

论文解读二十七:文本行识别模型的再思考
source link: https://my.oschina.net/u/4526289/blog/5313197
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

论文解读二十七:文本行识别模型的再思考 - 华为云开发者社区的个人空间 - OSCHINA - 中文开源技术交流社区
摘要:本文研究了两个解码器(CTC[1]和 Transformer[2])和三个编码器模块(双向LSTM[3]、Self-Attention[4]和GRCL[5]),通过大量实验在广泛使用的场景和手写文本公共数据集上比较准确性和性能。
本文分享自华为云社区《论文解读二十七:文本行识别模型的再思考》,作者: wooheng。

本文研究了文本行识别的问题。与大多数针对特定领域(例如场景文本或手写文档)的方法不同,本文针对通用架构的一般问题进行研究,该模型结构不用考虑数据输入形式,可以从任何图像中提取文本。本文研究了两个解码器(CTC[1]和 Transformer[2])和三个编码器模块(双向LSTM[3]、Self-Attention[4]和GRCL[5]),通过大量实验在广泛使用的场景和手写文本公共数据集上比较准确性和性能。本文发现,迄今为止在文献中很少受到关注的组合,即与CTC 解码器结合Self-Attention编码器加上语言模型的结构,在公共和内部数据上进行训练时,其准确性和计算复杂度优于其他所有组合。与更常见的基于Transformer的模型不同,这种架构可以处理任意长度的输入。

图1 数据集中的文本行示例图像,其中包含各种长度的手写、场景文本和文档文本图像。
2.模型结构
大多数最先进的文本行识别算法由三个主要组件组成:用于提取视觉特征的卷积主干;用于聚合部分或整个序列的特征的顺序编码器;最后是一个解码器,根据编码器输出产生最终转录。在本工作中研究了具有固定主干的编码器和解码器的不同组合,并提出了一种最优的模型体系结构,模型结构见图2。
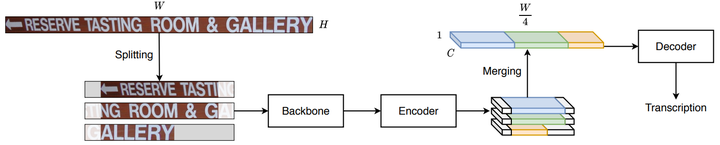
图2 模型结构。输入图像在馈送到主干之前被分割成带有双向填充的重叠块。生成的序列特征的有效部分在馈送到解码器之前被级联。
2.1 主干网络
本文的主干是一个等距架构[6],使用融合反转瓶颈层作为构建块,这是反转瓶颈层[7]的变体,它用全卷积取代可分离的结构,以提高模型推理效率。等距架构在所有层中保持恒定的内部分辨率,允许低激活内存占用空间,并使模型更容易自定义到专用硬件,并实现最高利用率。图3详细说明了网络。它由一个块大小为4的space-to-depth层组成,然后是11个融合反转瓶颈层,具有3×3内核和8×扩展速率,具有64个输出通道。应用最终的完全卷积残差块将张量高度降低到1,作为输入送到编码器网络。
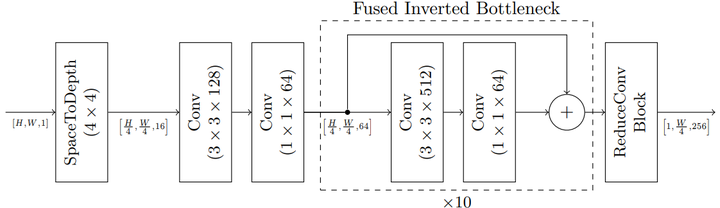
图3 实验中使用的主干。首先通过空间到深度操作将输入灰度图像的分辨率降低4倍,然后应用11个融合反转瓶颈层,扩展速率为8和64个输出通道,并使用残差卷积块将输出投影到高度为1的张量中。
2.2 编码器
Self-Attention编码器已被广泛用于许多NLP和视觉任务。作为图像到序列的任务,文本行识别也不例外。自我注意编码器可以有效地输出总结整个序列的特征,而不使用重复连接。主干网络的输出被馈送到编码器。编码特征Y计算为:
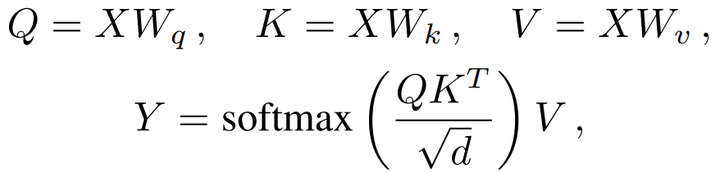
其中Q、K和V的三个参数W是大小为d×d的学习参数,它们分别将输入序列X投影到queries、keys和values中。编码特征Y是计算值V的凸组合,相似性矩阵由queries和keys的点积计算。
本文使用4个独立的头,每个头都使用多头注意力机制。隐藏层大小设置为256。为了防止过拟合,在每个子层之后应用dropout,设置为0.1。增加正弦相对位置编码,使编码器位置感知。在本文的实验中,我们通过将k个编码器层与以{4、8、12、16、20}数量堆叠,比较了不同模型变化的精度和复杂性。
2.3 解码器
在CTC解码器之后加入语言模型,采用基于字符的N-gram语言模型使用最小错误率来训练优化特征函数的权重。
2.4 图片分块
由于自注意力层中的点积注意力影响,编码器的模型复杂性和内存占用率与图像宽度的函数比例呈二次增长。这会导致图片太长使得输入出现问题。缩小长图像可以避免这些问题,但它不可避免地会影响识别精度,特别是对于狭窄或紧密间隔的字符。
本文提出了一个简单而有效的分块策略,以确保模型在任意宽的输入图像上工作良好,而不会收缩(见图2)。本文将输入图像的大小调整为40像素高度,保留宽高比。然后,文本行被拆分为重叠的块,带有双向填充,以减少可能的边界效果(请注意,最后一个块有额外的填充,以确保用于批处理目的的统一形状)。本文将重叠的块馈送到主干和自注意力编码器中,以生成每个块的序列特征。最后将有效区域合并回一个完整的序列,删除填充区域。
这种方法将长序列拆分为k个较短的块,有效地将模型复杂性和自注意力层的内存使用量降低了k倍。此策略在训练和推理时都使用,以保持行为一致。
3.实验结果
图4为实验结果,结果显示CTC 解码器结合Self-Attention编码器加上语言模型的结构,在公共和内部数据上进行训练时,其准确性和计算复杂度优于其他所有组合

图4 对选择模型结构在手写数据集和场景文本数据集上的评估结果。“Rect.”列指示模型是否包括矫正模块。“S-Attn”、“Attn”和“Tfmr Dec.”分别代表自我注意力机制、注意力机制和Transformer解码器。“MJ”,“ST”和“SA”分别代表MJSynth、SynthText 和SynthAdd数据集。
在文本工作中,研究了具有代表性的编码器/解码器体系结构作为通用文本行识别器的性能。在解码器比较中,发现CTC与语言模型结合产生了整体优越的性能。在没有LM的情况下,CTC和Transformer具有竞争力,CTC在某些情况下占主导地位(GRCL),Transformer在其他情况下占主导地位(BiLSTM)。另一方面,在编码器比较中,SelfAttention总是表现更好,在没有LM的情况下,两个解码器都同样好用。有趣的是,未经研究的SelfAttention/CTC+LM模型效果最好。本文同样表明,基于注意力的解码器仍然可以从外部语言模型中受益。研究具有变压器解码器的外部语言模型的有效性将是未来的工作。
本文还考虑了在样本分布中存在长图像所产生的问题。至少有两个新的方面需要考虑,效率和性能。由于图像长度的二次缩放,长图像会影响使用自注意力编码器的模型效率。本文证明,通过对图像进行分块,CTC模型可以解决这个问题,而不会造成性能损失。对固定最大宽度图像的训练会影响使用变压器解码器的模型对较长图像识别的性能。通过将图像大小调整到训练的宽度,虽然不能完全消除,但可以缓解此问题。
[1] Graves A, Fernández S, Gomez F, et al. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. Proceedings of the 23rd international conference on Machine learning. 2006: 369-376.
[2] Bleeker M, de Rijke M. Bidirectional scene text recognition with a single decoder. arXiv preprint arXiv:1912.03656, 2019.
[3] Hochreiter S, Schmidhuber J. Long short-term memory. Neural computation, 1997, 9(8): 1735-1780.
[4] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Advances in neural information processing systems. 2017: 5998-6008.
[5] Wang J, Hu X. Gated recurrent convolution neural network for ocr. Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017: 334-343.
[6] Sandler M, Baccash J, Zhmoginov A, et al. Non-discriminative data or weak model? on the relative importance of data and model resolution. Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. 2019: 0-0.
[7] Sandler M, Howard A, Zhu M, et al. Mobilenetv2: Inverted residuals and linear bottlenecks. Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4510-4520.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK