

JAVA 线上故障排查思路,从 CPU、磁盘、内存、网络到GC
source link: https://blog.csdn.net/u011783999/article/details/120997453
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

线上故障主要会包括cpu、磁盘、内存以及网络问题,而大多数故障可能会包含不止一个层面的问题,所以进行排查时候尽量四个方面依次排查一遍。同时例如jstack、jmap等工具也是不被局限在一个方面的问题的,基本上出问题就是df、free、top 三连,然后依次jstack、jmap伺候,具体问题具体分析即可。
一 、cpu使用情况
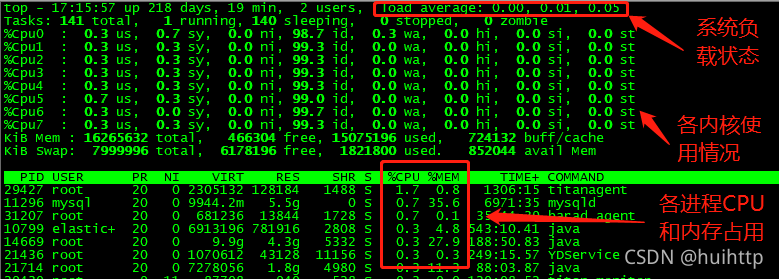
1. top查看总体的系统硬件使用情况
[root@VM_132_3_centos temp]# top
- load average 查看一分钟 十分钟 半个小时内的平均负载状态
- 多次按键盘1 可查看每个CPU内核的使用情况
- 各个进程的内存和CPU使用情况
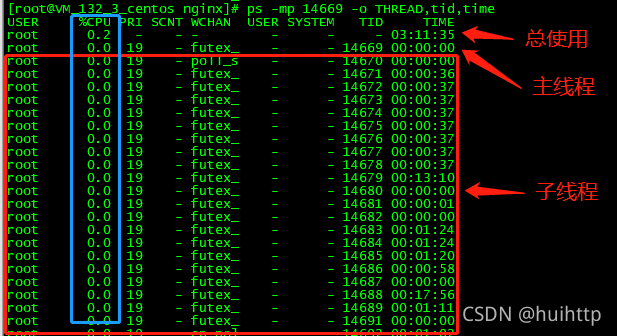
ps -mp PID -o THREAD,tid,time 查看这个进程的具体线程的使用cpu情况
- m 显示所有的线程
- p pid 进程使用cpu的时间
- 0 该参数后是用户自定义格式
[root@VM_132_3_centos nginx]# ps -mp 14669 -o THREAD,tid,time
USER %CPU PRI SCNT WCHAN USER SYSTEM TID TIME
root 0.2 - - - - - - 03:11:33
root 0.0 19 - futex_ - - 14669 00:00:00
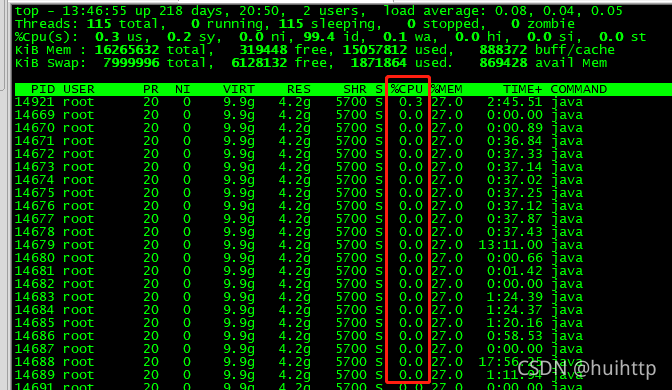
当然也可以用 top -H -p pid来找到cpu使用率比较高的一些线程
[root@VM_132_3_centos nginx]# top -H -p 14669
printf ‘%x\n’ pid 然后将占用最高的pid转换为16进制得到nid
[root@VM_132_3_centos nginx]# printf "%x\n" 14818

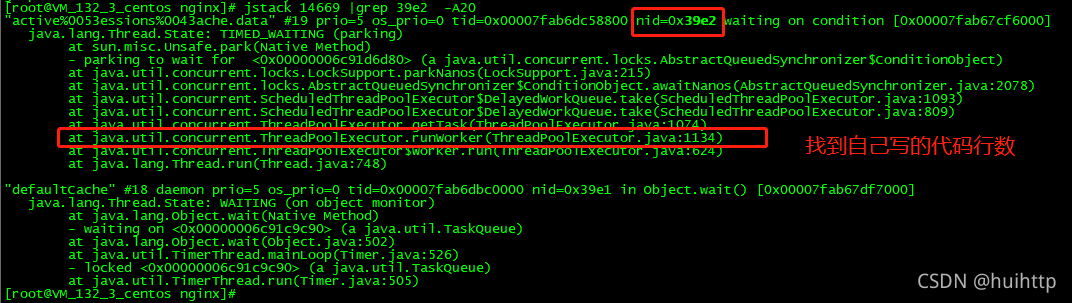
接着直接在jstack中找到相应的堆栈信息jstack pid |grep ‘nid’ -A50,找到自己写的代码行数,就定位到了出问题的代码位置
- pid 进程id
- nid 线程id 小写的16进制编号
- A50 查看匹配到行后的50行 或者用C20查看前后20行
[root@VM_132_3_centos nginx]# jstack 14669 |grep 39e2
2. vmstat 查看cpu
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数单位是秒,第二个参数是采样的次数
[root@VM_132_3_centos temp]# vmstat -n 2 3

- 参数解释
[1]. procs
– r: 运行和等待CPU时间片的进程数,原则上1核的CPU的运行队列不要超过2,整个系统的运行队列不能超过总核数的2倍,
否则代表系统压力过大
– b: 等待资源的进程数,比如正在等待磁盘I/0、网络I/0等。
[2]. cpu
– us: 用户进程消耗CPU时间百分比,us值高,用户进程消耗CPU时间多,如果长期大于50%,优化程序;
– sy:内核进程消耗的CPU时间百分比;
– us + sy:参考值为80%,如果us + sy大于80%,说明可能存在CPU不足;
– id:处于空闲的CPU百分比.;
– wa:系统等待IO的CPU时间百分比;
– st:来自于一个虚拟机偷取的CPU时间的百分比。
-[3]. system
– cs(context switch):一列则代表了上下文切换的次数
3. jstat分析频繁gc
当然我们还是会使用jstack来分析问题,但有时候我们可以先确定下gc是不是太频繁,使用jstat -gc pid 1000命令来对gc分代变化情况进行观察,1000表示采样间隔(ms),S0C/S1C、S0U/S1U、EC/EU、OC/OU、MC/MU分别代表两个Survivor区、Eden区、老年代、元数据区的容量和使用量。YGC/YGT、FGC/FGCT、GCT则代表YoungGc、FullGc的耗时和次数以及总耗时。如果看到gc比较频繁,再针对gc方面做进一步分析。
二、 内存使用情况
1. free 查看内存使用情况
[root@VM_132_3_centos nginx]# free -m

2 .使用JMAP定位代码内存泄漏
上述关于OOM和StackOverflow的代码排查方面,我们一般使用JMAPjmap -dump:format=b,file=filename pid来导出dump文件

通过mat(Eclipse Memory Analysis Tools)导入dump文件进行分析,内存泄漏问题一般我们直接选Leak Suspects即可,mat给出了内存泄漏的建议。另外也可以选择Top Consumers来查看最大对象报告。和线程相关的问题可以选择thread overview进行分析。除此之外就是选择Histogram类概览来自己慢慢分析,大家可以搜搜mat的相关教程。

日常开发中,代码产生内存泄漏是比较常见的事,并且比较隐蔽,需要开发者更加关注细节。比如说每次请求都new对象,导致大量重复创建对象;进行文件流操作但未正确关闭;手动不当触发gc;ByteBuffer缓存分配不合理等都会造成代码OOM。
三、 硬盘空间使用情况
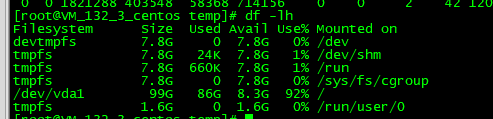
1. df -lh 查看磁盘的使用情况
[root@VM_132_3_centos temp]# df -lh
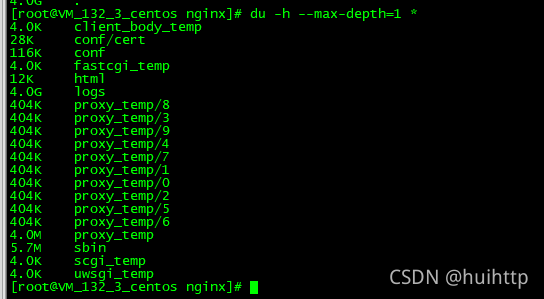
2. du -h --max-depth=1 查看当前目录中文件和文件夹的大小
[root@VM_132_3_centos nginx]# du -h --max-depth=1
3.iostat 查看磁盘io情况
最后一列%util可以看到每块磁盘写入的程度,而rrqpm/s以及wrqm/s分别表示读写速度,一般就能帮助定位到具体哪块磁盘出现问题了。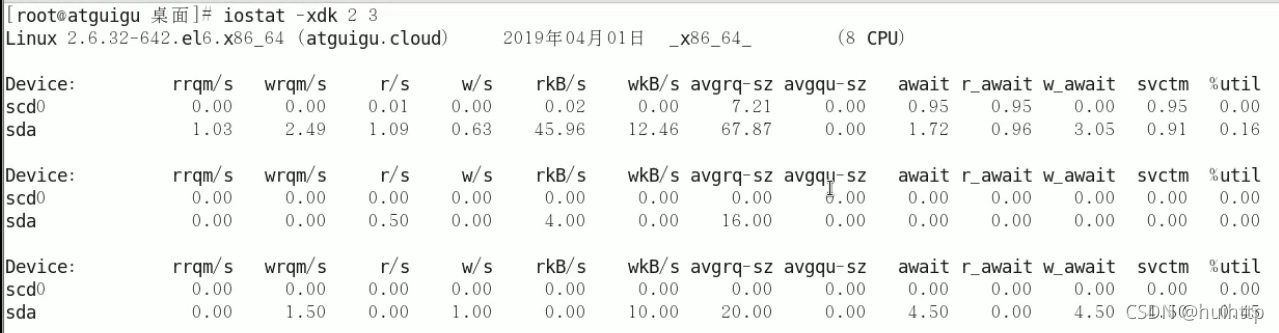
磁盘块设备分布
-
rkB/s每秒读取数据量kB;
-
wkB/s每秒写入数据量kB;
-
svctm I/O请求的平均服务时间,单位毫秒;
-
await I/O请求的平均等待时间,单位毫秒;值越小,性能越好;
-
util一秒中有百分几的时间用于I/O操作。接近100%时,表示磁盘带宽跑满,需要优化程序或者增加磁盘;
4. lsof -p pid查看文件读取情况
输出各列信息的意义如下:
COMMAND: 进程的名称
PID: 进程标识符
USER: 进程所有者
FD: 文件描述符,应用程序通过文件描述符识别该文件。每个进程都有自己的文件描述符表,因此FD可能会重名
TYPE: 文件类型
DEVICE: 指定磁盘的名称
SIZE: 文件的大小
NODE: 索引节点(文件在磁盘上的标识)
NAME: 打开文件的确切名称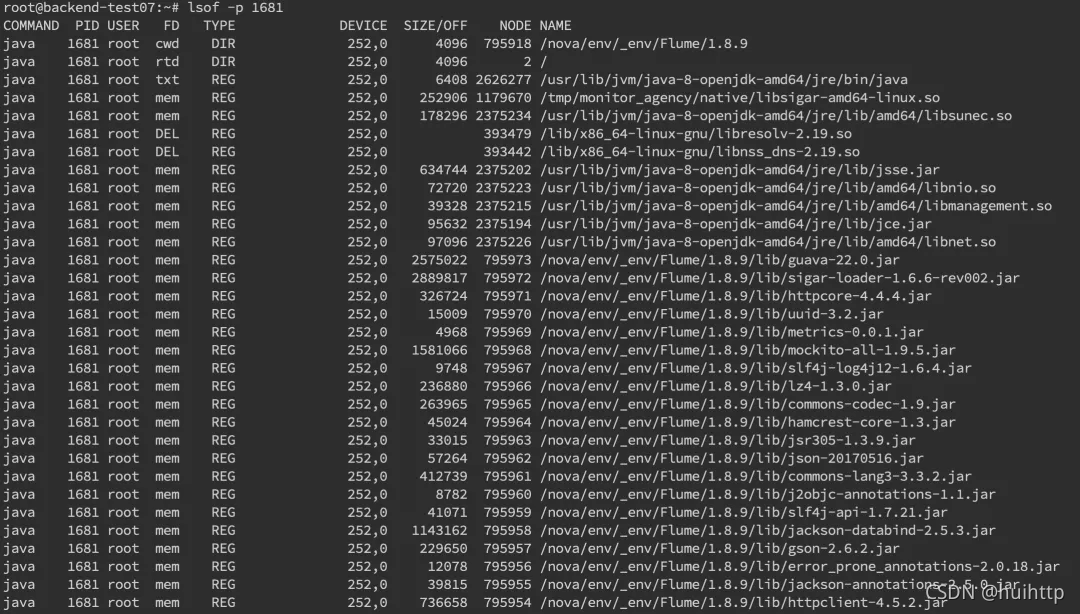
四、网络使用情况
1. netstat 查看tcp等连接情况
tcp队列溢出
netstat命令,执行netstat -s | egrep “listen|LISTEN”

如上图所示,overflowed表示全连接队列溢出的次数,sockets dropped表示半连接队列溢出的次数。
查看各状态的连接数量 netstat -n | awk ‘/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}’
[root@VM_132_3_centos nginx]# netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'

2. telnet查看端口是否连通
出现下面这个connected就是说明端口是通的
[root@VM_132_3_centos nginx]# telnet www.baidu.com 80

3. ifstat 查看网络io情况
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK