

Unity中Compute Shader的基础介绍与使用
source link: https://blog.uwa4d.com/archives/USparkle_ComputeShader2.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

前言
Compute Shader是如今比较流行的一种技术,例如之前的《天刀手游》,还有最近大火的《永劫无间》,在分享技术的时候都有提到它。
Unity官方对Compute Shader的介绍如下:https://docs.unity3d.com/Manual/class-ComputeShader.html
Compute Shader和其他Shader一样是运行在GPU上的,但是它是独立于渲染管线之外的。我们可以利用它实现大量且并行的GPGPU算法,用来加速我们的游戏。
在Unity中,我们在Project中右键,即可创建出一个Compute Shader文件:

生成的文件属于一种Asset文件,并且都是以 .compute作为文件后缀的。
我们来看下里面的默认内容:
#pragma kernel CSMain
RWTexture2D<float4> Result;
[numthreads(8,8,1)]
void CSMain (uint3 id : SV_DispatchThreadID)
{
Result[id.xy] = float4(id.x & id.y, (id.x & 15)/15.0, (id.y & 15)/15.0, 0.0);
}
本文的主要目的就是让和我一样的萌新能够看懂这区区几行代码的含义,学好了基础才能够看更牛的代码。
语言
Unity使用的是DirectX 11的HLSL语言,会被自动编译到所对应的平台。
kernel
然后我们来看看第一行:
#pragma kernel CSMain
CSMain其实就是一个函数,在代码后面可以看到,而kernel是内核的意思,这一行即把一个名为CSMain的函数声明为内核,或者称之为核函数。这个核函数就是最终会在GPU中被执行。
一个Compute Shader中至少要有一个kernel才能够被唤起。声明方法即为:
#pragma kernel functionName
我们也可用它在一个Compute Shader里声明多个内核,此外我们还可以再该指令后面定义一些预处理的宏命令,如下:
#pragma kernel KernelOne SOME_DEFINE DEFINE_WITH_VALUE=1337
#pragma kernel KernelTwo OTHER_DEFINE
我们不能把注释写在该命令后面,而应该换行写注释,例如下面写法会造成编译的报错:
#pragma kernel functionName // 一些注释
RWTexture2D
接着我们再来看看第二行:
RWTexture2D<float4> Result;
看着像是声明了一个和纹理有关的变量,具体来看一下这些关键字的含义。
RWTexture2D中,RW其实是Read和Write的意思,Texture2D就是二维纹理,因此它的意思就是一个可以被Compute Shader读写的二维纹理。
如果我们只想读不想写,那么可以使用Texture2D的类型。
我们知道纹理是由一个个像素组成的,每个像素都有它的下标,因此我们就可以通过像素的下标来访问它们,例如:Result[uint2(0,0)]。
同样的每个像素会有它的一个对应值,也就是我们要读取或者要写入的值。这个值的类型就被写在了<>当中,通常对应的是一个RGBA的值,因此是float4类型。通常情况下,我们会在Compute Shader中处理好纹理,然后在FragmentShader中来对处理后的纹理进行采样。
这样我们就大致理解这行代码的意思了,声明了一个名为Result的可读写二维纹理,其中每个像素的值为float4。
在Compute Shader中可读写的类型除了RWTexture以外还有RWBuffer和RWStructuredBuffer,后面会介绍。
numthreads
然后是下面一句(很重要!):
[numthreads(8,8,1)]
又是num,又是thread的,肯定和线程数量有关。没错,它就是定义一个线程组(Thread Group)中可以被执行的线程(Thread)总数量,格式如下:
numthreads(tX, tY, tZ)
注:X,Y,Z前加个t方便和后续Group的X,Y,Z进行区分
其中tXtYtZ的值即线程的总数量,例如numthreads(4, 4, 1)和numthreads(16, 1, 1)都代表着有16个线程。那么为什么不直接使用numthreads(num)这种形式定义,而非要分成tX、tY、tZ这种三维的形式呢?看到后面自然就懂其中的奥秘了。
每个核函数前面我们都需要定义numthreads,否则编译会报错。
其中tX,tY,tZ三个值也并不是可以随便乱填的,比如来一刀tX=99999暴击一下,这是不行的。它们在不同的版本里有如下的约束:

在Direct11中,可以通过ID3D11DeviceContext::Dispatch(gX,gY,gZ)方法创建gXgYgZ个线程组,一个线程组里又会包含多个线程(数量即numthreads定义)。
注意顺序,先numthreads定义好每个核函数对应线程组里线程的数量(tXtYtZ),再用Dispatch定义用多少线程组(gXgYgZ)来处理这个核函数。其中每个线程组内的线程都是并行的,不同线程组的线程可能同时执行,也可能不同时执行。一般一个GPU同时执行的线程数,在1000-10000之间。
接着我们用一张示意图来看看线程与线程组的结构,如下图:

上半部分代表的是线程组结构,下半部分代表的是单个线程组里的线程结构。因为他们都是由(X,Y,Z)来定义数量的,因此就像一个三维数组,下标都是从0开始。我们可以把它们看做是表格一样:有Z个一样的表格,每个表格有X列和Y行。例如线程组中的(2,1,0),就是第1个表格的第2行第3列对应的线程组,下半部分的线程也是同理。
搞清楚结构,我们就可以很好的理解下面这些与单个线程有关的参数含义:
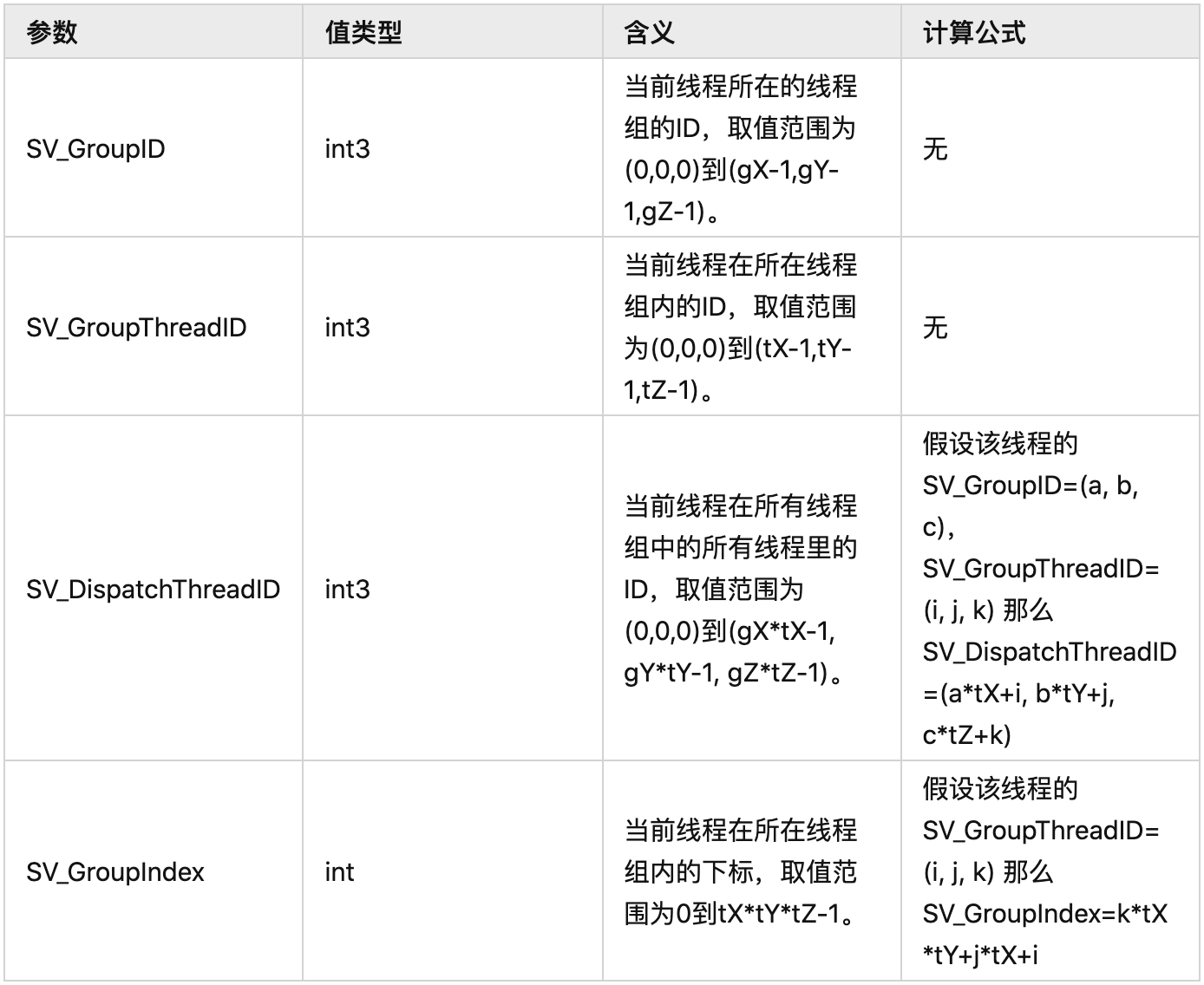
这里需要注意的是,不管是Group还是Thread,它们的顺序都是先X再Y最后Z,用表格的理解就是先行(X)再列(Y)然后下一个表(Z),例如我们tX=5,tY=6那么第1个thread的SV_GroupThreadID=(0,0,0),第2个的SV_GroupThreadID=(1,0,0),第6个的SV_GroupThreadID=(0,1,0),第30个的SV_GroupThreadID=(4,5,0),第31个的SV_GroupThreadID=(0,0,1)。Group同理,搞清顺序后,SV_GroupIndex的计算公式就很好理解了。
再举个例子,比如SV_GroupID为(0,0,0)和(1,0,0)的两个Group,它们内部的第1个Thread的SV_GroupThreadID都为(0,0,0)且SV_GroupIndex都为0,但是前者的SV_DispatchThreadID=(0,0,0)而后者的SV_DispatchThreadID=(tX,0,0)。
好好理解下,它们在核函数里非常的重要。
numthreads - Win32 apps
核函数
void CSMain (uint3 id : SV_DispatchThreadID)
{
Result[id.xy] = float4(id.x & id.y, (id.x & 15)/15.0, (id.y & 15)/15.0, 0.0);
}
最后就是我们声明的核函数了,其中参数SV_DispatchThreadID的含义上面已经介绍过了,除了这个参数以外,我们前面提到的几个参数都可以被传入到核函数当中,根据实际需求做取舍即可,完整如下:
void KernelFunction(uint3 groupId : SV_GroupID,
uint3 groupThreadId : SV_GroupThreadID,
uint3 dispatchThreadId : SV_DispatchThreadID,
uint groupIndex : SV_GroupIndex)
{
}
而函数内执行的代码就是为我们Texture中下标为id.xy的像素赋值一个颜色,这里也就是最牛的地方。
举个例子,以往我们想要给一个x*y分辨率的Texture每个像素进行赋值,单线程的情况下,我们的代码往往如下:
for (int i = 0; i < x; i++)
for (int j = 0; j < y; j++)
Result[uint2(x, y)] = float4(a, b, c, d);
两个循环,像素一个个的慢慢赋值。那么如果我们要每帧给很多张2048*2048的图片进行操作,可想而知会卡死。
如果使用多线程,为了避免不同的线程对同一个像素进行操作,我们往往使用分段操作的方法,如下,四个线程进行处理:
void Thread1()
{
for (int i = 0; i < x/4; i++)
for (int j = 0; j < y/4; j++)
Result[uint2(x, y)] = float4(a, b, c, d);
}
void Thread2()
{
for (int i = x/4; i < x/2; i++)
for (int j = y/4; j < y/2; j++)
Result[uint2(x, y)] = float4(a, b, c, d);
}
void Thread3()
{
for (int i = x/2; i < x/4*3; i++)
for (int j = x/2; j < y/4*3; j++)
Result[uint2(x, y)] = float4(a, b, c, d);
}
void Thread4()
{
for (int i = x/4*3; i < x; i++)
for (int j = y/4*3; j < y; j++)
Result[uint2(x, y)] = float4(a, b, c, d);
}
这么写不是很蠢么,如果有更多的线程,分成更多段,不就一堆重复的代码。但是如果我们能知道每个线程的开始和结束下标,不就可以把这些代码统一起来了么,如下:
void Thread(int start, int end)
{
for (int i = start; i < end; i++)
for (int j = start; j < end; j++)
Result[uint2(x, y)] = float4(a, b, c, d);
}
那我要是可以开出很多很多的线程是不是就可以一个线程处理一个像素了?
void Thread(int x, int y)
{
Result[uint2(x, y)] = float4(a, b, c, d);
}
用CPU我们做不到这样,但是用GPU,用Compute Shader我们就可以。实际上,前面默认的Compute Shader的代码里,核函数的内容就是这样的。
接下来我们来看看Compute Shader的妙处,看id.xy的值。id的类型为SV_DispatchThreadID,我们先来回忆下SV_DispatchThreadID的计算公式:
假设该线程的SV_GroupID=(a, b, c),SV_GroupThreadID=(i, j, k) 那么SV_DispatchThreadID=(atX+i, btY+j, c*tZ+k)
首先前面我们使用了[numthreads(8,8,1)],即tX=8,tY=8,tZ=1,且i和j的取值范围为0到7,而k=0。那么我们线程组(0,0,0)中所有线程的SV_DispatchThreadID.xy也就是id.xy的取值范围即为(0,0)到(7,7),线程组(1,0,0)中它的取值范围为(8,0)到(15, 7),...,线程(0,1,0)中它的取值范围为(0,8)到(7,15),...,线程组(a,b,0)中它的取值范围为(a8, b8, 0)到(a8+7,b8+7,0)。
我们用示意图来看下,假设下图每个网格里包含了64个像素:

也就是说我们每个线程组会有64个线程同步处理64个像素,并且不同的线程组里的线程不会重复处理同一个像素,若要处理分辨率为1024*1024的图,我们只需要dispatch(1024/8, 1024/8, 1)个线程组。
这样就实现了成百上千个线程同时处理一个像素了,若用CPU的方式这是不可能的。是不是很妙?
而且我们可以发现numthreads中设置的值是很值得推敲的,例如我们有4*4的矩阵要处理,设置numthreads(4,4,1),那么每个线程的SV_GroupThreadID.xy的值不正好可以和矩阵中每项的下标对应上么。
我们在Unity中怎么调用核函数,又怎么dispatch线程组以及使用的RWTexture又怎么来呢?这里就要回到我们C#的部分了。
C#部分
以往的vertex&fragment shader,我们都是给它关联到Material上来使用的,但是Compute Shader不一样,它是由C#来驱动的。
先新建一个monobehaviour脚本,Unity为我们提供了一个Compute Shader的类型用来引用我们前面生成的 .compute 文件:
public ComputeShader computeShader;

在Inspector界面关联.compute文件
此外我们再关联一个Material,因为Compute Shader处理后的纹理,依旧要经过Fragment Shader采样后来显示。
public Material material;
这个Material我们使用一个Unlit Shader,并且纹理不用设置,如下:

然后关联到我们的脚本上,并且随便建个Cube也关联上这Material。
接着我们可以将Unity中的RenderTexture赋值到Compute Shader中的RWTexture2D上,但是需要注意因为我们是多线程处理像素,并且这个处理过程是无序的,因此我们要将RenderTexture的enableRandomWrite属性设置为true,代码如下:
RenderTexture mRenderTexture = new RenderTexture(256, 256, 16);
mRenderTexture.enableRandomWrite = true;
mRenderTexture.Create();
我们创建了一个分辨率为256*256的RenderTexture,首先我们要把它赋值给我们的Material,这样我们的Cube就会显示出它。然后要把它赋值给我们Compute Shader中的Result变量,代码如下:
material.mainTexture = mRenderTexture;
computeShader.SetTexture(kernelIndex, "Result", mRenderTexture);
这里有一个kernelIndex变量,即核函数下标,我们可以利用FindKernel来找到我们声明的核函数的下标:
int kernelIndex = computeShader.FindKernel("CSMain");
这样在我们FragmentShader采样的时候,采样的就是Compute Shader处理过后的纹理:
fixed4 frag (v2f i) : SV_Target
{
// _MainTex 就是被处理后的 RenderTexture
fixed4 col = tex2D(_MainTex, i.uv);
return col;
}
最后就是开线程组和调用我们的核函数了,在Compute Shader中,Dispatch方法为我们一步到位:
computeShader.Dispatch(kernelIndex, 256 / 8, 256 / 8, 1);
为什么是256/8,前面已经解释过了。来看看效果:

上图就是我们Unity默认生成的Compute Shader代码所能带来的效果,我们也可试下用它处理2048*2048的Texture,也是非常快的。
接下来我们再来看看粒子效果的例子:
首先一个粒子通常拥有颜色和位置两个属性,并且我们肯定是要在Compute Shader里去处理这两个属性的,那么我们就可以在Compute Shader创建一个struct来存储:
struct ParticleData {
float3 pos;
float4 color;
};
接着,这个粒子肯定是很多很多的,我们就需要一个像List一样的东西来存储它们,在ComputeShader中为我们提供了RWStructuredBuffer类型。
RWStructuredBuffer
它是一个可读写的Buffer,并且我们可以指定Buffer中的数据类型为我们自定义的struct类型,不用再局限于int、float这类的基本类型。
因此我们可以这么定义我们的粒子数据:
RWStructuredBuffer<ParticleData> ParticleBuffer;
RWStructuredBuffer - Win32 apps
为了有动效,我们可以再添加一个时间相关值,我们可以根据时间来修改粒子的位置和颜色:
float Time;
接着就是怎么在核函数里修改我们的粒子信息了,要修改某个粒子,我们肯定要知道粒子在Buffer中的下标,并且这个下标在不同的线程中不能重复,否则就可能导致多个线程修改同一个粒子了。
根据前面的介绍,我们知道一个线程组中SV_GroupIndex是唯一的,但是在不同线程组中并不是。例如每个线程组内有1000个线程,那么SV_GroupID都是0到999。我们可以根据SV_GroupID把它叠加上去,例如SV_GroupID=(0,0,0)是0-999,SV_GroupID=(1,0,0)是1000-1999等等,为了方便我们的线程组都可以是(X,1,1)格式。然后我们就可以根据Time和Index随便的摆布下粒子,Compute Shader完整代码:
#pragma kernel UpdateParticle
struct ParticleData {
float3 pos;
float4 color;
};
RWStructuredBuffer<ParticleData> ParticleBuffer;
float Time;
[numthreads(10, 10, 10)]
void UpdateParticle(uint3 gid : SV_GroupID, uint index : SV_GroupIndex)
{
int pindex = gid.x * 1000 + index;
float x = sin(index);
float y = sin(index * 1.2f);
float3 forward = float3(x, y, -sqrt(1 - x * x - y * y));
ParticleBuffer[pindex].color = float4(forward.x, forward.y, cos(index) * 0.5f + 0.5, 1);
if (Time > gid.x)
ParticleBuffer[pindex].pos += forward * 0.005f;
}
接下来我们要在C#里给粒子初始化并且传递给Compute Shader。我们要传递粒子数据,也就是说要给前面的RWStructuredBuffer赋值,Unity为我们提供了ComputeBuffer类来与RWStructuredBuffer或StructuredBuffer相对应。
ComputeBuffer
在Compute Shader中经常需要将我们一些自定义的Struct数据读写到内存缓冲区,ComputeBuffer就是为这种情况而生的。我们可以在C#里创建并填充它,然后传递到Compute Shader或者其他Shader中使用。
通常我们用下面方法来创建它:
ComputeBuffer buffer = new ComputeBuffer(int count, int stride)
其中count代表我们buffer中元素的数量,而stride指的是每个元素占用的空间(字节),例如我们传递10个float的类型,那么count=10,stride=4。需要注意的是ComputeBuffer中的stride大小必须和RWStructuredBuffer中每个元素的大小一致。
声明完成后我们可以使用SetData方法来填充,参数为自定义的struct数组:
buffer.SetData(T[]);
最后我们可以使用Compute Shader类中的SetBuffer方法来把它传递到Compute Shader中:
public void SetBuffer(int kernelIndex, string name, ComputeBuffer buffer)
记得用完后把它Release()掉。
https://docs.unity3d.com/ScriptReference/ComputeBuffer.html
在C#中我们定义一个一样的struct,这样才能保证和Compute Shader中的大小一致:
public struct ParticleData
{
public Vector3 pos;//等价于float3
public Color color;//等价于float4
}
然后我们在Start方法中声明我们的ComputeBuffer,并且找到我们的核函数:
void Start()
{
//struct中一共7个float,size=28
mParticleDataBuffer = new ComputeBuffer(mParticleCount, 28);
ParticleData[] particleDatas = new ParticleData[mParticleCount];
mParticleDataBuffer.SetData(particleDatas);
kernelId = computeShader.FindKernel("UpdateParticle");
}
由于我们想要我们的粒子是运动的,即每帧要修改粒子的信息。因此我们在Update方法里去传递Buffer和Dispatch:
void Update()
{
computeShader.SetBuffer(kernelId, "ParticleBuffer", mParticleDataBuffer);
computeShader.SetFloat("Time", Time.time);
computeShader.Dispatch(kernelId,mParticleCount/1000,1,1);
}
到这里我们的粒子位置和颜色的操作都已经完成了,但是这些数据并不能在Unity里显示出粒子,我们还需要Vertex&FragmentShader的帮忙,我们新建一个UnlitShader,修改下里面的代码如下:
Shader "Unlit/ParticleShader"
{
SubShader
{
Tags { "RenderType"="Opaque" }
LOD 100
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct v2f
{
float4 col : COLOR0;
float4 vertex : SV_POSITION;
};
struct particleData
{
float3 pos;
float4 color;
};
StructuredBuffer<particleData> _particleDataBuffer;
v2f vert (uint id : SV_VertexID)
{
v2f o;
o.vertex = UnityObjectToClipPos(float4(_particleDataBuffer[id].pos, 0));
o.col = _particleDataBuffer[id].color;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
return i.col;
}
ENDCG
}
}
}
前面我们说了ComputeBuffer也可以传递到普通的Shader中,因此我们在Shader中也创建一个结构一样的Struct,然后利用StructuredBuffer来接收。
SV_VertexID:在VertexShader中用它来作为传递进来的参数,代表顶点的下标。我们有多少个粒子即有多少个顶点。顶点数据使用我们在Compute Shader中处理过的Buffer。
最后我们在C#中关联一个带有上面Shader的Material,然后将粒子数据传递过去,最终绘制出来。完整代码如下:
public class ParticleEffect : MonoBehaviour
{
public ComputeShader computeShader;
public Material material;
ComputeBuffer mParticleDataBuffer;
const int mParticleCount = 20000;
int kernelId;
struct ParticleData
{
public Vector3 pos;
public Color color;
}
void Start()
{
//struct中一共7个float,size=28
mParticleDataBuffer = new ComputeBuffer(mParticleCount, 28);
ParticleData[] particleDatas = new ParticleData[mParticleCount];
mParticleDataBuffer.SetData(particleDatas);
kernelId = computeShader.FindKernel("UpdateParticle");
}
void Update()
{
computeShader.SetBuffer(kernelId, "ParticleBuffer", mParticleDataBuffer);
computeShader.SetFloat("Time", Time.time);
computeShader.Dispatch(kernelId,mParticleCount/1000,1,1);
material.SetBuffer("_particleDataBuffer", mParticleDataBuffer);
}
void OnRenderObject()
{
material.SetPass(0);
Graphics.DrawProceduralNow(MeshTopology.Points, mParticleCount);
}
void OnDestroy()
{
mParticleDataBuffer.Release();
mParticleDataBuffer = null;
}
}
material.SetBuffer:传递ComputeBuffer到我们的Shader当中。
OnRenderObject:该方法里我们可以自定义绘制几何。
DrawProceduralNow:我们可以用该方法绘制几何,第一个参数是拓扑结构,第二个参数数顶点数。
https://docs.unity3d.com/ScriptReference/Graphics.DrawProceduralNow.html
最终得到的效果如下:

Demo链接如下:
https://github.com/luckyWjr/ComputeShaderDemo/tree/master/Assets/Particle
ComputeBufferType
在例子中,我们new一个ComputeBuffer的时候并没有使用到ComputeBufferType的参数,默认使用了ComputeBufferType.Default。实际上我们的ComputeBuffer可以有多种不同的类型对应HLSL中不同的Buffer,来在不同的场景下使用,一共有如下几种类型:

举个例子,在做GPU剔除的时候经常会使用到Append的Buffer(例如后面介绍的用Compute Shader实现视椎剔除),C#中的声明如下:
var buffer = new ComputeBuffer(count, sizeof(float), ComputeBufferType.Append);
注:Default,Append,Counter,Structured对应的Buffer每个元素的大小,也就是stride的值应该是4的倍数且小于2048。
上述ComputeBuffer可以对应Compute Shader中的AppendStructuredBuffer,然后我们可以在Compute Shader里使用Append方法为Buffer添加元素,例如:
AppendStructuredBuffer<float> result;
[numthreads(640, 1, 1)]
void ViewPortCulling(uint3 id : SV_DispatchThreadID)
{
if(满足一些自定义条件)
result.Append(value);
}
那么我们的Buffer中到底有多少个元素呢?计数器可以帮助我们得到这个结果。
在C#中,我们可以先使用ComputeBuffer.SetCounterValue方法来初始化计数器的值,例如:
buffer.SetCounterValue(0);//计数器值为0
随着AppendStructuredBuffer.Append方法,我们计数器的值会自动的++。当Compute Shader处理完成后,我们可以使用ComputeBuffer.CopyCount方法来获取计数器的值,如下:
public static void CopyCount(ComputeBuffer src, ComputeBuffer dst, int dstOffsetBytes);
Append、Consume或者Counter的Buffer会维护一个计数器来存储Buffer中的元素数量,该方法可以把src中的计数器的值拷贝到dst中,dstOffsetBytes为在dst中的偏移。在DX11平台dst的类型必须为Raw或者IndirectArguments,而在其他平台可以是任意类型。
因此获取buffer中元素数量的代码如下:
uint[] countBufferData = new uint[1] { 0 };
var countBuffer = new ComputeBuffer(1, sizeof(uint), ComputeBufferType.IndirectArguments);
ComputeBuffer.CopyCount(buffer, countBuffer, 0);
countBuffer.GetData(countBufferData);
//buffer中的元素数量即为:countBufferData[0]
从上面两个最基础的例子中,我们可以看出,Compute Shader中的数据都是由C#传递过来的,也就是说数据要从CPU传递到GPU。并且在Compute Shader处理结束后又要从GPU传回CPU。这样可能会有点延迟,而且它们之间的传输速率也是一个瓶颈。
但是如果我们有大量的计算需求,不要犹豫,请使用Compute Shader,对性能能有很大的提升。
UAV(Unordered Access view)
Unordered是无序的意思,Access即访问,view代表的是“data in the required format”,应该可以理解为数据所需要的格式吧。
什么意思呢?我们的Compute Shader是多线程并行的,因此我们的数据必然需要能够支持被无序的访问。例如,如果纹理只能被(0,0),(1,0),(2,0),...,Buffer只能被[0],[1],[2],...这样有序访问,那么想要用多线程来修改它们明显不行,因此提出了一个概念,即UAV,可无序访问的数据格式。
前面我们提到了RWTexture,RWStructuredBuffer这些类型都属于UAV的数据类型,并且它们支持在读取的同时写入。它们只能在FragmentShader和ComputeShader中被使用(绑定)。
如果我们的RenderTexture不设置enableRandomWrite,或者我们传递一个Texture给RWTexture,那么运行时就会报错:
the texture wasn't created with the UAV usage flag set!
不能被读写的数据类型,例如Texure2D,我们称之为SRV(Shader Resource View)。
Wrap / WaveFront
前面我们说了使用numthreads可以定义每个线程组内线程的数量,那么我们使用numthreads(1,1,1)真的每个线程组只有一个线程嘛?NO!
这个问题要从硬件说起,我们GPU的模式是SIMT(single-instruction multiple-thread,单指令多线程)。在NVIDIA的显卡中,一个SM(Streaming Multiprocessor)可调度多个wrap,而每个wrap里会有32个线程。我们可以简单的理解为一个指令最少也会调度32个并行的线程。而在AMD的显卡中这个数量为64,称之为Wavefront。
也就是说如果是NVIDIA的显卡,如果我们使用numthreads(1,1,1),那么线程组依旧会有32个线程,但是多出来的31个线程完全就处于没有使用的状态,造成浪费。因此我们在使用numthreads时,最好将线程组的数量定义为64的倍数,这样两种显卡都可以顾及到。
https://www.cvg.ethz.ch/teaching/2011spring/gpgpu/GPU-Optimization.pdf
移动端支持问题
我们可以运行时调用SystemInfo.supportsComputeShaders来判断当前的机型是否支持Compute Shader。其中OpenGL ES从3.1版本才开始支持Compute Shader,而使用Vulkan的Android平台以及使用Metal的IOS平台都支持Compute Shader。
然而有些Android手机即使支持Compute Shader,但是对RWStructuredBuffer的支持并不友好。例如在某些OpenGL ES 3.1的手机上,只支持Fragment Shader内访问StructuredBuffer。
在普通的Shader中要支持Compute Shader,Shader Model最低要求为4.5,即:
#pragma target 4.5
利用Compute Shader实现视椎剔除
《Unity中使用Compute Shader做视锥剔除(View Frustum Culling)》
利用Compute Shader实现Hi-z遮挡剔除
《Unity中使用Compute Shader实现Hi-z遮挡剔除(Occlusion Culling)》
Shader.PropertyToID
在Compute Shader中定义的变量依旧可以通过 Shader.PropertyToID("name") 的方式来获得唯一id。这样当我们要频繁利用ComputeShader.SetBuffer对一些相同变量进行赋值的时候,就可以把这些id事先缓存起来,避免造成GC。
int grassMatrixBufferId;
void Start() {
grassMatrixBufferId = Shader.PropertyToID("grassMatrixBuffer");
}
void Update() {
compute.SetBuffer(kernel, grassMatrixBufferId, grassMatrixBuffer);
// dont use it
//compute.SetBuffer(kernel, "grassMatrixBuffer", grassMatrixBuffer);
}
全局变量或常量?
假如我们要实现一个需求,在Compute Shader中判断某个顶点是否在一个固定大小的包围盒内,那么按照以往C#的写法,我们可能如下定义包围盒大小:
#pragma kernel CSMain
float3 boxSize1 = float3(1.0f, 1.0f, 1.0f); // 方法1
const float3 boxSize2 = float3(2.0f, 2.0f, 2.0f); // 方法2
static float3 boxSize3 = float3(3.0f, 3.0f, 3.0f); // 方法3
[numthreads(8,8,1)]
void CSMain (uint3 id : SV_DispatchThreadID)
{
// 做判断
}
经过测试,其中方法1和方法2的定义,在CSMain里读取到的值都为 float3(0.0f,0.0f,0.0f) ,只有方法3才是最开始定义的值。
Shader variants and keywords
ComputeShader同样支持Shader变体,用法和普通的Shader变体基本相似,示例如下:
#pragma kernel CSMain
#pragma multi_compile __ COLOR_WHITE COLOR_BLACK
RWTexture2D<float4> Result;
[numthreads(8,8,1)]
void CSMain (uint3 id : SV_DispatchThreadID)
{
#if defined(COLOR_WHITE)
Result[id.xy] = float4(1.0, 1.0, 1.0, 1.0);
#elif defined(COLOR_BLACK)
Result[id.xy] = float4(0.0, 0.0, 0.0, 1.0);
#else
Result[id.xy] = float4(id.x & id.y, (id.x & 15) / 15.0, (id.y & 15) / 15.0, 0.0);
#endif
}
然后我们就可以在C#端启用或禁用某个变体了:
- #pragma multi_compile 声明的全局变体可以使用Shader.EnableKeyword/Shader.DisableKeyword或者ComputeShader.EnableKeyword/ComputeShader.DisableKeyword
- #pragma multi_compile_local 声明的局部变体可以使用ComputeShader.EnableKeyword/ComputeShader.DisableKeyword
示例如下:
public class DrawParticle : MonoBehaviour
{
public ComputeShader computeShader;
void Start() {
......
computeShader.EnableKeyword("COLOR_WHITE");
}
}
这是侑虎科技第1027篇文章,感谢作者王江荣供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
作者主页:https://www.zhihu.com/people/luckywjr,再次感谢王江荣的分享,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK