

Harbour.Space Scholarship Contest 2021-2022 (Div. 1 + Div. 2) Editorial
source link: http://codeforces.com/blog/entry/93105
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Hope you all enjoyed the problemset! Editorials to problems H and I are not ready yet, we will add them as soon as possible. We apologize for weak pretests and easy problems for top participants.
By the way, solution authors did not necessarily prepare the problems. The solutions were chosen at random.
UPD. Editorials for H and I are ready! Wish you all productive upsolving and high ratings!
Idea: bthero Preparation: kefaa2
Idea: Errichto Preparation: Will not be revealed for now because we care for his/their safety.
Idea: Errichto Preparation: BledDest
Idea: Adel_SaadEddin, Zaher Preparation: Will not be revealed for now because we care for his/their safety.
Idea: bthero, kefaa2 Preparation: BledDest
Idea: kefaa2, Errichto Preparation: bthero
Idea: Adel_SaadEddin, Zaher, Errichto Preparation: Errichto
Idea: kefaa2 Preparation: BledDest, marX, kefaa2
Idea: bthero, kefaa2, BledDest Preparation: BledDest, kefaa2
-
This is what you want with coffee in the morning.Big Thanks
-
The comment is hidden because of too negative feedback, click here to view it
-
As you can read in the main blog, um_nik was a tester. He has nothing to do with the editorial.
-
No offence, but I am curious: do you personally like problems B & C? It's very surprising to me that these are the best ideas an LGM, who's also involved in a number of CP activities, can come up with.
-
No worries, I'm happy to explain my/our reasoning.
I certainly like B & C more than problem A. In the discussion below some CF blogs, I've already argued that math puzzles aren't that good for easy problems. But yeah, you can also say that I'm getting out of shape and my taste is getting worse. I lost my hopes after feedback from my AGC 47.
I suggested three easy problems: something rejected as A, penalties without question marks as B, and Reverse String with as C or with as B. I would use those three in my round and I can defend that choice. In particular, I like Penalties most as it's a natural problem that I came up with during Euro Cup. "Given a binary string like 1011100000, say when the winner is already decided".
Reverse String was rejected because it would be adjacent to the similar-styled Backspace. Penalties were too easy for the second slot (or so we thought) so somebody suggested question marks. Sadly, that change modifies the problem from cute to artificial. Testers then provided feedback that the round is too difficult for beginners. To fit the slot between Digits Sum and Penalties, we used Reverse String with .
-
-
-
-
3 months ago, # |
what is the 85th token of 19th test case of problem D??
-
If t matches the first few characters of s, you need to judge whether the number of remaining characters of s is even. Only if the number is even can the match be true.
-
Can u give that testcase or something similar to that, I am facing trouble regarding that t-c 19 85-th token..
-
-
Can you told me why I am getting TLE on test 30 in Problem D? -_- I used binary search. Can it be a reason? Here is my solution :
-
na apu,,,,,..... nlogn is efficient......... but you declare vector odd[200010] which complexity is O(n),n=size......... total complexity will be O(n*q)......... then if q=100000, it will definitely fail..............
-
-
-
3 months ago, # |
Hey, I am an author of problem F. We actually did not intend any solutions to pass at the beginning.
The thing is, my Fenwick tree solution works in ~400 ms, but my segment tree solution works in ~2.5 s. Segment tree with pushes does not even pass the time limit because of a high constant factor. Also we had to care about Java solutions, so I decided to raise the TL from 3s to 4s, letting to pass.
I know I had to fix this problem in a more adequate way by experimenting with constraints. Will certainly do that in future rounds. Sorry about that.
-
I think you mean solutions, as I am not aware of any solution. The thing is, mine was nowhere close even with pragmas and the 64-bit compiler.
-
My passes pretty comfortably within the TL. Unfortunately, I was not able to debug this quickly enough during the contest.
-
My solution with a time complexity of passed all the pretests using and then passed all the system tests using .
Note: this is not a comment talking about creative solutions, but a comment talking about how to use some ordinary data structure to compensate stupidity, so please forgive me if this sounds not so inspiring...... QwQ
Just sharing some thoughts...... QwQ
If you use enumerate all of the possible results of , you will end up with a condition in which you need to maintain a sequence allowing you to perform to operations:
- Updating one single element in the sequence(we will simply call this "update").
- Query the sum of a continuous prefix of the sequence(we will simply call this "query").
And the length of the sequence is , the total number of "update"s is , while the total number of "query"s is .
You choose a power of near , in my case I chose , and divide the sequence into several blocks, each have a length of .
You maintain two sequences, and , in which means the sum of elements in the -th, -th, ......, and the -st block, while means the sum of elements in the -th position, -th position, -th position, ......, and the earliest position that still belongs in block .
It's not hard to see the answer to any queries to position is , meanwhile can be calculated quickly enough using the bitwise
>>operation.When an update occurs, if the update is a plus at position , you just enumerate all the blocks ,...... and add to the of those; and within block , you just enumerate all the positions and add to the of those.
This data structure handles each update in time, each query in time, or constant time, and it also has a pretty excellent constant factor.
My implementation(may be very ugly QAQ) is here: Submission #123330049 — Codeforces
Thank you very much for your time reading this! I really appreciate it.
-
It is amusing that this is kind of a "two-layer" segment tree, and if you change it into three layers, the time complexity handling updates will reduce to while not changing the time complexity of queries(since its adds up pieces of information instead of ).
That means that you can actually chose ANY constant number and make the time complexity — ......
But in practice I've only seen choosing and a large proportion of them ...... QwQ
-
Shouldn't the complexity be ?
-
-
-
3 months ago, # |
Regarding problem E, could someone elaborate on transforming a permutation into another one? Why does the provided algorithm work? Could you provide some online resource about this?
-
Suppose you have a connected component of size . It will surely be a cycle. You can easily show that this cycle can be fixed using swaps, but not less. In total this will sum up to operations.
Also you could try mixing elements between different cycles, but you will see it does not help either. This is not a formal proof, just a simple explanation built on pure intuition and logic.
3 months ago, # |
Alternate solution for B
Store all the substrings of the string in an unordered map with the string being the key and the value being a vector of ending indices of the substring (note that a single substring might exist multiple times). For the string , split it into two at every index and let's say we get string and , check if -
- and reverse() exist in the map
- ending position of one such = ending position of one such reverse() + 1
3 months ago, # |
F in chat for person who lost scholarship due to hacks
I used a sledgehammer to crack a nut. Used KMP algorithm in B.
My submission: 123364212
Works in probably.
-
Could U give a brief solution on your idea?
-
In short, I'm searching for all prefixes of and reverse of the remaining part in .
SpoilerEdit:
1. is the length of .
2. All searches are done in as the two substrings to be searched add up to a length .
3. -based indexing is used.
-
3 months ago, # |
Dear problem setters please attach images for better understanding of problems !
3 months ago, # |
My solution to H is different from the first one provided in the editorial, and the second one provided in the editorial is too vague, so I’ll describe mine here.
Alternate Solution for 1553H - XOR and Distance
3 months ago, # |
I think it should be in the editorial of C, instead of .
How to solve B in , I thought a lot but couldn't come up with a solution.
-
solution i think my dp solution is n2 .correct me if i am wrong.
-
123306389 my dfs solution is truly similar to yours.I think that the dp array in your solution isn't necessarry and it may not work because we keep going right and then keep going left.So we cannot get repetitive (i,j,flag),right? of course i think our solutions are O(n²) and it may work even faster in tests.
-
3 months ago, # |
TerriblePretestsForces
Preparation : will not be revealed for now cuz we care for their safety ...lol .. Btw fstforces
3 months ago, # |
Wow, problem B was really harder than many people thought.
-
Not so hard, as is really easy to think and code.
Many people thought they can work out ,but they failed. That's no need.
-
But why passes as it is operations but it should be maximum of around per second, right?
Edit — Found this
-
3 months ago, # |
I had totally ignored bound on m, got that cyclic swaps part during the contest, but screwed all the time by thinking about how can I optimize my solution. Now I have learned from this mistake to read questions carefully :)
3 months ago, # |
I think tests on H are weak. I passed them with solution with some stupid approaches + random, but after I looked at the tests I noticed that all big tests have all 1's as answers. Here is the solution that takes random pair i, j and calculates for all x and if n>200 writes all 1's.
3 months ago, # |
the pre testcases was weak and made a round not fair for some people i solved a b c d and hacked 6 subbmisions so i was in 1000 place but after main test found d get wrong answer and become in 2200 place it was big shock for me
3 months ago, # |
https://codeforces.com/contest/1553/submission/123309155 in this submission i used dp with size 600 but lenth of t maybe equal to 999 why it didnt get run run time error can any one answer me??
3 months ago, # |
Solution for B: suppose you're standing on the position . There are 4 cases:
you can go only to the right, so is a substring from .
you can go only left, so the reverse of is a substring from .
you can go right then left, then there are two cases:
either you go from index to index : then to index .
then you can divide that into an odd-length-palindrome prefix and some sector, so you take from the center of the palindrome till the end of . then reverse and check if that is a substring from .
or you go from index to index : then to index . then you can divide that into some sector an odd-length-palindrome suffix, so you take from the center of the palindrome till the beginning of . then reverse and check if that is a substring from .
If it doesn't belong to any of these options, then the answer is No.
complexity:
link for the submission:
https://codeforces.com/contest/1553/submission/123368933
3 months ago, # |
In problem E, can someone provide me a proof why for each cycle of size the minimum number of swaps is ? couldn't it be less than swap?
-
Proof works with induction.
The base case is that k==2, then one swap fixes both elements. Else k>2, and swapping two elements fixes at most one of them, leaving us with a cycle of size k-1. It is easy to see that swapping two elements without fixing one does not give a better solution.
3 months ago, # |
H can be implemented in a similar style to FFT/FWHT. I don't know if there is a way to interpret this in terms of polynomials.
The code is quite short (shortest submission at time of writing): 123356112. It uses time and memory.
3 months ago, # |
actually,i dont think that weak pretest make contest somehow worse.becouse it teach u to be more attentive and re-read code even if it got AC on pretest.And every solution tests on same set of pretests so every one is on equal terms.
3 months ago, # |
Why can not I see the tutorial of the problem D
-
Solution for D
The tutorial for D is most likely not written yet or its written and is undergoing some edits. Whatever the case, the tutorial is still not out and available yet.
-
why we have to move right to left ,i tried an approach where i am are moving from left to right and if difference between some part is even we can delete it
but it is giving wrong answer my code
can you please tell which case i am missing?
or can you tell me how i can think of approach of moving pointer from right to left?
-
You can just reverse strings right after reading them from the input and then do left to right processing in the rest of your code. That's what I did myself during the contest. If the standard C++ library doesn't offer a native way to reverse strings, then it makes sense to have such function somewhere in your collection of code templates.
The main idea is that in many cases it is possible to do some cheap pre-processing of the input data to make the problem easier. Sometimes it's sorting of the input data, sometimes it's reversing the order of elements, etc.
-
-
Why can not I see the tutorial of the problem D
My random guess is that maybe the official solution for D was not originally intended to be greedy?
I first tried to implement my solution as a recursive DP with a two-dimensional state array of 1-bit boolean states, but this is obviously not a good fit for the problem constraints and needed improvements. Still I used this code as a reference implementation to generate a lot of testcases. I thought that maybe a single-dimensional DP state array (storing something like the best index or whatever) could do the job. But then noticed that just a simple greedy modification doesn't seem to fail any of the generated testcases. This was a facepalm moment for me. Spent so much time on something that turned out to have just a greedy solution! The letter D was really deceiving. However observing many system tests failures and hacks after the contest made me change my mind to some extent. The time spent on thoroughly testing solutions locally was not a completely wasted effort after all.
I wake up and see result problem D Time limit on test 99 , very sad!!!!!!
-
I have the same problem as you. Have you found where the wrong is? Tell me about it, please.
3 months ago, # |
hello, can you tell me the logic of penalty and why in last test case the answer is 9. It would be helpful if you give me some competitive programming tips. thanks
-
Hello, which problem are you talking about here?
As for the penalty, For every submission you get a non-AC verdict on tc != 1 during the contest, you get a penalty of 10mins, that is your solution is considered to be 10mins late after the actual AC verdict.
3 months ago, # |
3 months ago, # |
An Easy to understand Recursive Solution of Problem B
bool got(string s, string t, int i, int j, bool goingRight) {
if (j == t.size()) return 1;
if (i < 0 || i == s.size()) return 0;
if (s[i] == t[j]) {
if (goingRight)
// then right and left both can be explored
return got(s, t, i + 1, j + 1, 1) || got(s, t, i - 1, j + 1, 0);
// otherwise you can go left only
return got(s, t, i - 1, j + 1, 0);
}
return 0;
}
void argon17()
{
string s, t;
cin >> s >> t;
for (int i = 0; i < s.size(); ++i) {
// try at every index
if (got(s, t, i, 0, 1)) {
cout << "YES\n";
return;
}
}
cout << "NO\n";
}3 months ago, # |
If you have noticed in editorial or not but I found this funny :- Preparation: Will not be revealed for now because we care for his/their safety. :)
When I tried to see the tutorial of problem D, I saw "Tutorial is not available". However, someone has asked a problem about the problem D's tutorial, so if anyone can tell me what's wrong?
3 months ago, # |
I tried solving B using two pointers, getting WA on TC 14. Can anyone point out what's wrong? 123384175
In D,many codes failed for test 19 ,you guys just have looked the things from back like say you have two strings str1 abd str2 with length n and m respectively. All you need to do is keep a pointer(j) for str2 starting from m-1 coming back to 0 and start iterating for str1 from n-1 (i) if you find such i such that str1[i]=str2[j] and elements which didinot match their count is even then just decrement j and iterate from i-1 .No edge case to be handled in it. You can see my submission,its simple to understand.
-
A very simple test for D would be the following:
babcde bab NOIt is no, because whatever you do, you cannot delete your remaining odd number of symbols(in this case ) without affecting the other letters, simply because not adding another two symbols requires two(duh), and an odd number is obviously not a multiple of two.
That's the reason why solutions that worked from 1 to n failed, but those working from n to 1 passed. You can delete as many symbols from the beginning as you like, but this doesn't work for the end, you need to check whether the length from the position of your last taken character till the end of array is an even number. Only then it is possible.
3 months ago, # |
Can anybody help me calculate the time complexity of my solution to B? I think it's O(n^4), but it passed the system test. Code here
Oops, sorry about that!! Thanks to Nezzar and Rossoneri_Forever!!
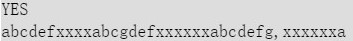
I have easier solution for problem D , if needed I will explain the code as well
int t ;
cin >> t ;
while( t -- ){
string s ;
string t ;
cin >> s >> t ;
int indx = s.size() - 1 ;
int test = 1 ;
string sk ;
for( int j = t.size() - 1 ; j >= 0 ; j -- ){
for( int i = indx ; i >= 0 ; i -- ){
if( s[ i ] == t[ j ] && ( indx - i ) % 2 == 0 ){
sk = sk + s[ i ] ;
indx = i - 1 ;
break ;
}
}
}
reverse( sk.begin() , sk.end() ) ;
//cout << sk << endl ;
if( sk == t ) cout << "YES\n" ;
else cout << "NO\n" ;
}3 months ago, # |
Great contest from which I learned a lot
3 months ago, # |
Because I have missed this multiple times in the past and I missed it in E again. So, as a reminder to myself and also for it may help others. These are two other problems which use Constraint Exploitation.
If you know of more such Problems, it would be nice if you could comment them down here.
3 months ago, # |
For Problem B, just enumerate all possible turing point (where you change direction), then you will get strings, which are s. Use KMP to query whether string is a substring of them, which costs .
Since first step cost , all the problem can be solved in
Code is here: https://codeforces.com/contest/1553/submission/123304298
3 months ago, # |
For problem A, if we take n=100 then the possible interesting numbers are 9,18,27,36,45,54,63,72,81,90,99 so there are total of 11 interesting numbers but according to the solution given above the answer would be 10
Can someone explain this anomaly?
Thanks in advance!!
-
For n=100, the possible interesting numbers are actually 9,19,29,39,49,59,69,79,89,99, which results in the answer becoming 10. other than 9,99 none of the numbers you mentioned are interesting, for example 18 : sum of digits is 9 18+1 = 19 : sum of digits is 10 which violates that S(19) < S(18) and therefore is not an interesting number. Similarly for the other numbers you mentioned. Hope this helped!
Deleted. 1001 way to overcomplicate your solution, lol.
3 months ago, # |
"Preparation: Will not be revealed for now because we care for his/their safety."
3 months ago, # |
Can someone provide tutorial for Um_nik solution of problem D. It would be really helpful.
Thanks in advanced :)
-
We first observe that if we type backspace, 2 characters in the origin text will be deleted. If the difference of the lengths between the origin text and the expected text is odd, then we must delete at least one character at the beginning of the origin text (which is what this
int p = (n - m) & 1;andfor (int i = p;...)does). Then, if the character at s[i] == t[q], we can go and check the next. If not, then we must delete this mismatch. At mentioned at the beginning, we have to delete the both characters starting from the mismatch, which is what the variable k does. Now, at the end, if the index q == the length of expected text m, we have found a way. Otherwise, we cannot transform the origin text to the expected.And just saw the official editorial is also avaliable now.
3 months ago, # |
in E's tutorial, what does — n/(n — 2n/3) signifies. I count cnt > n — 2m = n/3 why only 3 such counts are possible??
-
If the sum of many numbers is n, only three of them can be greater than n/3.
-
Thanks, I will read tutorial again, but can you explain why these 3 value of k are turned out to be only 0, 1, 2, 3?
-
I don't understand your question. Are you asking about some particular test? You might want to watch the video explanation too, it's in the first comment below the blog.
-
I got the solution completely, thank you so much, man...I don't know whether it will benefit me in the future or not to get problems solved using editorials and looking at other's code.
-
-
-
Why are they not revealing who prepared certain questions? What security concerns are they worried about? Have there been any past incidents?
3 months ago, # |
Despite several comments mentioning KMP/Z-function as applicable to problem B, I don't see any mentioning that it can actually be solved in linear time with that tool.
The basic idea is that the 'turning point' where the chip goes from moving right in to moving left must happen in the middle of a palindromic suffix or prefix of with some odd length . The substring of visited by the chip in this case is then either the substring of without its last characters (for palindromic suffixes) or the reversal of the substring of without its first characters (for palindromic prefixes).
In either case, it is clearly optimal to take as large as possible, i.e. use the longest odd-length palindromic prefix or likewise suffix of . These can easily be found in with KMP/Z-function, and then the problem is reduced to testing for the presence of either of two substrings.
3 months ago, # |
I felt like sharing my solution for F.
The basic idea of using the identity and grouping queries by the same values of is the same as the tutorial. What is different is that when we are checking the -th element we separate in two cases (1) and (2) .
We also have an array of size which is updated with the value of for all on each .
To calculate the sum of for : If (1) , we just iterate over all (as simple optimization, not really needed), and if (2) , we iterate over values of , of which there are at most .
To calculate the sum of for : If (1) , we get the value from array , and if (2) we query over at most ranges and sum.
So far, it is not exactly clear how to avoid either having queries or updates. What we do now is to separate the array in groups and update all auxiliary arrays only once for each group. The queries only account for the values of the previous groups, which means that the values missing are of , for pairs that are in the same group. These values can be recovered offline by checking pairs in each of the groups.
Cool thing about this strategy is that (to my knowledge) it still works if there are repeated values in A.
3 months ago, # |
For problem B, we can fix the segment [i,j] which goes from left to right, then calculate k, in that way we can fix the chip's route and then we can use hash to check. The time complexity is .
But I wonder whether we can solve it in an or quicker way.
3 months ago, # |
the solution of Problem F may be wrong because it won't print any integer on test 26. Please check your standard solution, thanks.
3 months ago, # |
What's wrong with test #26 of problem F? I don't know why the jury says the length of answer should be 0. I tried some AC codes, but they all get WA on test 26.
3 months ago, # |
Is there a problem with the 26th test point of question f? The code of the person I have used is still wrong. STD can't pass
3 months ago, # |
Unfortunately, the testing on test 26 of problem F was malfunctioning for the last several hours (I don't know the exact reason, probably something with Codeforces cache). The problem is fixed by now, all submissions that failed test 26 will be rejudged in a few minutes.
3 months ago, # |
Can someone please tell me why the answer to
cabad
cabac
should be YES for problem B ? (Test case 14).
TIA
3 months ago, # |
In problem E I think you mean the sum of cnt[k]= n, not n! This is why mathematicians shouldn't get overly excited (:
3 months ago, # |
Has anyone tried to solve problem D using regex?
It's a pretty straightforward solution with regex but I'm getting TLE with Java/Python and I'm unable to use regex in C++
2 months ago, # |
Can anyone told me why I am getting TLE on test 30 in Problem D? -_- I used binary search. Can it be a reason? Here is my solution :
2 months ago, # |
Can anyone provide me with the testcase 7 for problem D.
7 weeks ago, # |
Can we use submask enumeration technique to generate all possibilities for problem C?
3 weeks ago, # |
Will preparation for B and D ever be revealed?
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK