

ReplacingMergeTree:实现Clickhouse数据更新
source link: https://my.oschina.net/u/4526289/blog/5294352
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

ReplacingMergeTree:实现Clickhouse数据更新 - 华为云开发者社区的个人空间 - OSCHINA - 中文开源技术交流社区
摘要:Clickhouse作为一个OLAP数据库,它对事务的支持非常有限。本文主要介绍通过ReplacingMergeTree来实现Clickhouse数据的更新、删除。
本文分享自华为云社区《Clickhouse如何实现数据更新》,作者: 小霸王。
Clickhouse作为一个OLAP数据库,它对事务的支持非常有限。Clickhouse提供了MUTATION操作(通过ALTER TABLE语句)来实现数据的更新、删除,但这是一种“较重”的操作,它与标准SQL语法中的UPDATE、DELETE不同,是异步执行的,对于批量数据不频繁的更新或删除比较有用,可参考https://altinity.com/blog/2018/10/16/updates-in-clickhouse。除了MUTATION操作,Clickhouse还可以通过CollapsingMergeTree、VersionedCollapsingMergeTree、ReplacingMergeTree结合具体业务数据结构来实现数据的更新、删除,这三种方式都通过INSERT语句插入最新的数据,新数据会“抵消”或“替换”掉老数据,但是“抵消”或“替换”都是发生在数据文件后台Merge时,也就是说,在Merge之前,新数据和老数据会同时存在。因此,我们需要在查询时做一些处理,避免查询到老数据。Clickhouse官方文档提供了使用CollapsingMergeTree、VersionedCollapsingMergeTree的指导,https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/collapsingmergetree/。相比于CollapsingMergeTree、VersionedCollapsingMergeTree需要标记位字段、版本字段,用ReplacingMergeTree来实现数据的更新删除会更加方便,这里着重介绍一下如何用ReplacingMergeTree来实现数据的更新删除。
我们假设一个需要频繁数据更新的场景,如某市用户用电量的统计,我们知道,用户的用电量每分每秒都有可能发生变化,所以会涉及到数据频繁的更新。首先,创建一张表来记录某市所有用户的用电量。
CREATE TABLE IF NOT EXISTS default.PowerConsumption_local ON CLUSTER default_cluster
(
User_ID UInt64 COMMENT '用户ID',
Record_Time DateTime DEFAULT toDateTime(0) COMMENT '电量记录时间',
District_Code UInt8 COMMENT '用户所在行政区编码',
Address String COMMENT '用户地址',
Power UInt64 COMMENT '用电量',
Deleted BOOLEAN DEFAULT 0 COMMENT '数据是否被删除'
)
ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/default.PowerConsumption_local/{shard}', '{replica}', Record_Time)
ORDER BY (User_ID, Address)
PARTITION BY District_Code;
CREATE TABLE default.PowerConsumption ON CLUSTER default_cluster AS default.PowerConsumption_local
ENGINE = Distributed(default_cluster, default, PowerConsumption_local, rand());PowerConsumption_local为本地表,PowerConsumption为对应的分布式表。其中PowerConsumption_local使用ReplicatedReplacingMergeTree表引擎,第三个参数‘Record_Time’表示相同主键的多条数据,只会保留Record_Time最大的一条,我们正是利用ReplacingMergeTree的这一特性来实现数据的更新删除。因此,在选择主键时,我们需要确保主键唯一。这里我们选择(User_ID, Address)来作为主键,因为用户ID加上用户的地址可以确定唯一的一个电表,不会出现第二个相同的电表,所以对于某个电表多条数据,只会保留电量记录时间最新的一条。
然后我们向表中插入10条数据:
INSERT INTO default.PowerConsumption VALUES (0, '2021-10-30 12:00:00', 3, 'Yanta', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (1, '2021-10-30 12:10:00', 2, 'Beilin', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (2, '2021-10-30 12:15:00', 1, 'Weiyang', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (3, '2021-10-30 12:18:00', 1, 'Gaoxin', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (4, '2021-10-30 12:23:00', 2, 'Qujiang', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (5, '2021-10-30 12:43:00', 3, 'Baqiao', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (6, '2021-10-30 12:45:00', 1, 'Lianhu', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (7, '2021-10-30 12:46:00', 3, 'Changan', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (8, '2021-10-30 12:55:00', 1, 'Qianhan', rand64() % 1000 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (9, '2021-10-30 12:57:00', 4, 'Fengdong', rand64() % 1000 + 1, 0);表中数据如图所示:
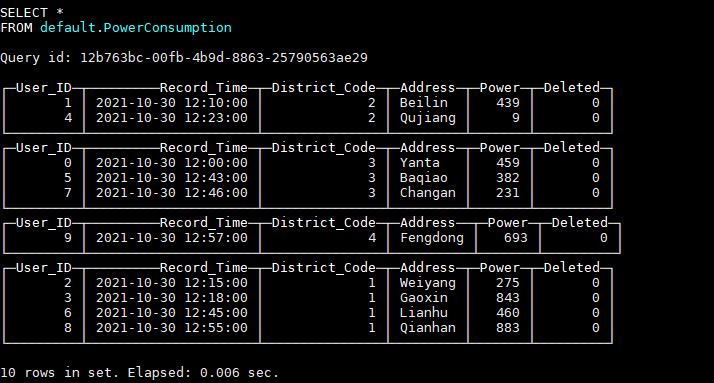
假如现在我们要行政区编码为1的所有用户数据都需要更新,我们插入最新的数据:
INSERT INTO default.PowerConsumption VALUES (2, now(), 1, 'Weiyang', rand64() % 100 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (3, now(), 1, 'Gaoxin', rand64() % 100 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (6, now(), 1, 'Lianhu', rand64() % 100 + 1, 0);
INSERT INTO default.PowerConsumption VALUES (8, now(), 1, 'Qianhan', rand64() % 100 + 1, 0);插入最新数据后,表中数据如图所示:
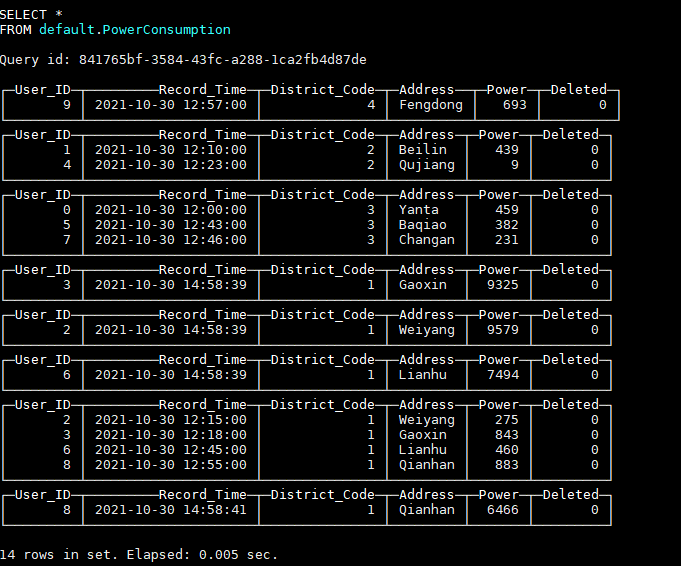
可以看到,此时新插入的数据与老数据同时存在于表中,因为后台数据文件还没有进行Merge,“替换”还没有发生,这时就需要对查询语句做一些处理来过滤掉老数据,函数argMax(a, b)可以按照b的最大值取a的值,所以通过如下查询语句就可以只获取到最新数据:
SELECT
User_ID,
max(Record_Time) AS R_Time,
District_Code,
Address,
argMax(Power, Record_Time) AS Power,
argMax(Deleted, Record_Time) AS Deleted
FROM default.PowerConsumption
GROUP BY
User_ID,
Address,
District_Code
HAVING Deleted = 0;查询结果如下图:
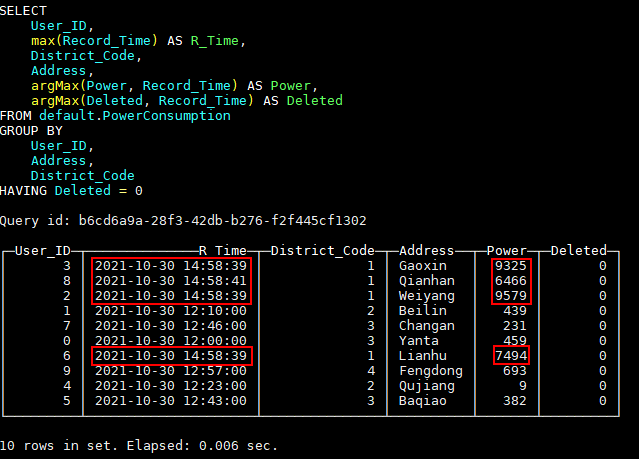
为了更方便我们查询,这里可以创建一个视图:
CREATE VIEW PowerConsumption_view ON CLUSTER default_cluster AS
SELECT
User_ID,
max(Record_Time) AS R_Time,
District_Code,
Address,
argMax(Power, Record_Time) AS Power,
argMax(Deleted, Record_Time) AS Deleted
FROM default.PowerConsumption
GROUP BY
User_ID,
Address,
District_Code
HAVING Deleted = 0;通过该视图,可以查询到最新的数据:
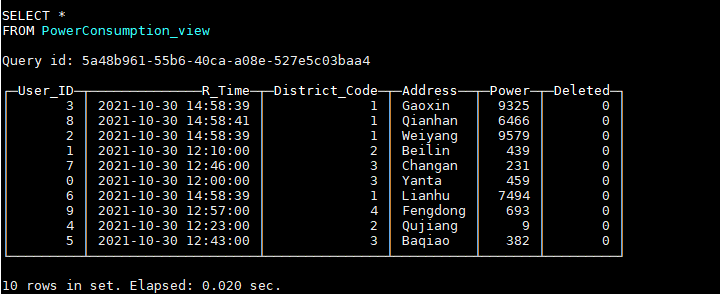
假如现在我们又需要删除用户ID为0的数据,我们需要插入一条User_ID字段为0,Deleted字段为1的数据:
INSERT INTO default.PowerConsumption VALUES (0, now(), 3, 'Yanta', null, 1);查询视图,发现User_ID为0的数据已经查询不到了:
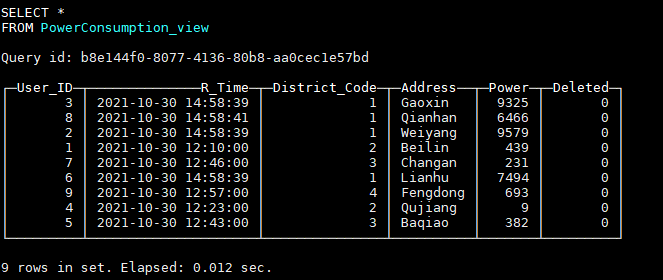
通过如上方法,我们可以实现Clickhouse数据的更新、删除,就好像在使用OLTP数据库一样,但我们应该清楚,实际上老数据真正的删除是在数据文件Merge时发生的,只有在Merge后,老数据才会真正物理意义上的删除掉。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK