

如何克服 Apache Kafka中的数据顺序问题 - DATAVERSITY
source link: https://www.jdon.com/57390
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

通过了解 Apache Kafka 如何对数据进行排序,您可以确保您的数据或应用程序保持良好的工作状态。
尽管Apache Kafka已经赢得了作为功能强大的分布式流媒体平台的声誉,但在确保按您希望的顺序存储和检索数据方面,它还具有一些复杂性。
为了捕获流数据,Kafka 将记录发布到多个 Kafka消费者可以订阅和检索数据的主题、类别或提要名称。Kafka 集群为每个主题维护一个分区日志,来自同一个生产者的所有消息发送到同一个分区,并按照它们到达的顺序添加。通过这种方式,分区是结构化的提交日志,保存有序且不可变的记录序列。添加到分区的每条记录都分配了一个偏移量,一个唯一的顺序 ID。
在 Kafka 中按照你喜欢的顺序接收数据的挑战有一个相对简单的解决方案:分区保持严格的顺序,并且总是按照数据添加到分区的顺序将数据发送给消费者。但是,Kafka 不会维护跨多个分区的主题的总记录顺序。
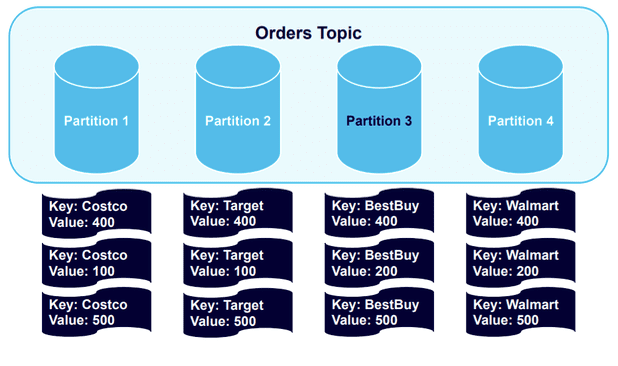
让我们使用一个”键key“的例子,它允许你向生产者记录添加键。我们将向一个有两个分区的Kafka主题发送四个包含键key的消息。
有四个不同的键——Costco、Walmart、Target 和 Best Buy,并在集群中散列并分布到分区中,
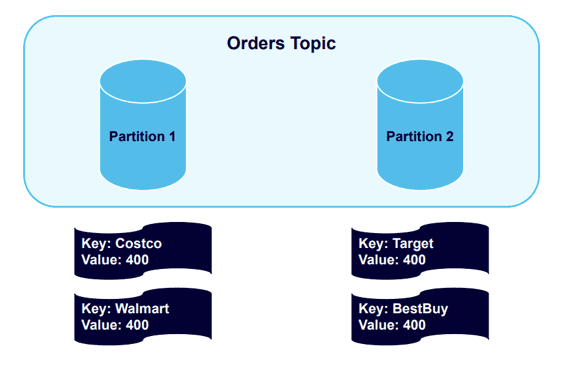
现在我们将再发送另外四条消息,Kafka 将向已经使用现有Key的分区发送消息:
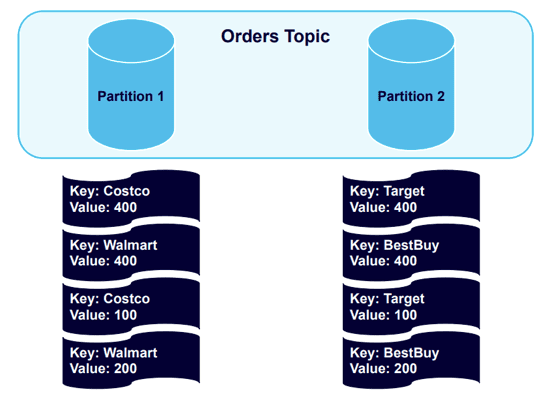
所有 Costco 或 Walmart 记录都在分区 1 中,所有 Target 或 Best Buy 记录都在分区 2 中。这些记录按它们发送到这些分区的顺序排列。
接下来,让我们看看如果向集群添加更多分区会发生什么,我们可能希望这样做以便以更健康的方式平衡数据。
添加新的一个分区后,我们将触发重新平衡事件:
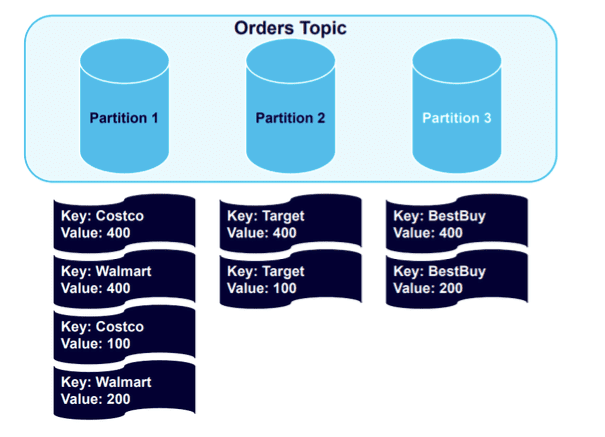
数据保持良好的键结构,所有 Best Buy 数据都平衡到分区 3。如果我们向主题添加另外四条消息,情况将保持不变:
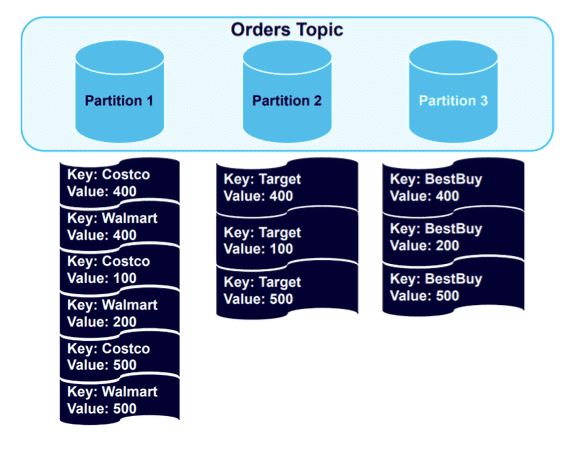
数据进入保存已建立key的分区。但是,因为一个分区保存的数据是其他分区的两倍,所以添加第四个分区并触发另一个重新平衡是合乎逻辑的:
结果是数据集的健康平衡。
确保数据始终按顺序发送
其他问题
还有许多其他问题可能导致数据在 Kafka 中无序到达,包括代理或客户端故障以及重新尝试发送数据产生的混乱。为了解决这些问题,让我们首先仔细看看 Kafka 生产者。
以下是显示 Kafka 生产者如何工作的高级概述:
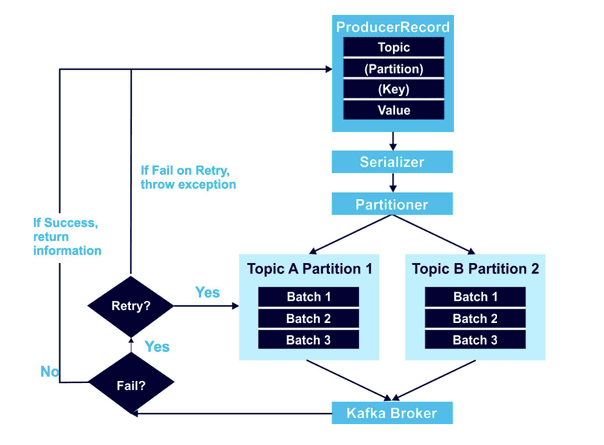
至少,ProducerRecord 对象包括要将数据发送到的主题和一个值。它还可以包括要使用的指定分区和Key。在上面的示例中,我建议您始终使用Key。如果不这样做,数据将循环分配到任何没有组织的分区。ProducerRecord 中的数据接下来使用 Serializer 进行编码,然后 Partitioner 算法决定数据的去向。
上图左侧概述的重试机制是一个经常发生数据顺序问题的区域。例如,假设您尝试向 Kafka 发送两条记录,但一条由于网络问题而失败,而另一条通过。当您尝试重新发送数据时,存在数据乱序的风险,因为您现在同时向 Kafka 发送两个请求。
您可以通过将 max.in.flight.requests.per.connection 设置为 1 来解决此问题。如果设置为多个(并且 retries 参数非零),则代理可能无法成功写入第一批消息同时写第二个,因为它也被允许在飞行中,然后成功重试第一批,将他们的顺序交换到你不想要的顺序。相比之下,将 max.in.flight.requests.per.connection 设置为 1 可确保这些请求按顺序依次发生。
在顺序至关重要的场景中,我建议将 in.flight.requests.per.session 设置为 1;这可确保在重试消息批处理时不会发送其他消息。然而,这种策略严重限制了生产者的吞吐量,只有在顺序必不可少的情况下才应该使用。将允许的重试设置为零似乎是一种可能的选择,但是,如果对系统可靠性的影响使其成为不可选项。
实现“恰好一次的消息传递”
Kafka 包括三种不同的消息传递方法,每种方法都有自己的保证行为:
- At-Once Message Delivery:此方法将传递一次消息批处理,或从不传递。这消除了重新发送相同消息的风险,但也允许它们丢失。
- At-Least-Once Message Delivery:此方法在消息传递之前不会停止。虽然传递总是成功并且没有消息丢失,但是它们可以被多次传递。
- Exactly-Once Message Delivery:这种方法保证所有消息的传递,并且每个消息只传递一次。虽然会发生失败和重试,但 Exactly-Once Message Delivery 会采取额外的步骤来确保单次成功传递。
显然,Exactly-Once Message Delivery 是保持数据顺序的理想选择。
将 Exactly-Once Message Delivery 付诸实践需要利用三个组件:幂等生产者、跨分区事务和事务消费者。
- 1) 幂等生产者
生产者幂等性可以导致消息在单个进程中持续存在,从而防止重试问题。激活幂等性会为每个 Kafka 消息添加一个生产者 ID (PID) 和一个序列 ID。当代理或客户端发生故障并尝试重试时,主题仅接受具有从未见过的生产者和序列 ID 的消息。代理进一步保证了幂等性,它自动对生产者发送的所有消息进行重复数据删除。
- 2)跨分区事务
事务可以确保每条消息只处理一次。这允许将选定的消息转换并原子地写入多个主题或分区,以及偏移量跟踪消耗的消息。
原子写入的状态由事务协调器和事务日志(在 Apache Kafka v0.11 中引入)维护。事务协调器类似于消费者组协调器:每个生产者都有一个分配的事务协调器,负责分配PID和管理事务。事务日志是所有事务的持久记录,充当事务协调器的状态存储。
- 3) 事务消费者
要强制事务消费者只读取已提交的数据,请将isolation.level 设置为read_committed(默认情况下,隔离级别为未提交读。)
使用Exactly-Once 消息传递的 Kafka 事务工作流的步骤
下图捕获了实现 Exactly-Once Message Delivery 所需的 Kafka 事务工作流步骤。
- 步骤 1 – initTransactions()向事务协调器注册一个事务transaction ID(一个唯一的持久性生产者 ID)。
- 第 2 步 - 协调器提高生产者 ID 的纪元(确保只有一个合法的生产者活动实例)。不再接受来自该 PID 先前实例的写入。
- 步骤 3 – 在向分区发送数据之前,生产者使用协调器添加一个新分区。
- 步骤 4 – 协调器将每个事务的状态存储在内存中并将其写入事务日志。
- 步骤 5 – 生产者将消息发送到分区。
- 步骤 6 – 生产者开始提交事务,使协调器启动其两阶段提交协议。
- 步骤 7 –(提交协议阶段 1)协调器通过更新事务日志来准备提交。
- 步骤 8 –(提交协议阶段 2)协调器将事务提交标记写入事务中涉及的主题分区。
- 步骤 9 – 协调器将事务标记为已提交。
- 第 10 步——“Exactly-Once Message Delivery”事务成功。
下面是这个过程的更多技术架构图:
通过了解 Apache Kafka 如何对数据进行排序并利用上述技术,您可以确保您的数据或应用程序保持良好的工作状态。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK