

The weirdest bug I've ever encountered
source link: https://mental-reverb.com/blog.php?id=29
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

The weirdest bug I've ever encountered
I am responsible for the reliability of the firmware updates on our devices and this work never gets boring. The thing about firmware updates is that by definition, every bug is caused by the updater because before installing the affected version, the bug was not present. You could say that updates are the cause and the solution of all software problems. So, a lot of update bug reports that find their way to me have nothing to do with the updater per se, they just manifest themselves immediately, giving the impression that the updater is broken. But I'm getting ahead of myself, so let's start from the beginning.
A new bug comes in: Update failed from version X to version Y, error getting log files from sensor. After that, the user manually rebooted the machine and it worked again.
I connect to the machine and download all the logfiles. In the logs, I see that the update installed successfully. After the reboot which starts the newly installed firmware, there were some minor problems: Some processes took a bit longer to start than expected. Other than that, the log looks clean, no errors that could explain this behaviour.
I try to install the affected Firmware version Y on various devices. The problem does not appear. But as luck has it, a co-worker encountered the problem and had the presence of mind to recognize it and leave the system undisturbed for analysis. Connecting to the system is difficult because it is laggy and slow. The device can barely handle simple commands. Weird. Let's run top.
60 processes; 646 threads;
CPU states: 16.0% user, 35.0% kernel
CPU 0 Idle: 55.4%
CPU 1 Idle: 42.4%
Memory: 0 total, 543M avail, page size 4K
PID TID PRI STATE HH:MM:SS CPU COMMAND
1 12 10 Run 1:51:21 17.72% kernel
1 5 10 Run 2:13:10 17.04% kernel
602168 1 10 Rdy 3:30:01 13.98% ps
229398 1 21 Rcv 0:09:32 0.67% smb-tunnelcreek
778301 1 10 Rply 0:00:00 0.62% top
253978 2 21 NSlp 0:05:43 0.40% devi-tsc2007
1 6 10 Rcv 2:08:09 0.25% kernel
7 2 21 Rcv 0:01:41 0.07% io-pkt-v4-hc
581675 15 10 CdV 0:00:17 0.07% telescope
8200 9 21 Rcv 0:00:35 0.05% io-usb
Min Max Average
CPU 0 idle: 55% 55% 55%
CPU 1 idle: 42% 42% 42%
Mem Avail: 543MB 543MB 543MB
Processes: 60 60 60
Threads: 646 646 646
Okay, we immediately have some clues here. The QNX kernel is doing a lot of stuff and so is ps. We see that the CPU load of the two cores is about 50%. But we know that the system has hyperthreading and only has one physical core, so the real load is actually more like 100%. To me, it looks like ps is saturating the core completely, the kernel load is probably caused by whatever ps is doing.
Who is calling ps? With ps -ef we can see the PPID, the parent process id, to track down who spawned this process. Ironically, we use ps to debug this ps problem. Like this, I find that it was spawned by the shell sh, which in turn was spawned by one of our proprietary processes. Equipped with the knowledge of which process is affected and analysing the logs to find out where this process got stuck, I quickly find the offending line of code. It looks like this: int rc = system( "ps -e | grep Foo" ); where Foo is some program whose presence we need to check. Not the prettiest way to implement it, but it is legacy code that worked for many years. I also see that this code only gets executed on certain old hardwares. This explains why the problem never reproduced on most systems, they have newer hardware. Even on the old hardware, it is exceedingly rare and hard to reproduce. Killing the offending ps process, which loops infinitely otherwise, unblocks the system and restores normal operation.
We now know a lot about this problem, but what is the root cause? The ps program causes 100% CPU load... What is this? We use QNX 6.6 and ps is supplied as a closed source binary. To understand this problem, we need to analyse the ps utility itself. We can already do that at the assembly level. The QNX Momentics IDE has an option "Attach to Remote Process via QConn" with which I can tap right into the running process. We see that it is stuck in a loop that calls devctl() over and over again. The return value of this devctl() is 3 which is ESRCH: No such process. This error comes straight from MsgSendv_r which returned -3. It documents that ESRCH means The server died while the calling thread was SEND-blocked or REPLY-blocked..
Okay, so, ps gets stuck in an infinite loop. Dare I say it: Do we have a ps bug on our hands? The QNX ecosystem is generally quite robust. In the past, it almost always ended up being my own mistake when I suspected problems in QNX and its utilities. But how can the infinite loop seen in live assembly debugging be explained with a user error of ps?
At this point, an intermezzo with some QNX history is in order. A bit more than a decade ago, the QNX source code was available to the public. Back then, QNX had a vibrant open source community. People would experiment with the kernel, write various useful utilities and help each other in forums. QNX even had a fully featured Desktop GUI, ran Firefox and was self-hosting, so you could develop for QNX right on QNX itself with full IDE and compiler support. It was beautiful. Then QNX was bought, source code access was revoked and the community largely withered away. Questions were increasingly asked via private support tickets directly to QNX, locked away from the public. QNX know-how becomes harder and harder to acquire, open source software for modern QNX releases is essentially non-existent and the driver situation is a catastrophe. The QNX kernel is the most beautiful and interesting kernel I have ever had the pleasure of working with, but it lies in the shackles of corporate ownership.
Back to the bug. So there is old QNX source code lying around. Do you think anyone has modified the source code of the ps utility throughout the last 15 years? Me neither! Let's dive right into the old code.
The old ps utility compiles for QNX 6.6 on the first try. Nice! It works just like the closed source binary we have. I install my newly compiled ps, write some software to automatically test reboots in a loop overnight and am able to reproduce the problem with this custom ps binary. Perfect! Now we can use the "Attach to Remote Process via QConn" feature again, but this time we have the source code of our ps. I already read the source code of the old ps before I did all of this, and I already had my suspicions as to which devctl() call was being repeated endlessly in the loop, so it comes as no surprise when the debugger points me to the following line:
if (devctl (fd, DCMD_PROC_TIDSTATUS, &tinfo, sizeof (tinfo), 0) == EOK)
The root cause of the bug is the following. For every process in the /proc directory, ps opens a file descriptor to this process' address space (as) file to read the process information to be displayed. For each process, it loops through all the threads of this process, and the bug is that this loop has insufficient termination criteria (in other words, in some cases, it loops infinitely). The problem occurs when the process whose threads we want to inspect terminates right before ps enters this loop. In that case, the devctl() call fails and as you can see in the following simplified snippet, it will never terminate because the if-clause is never entered.
while (1)
{
if (devctl (fd, DCMD_PROC_TIDSTATUS, &tinfo, sizeof (tinfo), 0) == EOK)
{
//[...]
tcount++;
// stop when we have gone through each thread, or when
// the user only want process info
if ((usingThreads == 0) || (tcount == info.num_threads))
break;
}
tinfo.tid++;
}
I also verify this hypothesis by halting the ps process in the debugger, killing the process whose threads we are about to inspect and resuming ps and it hangs in precisely the same way. This is what it looks like in the QNX Momentics IDE:
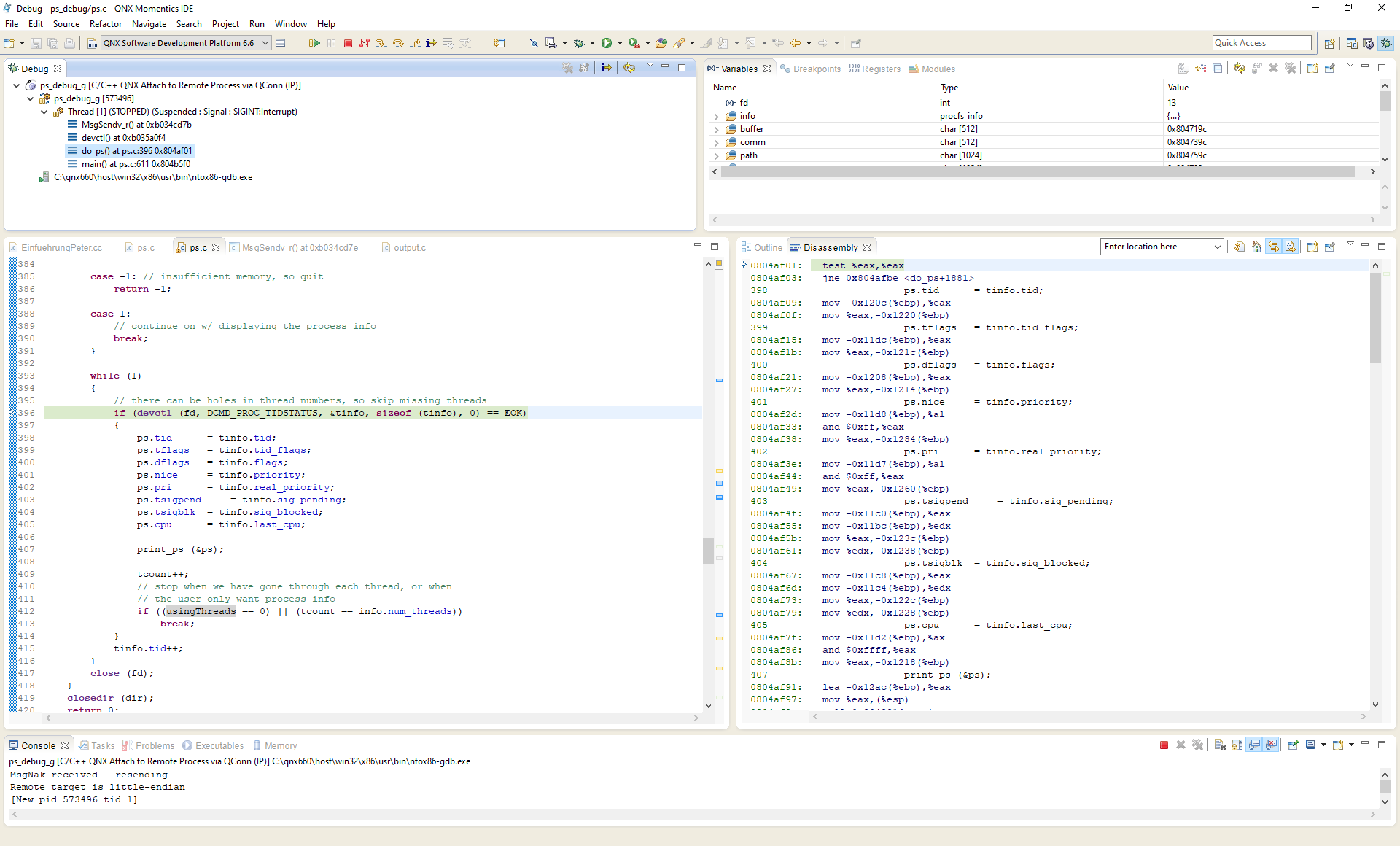
After this analysis, I'm quite sure that this 15 years old bug is still alive and well in our closed source binary.
Why did this problem suddenly appear in our firmware? We can only speculate, it must have been changes in the scheduling order or timing at boot time. The bug is a race condition, so it can rear its ugly head whenever it wants. The affected code was old and deployed in production for many years.
How did I fix it? I briefly considered shipping our own ps utility, but I was still unsure about other bugs that might potentially be fixed in the latest closed source binary, those fixes would be lost again if I revert to the old open source version. At the end of the day, I decided to comb through our code base and just eliminate the usage of ps in non-interactive code, there weren't that many instances. Our ps utility remains buggy as it is, but it's pretty much impossible to reproduce this bug in an interactive terminal, and our firmware no longer uses it. Needless to say, this particular update problem never occurred again after that.
Does the ps bug still exist in QNX ecosystems more recent than QNX 6.6? Most likely, yes. If it was open source, I would fix it and send a pull request. Because it's not, they have to deal with the issue themselves. Maybe in a decade, an unfortunate soul runs into this bug again. Let's hope this blog post will save them some trouble.
What do we learn?
- No matter how battle-tested and old the code and how reputable the distributor - the code contains bugs.
- Old bugs can manifest themselves seemingly out of nowhere, caused by subtle changes in timing or memory layout.
- Whenever the file system is involved, there is a significant danger that bugs are caused by race conditions.
- Closed source operating systems and ecosystems are a pain to debug. Even old open source releases help.
- Do not use interactive shell utilities in non-interactive code. Avoid
system()whenever possible. Not only is the performance terrible, it can give rise to bugs like this one. - Make sure your loops terminate. Bounded loop variants that increase or decrease strictly monotonically guarantee loop termination. Don't be too clever with loops!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK