

Fantastic ML Pipelines and Tips for Building Them
source link: https://dzone.com/articles/fantastic-ml-pipelines-and-how-to-build-them
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Fantastic ML Pipelines and Tips for Building Them
This article provides an overview of technical debts that we need to look out for in addition to building ML pipelines and discussing mitigation strategies.
Join the DZone community and get the full member experience.
Join For FreeA machine learning (ML) pipeline is an automated workflow that operates by enabling the transformation of data, funneling them through a model, and evaluating the outcome. In order to cater to these requirements, an ML pipeline consists of several steps such as training a model, model evaluation, visualization after post-processing, etc. Each step is crucial towards the success of the whole pipeline, not only for the short-term but also in the long run. In order to ensure the sustainability of a pipeline in the longer run, ML engineers and organizations need to account for several ML-specific risk factors in the system design. The authors from Google pinpoint risk factors such as boundary erosion, entanglement, hidden feedback loops, undeclared consumers, data dependencies, configuration issues, changes in the external world, and a variety of system-level anti-patterns [1]. In this article, we will be diving deep into the root causes of some of these risk factors.

Figure 1: Automated pipeline (source : 123.rf)
1. Boundary Erosion
If you are given an ML pipeline and if your data team approaches you with a change in the input feature such as increase/reduction in dimension, would you be able to ensure that it won't affect the entire pipeline? Mostly the answer would be no.
So where is the problem?
In traditional software engineering, it is very easy to create strong abstraction boundaries with the usage of encapsulation and modular design. This paves the way towards isolated changes and improvements. Unfortunately in ML systems, enforcement of such strict abstraction by intended behavior is nearly impossible as the real world doesn't fit into tidy encapsulation.
For example, it would be impossible to encapsulate the frequency sensitivity of a time series prediction, in an ML pipeline design.
Hence the boundary erosion significantly increases the technical debt of the end-to-end pipeline due to 3 main reasons: the system being interdependent (entanglement), models being dependent on previous models (correction cascades), and undeclared consumers.
As ML engineers who design data pipelines and automated systems, it is crucial for us to understand how each of the above-mentioned reasons originates, how they can be identified, and how they can be mitigated.
Let's dive right in!
Entanglement is inevitable in ML pipelines as the systems mix signals together. As ML systems work in a “change anything, change everything” (CACE) fashion, isolated improvements become impossible. Let's consider an example scenario, an ML system uses the following features as input to their pipeline.
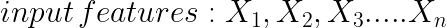
If the distribution of X1 changes, then the importance, weights, and use of the remaining features would also change. This would be the case of a new feature addition or deletion of a feature. The CACE applies not only to features but also to learning settings, sampling methods, data selection, etc. As a mitigation strategy, isolating the models and serving them as ensembles would work. A high-dimensional visualization tool will also be helpful to quickly see the effects across many dimensions and slicings.
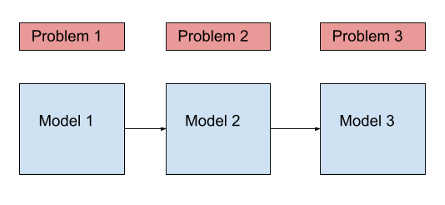
Figure 2: Model cascade
In situations where various new ML problems arise, similar to previously dealt ones, it is often tempting to create models which learn from the previous one, creating the problem of correction cascades. Though it's a faster way towards the solution, it creates an improvement deadlock down the line. Individual component level improvements become nearly impossible due to the dependency on the previous model. The cost-effective way to mitigate this would be to add new features to the existing model, enabling it to distinguish between the new cases or to accept the cost of creation for a completely new model for the new problem.
As some ML models are often left widely accessible, they could be consumed by other systems. Without access controls, these consumers become undeclared to the existing pipeline. Any future improvements which we may make to our pipeline would be detrimental to these undeclared consumers. The ideal mitigation strategy would be to have access restrictions or enable service level agreements to ensure that the consumers' systems do not fail due to improvements in ours.
2. Data Dependencies
Generally, identification of code level dependencies is very easy thanks to compilers and linkers. But the identification of data dependencies in ML pipelines is difficult. With the changes happening in dependency pipelines and decision makings in our pipeline, two technical depths pertaining to data, namely unstable data and underutilized data, are created.
Unstable data is when the input signal is changing qualitatively or quantitatively over time. This change could happen implicitly when the input is coming from another ML model/pipeline that is updated over time, or this change could happen explicitly as well when the ownership of the input signal is different from the model which consumes it. In such cases, any “improvements” to the input signal may have detrimental effects on the pipeline which consumes it. An ideal mitigation strategy would be to version the copies of a given signal. As an example, rather than changing the semantic mapping of worlds to change over time, when a new update happens, creating a new version would enable backtracking the source of the problem very easily.
Underutilization of data could also have catastrophic effects on an ML pipeline over time. Underutilization of data dependency could creep into a model in several ways:
- Legacy features: over time, a feature becomes redundant by new features
- Bundled features: “deadline” pressure causes a group of features to be bundled into a model by the ML engineer
- ε features: the temptation to add new features despite the model accuracy gain is small
- Correlated features: addition of highly correlated features into the model despite the causation being less
The above would lead to brittleness of the model in the real world and also when the real-world behavior changes. The ideal mitigation strategy would be to run “leave one feature out” evaluations very regularly, to remove redundant features. The implementation of an automatic dependency management system (as mentioned in McMahan et al., 2013) would ensure all dependencies have appropriate annotations. This would make migration and deletion a safer practice.
3. Feedback Loops
ML systems have a tendency to influence their own behavior if they update over time, hence it forms an analysis debt, making it hard to predict the pipeline/model’s behavior over time even before it is released. As these feedback loops may gradually happen over a long period of time, they will be more difficult to detect. In a general scenario, there could be two types of feedback: a direct one and an indirect one. The direct feedback could happen in bandit algorithms, especially where the model may directly influence its own training data. This would cause issues, as the algorithm now will not be able to scale well to the required action spaces of the real-world problem. One possible mitigation strategy would be to isolate certain parts of the data from being influenced by the model.
It is also possible to reduce some of the feedback issues by insertion of randomization [3]. An indirect feedback loop is also possible in the real world, although this would be a difficult case to spot. Consider the case of two stock market prediction models from two different investment companies: improvements/bugs could influence the bidding and buying behavior of the other.
4. ML System Anti-Patterns
Imagine yourself in an ML code review: too many experimental pathways, too many code blocks preventing you from understanding the bigger picture at a single glance. Is there a solution to overcome this situation? Glad you asked!
As ML systems are high debt design patterns, system-level anti-patterns [4] will surface. This needs to be refactored wherever possible. System-level anti-patterns in ML systems could surface in the following categories:
- Glue code: The usage of a generic library inhibits domain-specific advantages from being taken. Also, it requires massive amounts of support code written to get the data in and out of these packages. This could be easily mitigated if the packages are wrapped into common APIs, reducing the cost of changing packages.
- Pipeline jungle: As new signals are indented and embedded into the pipeline, the resulting system will often lead to many intermediary output files, resulting in a messy system. Anticipating future efforts needed for a pipeline would be an ideal mitigation strategy. Also, this often happens due to the roles of a researcher and engineer in an ivory tower setting.
- Dead experimental code paths: As experimental code paths accumulate in the pipeline over time, the backward compatibility drops. This also increases the cyclomatic complexity as testing all code paths becomes difficult. An ideal mitigation strategy would be to periodically re-examine each experimental branch and delete them.
- Common smells:
- Plain old data type smell: Rather than encoding rich information into plain data such as integer or float, wrapping everything through a class would result in better understanding. A prediction should know various pieces of information which produced it.
- Multiple language smell: The usage of multiple languages due to library convenience should be omitted, as this hinders ownership transfer and increases the code of effective testing.
- Prototype smell: Heavy reliability on a prototype environment makes the full-scale environment performance brittle. This also causes difficulty to change.
6. Configuration Debt
As ML systems grow, many branches would be added to a wide range of configuration options. i.e. which features to use, data selection criteria, pre-/post-processing techniques, etc. As a rule of thumb, the transition between various configurations should be simple. The following are principles of good configuration systems:
- It should be easy to specify configuration as a small change from the previous
- It should be hard to make manual errors, omissions
- Easy to visually see the configuration difference between the two models
- Automatic assertions to verify basic facts about the configuration, # features
- Possibility to detect unused/redundant setting
- Configuration should undergo a full code review
Conclusion
“With great power, comes great responsibility” is a statement that would appropriately summarize ML pipelines. Though it has become increasingly easy to create and deploy ML pipelines as ML engineers and researchers, it is very crucial to understand the hidden technical debts. Continuous sanity checks on data and better reproducibility have become part and parcel of an ML engineer’s job role. Organizations have a responsibility to assign appropriate resources by looking at business priorities and encouraging a culture where reduction in code complexity, stability improvements, and monitoring are treated as improvements of accuracy.
Paying down ML-related technical debts requires a significant commitment from both parties, which can only be achieved together as a team effort.
References
- Sculley, D.; Holt, G.; Golovin, D.; Davydov, E.; Phillips, T.; Ebner, D.; Chaudhary, V.; Young, M.; Crespo, J.-F. & Dennison, D. (2015), Hidden Technical Debt in Machine Learning Systems., in Corinna Cortes; Neil D. Lawrence; Daniel D. Lee; Masashi Sugiyama & Roman Garnett, ed., 'NIPS', pp. 2503-2511 .
- H. B. McMahan, G. Holt, D. Sculley, M. Young, D. Ebner, J. Grady, L. Nie, T. Phillips, E. Davydov,D. Golovin, S. Chikkerur, D. Liu, M. Wattenberg, A. M. Hrafnkelsson, T. Boulos, and J. Kubica. Ad click prediction: a view from the trenches. In The 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD 2013, Chicago, IL, USA, August 11-14, 2013, 2013.
- L. Bottou, J. Peters, J. Quiñonero Candela, D. X. Charles, D. M. Chickering, E. Portugaly, D. Ray, P. Simard, and E. Snelson. Counterfactual reasoning and learning systems: The example of computational advertising. Journal of Machine Learning Research, 14(Nov), 2013.
- W. J. Brown, H. W. McCormick, T. J. Mowbray, and R. C. Malveau. Antipatterns: refactoring software,architectures, and projects in crisis. 1998
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK