green + 117 * blue + (0x200)) >> 10;
}
if (rgbPixelOut > 255) {
rgbPixelOut = 255;
}
self->_data[i + j*selfWidth] = rgbPixelOut;
}
});
}
return self;
}
@end
在自定义的转换过程中,还有一些其他优化点:
优化点1:按数据存储特性,合理选择读取方式
我们的图片数据是由一个个像素组成,像素形成一个图像矩阵数据,在内存中是以连续的内存区域存储的,如果我们的图像是按行存储的,那么每次提取也是按行的花会加速内存的访问,因为 CPU 会有优化,会先预读内存。

优化点2:使用并行提高遍历速度
使用多线程并发加快遍历速度,传统的实现是用for循环做单线程的遍历,在 iOS 里可以使用 dispatchapply 替代 for loop 做到并发处理。下面的图是几种便利方式的对比,最慢的是按列读取,需要 44ms,按行读取需要21ms,提升一倍,这基础上再使用 dispatchapply 可以提升到 12ms,差不多也是近一倍的提升
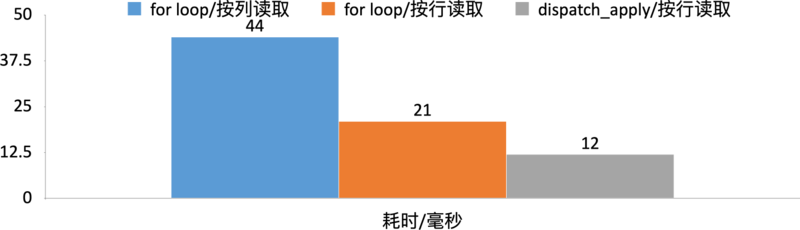
效果(单次扫码速度优化后)
我们已经把单次扫码速度提升了 20 倍,大盘数据会有怎么样的影响呢?是不是扫码速度也会提升 20 倍?上述优化上线之后,当时我们再来看了下统计数据,我们发现扫码成功平均时长只降低了 0.9s,扫码成功率只提升了 1%。
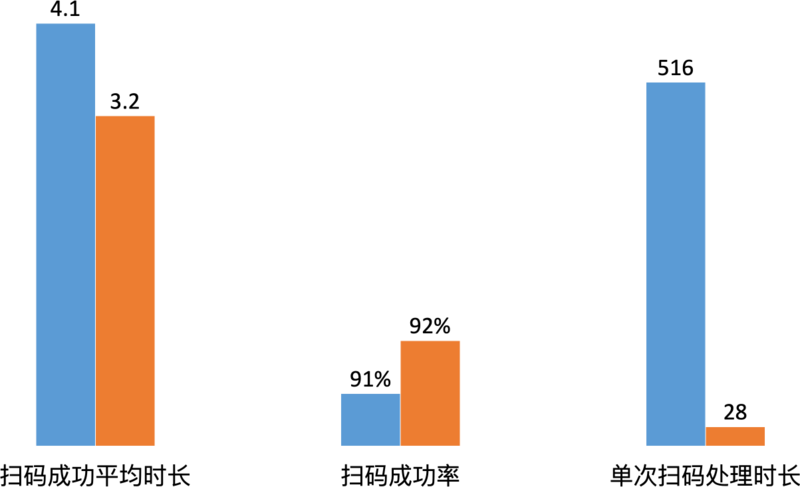
对大盘影响非常小,为什么呢?我们再来分析下整个扫码过程。进入扫码页,会开启摄像头,手机对准商品或者商品对准手机,接着挪动条码出现在摄像头内,再把条码挪到剪裁框内,因为挪动过程可能不是平稳的,返回的条码可能是模糊的,会导致解码失败。得到一个清晰的条码可能就1-3帧,大职能推理出,从之前 500ms 到 1500ms ,减少至 33ms 到 100ms,差不多也是 900ms 的样子,和大盘数据比较吻合。
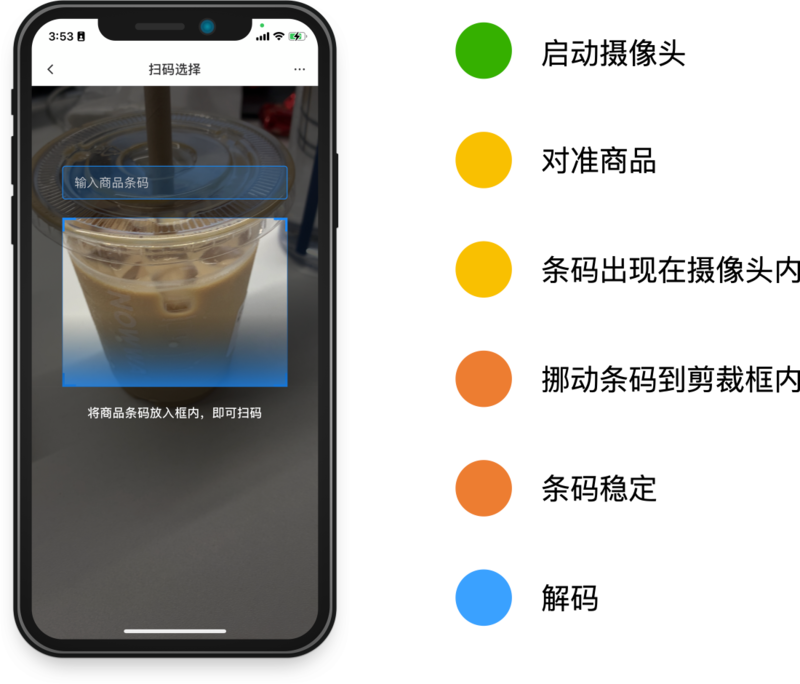
扫码成功率
除了扫码速度降低比较少之外,扫码成功率页几乎没有提升,1个百分点可能也是在误差范围内。这是为什么呢?我们对影响扫码成功率的几个因素做了下分析。
比如这个比较有特色的条码,条码周围有一圈黑背景,这非常影响二值化后的结果,我们对这个条码进行二值化后可以看到,条码有些信息已经丢失了,识别不出来也在情理之中。

条码过度旋转会导致解码失败,下图一个是垂直的,一个是旋转角度比较大的。这几个条码都不能被识别出来。

那么有什么方法可以提高扫码速度和和成功率呢?如果把条码从图中正确分类,并且转正是不是可以不影响二值化的结果,并且也不用考虑条码是否被旋转了,并且可以在条码进入摄像头的时候就可以识别了,不需要等条码挪到扫描框内才行。并且小图也能加速解码的速度。要实现这个,有两种方法:基于形态学和基于深度学习。
传统的方式是基于形态学,从原始图像经过MSERs检测,极值点检测,聚类,计算选择框这几个步骤,可以达到上述效果。但是有以下几个缺点,性能较差,特别是在高分辨率图下,640x480 的耗时需要 130ms,而且在 1920x1080 的图片则需要 600ms。并且准备率比较低,高分辨率图片下的定位也比较困难,有比较多的干扰。在通用的测试集下的准确率只有89%。所以并不能直接采用这种方法
深度学习在计算机视觉上的应用已经非常成熟了。比如:图片分类(Image Classifcation)和物体检测(Object Detection)。
物体检测大家肯定不陌生,比如特斯拉纯视觉的自动驾驶、Amazon Go 的无人超市、在有赞入口边上也有个无人售货柜,这些都用了物体检测。物体检测就是让计算机去分析一张图片或者一段影片中的物体,并标记出来,这需要给神经网络大量的物体数据去训练它,这样才能进行识别。
使用「物体检测」正好可以解决「条码区域定位」问题。

图片分类应用也挺多的,比如形色、微软识花等,即使没用过这些识别花的应用,应该都参与过支付宝扫「福」的活动,识别花的种类和扫福其实就是用到了图片分类。图像分类,根据各自在图像信息中所反映的不同特征,把不同类别的目标区分开来的图像处理方法。它利用计算机对图像进行定量分析,把图像或图像中的每个像元或区域划归为若干个类别中的某一种,以代替人的视觉判读。
通过物体检测解决了条码定位问题,但识别到的条码可能也是旋转的,会影响解码效果。可以把每个旋转角度的条码当成 1 个图片分类,这样就可以把条码角度预测问题转换成图片分类问题。测量条码和水平线的角度旋转角度用于图像分类,一维码头尾是有方向信息的,所以旋转的方向范围在 0 - 180 度之间。


基于深度学习学习如何解决码区识别问题:原始图片经过物体检测的神经网络得到条码在图片中的区域,接着剪裁这个区域里的图片,之后把检测后的图片经过角度预测的神经网络预测,比如这里得到的结果是 180 度,那么把条码旋转正确,再进行解码得到条码的内容。

iOS 虽然可以选择系统自带 CoreML,且不会影响包体积,但是因为只能 iOS 使用并且有些 API 只有高版本的系统才有,所以最后使用了 TensorFlow,这样 iOS 和 Android 可以达到同样的优化效果。我们收集了对应数据,平均耗时 iOS 40ms,Android 60ms。这里的平均耗时是从摄像头拿到图片数据回掉后到解码返回之间到耗时。虽然耗时增加了,但是同时也减少了无效解码的,没有检测到条码不会进行解码,可以降低性能损耗。
效果(基于深度学习)
这个是条码定位的效果,可以看到码区识别有准又快。

上线之后的大盘数据:扫码平均时长从 4.1s 降低到了 1.5s,扫码成功率 91% 提升到了 97%,线上问题也从此没有商家反馈了。
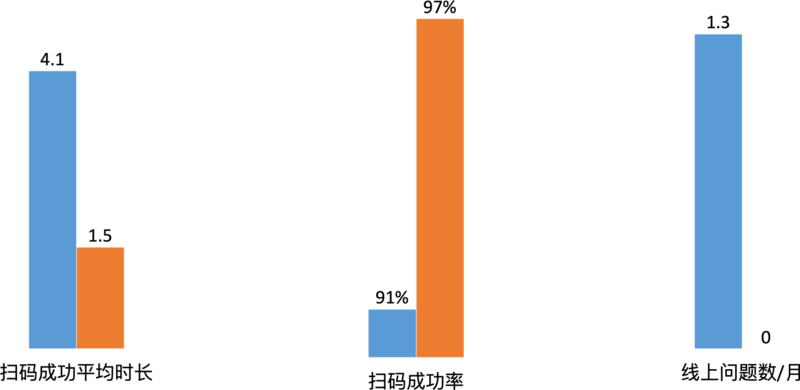
商家的实际使用情况,基本一打开摄像头就可以识别出来。

上述优化也适用于二维码,只需要增加对应的训练集,并且还能支持多码场景。
通过这次的优化实践,我们感受到:
- 关键数据的埋点和统计非常重要。如果没有之前的线上埋点数据积累,很多优化点我们都发现不了。
- “拿来主义”是不够的。ZXing 作为业界知名扫码库,简单的拿来就用,效果也很一般。只有全面了解其用法,甚至深入分析其源码,才能挖掘出进一步优化的空间。
- 新技术的“降维打击”非常关键。通过机器学习达到的码区识别的效果,比传统的算法优化要好很多。我们要保持对新技术的关注,多进行创新思考和应用。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK