

一文帮你掌握TDengine的降采样查询+跨时区统计
source link: https://my.oschina.net/u/4248671/blog/5308370
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一文帮你掌握TDengine的降采样查询+跨时区统计 - 涛思数据TDengine的个人空间 - OSCHINA - 中文开源技术交流社区
 作者|陈玉,涛思数据
小 T 导读:作为一款高性能的时序数据库,TDengine提供了强大的数据分析功能。在TDengine官网的第一个章节里,有这样的描述:“无论是十年前还是一秒钟前的数据,指定时间范围即可查询。数据可在时间轴上或多个设备上进行聚合。”
作者|陈玉,涛思数据
小 T 导读:作为一款高性能的时序数据库,TDengine提供了强大的数据分析功能。在TDengine官网的第一个章节里,有这样的描述:“无论是十年前还是一秒钟前的数据,指定时间范围即可查询。数据可在时间轴上或多个设备上进行聚合。”
今天,我们的主角就是上文中“可在时间轴上”聚合的强大函数——INTERVAL。
INTERVAL是TDengine一大重要功能,可以帮助我们实现降低数据采集频率的功能——也就是降采样。举个简单的例子:假设我们有某个设备一年的数据,时间数据的频率是1天,那么就是一共365条数据。现在,如果我们想按照‘月’这个频率统计,那么数据量就变成了12条。
根据官网的语法描述,相关的功能模块有三个:- INTERVAL本身
- SLIDING
- INTERVAL OFFSET
 对于以处理时序数据为根基的时序数据库来说,如何灵活的利用时间频率来计算分析数据实在是太重要了。下面我们围绕上面三个功能模块,分别举一个简单的应用场景的例子并做出具体说明:
对于以处理时序数据为根基的时序数据库来说,如何灵活的利用时间频率来计算分析数据实在是太重要了。下面我们围绕上面三个功能模块,分别举一个简单的应用场景的例子并做出具体说明:
INTERVAL:查询温度传感器t1记录的温度、压力每五分钟的平均值
select avg(t), avg(p) from t1 interval(5m);这是一个最简单的使用情况,INTERVAL负责指定时间范围窗口,由AVG这种聚合函数来计算这个时间范围内的平均值。也可以换成MAX/MIN这类的选择函数,来统计出这个时间范围内的最大值/最小值。(在TAOS SQL中,聚合函数指的是COUNT/AVG/TWA/SUM等用于从数据集中汇合再计算的函数,选择函数是指 MIN/MAX/FIRST/LAST/LAST_ROW等用于从数据集中筛选结果的函数。) INTERVAL本质上就是group by的时间版本,所以一定需要配合上述聚合或选择函数来使用。INTERVAL后面的时间单位可以是 a(毫秒)、s(秒)、m(分)、h(小时)、d(自然日)、w(周), n(自然月) 和 y(自然年)。(最小10毫秒,暂时还不支持自然周,interval(1w) 目前等效于interval(7d))。
SLIDING:可以统计类似股票市场的均线
select avg(t) from stockmarket interval(5d) sliding(1d)。上述语句的实际含义是统计股市上某股票所有每过一天的5天的价格平均值,把这些值连起来,就是大家熟知的五日均线了。
在上述计算过程中,SLIDING起到了非常关键的作用。我们已经知道,INTERVAL 的值负责指定每次执行查询的时间窗口。SLIDING则代表着指定窗口向前滑动的时间。如下图所示:
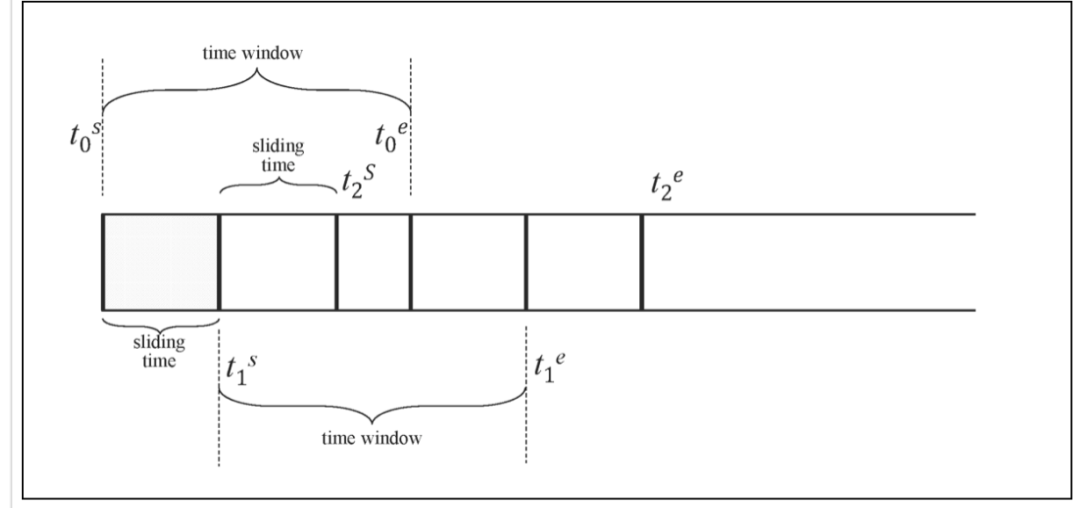
t0s,t1s,t2s分别是三个时间窗口的起点,t0e,t1e,t2e分别是三个时间窗口的终点。当我们在查询中不指定SLIDING的值时,它默认等于INTERVAL VALUE。也即是说在第一个例子当中的select avg(t), avg(p) from t1 interval(5m)等效于select avg(t), avg(p) from t1 interval(5m) sliding (5m);
INTERVAL OFFSET:统计某个设备在其他时区(向西相差三个时区)的一个月的总数据量
select sum(t) from t1 interval(1n,3h) ;INTERVAL OFFSET会相对复杂一些。想了解的话,需要先更多地了解INTERVAL和时区的关系。
如果INTERVAL的值是自然日(d),自然月(n),自然年(y),那么它就是对齐TDengine服务端所在时区的0点开始做的窗口切分,如下图所示:不论当前所属哪个时区,所有时间戳列的起始时间都是0点。
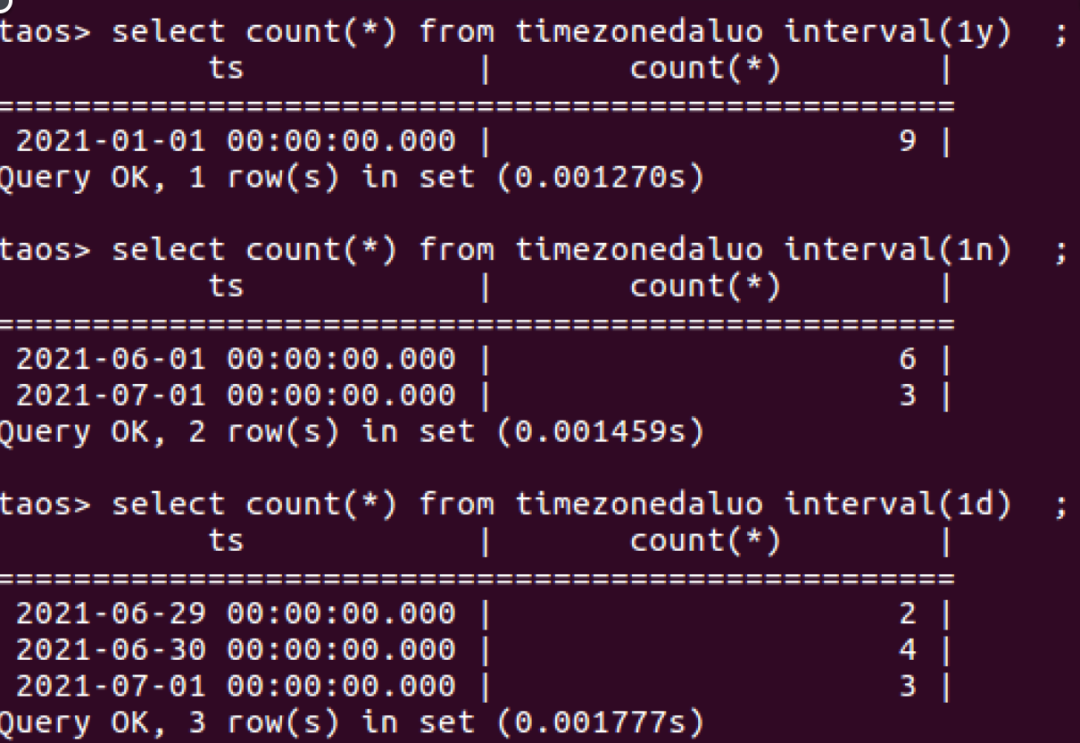
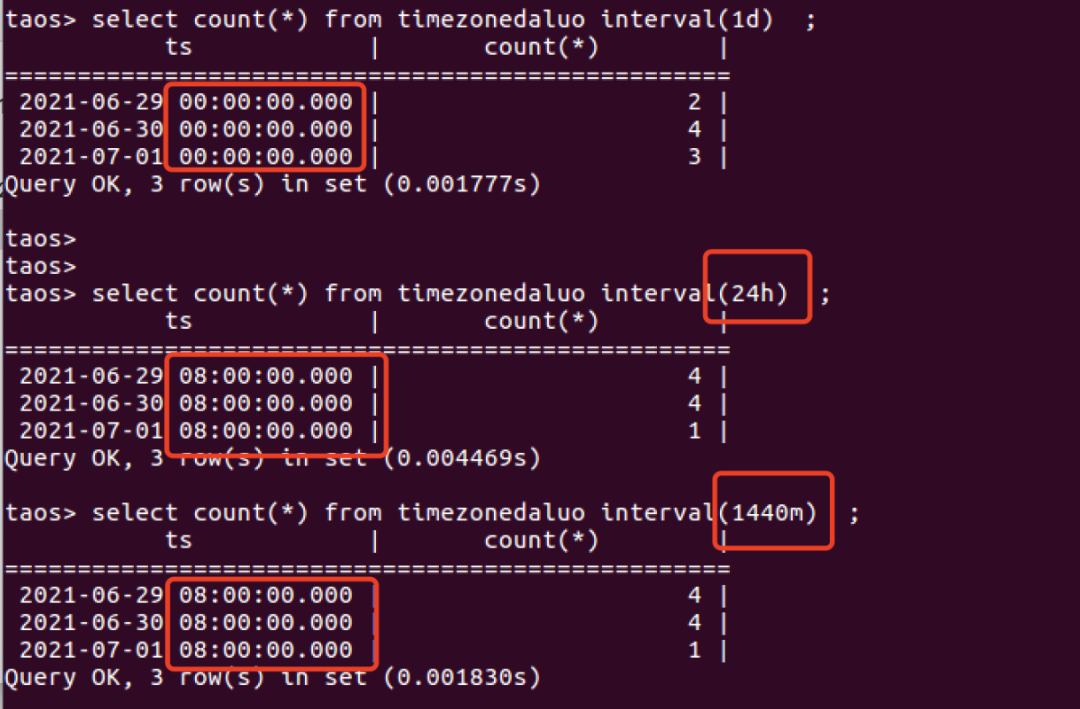
总结一下就是:TDengine以时间戳形式来存储时间数据,时间戳本身是一个和时区无关的东西,但是由于TDengine要把数据查询出来展示给世界上不同地区的用户看,就和时区有关系了。在INTERVAL中,如果是自然日,自然月,自然年,均以TDengine服务端所在时区的0点为起始时间进行时间窗口区分。如果是以h(小时)及以下为单位切分窗口,那么进行窗口切分的起始时间就是UTC时区的0点。TDengine 中时间戳的时区总是由客户端进行处理,与服务端无关。具体来说,客户端会对 SQL 语句中的时间戳进行时区转换,转为 UTC-0时区的Unix时间戳再交由服务端进行写入和查询;在读取数据时,服务端也是采用 UTC-0时区提供的原始数据,客户端收到后再根据本地设置,把时间戳转换为本地系统所要求的时区进行显示。
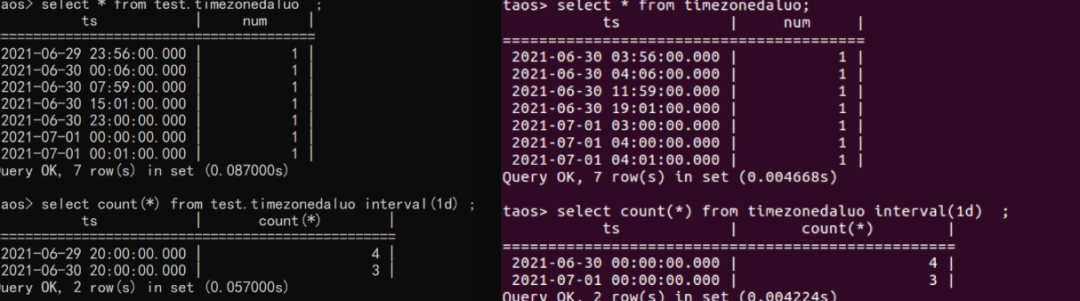
不论是哪个时区的客户端,最终的计算列结果都是一致的,只是由于时区不同,所以显示的时候在时间戳列上会有一些偏差。因此我们强烈建议,非特殊情况下,客户端服务器和服务端服务器的时区要保持一致,从而使得两边的查询显示是一致的,从而减少不必要的误解。
比如,左侧客户端count(*)看起来应该是1 4 2,实际上却是4和3。这就是因为两边时区不一致导致的视觉差异。这时候就要以服务端的显示为准:6月30日有4条数据,7月1日有3条数据——TDengine服务端所在服务器的查询结果,永远是所见即所得的正确。
select sum(t) from t1 interval(1n,3h) ;👇点击阅读原文,体验TDengine!
本文分享自微信公众号 - TDengine(taosdata_news)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK