

外星世界,真实呈现,外星版Pokemon Go是如何做到的?
source link: https://my.oschina.net/u/4067628/blog/5253141
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


背景介绍
基于Pokemon的故事背景的Pokemon Go在刚上线时,在全世界风靡一时。玩家可以通过智能手机在现实世界里发现宠物小精灵(宝可梦),进行抓捕和战斗。打开手机App, 通过摄像头画面就能看到Pokemon出现在真实世界中。
游戏于2016年7月开始发行,在2016年8月17日获得五项吉尼斯世界纪录认证:
被认定为“上线一个月以来收益最多的手游”
“最快取得1亿美元收益的手游(耗时20天)”
“上线一个月后下载次数(约1.3亿次)”
“上线一个月后在最多国家下载次数排行第一(约70多个国家)”
“上线一个月后的收益额在最多国家排行第一(约55个国家)”
其AR的玩法加上Pokemon的IP,让其红透一时。大家在体验后,其后续热度没有长期维持。这可能是因为这些AR游戏仅基于手机的陀螺仪及GPS定位等。只是把游戏角色放在摄像头画面中,并没有与摄像头中的现实场景有什么交互,让玩家觉得有违和感。
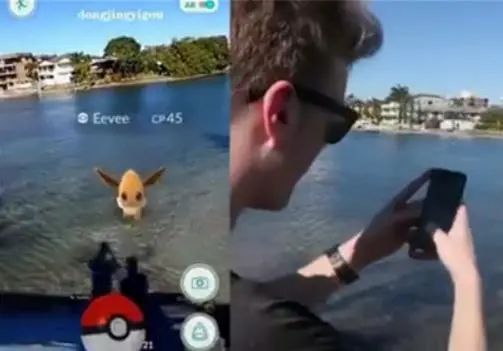
如下图,熟知Pokemon的同学都知道,普通伊布应该是不会在水面上或河中的,但因为GPS定位的偏差性,这在之前是无法避免的。
项目背景
是否借助深度学习的技术,我们就能实现更棒的AR呢? 随着深度学习技术的发展,DL技术逐步应用于AR领域。Google也推出了跨平台的MediaPipe,可实现部分物体的3D AR识别与跟踪。希望飞桨后续也推出类似的。但基于当前飞桨提供的技术能力,我们也能实现AR体验感优于PokemonGo的效果。
当然,这次我们不是寻找、捕捉宠物小精灵;而是搜寻外星人在地球的痕迹。我们大家都不知道外星人长什么样,那让GAN来协助我们,预测外星人是长什么样子的。或许像电影《黑衣人》中所描述的,外星人早已在我们身边,只是他们装扮成地球人一样,跟我们一起生活,我们没有发现而已。
为达到上述目标,我们需要用到 图像生成、识别、定位、图像融合、跟踪等技术。基于本次介绍的内容用在wechaty微信聊天端,所以仅结合了前面4项技术。
方案概要
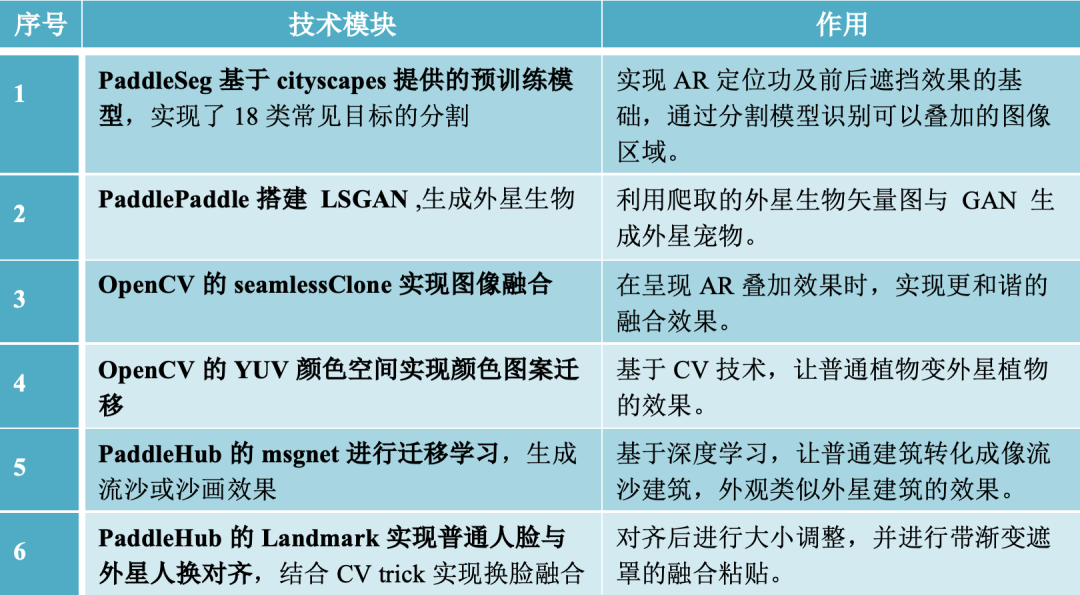
方案主要模块
本文介绍的内容及代码均可在下面项目中获取:
GitHub地址:
https://github.com/kevinfu1717/SuperInterstellarTerminal
AI Studio地址:
https://aistudio.baidu.com/aistudio/projectdetail/2230251?shared=1
微信聊天机器人互动展示gif,在微信中体验AR寻找外星人:

扫码进群,按群公告操作可进行体验 :

技术实现
1 识别图片中的环境
1.1. 模型
PaddleSeg提供了20+主流分割网络,50+高质量的预训练模型。在本项目中使用Cityscapes SOTA模型进行图像分割,实现AR的定位及遮罩效果。我为此做了简化与抽取,只提取了做inference仅需的内容,方便进行直接使用,这样就能快速体验这个模型。
对整个项目进行简化后,必需的文件结构如下:
├── CityscapesModule.py
└── PetModel
├── modelCityscape.pdparams
├── pretrainedCityscape.pdparams
└──mscale_ocr_cityscapes_autolabel_mapillary_ms_val.ymlpretrainedCityscape.pdparams下载地址:
https://bj.bcebos.com/paddleseg/dygraph/cityscapes/ocrnet_hrnetw48_mapillary/pretrained.pdparams
modelCityscape.pdparams下载地址:
https://bj.bcebos.com/paddleseg/dygraph/cityscapes/mscale_ocr_hrnetw48_cityscapes_autolabel_mapillary/model.pdparams
mscale_ocr_cityscapes_autolabel_mapillary_ms_val.yml 为模型的配置文件(需注意修改里面的pretrain model路径,其他不用修改)
1.2. 使用
图像分割实现定位
让AI能感知环境里有哪几样类别,同时可以定位其在图片中的具体位置。如:植物、人行道、墙壁、建筑天空等。返回的pred为分割结果,是一个二维数组,该数组尺寸与原图一样,每个像素的值对应类别,从0~17类。可用np.where(mask == index, 1, 0)来截取自己感兴趣的区域。Index为感兴趣的类别ID。
#把图片送入cistyScaperClass中的run,即可获取分割图
def run(self,image):
pred=[]
try:
t1=time.time()
## 前处理
im,ori_shape=preProcess(image,self.transforms)
print('seg time',time.time()-t1)
t2=time.time()
with paddle.no_grad():
## 预测 并进行后处理(如:转换回原图的尺寸)
pred = infer.inference(
self.segModel,
im,
ori_shape=ori_shape,
transforms=self.transforms.transforms,)
pred = paddle.squeeze(pred)
pred = pred.numpy().astype('uint8')
print('seg time',time.time()-t2)
except Exception as e:
print(e)
return self.resultCode[7],pred
#pred为结果,是一个二维数组,该数组尺寸与原图一样,每个像素的值对应类别,从0~17类
return self.resultCode[4],pred
(PS:注意真实返回的ID是从0开始的,所以是trainId-1,如:sky实际返回的id是10 not 11):

1.3. 效果展示
CityscapesModule.py中把pred ×10后保存成图片,见右下图(图片像素的灰度值从0~180)。

2 LSGAN生成外星生物
先看一下GAN生成的外星生物长什么样子:

2.1. GAN的训练图片:
首先,我们从百度爬取“外星人”的图片,但因为外星人搜出来的图比较杂乱。所以改变思路,用关键词“外星人 矢量”来进行搜索爬取。搜出来的外星人图片相对没那么杂乱,勉强可以用来训练。大概有1/5左右是白底,有1/5左右是PS中那种透明图的格子底图或水印的,有1/5是背景各种颜色的图,还有1/5是多个外星元素组成的图。如下图:

爬取代码较简单,就不贴出了,若要参考可到项目中查看:
https://aistudio.baidu.com/aistudio/projectdetail/2210138
2.2. 数据增广:
尝试过用midars模型或CV来提取单个外星生物,但效果都不是很好。所以,最终只使用水平翻转,增加了一倍的数量。尽管可以通过爬取来增加数量,但越到后面,爬取的图片越杂乱,而且没有相关性。所以还是通过水平翻转来处理。
最终训练使用3000多张图片,经水平翻转增广后,投入训练的有6000多张。
后续与PaddleGAN方向的工程师进行沟通。他们给了几个不错的建议可进行尝试:
每次训练生成的比较好效果的图片再投入进行作为训练样本。
基于训练图进行颜色变换。
2.3. 模型训练
1. 训练模型选用LSGAN,可能StyleGAN V2效果会更好,大家可以在PaddleGAN中尝试直接尝试StyleGAN V2模型。
2. LSGAN的对比传统GAN的优势:传统 GAN 的训练过程十分不稳定,这很大程度上是因为它的目标函数,尤其是在最小化目标函数时可能发生梯度弥散,使其很难再去更新生成器。而论文指出 LSGAN 可以缓解这个问题,因为 LSGAN 会惩罚那些远离决策边界的样本,这些样本的梯度是梯度下降的决定方向。

LSGAN 的损失函数如下:

LSGAN模型的搭建基于AI Studio上的项目通过LSGAN以及WGAN-GP实现128*128大小的喀纳斯风景图片 。在其基础上,每个Epoch执行更多的Generation,以及修改了其中的超参数。
训练过程。训练过程中可看到还是有不稳定的情况,判别器loss突然高,出现完全花了的图。Epoch 0 ~ Epoch 999 的训练过程见下图:

不足:
大概在200 Epochs就已经差不多,再训练到1000 Epochs反而效果还下降了。
最终会有不少彩色的杂点。
生成的外星生物矢量图有些还保留训练图的方格背景之类的。
生成的外星生物可能有部分过拟合,与原来的训练照片有点像。
备注:
因GAN直接生成的图片效果还不完美,我们把其叠加到现实图像中做AR效果时,使用cv处理优化这部分,如:开闭运算,seamlessclone时设置不同的参数等,去掉周围的杂色。
已训练好的模型见AI Studio数据页:
https://aistudio.baidu.com/aistudio/datasetdetail/103316
训练项目见:
https://aistudio.baidu.com/aistudio/projectdetail/2210138?shared=1
整体来说生成的还行,对比外国网友用GAN来生成宠物小精灵的效果,这个还是相当可以的。
3 AR效果叠加(外星宠物)

上图中你能找到几个外星生物呢?
实现过程:
实现对应位置的叠加AR效果。如:天空中出现飞在天上的外星飞碟或外星生物,树丛中会出现喜欢在树上的草食性外星生物。基于分割模型得到图像中对应事物mask区域,例如哪里是天空,哪里是人行道,按照外星生物可存在的位置判断是否出现外星生物,及其出现位置。
融合粘贴部分可使用DL的方法Deep Painterly Harmonization ,也可以使用普通图像处理的方式实现。我这里先用图像处理的方式实现,需调用OpenCV的 seamlessClone。根据外星生物的特性使用cv2.seamleClone,参数选用MIXED_CLONE或NORMAL_CLONE。MIXED_CLONE或NORMAL_CLONE差异见下方所述。
分析对比cv2.seamlessClone三种图像合成效果
# 会把src图的边缘进行模糊化,同时整个src图的色彩融合到dst中->需要src图较清晰,dst背景较简单,可以接受src图周边边缘模糊的场景
cv2.seamlessClone(src, dst, src_mask, center, cv2.NORMAL_CLONE)
# 基于透明度的融合,src图中白色的区域会显得透明度高,看起来叠加的颜色比较透->适合dst背景较复杂,但对src图清晰度要求不高,src图背景是白色的场景
cv2.seamlessClone(src, dst, src_mask, center, cv2.MIXED_CLONE)
# 会把src图变成灰度图合成到dst中->暂时看不到什么好用途
cv2.seamlessClone(src, dst, src_mask, center, cv2.MONOCHROME_TRANSFER)
借用别人的图,左中右分别是:NORMAL_CLONE , MIXED_CLONE , MONOCHROME_TRANSFER:
简单背景:

复杂背景:

效果好坏与背景图dst及前景图src都有关系。
4.结合mask的优化版seamlesClone图像合成效果
4.1.把src的外星生物图转成HSV格式,通过V通道,V大于200得到二值化的mask。HSV的V分量可以当作是亮度,在本次LSGAN生成的外星人中基本都是白色底的,可以抠去白色底
4.2.二值化的图进行开运算。去除LSGAN中生成的一些彩色噪声点,得到外星生物的mask,宁愿漏也不要去多了。因为合成时有个渐变,自然就把杂点淡化了。
4.3.把2中的二值化图进行边缘裁切,使mask图的四个边都有白色区域接触。这可能是seamlessClone的一个bug,若白色区域不接触图像边缘,其合成时的位置是按白色区域的中心点位置,不是mask图像的中心点位置,切记!
4.4.根据裁切后的mask,重新计算中心点左边center=(x,y)。seamlessClone的center参数是src的中心点在dst图中的位置。
4 外星人换脸
实现过程:
PaddleHub landmark模型作为人脸与外星脸对齐的基础点。landmark的68个人脸关键点模型具体介绍请见官方介绍:
https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.1/modules/image/keypoint_detection/face_landmark_localization
找到一张外星人正面的照片与侧面的照片,扣出其形象保存图片。我们需要手动用labelme的keypoint为其标上68个关键点,大概就好,不用太精确。landmark数据按labelme格式保存到json中。

3. 对用户发来的图片,利用PaddleHub的landmark模型获取图片中的人脸特征点。判断是正脸还是侧脸,根据正脸或侧脸使用对应的外星人照片。若角度太偏则不进行处理。然后,使用landmark中脸颊的特征点求中点进行人脸图像位置上的对齐。并根据用户图片的人脸对外星人人脸进行大小调整。
4. 融合粘贴
截取外星人人脸,生成一个上到下的渐透明的遮罩图。用cv2.seamlessCloned的NORMAL_CLONE复制到原人脸位置,但因为seamlessClone没法调参数的,外星人形象融在背景里面,不太明显不清晰。
截取外星人人脸及颈部及上半身,生成一个上到下的渐透明的遮罩图。用cv2.addWeight把外星人脸与1中所述的人脸进行透明度融合。

直接把外星人脸贴到用户图上边缘会很硬,如上图中的左图。项目中,还用了双重叠加方式,使外星人脸融合更佳自然,具体方法及代码请见项目。
5 外星植物——基于非深度学习的颜色图案迁移

颜色空间:
我们图片中最常用的颜色通道是RGB或OpenCV默认的BGR颜色空间。对应我们的红、绿、蓝三原色。除了这最常见的也有HSV, HSI, Ycrcb, YUV等颜色空间。我们进行CV的图像处理时较少在RGB颜色空间处理,而是转到HLS/HSV 也有 YUV颜色空间进行处理。这样作的好处是 其中的H 通道在一定程度上可以表示其颜色。通过这样来选择特定的颜色,S代表饱和度,V代表亮度。而YUV中 Y是亮度,U,V分别是 蓝 红 通道。

YUV颜色空间详细介绍可参见:
https://zhuanlan.zhihu.com/p/95952096
实现过程:
我们利用cityscaps模型分割出了植物的区域。把模板图调整到与这些区域大小一致,然后对这些区域的图像进行处理,使其颜色纹理混合上我们指定的模板文件。需先找来一些外星植物或想要转换的风格的图片。
我们可以保留模板的U,V通道(外星植物的颜色),Y通道亮度则通过系数调节比例。实现在大部分保留模板的纹理与颜色,也保留了原图的亮度变化信息。简单来说,原图较暗的区域,新合成的图也会较暗趋于黑色,而原图较亮颜色丰富的区域则换成了模板图的纹理与颜色。
# 把图片style,content转到yuv空间
yuv = cv2.cvtColor(np.float32(style), cv2.COLOR_BGR2YUV)
y, u, v = cv2.split(yuv)
yuv2 = cv2.cvtColor(np.float32(content), cv2.COLOR_BGR2YUV)
h, j, k = cv2.split(yuv2)
# 根据ratio这个比例来合成 style 与 content两张图
hy = np.array((h * ratio + y * (1 - ratio)), 'uint8')
# hy = np.clip(hy, 0, 255)
# 两张图进行合成
content = np.dstack((hy, u, v))
content = cv2.cvtColor(np.float32(content), cv2.COLOR_YUV2BGR)
上述处理非常简单,但缺点就是纹理是严格对齐模板图的纹理,没有适应原图的周边的图案。
6 外星建筑——基于深度学习的风格迁移
使用PaddleHub中的msgnet风格迁移模型,针对沙画图片进行finetune,从而得到类似沙画/流沙风格模型,并对图片中的建筑进行此风格迁移处理。

风格迁移:
风格迁移可以说是深度学习在艺术上最早的应用,在2016年时就出现了 Neural Style ,之后pixel2pixel等一系列的模型也陆续出现。MSG-Net。因为PaddleHub中的msgnet是用COCO数据集与油画数据集训练的,直接使用迁移成流沙或沙画风格,效果不太好。所以需要进行finetune。

1. msgnet的backbone用的是vgg16。进行finetune时,我们把这backbone层参数固定,不更新梯度。否则,若不固定backbone很快就模型就飞了,任何图迁移都只得到一张黑色的图。
checkpoint='/home/aistudio/model/msgnet/style_paddle.pdparams'
model = hub.Module(name='msgnet',load_checkpoint=checkpoint)
print(type(model),' parameters nums:',len(model.parameters()))
##
for index,param in enumerate(model.parameters()):
# model的前25层设置成不进行梯度更新
if index>25:
param.stop_gradient=False
else:
param.stop_gradient=True
2. 训练数据集使用aistudio上的miniCOCO, 共2001张训练图片。沙画风格的图片使用一张即可,否则因沙画同风格的图片较难收集,不同风格的沙画反而不好收敛。单张沙画,batch size=32,在32G的v100上训练65个epoch,已可以得到不错的效果。
optimizer = paddle.optimizer.Adam(learning_rate=0.0001, parameters=model.parameters())
trainer = Trainer(model, optimizer,use_gpu=True,use_vdl=True, checkpoint_dir='test_style_ckpt')
trainer.train(styledata, epochs=65, batch_size=32, eval_dataset=None, log_interval=10)
1. 若想直接体验该模型,可直接下载模型。AI Studio数据页:
https://aistudio.baidu.com/aistudio/datasetdetail/102698
项目地址:
https://github.com/kevinfu1717/sand-painting
2. 在这个项目,我们仅需利用cityscapes模型分割出的建筑作为mask,对这部分进行上述模型的风格迁移即可生成流沙或沙画风格的建筑。
大家可以对比植物部分基于CV的颜色迁移与这个建筑的基于DL的风格迁移。他们其实各有特点,这些技术都只是一个工具,要用哪个,什么时候用,还是看我们具体的应用场景。
总结
随着深度学习的发展,不仅模型的精度越来越高,各式的模型越来越多。结合多个模型的效果,加上一些原来CV的一些技术,我们可以实现越来越棒的效果。无论是哪种模型或者哪种CV的trick,我们都可以把其作为工具,希望未来使用这些各式的工具时,可以像使用Photoshop等工具那么简单。
长按下方二维码立即
Star

更多信息:
飞桨官方QQ群:793866180
飞桨官网网址:
www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
github.com/PaddlePaddle/Paddle
Gitee:gitee.com/paddlepaddle/Paddle
欢迎在飞桨论坛讨论交流~~
http://discuss.paddlepaddle.org.cn
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK