

Apache Kyuubi 助力 CDH 解锁 Spark SQL
source link: https://my.oschina.net/u/4565392/blog/5311661
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Apache Kyuubi 助力 CDH 解锁 Spark SQL
Apache Kyuubi(Incubating)(下文简称Kyuubi)是⼀个构建在Spark SQL之上的企业级JDBC网关,兼容HiveServer2通信协议,提供高可用、多租户能力。Kyuubi 具有可扩展的架构设计,社区正在努力使其能够支持更多通信协议(如 RESTful、 MySQL)和计算引擎(如Flink)。
Kyuubi的愿景是让大数据平民化。一个的典型使用场景是替换HiveServer2,帮助企业把HiveQL迁移到Spark SQL,轻松获得10~100倍性能提升(具体提升幅度与SQL和数据有关)。另外最近比较火的两个技术,LakeHouse和数据湖,都与Spark结合得比较紧密,如果我们能把计算引擎迁移到Spark上,那我们离这两个技术就很近了。
Kyuubi最早起源于网易,这个项目自诞生起就是开源的。在Kyuubi发展的前两年,它的使用场景主要在网易内部。自从2020年底进行了一次架构大升级、发布了Kyuubi 1.0之后,整个Kyuubi社区开始活跃起来了,项目被越来越多的企业采用,然后在今年6月进入了Apache基金会孵化器,并在今年9月发布了进入孵化器后的第一个版本1.3.0-incubating。
Kyuubi vs SparkThriftServer vs HiveServer2
我们通过Kyuubi和其他SQL on Spark方案的对比,看看用Kyuubi替换 HiveServer2能带来什么样的提升。图中对Hive Server2标记了Hive on Spark,这是Hive2的一个功能,最早的Hive会把SQL翻译成MapReduce来执行,Hive on Spark方案其实就是把SQL翻译成Spark算子来执行,但是这仅仅是物理算子的替换,因为复用了Hive的SQL解析逻辑,所以SQL方言还是HiveQL,包括后续SQL的改写、优化走的都是Hive的优化器。Spark2放弃了Hive on Spark方案,选择从头开始做SQL解析、优化,创造了Spark SQL和Catalyst。所以说,Spark Thrift Server只是兼容了HiveServer2的Thrift通信协议,它整个SQL的解析、优化都被重写了。
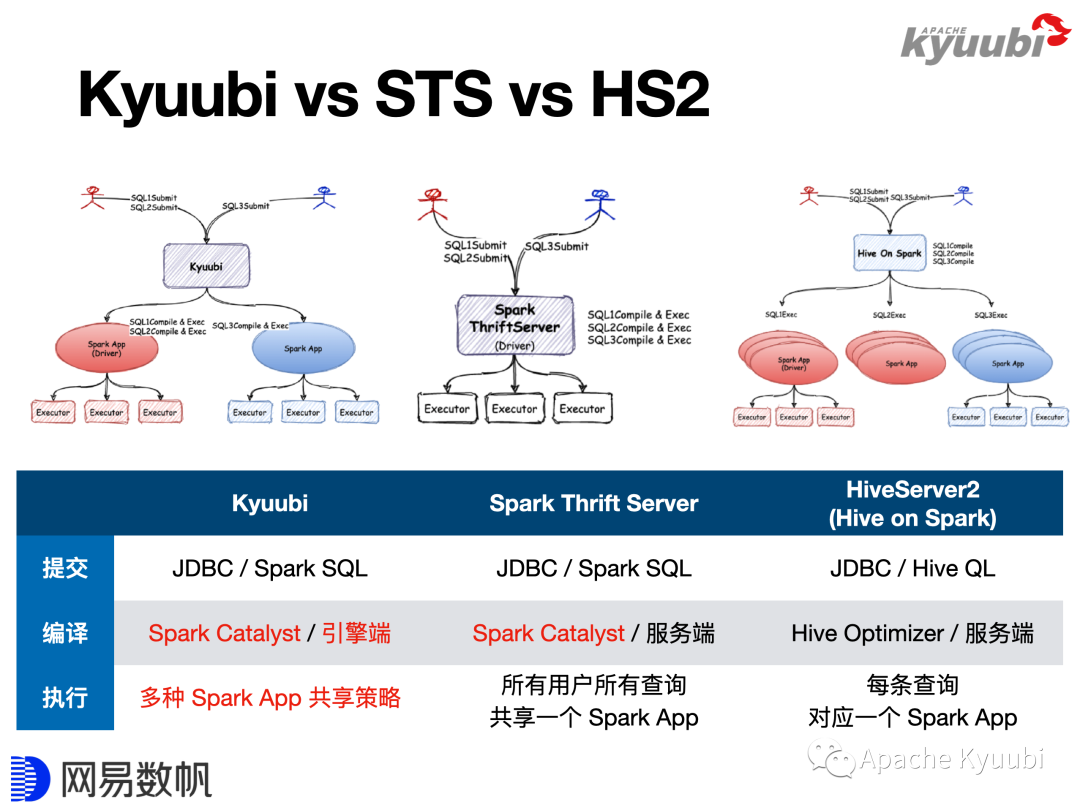
Kyuubi也是用Spark来解析、优化和执行SQL,所以对于用户来说,客户端与服务端的通信协议是一模一样的,因为大家兼容的都是HiveServer2的通信协议。但是在SQL方言上,Kyuubi和Spark Thrift Server是Spark SQL,HiveServer2是HiveQL。SQL的编译和优化过程,HiveServer2在本进程上进行,Spark是在Driver端进行。对于STS,Thrift Server和Driver在同一个进程内;对于Kyuubi,Thrift Server和Spark Driver是分离的,它们可以跑在同一台机器上的不同进程(如YARN Client模式),也可以跑在不同的机器上(如YARN Cluster模式)。
对于执行阶段,当一条SQL提交后,HiveServer2会将其翻译成了一个Spark Application,每一次SQL提交就会生成一个全新的Spark的应用,都会经历Driver的创建、Executor的创建过程,SQL执行结束后再将其销毁掉。Spark Thrift Server则是完全相反的方式,一个Spark Thrift Server只持有一个Driver,Driver是常驻的,所有的SQL都会由这一个Driver来编译、执行。Kyuubi不仅对这两种方式都支持,还支持了更灵活的Driver共享策略,会在后续详细介绍。
Kyuubi on Spark与CDH集成
CDH是使用最广泛的Apache Hadoop发行版之一,其本身集成了Spark,但是禁用了Spark Thrift Server功能和spark-sql命令,使得用户只能通过spark-shell、spark-submit使用Spark,故而在CDH上使用Spark SQL具有一定的门槛。在CDH上SQL方案用得更多的往往是Hive,比如说我们可以通过Beeline、HUE连接HiveServer2,来进行SQL批任务提交或交互式查询,同时也可以通过Apache Superset这类BI工具连接到HiveServer2上做数据可视化展示,背后最终的计算引擎可以是MapReduce,也可以是Spark。
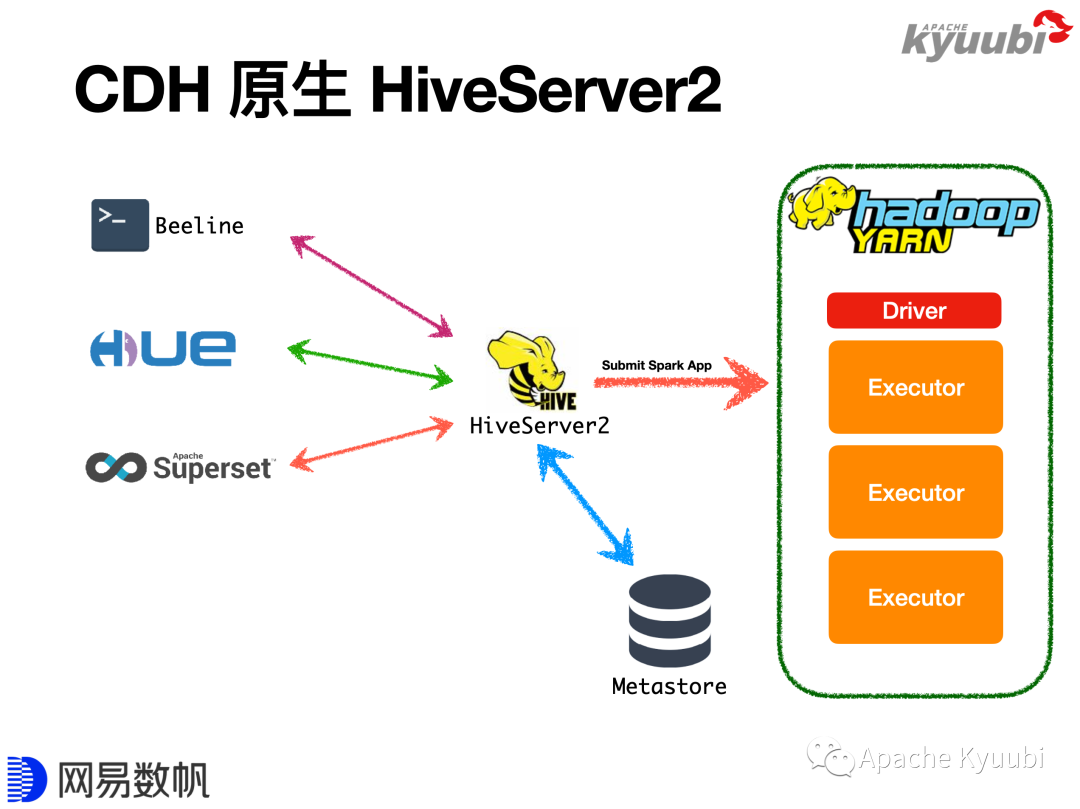
当我们引入Kyuubi后,图中左侧的这些Client都是不需要更改的,只需要部署Spark3和Kyuubi Server(当前Kyuubi仅支持Spark3),再把Client连接地址改一下,即可完成从HiveQL到Spark SQL的迁移。当然其间可能会碰到HiveQL方言跟Spark SQL方言的差异性问题,可以结合成本选择修改Spark或者修改SQL来解决。
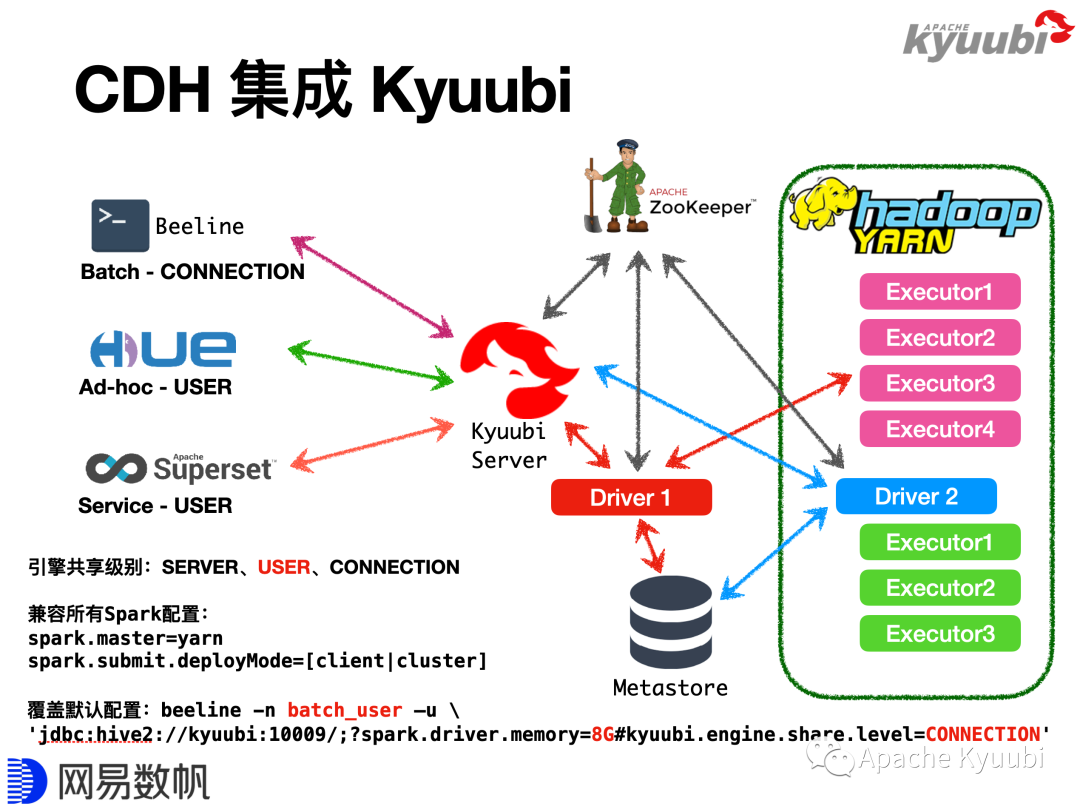
Kyuubi中有一个重要的概念叫作引擎共享级别(Engine Share Level),Kyuubi通过该特性提供了更高级的Spark Driver共享策略。Spark Engine与Spark Driver概念是等价的,都对应一个Spark Application。Kyuubi目前提供了三种Engine共享级别,SERVER、USER和CONNECTION,缺省是USER模式。
SERVER模式类似Spark Thrift Server,Kyuubi Server只会持有一个Spark Engine,即所有的查询都会提交到一个Engine上来跑。USER模式即每个用户会使用独立的Engine,能做到用户级别的隔离,这也是更具普适性的一种方式,一方面不希望太浪费资源,每个SQL都起一个Engine,另一方面也希望保持一定的隔离性。CONNECTION模式是指Client每建立一个连接,就创建一个Engine,这种模式和Hive Server2较为类似,但不完全一致。CONNECTION模式比较适合跑批计算,比如ETL任务,往往需要数十分钟甚至几个小时,用户不希望这些任务互相干扰,同时也希望不同的SQL有不同的配置,例如为Driver分配2G内存还是8G内存。总的来说,CONNECTION模式比较适合跑批任务或者大任务,USER模式比较适合HUE交互式查询的场景。
大家可能会担心,我们是不是对Spark做了很厚的一层包装,限制了很多功能?其实不是的,所有的Spark的configuration在Kyuubi中都是可用的。当一个请求发送给Kyuubi时,Kyuubi会去找一个合适的Engine跑这个任务,如果找不到它就会通过拼接spark-submit命令来创建一个Engine,所以所有的Spark支持的configuration都可以用。如图中列举了YARN Client和YARN Cluster两种模式,怎么写配置,Spark Driver就跑在什么地方,改成K8s,Driver就跑在Kubernetes里面,所以Kyuubi对Kubernetes的支持也是水到渠成的。
还有一个用户常问的问题,是不是USER模式或者CONNECTION模式,每一个场景都需要单独部署一套Kyuubi Server?不需要。我们可以把常用的配置固化在kyuubi-defaults.conf里面,当Client连接Kyuubi Server时,可以通过在URL里面写一些配置参数来覆盖默认配置项,比如缺省使用的是USER模式,提交批任务时选择CONNECTION模式。
Kyuubi 引擎隔离级别的实现
Kyuubi多种灵活的隔离级别是怎么实现的?下图绿色的组件即Service Discovery Layer,目前通过ZooKeeper实现,但它本质上是一个服务注册/发现的组件。我们已经发现有开发者把Kyuubi集成到Kubernetes上,用API Server来实现Service Discovery Layer,该功能目前还没有提交给社区。
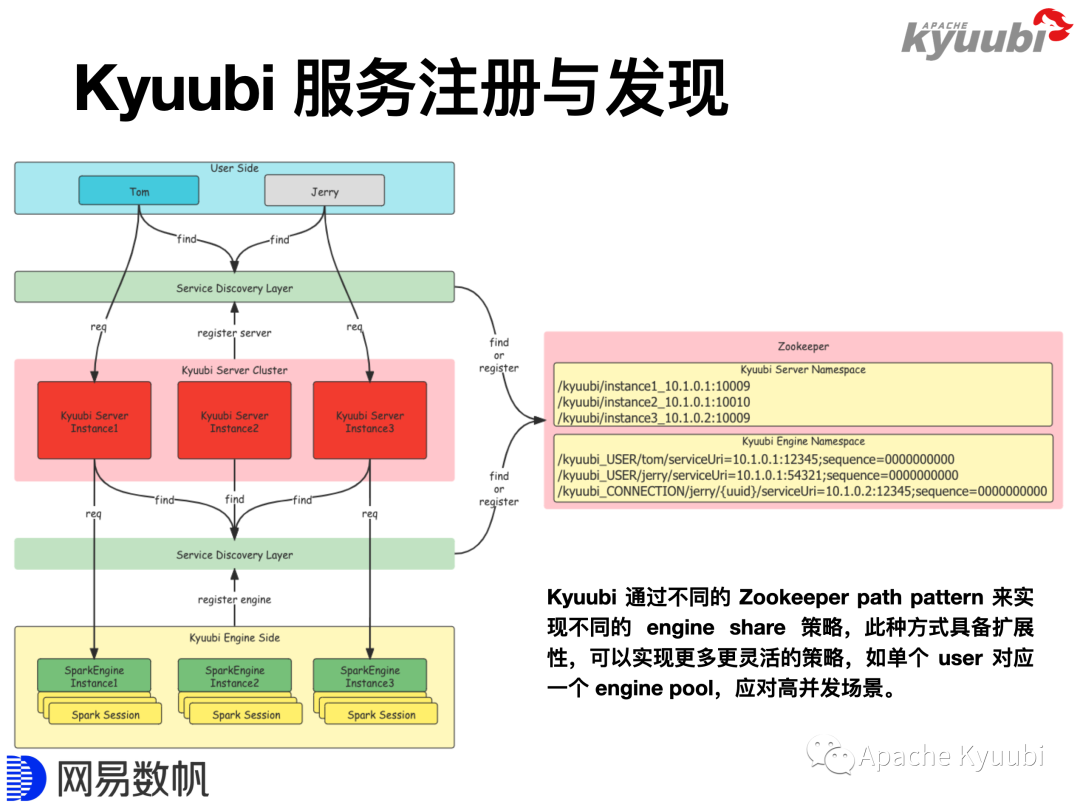
上图中的User Side即Client侧,社区目前策略是完全兼容Hive的Client,以更好的复用Hive生态。Hive本身通过ZooKeeper实现了Client侧的HA模式,Server启动以后,会将自身按照一定的规则注册到ZooKeeper里面,Beeline或者其他Client连接的时候,将连接地址设置成ZooKeeper集群的地址,Client即可以发现指定的路径下所有的Server,随机选择其中一个来连接。这是HiveServer2协议的一部分,Kyuubi是完全兼容的。
Kyuubi Server与Engine之间也使用了类似的服务注册与发现机制,Engine在Zookeeper上的注册路径会遵守一定的规则,例如在USER隔离级别下,路径规则是/kyuubi_USER/{username}/{engine_node}。Kyuubi Server接到连接请求,会按照规则从特定路径下查找可用的Engine节点。若找到,直接连接该Engine;若找不到,创建一个Engine并等待其启动完成,Engine启动完成后,会按照相同的规则在指定路径下创建一个engine节点,并把自己的(包含连接地址、版本等)填写到节点里。在YARN Cluster模式下,Engine会被分配到YARN集群任意节点启动,正是通过这种机制,Server才能找到并连接Engine。
对于CONNECTION模式,每一个Engine只会被连接一次,为了实现这个效果,Kyuubi设计了如下的路径规则,/kyuubi_CONNECTION/{username}/{uuid}/{engine_node},通UUID的唯一性来实现隔离。所以Kyuubi实现引擎隔离级别的方式是一个非常灵活的机制,我们目前支持了SERVER、USER和CONNECTION,但通过简单的扩展,它就可以支持更多更灵活的模式。在代码主线分支上,社区目前已经实现了额外的两个共享级别,一个是GROUP,可以让一组用户来共享一个Engine;另外一个是Engine Pool,可以让一个用户来使用多个Engine以提高并发能力,一个适用的场景是BI图表展示,例如为Superset配置一个Service Account,对应多个Engine,当几百个图表一起刷新时,可以将计算压力分摊到不同Engine上。
Kyuubi实践 | 编译Spark3.1以适配CDH5并集成Kyuubi
https://mp.weixin.qq.com/s/lgbmM1qNetuPB0-j-TAzkQ
Apache Kyuubi on Spark 在CDH上的深度实践
我们在Kyuubi的官方公众号提供了两篇文章,内容包含了将Kyuubi集成到CDH平台上的具体操作过程,第一篇描述了与CDH5(Hadoop2,启用Kerberos)的集成,第二篇描述了CDH6(Hadoop3,未启用Kerberos)的集成。对于集成其他非CDH平台的Hadoop发行版,也具有一定的参考价值。

Spark 3 特性以及 Kyuubi 带来的增强
动态资源分配
首先是动态资源分配,Spark本身已经提供了Executor的动态伸缩能力。可以看到,这几个参数配置在语义上是非常明确的,描述了Executor最少能有多少个,最多能有多少个,最大闲置时长,以此控制Executor的动态创建和释放。
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=0
spark.dynamicAllocation.maxExecutors=30
spark.dynamicAllocation.executorIdleTimeout=120
引入了Kyuubi后,结合刚才提到的Share Level和Engine的创建机制,我们可以实现Driver的动态创建,然后我们还引入了一个参数,engine.idle.timeout,约定Driver闲置了多长时间以后也释放,这样就实现Spark Driver的动态创建与释放。
kyuubi.engine.share.level=CONNECTION|USER|SERVER
kyuubi.session.engine.idle.timeout=PT1H这里要注意,因为CONNECTION场景比较特殊,Driver是不会被复用的,所以对于CONNECTION模式,engine.idle.timeout是没有意义的,只要连接断开Driver就会立刻退出。
Adaptive Query Execution
Adaptive Query Execution(AQE)是Spark 3带来的一个重要特性,简而言之就是允许SQL边执行边优化。就拿Join作为例子来说,等值的Inner Join,大表对大表做Sort Merge Join,大表对小表做Broadcast Join,但大小表的判断发生在SQL编译优化阶段,也就是在SQL执行之前。
我们考虑这样一个场景,两个大表和大表Join,加了一个过滤条件,然后我们发现跑完过滤条件之后,它就变成了一个大表和一个小表Join了,可以满足Broadcast Join的条件,但因为执行计划是在没跑SQL之前生成的,所以它还是一个Sort Merge Join,这就会引入一个不必要的Shuffle。这就是AQE优化的切入点,可以让SQL先跑一部分,然后回头再跑优化器,看看能不能满足一些优化规则来让SQL执行得更加高效。
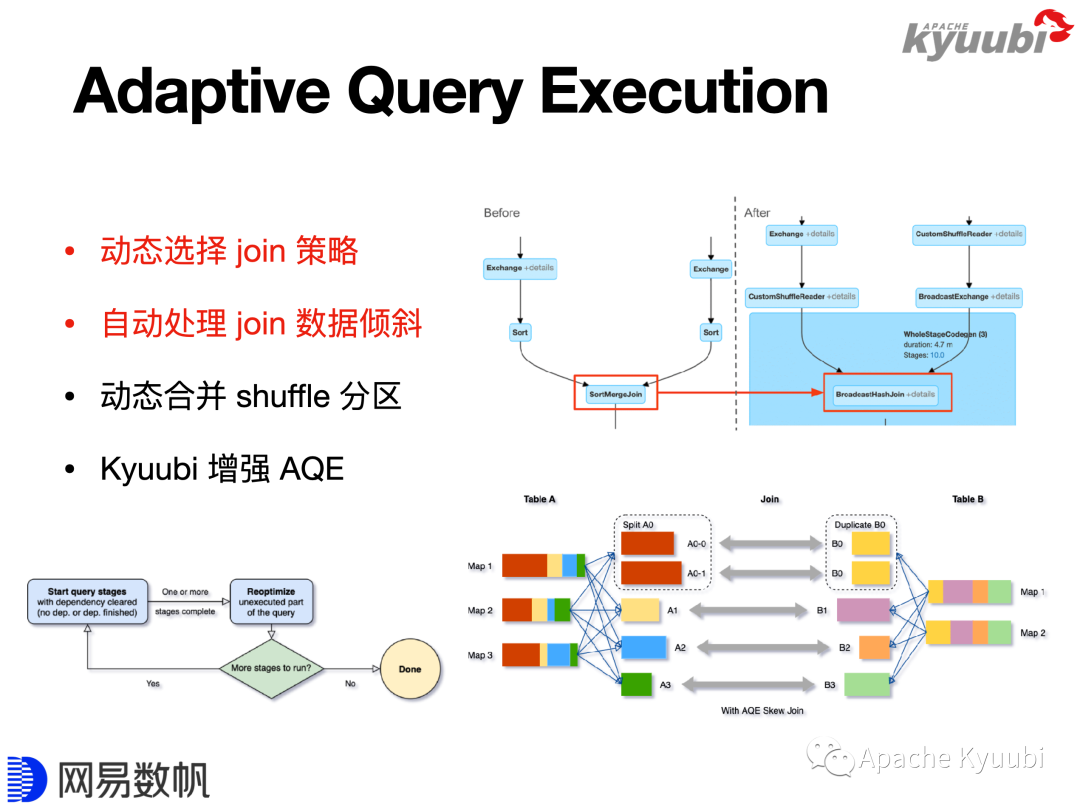
另一个典型的场景是数据倾斜。我们讲大数据不怕数据量大,但是怕数据倾斜,因为在理想情况下,性能是可以通过硬件的水平扩展来实现线性的提升,但是一旦有了数据倾斜,可能会导致灾难。还是以Join为例,我们假定是一个等值的Inner Join,有个别的partition特别大,这种场景我们会有一些需要修改SQL的解决方案,比如把这些大的挑出来做单独处理,最后把结果Union在一起;或者针对特定的Join Key加盐,比如加一个数字后缀,将其打散,但是同时还要保持语义不变,就是说右表对应的数据要做拷贝来实现等价的Join语义,最后再把添加的数字后缀去掉。
可以发现,这样的一个手工处理方案也是有一定规律可循的,在Spark中将该过程自动化了,所以在Spark3里面开启了AQE后,就能自动帮助解决这类Join的数据倾斜问题。如果我们的ETL任务里面有很多大表Join,同时数据质量比较差,有严重的数据倾斜,也没有精力去做逐条SQL的优化,这样情况从HiveQL迁到Spark SQL上面可以带来非常显著的性能提升,10到100倍一点也不夸张!
Extension
Spark通过Extension API提供了扩展能力,Kyuubi提供了KyuubiSparkSQLExtension,利用Extension API在原有的优化器上做了一些增强。这里列举了其中一部分增强规则,其中有Z-order功能,通过自定义优化器规则支持了数据写入时Z-order优化排序的的功能,并且通过扩展SQL语法实现了Z-order语法的支持;也有一些规则丰富了监控统计信息;还有一些规则限制了查询分区扫描数量,和结果返回数量等。
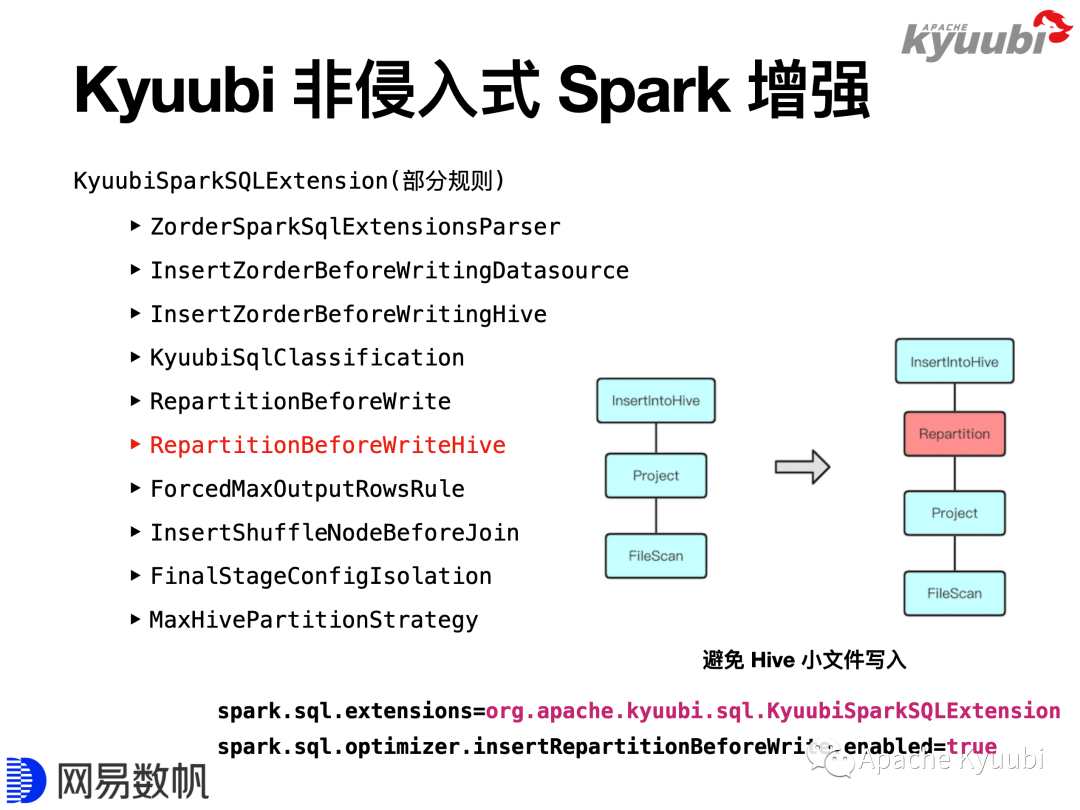
以RepartitionBeforeWriteHive为例做下简单介绍,这条规则用于解决Hive的小文件写入问题。对于Hive动态分区写入场景,如果执行计划最后一个stage,在写入Hive表之前,DataFrame的Partition分布与Hive表的Partition分布不一致,在数据写入时,每一个task就会将持有的数据写到很多Hive表分区里面,就会生成大量的小文件。当我们开启RepartitionBeforeWriteHive规则以后,它会在写入Hive表之前依照Hive表的分区插入一个Repartition算子,保证相同Hive表分区的数据被一个task持有,避免写入产生大量的小文件。
Kyuubi为所有规则都提供了开关,如果你只希望启用其中部分规则,参考配置文档将其打开即可。KyuubiSparkSQLExtension提供一个Jar,使用时,可以把Jar拷贝到${SPAKR_HOME}/jars下面,或命令参数--jar添加Jar,然后开启KyuubiSparkSQLExtension,并根据配置项来选择开启特定功能。
Spark on ClickHouse
Data Source V2 API也是Spark3引入的一个重要特性。Data Source V2最早在Spark 2.3提出,在Spark 3.0被重新设计。下图用多种颜色标记不同的Spark版本提供的Data Source V2 API,我们可以看到,每个版本都加了大量的API。可以看出,DataSourceV2 API 功能十分丰富,但我们更看重的是它有一个非常良好的扩展性,使得API可以一直进化。

Apache Iceberg在现阶段对Data Source V2 API提供了一个比较完整的适配,因为Iceberg的社区成员是Data Source V2 API主要设计者和推动者,这也为我们提供了一个非常好的Demo。
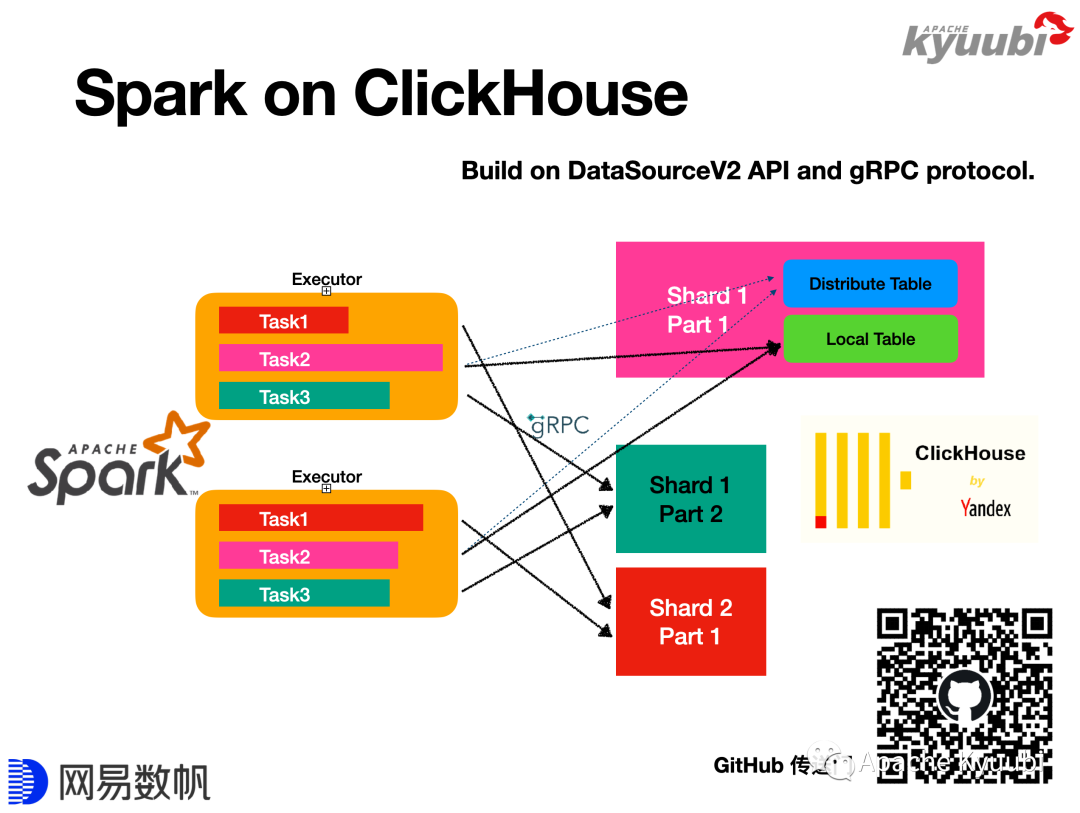
ClickHouse目前在OLAP领域,尤其在单表查询领域可以说是一骑绝尘,如果我们能结合Spark和ClickHouse这两个大数据组件,让Spark读写ClickHouse像访问Hive表一样简单,就能简化很多工作,解决很多问题。
基于Data Source V2 API,我们实现了并开源了Spark on ClickHouse,除了适配API提升Spark操作ClickHouse的易用性,也十分注重性能,其中包括了支持本地表的透明读写。ClickHouse基于分布式表和本地表实现了一套比较简单的分布式方案。如果直接写分布式表,开销是比较大的,一个变通的方案是修改调整逻辑,手动计算分片,直接写分布式表背后的本地表,该方案繁琐且有概率出错。当使用Spark ClickHouse Connector写ClickHouse分布式表时,只需使用SQL或者DataFrame API,框架会自动识别分布式表,并尝试将对其分布式表的写入转化成对本地表的写入,实现自动透写本地表,带来很大的性能提升。
项目地址:
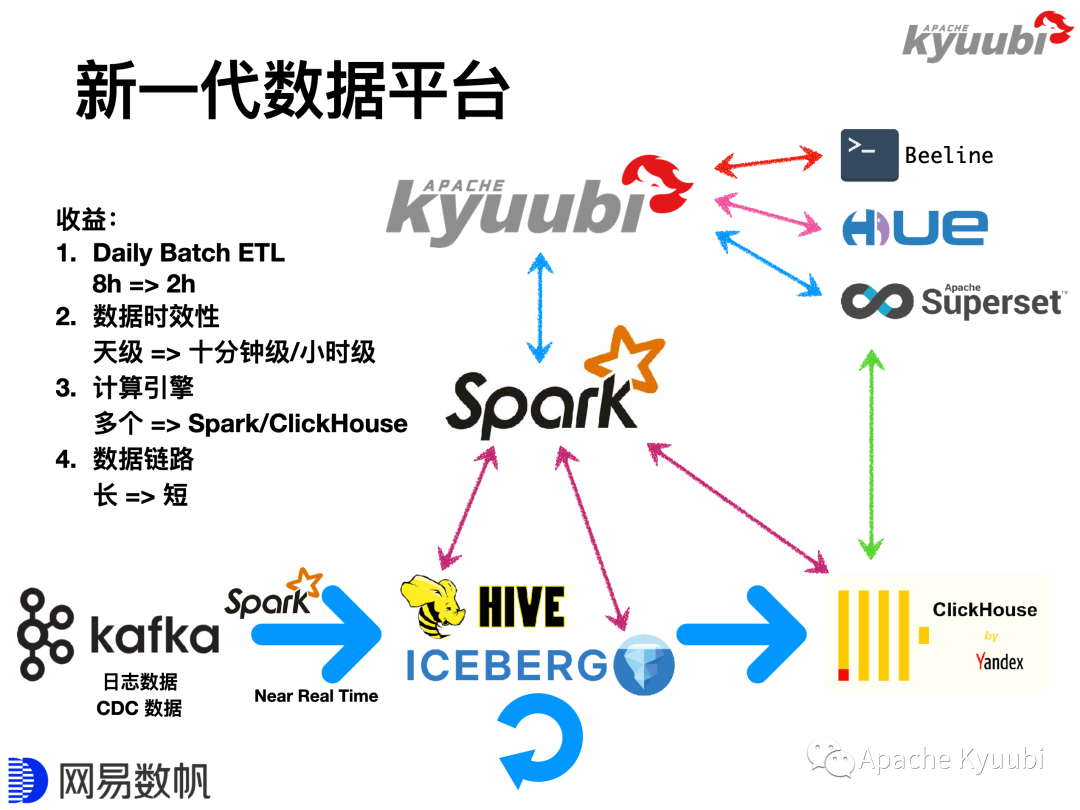
下图描绘了经过改造之后的新一代数据平台,改造带来了十分显著的收益。在硬件资源不变的情况下,首先,Daily Batch ETL从8个小时下降到了2个小时;其次,通过引入Iceberg和增量同步,数据的时效性是从天级降至十分钟级;第三,收缩计算引擎,原有平台需要搭配Hive、Elasticsearch、Presto、MongoDB、Druid、Spark、Kylin等多种计算引擎满足不同的业务场景,在新平台中,Spark和ClickHouse可以满足大部分场景,大大减少了计算引擎的维护成本;最后,缩短了数据链路,在以前,受限于RDMS的计算能力,我们往往在数据展示前需要进行一遍一遍的加工,最终把聚合结果放到MySQL里面,但是当引入ClickHouse以后,通常只要把数据加工成主题大宽表,报表展示借助ClickHouse强悍的单表计算能力,现场计算就可以了,所以数据链路会短很多。
Kyuubi 社区展望
最后展望一下Kyuubi社区未来的发展。刚才提到了Kyuubi架构是可扩展的,目前Kyuubi兼容HiveServer2,是因为仅实现了Thrift Binary协议;Kyuubi目前仅支持Spark引擎,Flink引擎正在开发中,这项工作由T3出行的社区伙伴在做。RESTful Frontend社区也正在做,这样我们也可以提供RESTful API。我们还计划提供MySQL的API,这样用户就可以直接使用MySQL Client或MySQL JDBC Driver来连接。后面附了社区里面相关的issue或者PR。
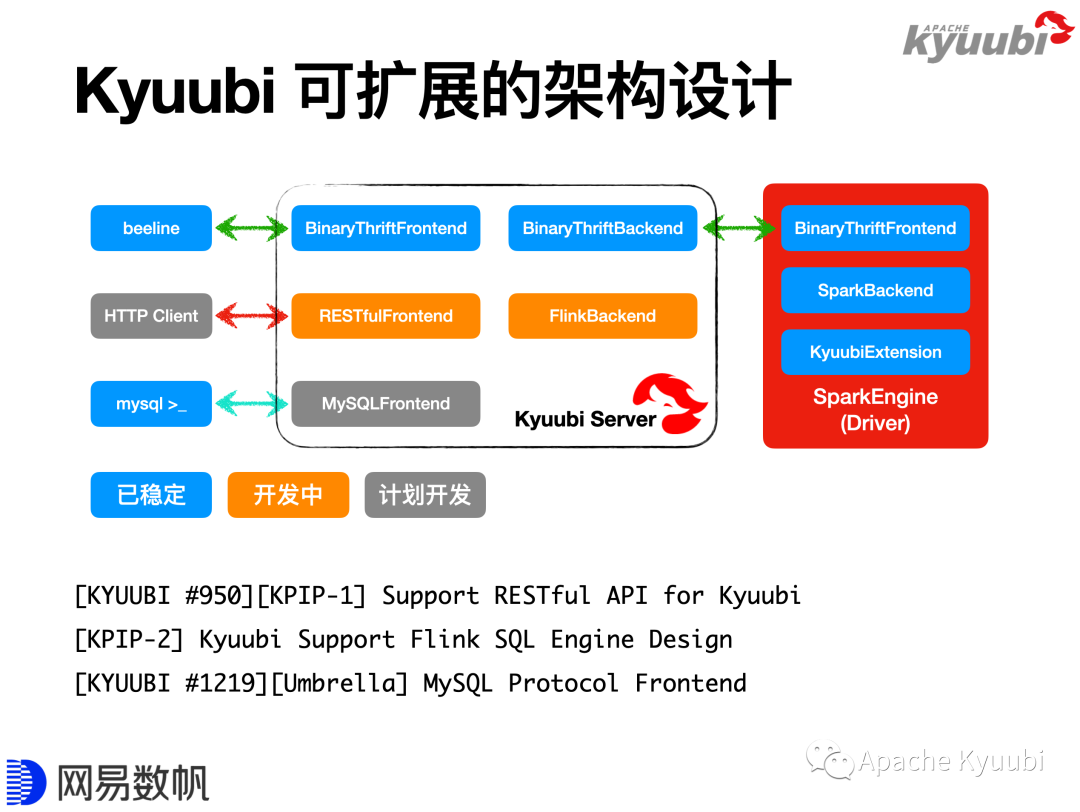
如下是即将出现在1.4版本中的一些特性,包括刚才已经提到过的Engine Pool、Z-order、Kerberos相关的解决方案,以及新发布的Spark 3.2的适配工作。
[KYUUBI #913] Support long running Kerberos enabled SQL engine
[KYUUBI #939] Add Z-Order extensions to support optimize SQL
[KYUUBI #962] Support engine pool feature
[KYUUBI #981] Add more detail stats to kyuubi engine page
[KYUUBI #1059] Add Plan Only Operations
[KYUUBI #1085] Add forcedMaxOutputRows rule for limitation
[KYUUBI #1131] Rework kyuubi-hive-jdbc module
[KYUUBI #1206] Support GROUP for engine.share.level
[KYUUBI #1224] Support Spark 3.2
. . .最后展示一下已知使用Kyuubi的企业,如果你也使用Kyuubi,或者在调研企业级的Spark SQL Gateway方案,有任何相关的问题,欢迎可以到我们社区里面分享、讨论。
GitHub分享页面:

结语
本文根据网易数帆大数据平台专家、Apache Kyuubi(Incubating) PPMC成员潘成在 Apache Hadoop Meetup 2021 北京站的分享内容整理,重点结合实际落地的案例讲述了如何实现 Apache Kyuubi(Incubating) on Spark和CDH集成,以及该方案为企业数据平台建设带来的收益,并展望了Apache Kyuubi(Incubating) 社区未来的发展。

Apache Kyuubi(Incubating)项目地址:
https://github.com/apache/incubator-kyuubi
视频回放:
https://www.bilibili.com/video/BV1Lu411o7uk?p=20
案例分享:
Recommend
-
8
Apache Kyuubi PPMC 燕青:为什么说这是开源最好的时代? 2021 年 8 月 04 日
-
8
在 Apache 首次亚洲线上技术峰会 --ApacheCon Asia 大会上,网易数帆大数据专家,Apache Kyuubi PPMC,Apache Spark / Submarine Committer 燕青...
-
7
Spark 开源地址:https://spark.apache.org/ 开源的、强大的计算引擎。 官网下载Release,比如:Spark 3.1.2
-
7
Kyuubi 是网易数帆主导开源的大数据项目,于2021年6月
-
2
支撑了80%的离线作业,日作业量在1W+ 大多数场景比 Hive 性能提升了3-6倍 多租户、并发的场景更加高效稳定 T3出行是一家基于车联网驱动的智慧出行平台,拥有海量且丰富的数据源。因为车联...
-
6
Kyuubi 简介 Apache Kyuubi (Incubating)是一个 Thrift JDBC/ODBC 服务,目前对接了 Apache Spark 计算框架,支持多租户和分布式等特性,可以满足企业内诸如 ETL、BI 报表等多种大数据场景的应用。Kyuubi 可以为企业级数据湖探索提供标准化的接口...
-
4
分享的内容主要包括三个内容: 1) Apache Kyuubi (Incubating) (以下简称Kyuubi)是什么?介绍Kyuubi的核心功能以及Kyuubi在各个使用场景中的解决方案; 2) Kyuubi在网易内部的定位、角色和实际使用场景; 3) 通过...
-
7
01 背景介绍 近几年随着B站业务高速发展,数据量不断增加,离线计算集群规模从最初的两百台发展到目前近万台,从单机房发展到多机房架构。在离线计算引擎上目前我们主要使用Spark、Presto、Hive。架构图如下所示,我们的BI、ADHOC...
-
8
导读 本文将分享 Apache Kyuubi 在爱奇艺的一些实践和落地。 文章将围绕下面三点展开: 爱奇艺 Spark Thrift Server 服务演进 Spark SQL 平台化适配 Spark SQL 服...
-
2
导读 本文主要介绍 Apache Kyuubi 最新版本 1.8 的特性与改进。 本次分享主要分为以下部分: Apache Kyuubi 简介 场景扩展 ------ 在线分析,离线跑批 流式增强 ------ 流批一体,...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK