

基于Seq2Seq的信息抽取方法在多轮对话场景的应用
source link: https://my.oschina.net/u/5359019/blog/5308401
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


导读
本文主要介绍了基于Seq2Seq方法从双人语音对话文档中提取电话号码的实践方法,重点介绍了基于不同模型结构的Seq2Seq方法如LSTM、GRU、Transformer的效果对比情况,同时介绍了在Encoder层尝试的不同Embedding方式及其如何采用Attention、Beam Search等方法来提升模型效果。实践结果表明基于Seq2Seq的方法在多轮对话交互中提取电话号码实体的效果相比基于传统的NER方法在F1值提升约30%。
背景
1. 业务背景
58同城是国内最大的生活服务类信息平台,该平台拥有大量的B端商家和C端用户。在双方的语音对话内容中,C端会告知B端一些已登记信息,如:用户的所在地和电话号码。为了核对用户已登记号码与对话中涉及的电话号码是否一致,从而发现异常用户,提升B端的运营效率与体验,利用NLP相关技术自动化提取的电话号码信息显得至关重要。
本文将任务抽象为以下两个阶段:

第一阶段是语音识别(ASR),将B端与C端的通话语音转化为文本。第二阶段是信息抽取,从对话文本中将C端提及的电话号码抽取出来。第一阶段直接利用58自研的语音识别引擎,因此本任务只关注第二阶段。在第二阶段,本文利用了基于对齐注意力机制的Seq2Seq结构进行电话号码抽取。
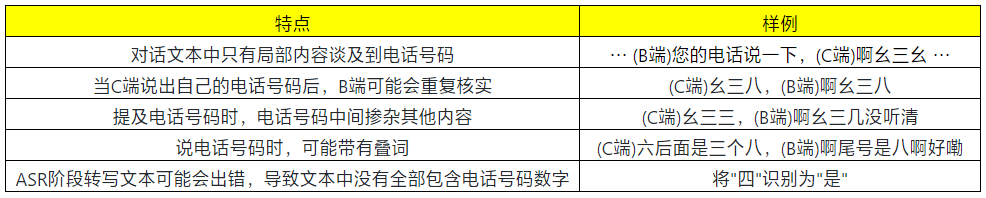
2.数据特点
人工阅读大量对话文本后,可以发现数据有以下特点:
解决方案
1.正则表达式
利用正则表达式提取电话号码是最简单的方法,但是它缺点明显,如:需要针对很多情况进行大量的预处理,过程繁琐,需要编写大量的模板,而且召回率很低。在测试集上进行实验,该方法的F1值为35.98%。
2.命名实体识别
将C端或B端的对话内容拼接在一起,然后利用命名实体识别的方法进行电话号码提取,也是比较简单的方法,但是该方法非常受限于原始对话文本。正如前面所提,电话号码中间会掺杂其他口语等内容,使得电话号码无法保持完整,因此该方法召回率也较低。在测试集上进行实验,该方法的F1值为37.49%。
3.Seq2Seq结构
Seq2Seq结构是基于深度学习的网络结构,它通过对原始信息进行编码,得到全文的语义编码,然后利用编码信息逐步解码,生成最终的答案。该结构已经广泛运用于机器翻译、文本摘要等任务,并且取得不错的效果,因此本文将采用该结构来完成此任务。
Seq2Seq的具体实践
1.Seq2Seq结构总述
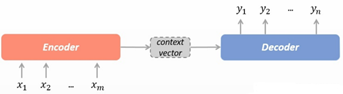
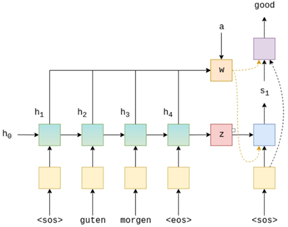
如图所示,Seq2Seq又称为Encoder-Decoder结构。在Encoder阶段,利用特征提取器,将输入序列进行编码,得到context vector。特征抽取器一般有CNN、 RNN、 Transformer等。在Decoder阶段,利用context vector和历史解码结果,依次解码得到答案。
2.Encoder
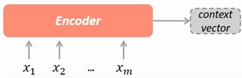
如图所示,x1、x2…xm是输入的tokens,采用字符级别。在Encoder内部,利用embedding、RNN、FC等,得到输入的向量表示C。其中,特征提取器的性能,决定向量C的表达能力。向量C一般称为上下文向量,可以看作对所有源信息的整合。本次任务是从对话文本中提取电话号码,对长距离特征、时序特征的捕获非常重要。
在实践中,需要先对对话文本进行预处理,从对话中提取部分内容作为输入。具体做法是:利用正则,只保留提及电话号码相关的内容。选择部分内容而不是全部内容作为Enocder的输入,可以降低任务的复杂性和难度,使模型专注于电话号码上下文的理解。
3.Decoder
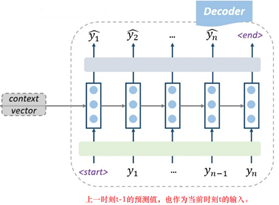
如图所示,Decoder阶段利用Encoder的输出Context Vector和前一时刻的解码结果yt-1,得到当前时刻的预测结果yt。
在实践中,本文对输出端进行了若干限制。首先,限制解码长度为电话号码的长度,即11位;其次,限制输出端的词表为0~9,即10个数字。
4.数据集
经过上述的预处理后,得到训练集45376份、验证集5671份、测试集5673份。
5.模型1:基于LSTM的Seq2Seq结构
首先尝试的是基于LSTM的Seq2Seq结构,它的模型结构如图所示。
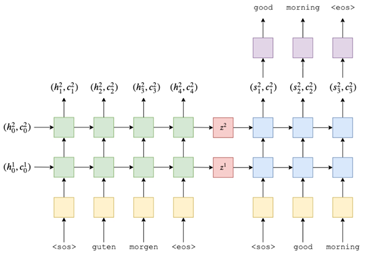
在Encoder中,特征提取器采用两层双向LSTM,得到源信息的固定表征Context Vector。在Decoder中,特征提取器采用两层单向LSTM,将Context Vector作为隐藏层的初始化输入。在超参数上,embedding_size为256,hidden_size为512。在损失函数上,选择极大似然估计作为损失函数。
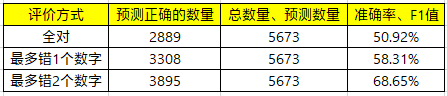
训练后发现,模型的拟合速度慢,存在误差爆炸的现象。于是采用Teacher-Forcing策略进行训练。简单来说,Teacher-Forcing是引导着模型去学习,即:在训练阶段,用上一时刻的真实结果而不是预测结果作为当前时刻的输入。这样的引导式学习方式,可以避免“一步错、步步错”的问题,使得训练过程更加容易。此外,为了避免训练和推理阶段不一致,需要对训练过程进行适度指导,即:以一定的概率选择真实结果作为输入。
因此,本文将teacher_forcing_ratio的参数值设置为0.5。训练成功后,具体的实验结果如下。
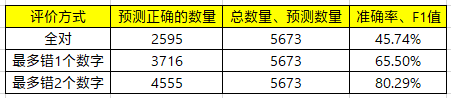
在业务实际应用中,提取的电话号码会发送到业务方,业务方会将该电话号码与用户已登记的电话号码进行核实确认。如果两者一致,说明该用户是目标客户。电话号码共有11位,即使错误1、2位,也可以近似判断两者的一致性。由此可见,电话号码识别错误1、2位对业务影响较小,于是本文选择3种评价方式。
从结果来看,该模型的效果一般。于是,针对此模型进行了一系列优化。
6.对模型1的优化
在解码时采用beam search算法。在之前的解码阶段,每时刻只保留概率最大的一个结果。采用beam search算法后,每时刻保留概率最大的k个结果,这可以在一定程度上避免局部最优的情况。本文设置k为5,全对的准确率提升较大,约5%。
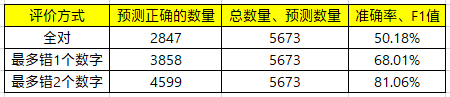
限制输入端的词表,只保留与电话号码相关的词汇。从结果来看,准确率提升有限,约1%左右。
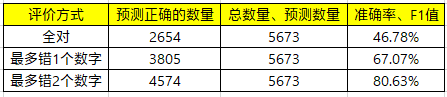
只保留C端用户的说话内容。从结果来看,虽然全对的准确率有所提升,但是其他两者的准确率下降明显。分析badcases后发现,由于ASR转写文本存在损失,导致C端的说话内容无法完全包含号码中的数字。
融入角色信息。在Embedding阶段,将角色信息向量化,参与模型的训练。从结果来看,准确率略有提升。
经过的以上的尝试后发现,该模型的特征提取能力有限,于是采用基于注意力机制的模型。
7.模型2:基于GRU+Attention+特征融合的Seq2Seq结构
模型2的结构如图所示,该结构选择GRU作为特征提取器。由论文《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》可知,在一些应用场景中,GRU的效果要优于LSTM。而且,GRU的参数量比LSTM少,训练时收敛速度更快,便于快速迭代。相比较于模型1,模型2主要有两个创新点:
1.利用注意力机制得到源信息的动态表征;
2.在Decoder阶段将多个特征融合,相比于模型1,减少了信息压缩。

如图所示,模型2的注意力机制一般称为基于对齐的注意力机制。这种注意力机制主要包括3个步骤:打分、归一化、合成。在“打分”阶段,该模块负责计算Decoder隐藏层的输出ht-1与Encoder中隐藏层的输出h1…h4的相关性。本文采用的是线性变换和非线性变换组合的方式,得到了输入端所有时间步的打分值。在“归一化”阶段,将打分值进行softmax归一化,得到概率表示,此时的概率表示可以看作Encoder中各部分的权重。在“合成”阶段,利用概率权重对Encoder各部分进行加权求和,得到最终的上下文向量Context Vector。简单来说,注意力机制可以从纷繁的信息中找到当前任务所需要的关键信息。
在Decoder阶段,每一时刻都会重复计算上下文向量,所以称之为源信息的动态表征。在多特征融合方面,首先将Context Vector和yt-1拼接,作为GRU的输入;其次,将Context Vector、yt-1、ht拼接,作为预测时全连接层的输入。这种多特征融合的方式,使得特征之间的交互更充分。
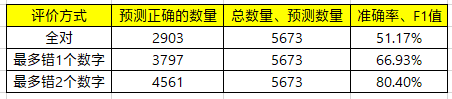
经过训练调优后,模型2的效果如下。
从结果来看,在各种评价方式上,准确率有非常大的提升。
此外,为了对比LSTM和GRU在此任务的效果,本文还将GRU替换为LSTM,实验结果如下。
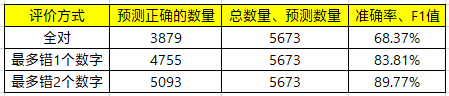
从结果来看,两者效果差别不大,GRU略优。可见在本任务中,GRU提取特征能力已经足够强大,能够胜任本任务。
8."基于LSTM的Seq2Seq结构"与"基于GRU+Attention+特征融合的Seq2Seq结构"的结果分析
"基于LSTM的Seq2Seq结构"只能对简单文本中的电话号码识别效果好。如以下样例。

"基于GRU+Attention+特征融合的Seq2Seq结构"不仅对简单文本识别效果好,对于那些复杂文本和需要语义理解的文本,也可以取得良好的效果。如以下样例。

此外,对"基于GRU+Attention+特征融合的Seq2Seq结构"的bad cases进行了分析。在这些识别错误样本中,约有80%的错误是由ASR阶段导致。例如,由于语速过快或方言导致ASR阶段的数字转写错误和转写遗漏。由此可见,虽然准确率约70%,但是该模型的泛化能力很好。
9.模型3:基于Transformer的Seq2Seq结构
最后,本文还尝试了Transformer模型,模型结构如图所示。
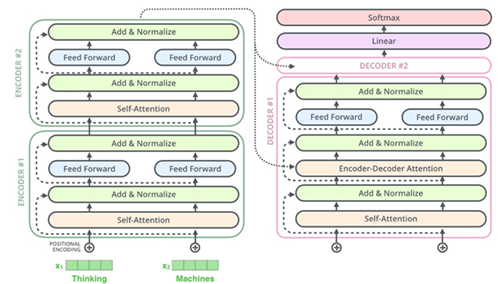
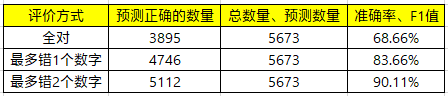
Transformer是业内常用的Seq2Seq结构,其内部利用self-attention作为特征抽取器。经过训练调优后,模型3的效果如下:
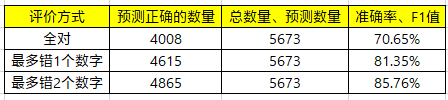
相比较于模型1,准确率依然有很大的提升;但是相比较于模型2,全对的准确率高约1%,其他两者的准确率差距较大。
Transformer的效果弱于模型2,原因可能是:Transoformer调参困难,容易过拟合;该任务训练数据有限、任务难度有限,没有发挥self-attention的优势。从经验来看,一般数据量很大且任务难度较大时,Transformer的效果才会明显优于RNN。知乎上很多网友的任务经验也印证了这一点,详情见参考文献5。
由此可见,针对提取电话号码这类任务,利用“GRU+Attention+特征融合”的方案更有效。
总结和展望
本文分析了电话号码提取任务的特点和解决方案,并利用Seq2Seq结构解决此类任务。在Seq2Seq结构中,本文尝试了多种特征提取器和优化方案,其中“GRU+基于对齐的注意力机制+多特征融合”的方案综合效果最优。在后续的迭代优化中,不仅在数据预处理阶段更加细致,还会采用规则与模型相结合的方式提升准确率。
参考文献
1.Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Advances in neural information processing systems. 2014: 3104-3112.
2.Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
3.Chung J, Gulcehre C, Cho K H, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[J]. arXiv preprint arXiv:1412.3555, 2014.
4.Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
5.https://www.zhihu.com/question/302392659
作者
高正建,58同城AI Lab算法工程师。2020年6月硕士毕业于首都师范大学,毕业后入职58AI Lab从事算法研发工作。目前负责语音语义标签挖掘分析、智能写稿等相关的工作。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK