

JS 强制转 Number 的方法研究
source link: https://www.clloz.com/programming/front-end/js/2021/03/17/js-convert-number-ways/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

JS 强制转 Number 的方法研究
我在 深入Javascript类型转换 一文中从标准的角度对 JavaScript 中的类型转换的部分内容进行解读,主要是 Number,String 和 Boolean 这三个日常经常遇到的类型。昨天在阅读 lodash 的 slice 源码看到用无符号右移 start >>> 0 来确保 start 是一个 Number 类型的正整数。在 JavaScript设计模式与开发实践 中也看到了 +new Date 这样转换日期毫秒数的。我日常转换日期毫秒数都是用的 Date.prototype.getTime() 方法,强制转换数字我经常使用 Number() 构造器。在经过一番搜索之后发现很多文章说 Number() 是效率最低的一种方式,于是我决定自己对强制转换为 Number 类型的多种方法进行一下探究。
一元操作符
一元操作符有 ++, --, +, -, ~, !,我在 深入Javascript类型转换 中已经写过,除了 !,其他一元操作符都是会将类型转换为 Number 类型,MDN 中也推荐用一元 + 来讲其他类型转为 Number:一元正号是转换其他对象到数值的最快方法,也是最推荐的做法,因为它不会对数值执行任何多余操作。它可以将字符串转换成整数和浮点数形式,也可以转换非字符串值 true,false 和 null。小数和十六进制格式字符串也可以转换成数值。负数形式字符串也可以转换成数值(对于十六进制不适用)。如果它不能解析一个值,则计算结果为 NaN。
对于 JavaScript 中的位运算不熟悉的同学可以先去看一看 JavaScript 中的按位操作符。JavaScript 中的按位操作符会将操作数转换成 32 位的二进制整数,所以也可以用来进行 Number 转换。但是需要注意的是 32 位有符号二进制整数所能表示的最大值为 $2^32 – 1$,即 4294967295,如果数字超过这个范围则会出错,超出 32 位的部分会直接被丢弃。所以我们使用连续的按位非 ~~,或者无符号右移 >>>,以及 |0 都要注意操作数的范围。比如上面说的用 +new Date 可以获得毫秒数,如果使用 >>> 将会得到错误结果。
const time = +new Date;
console.log(+new Date) // 1615946620311
const time_binary = time.toString(2);
console.log(time_binary, time_binary.length); // 10111100000111101111011001100010001011011 41
const time_bit = time >>> 0;
console.log(time_bit); // 1038988502
console.log(parseInt(`${time_binary}`.slice(8), 2)) // 1038988502
我们可以看到上面的代码 time 为当前时间毫秒数,是用 + 进行转换的,time_binary 是用 Number.prototype.toString 转换的二进制字符串,time_bit 则是用无符号右移获得的 Number。我们可以看到无符号右移只能保留低位的 32 位二进制,超出的高位都被丢弃。
关于 JavaScript 中的进制的一些细节参考我的另一篇文章 JS 中的数字进制
parseInt
parseInt 是一个内置的全局函数,也是我们使用频率比较高的一个方法,但是 parseInt 的机制还是比较复杂的,这里我来详细总结一下。
parseInt 的语法是 parseInt(string, radix),接受两个参数,第一个参数是一个字符串,如果不是字符串会强制转换为 String,字符串开头的空白符会被忽略。第二个参数为可选参数,表示字符串的基数,范围为 2-36。虽然看起来很简单,但是由于 JavaScript 中的类型转换规则比较复杂,所以第一个参数的 toString 会产生很多奇怪的结果。比如下面:
console.log(parseInt('012')) // 12
console.log(parseInt(012)) // 10
console.log(parseInt('012', 8)) // 10
console.log(parseInt(012, 8)) // 8
console.log(parseInt('0o12')) // 0
console.log(parseInt(0o12)) // 10
console.log(parseInt('0o12', 8)) // 0
console.log(parseInt(0o12, 8)) // 8
这里我选了八进制作为示例,注意八进制的两种表示方式 0 和 0o,前者是不推荐使用了,ES5 本身也是不支持八进制的,我们使用的 0 开头的八进制是浏览器厂商自己支持的,ES6 中则使用 0o 对八进制进行了支持。ECMAScript 5 规范也不允许 parseInt 函数的实现环境把以 0 字符开始的字符串作为八进制数值。所以我们在编码中尽量用复合标准的 0o,虽然 0 也能得到大部分浏览器的支持。
这里我们在说一下 radix 的规定,注意,radix 的默认值不是 10,如果 radix 是 undefined、0 或未指定的,JavaScript 会假定以下情况:
如果输入的 string 以 0x 或 0x 开头,那么 radix 被假定为 16,字符串的其余部分被当做十六进制数去解析。
如果输入的 string 以任何其他值开头, radix 是 10。
如果 radix 的范围超出 2-36,那么 parseInt 表达式直接返回 NaN
如果输入的 string 以 0 开头, radix 被假定为八进制或十进制。具体选择哪一个 radix 取决于实现。ECMAScript 5 规定了应该使用十进制,但不是所有的浏览器都支持。因此,在使用 parseInt 时,一定要指定一个 radix。
讲完了规则,我们一条一条来分析:parseInt('012') 的结果是 12,这是因为 chrome 对于 0 开头的字符串的 parseInt 实现遵循了 ES5 标准,即没有传入 radix 的时候,0 开头的字符串会被作为一个十进制数。
parseInt(012),这里我们直接传入了一个八进制数 012,即十进制的 10,我们看到结果成功返回了 10。我们分析一下过程,我们传入的是一个 Number,所以会先调用 012 .toString()(注意数字和小数点之间有空格,这是 JS 的一个 bug,否则 . 会被解释为一个小数点,而不是成员访问),012 被 toString 转为十进制的字符串 '10' (toString d的默认参数是 10),所以我们的该条表达式最后实际被转化为 parseInt('10'),自然能够得到 10。
parseInt('012', 8) 是一个推荐的标准写法,即我们传入一个个指定进制的字符串,同时传入该进制的基数,能够得到一个确定的正确结果,日常编码中我们应该采用这种写法,以免出现意想不到的结果。
parseInt(012, 8) 得到了一个让我们以外的结果 8,但其实结合 parseInt(012) 的分析过程我们可以发现这个语句被转换成了 parseInt('10', 8),这样得到 8 就不足为奇了。
后面四条语句我是使用的 ES6 标准的 0o 表示的八进制数,我们主要来看第一条和第三条表达式。parseInt('0o12') 和 parseInt('0o12', 8) 得到了两个相同的结果 0,这主要是因为这条规则
如果
parseInt遇到的字符不是指定radix参数中的数字,它将忽略该字符以及所有后续字符,并返回到该点为止已解析的整数值。parseInt将数字截断为整数值。 允许前导和尾随空格。如果第一个空白字符不能转换为数字则parseInt表达式返回NaN。
结合上面的 radix 的规则,我们可以得出结论,除了十六进制字符串能够被准确识别出 radix,其他字符串的 radix 都默认是 10,而且 parseInt 对字符串是否是数字不是做一个整体的判断,而是从低位开始解析,解析到不是数字的位置停止,并返回已经解析的结果。这就导致了像 123sdfds 这样的数字字符混合的字符串我们不能得到 NaN,这是我们使用 parseInt 需要注意的一个问题。MDN 上给出了一个严格解析函数来应对这个问题:
function filterInt(value) {
// 正则表达式判断是否只有正负号数字以及 Infinity,否则返回 NaN
if (/^[-+]?(\d+|Infinity)$/.test(value)) {
return Number(value)
} else {
return NaN
}
}
parseInt 可以识别 + 和 -。parseInt 不应用于科学计数法,类似 6.022e23 这样的数字,对于科学计数法应当使用 Math.floor。
parseFloat
parseFloat 和 parseInt 一样是个全局函数,不属于任何对象。它只接受一个 String 作为参数,如果参数不是 String,会强制转换为 String,开头的空白符会被忽略,解析规则如下:
- 如果
parseFloat在解析过程中遇到了正号+、负号-、数字、小数点、或者科学记数法中的指数(e或E)以外的字符,则它会忽略该字符以及之后的所有字符,返回当前已经解析到的浮点数。 - 第二个小数点的出现也会使解析停止(在这之前的字符都会被解析)。
- 参数首位和末位的空白符会被忽略。
- 如果参数字符串的第一个字符不能被解析成为数字,则
parseFloat返回NaN。 parseFloat也可以解析并返回Infinity。parseFloat解析BigInt为Numbers, 丢失精度。因为末位n字符被丢弃。
考虑使用 Number(value) 进行更严谨的解析,只要参数带有无效字符就会被转换为 NaN 。
Number
作为原始包装对象,使用 Number() 可以将参数转换为 Number,转换规则参考 类型转换细节
上面分析了这些方法的细节,那么这些方法的性能到底如何呢,是不是真的如有些文章说的 Number 的性能很差呢?我分别用 benchmarkjs 在本地的 node 环境中和 jsbench 上各跑了几次。benchmarkjs 的代码如下:
const Benchmark = require('benchmark');
const suite = new Benchmark.Suite();
suite
.add('parseInt', () => {
parseInt('4294967295');
})
.add('parseFloat', () => {
parseFloat('4294967295');
})
.add('unary', () => {
+'4294967295';
})
.add('bit', () => {
'4294967295' >>> 0;
})
.add('Number', () => {
Number('4294967295');
})
// add listeners
.on('cycle', function (event) {
console.log(String(event.target));
})
.on('complete', function () {
console.log('Fastest is ' + this.filter('fastest').map('name'));
})
// run async
.run({ async: true });
跑的结果如下:
parseInt x 8,844,909 ops/sec ±3.67% (86 runs sampled)
parseFloat x 12,166,845 ops/sec ±1.11% (91 runs sampled)
unary x 838,130,806 ops/sec ±0.92% (86 runs sampled)
bit x 839,113,877 ops/sec ±0.88% (89 runs sampled)
Number x 838,017,789 ops/sec ±0.96% (87 runs sampled)
Fastest is bit,unary,Number
jsbench 网站上的结果如下图
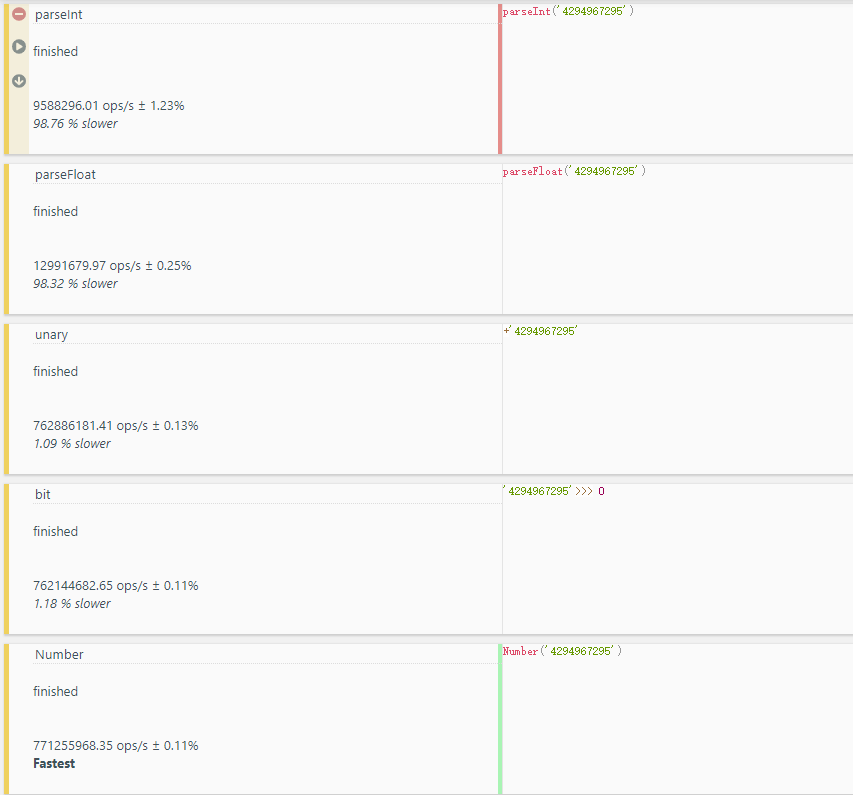
从两个结果上看我们可以看出一元操作符,位运算符和 Number 的性能是很接近的,而 parseInt 的性能则要差很多。而位操作符又有范围限制。所以最后的结论解释我们可以使用一元 + 或者 Number 都可以。
本文我们详细分析了几种将值转为 Number 的方法的细节,可能有错漏之处,欢迎指出。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK