

AI技术在漫画阅读体验上的应用 - InfoQ 写作平台
source link: https://xie.infoq.cn/article/6044eec45541d6c1d0b34391c
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

快看作为国内第一漫画平台,除了连载作品量大,同时也涵盖了多种形态的漫画作品,展示形态不一,如页漫和条漫、黑白漫和彩漫,为了使各种类型漫画读者都能获得良好的阅读体验,减少漫画阅读中的疲劳感,我们结合了深度学习技术,做了一些大胆的探索。
探索一:页漫转条漫
页漫和条漫的不同
提起页漫和条漫,对于很多对漫画不了解的读者来说,可能会比较陌生,为了使读者更好的理解本文的后续内容,我们简单介绍下两种漫画形式的不同。
传播媒介的不同
页漫更多的是伴随着 PC 及印刷物而发展起来的
条漫则是伴随移动互联网的发展,适配移动端小屏幕设备而发展起来的
单排分镜数的不同
页漫一排通常会有多个分镜。另外,在印刷物上,为了渲染气氛或展示更宏大的画面,可能一个画面会跨越两个页码
条漫一排通常只有一个分镜(也可能包含两个小的分镜,但通常信息密度较小或非重要内容分镜)
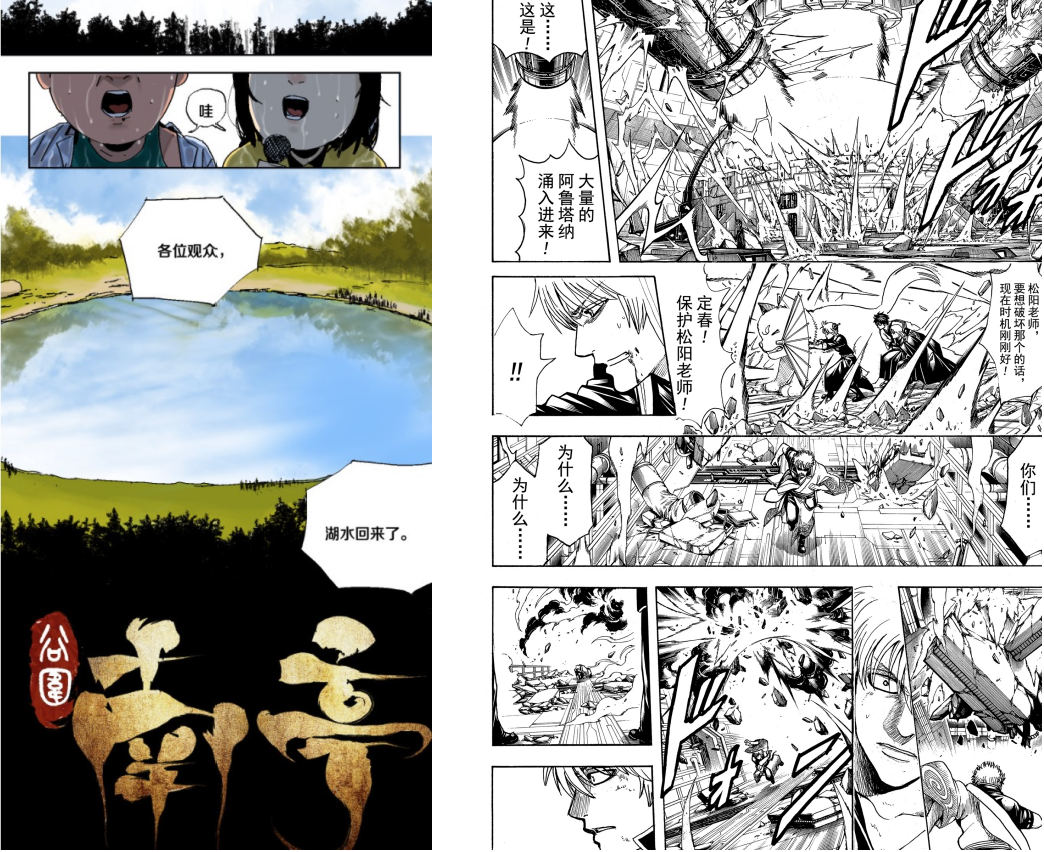
左侧为条漫,右侧为页漫
阅读顺序的不同
国内页漫一般是从左到右,从上到下的顺序进行阅读,而日式页漫则是从右向左,从上到下的顺序
条漫主要是从上到下的阅读顺序
分镜界限的不同
页漫每个分镜内容比较完整,容易划分
条漫因为通常一排只有一个分镜,很多时候内容边界并不清晰,会有大面积的过渡画面,为了引导用户或渲染某种氛围。
以上只是从大部分作品中总结的一些基本规律,由于创作者可以自由发挥,不排除个别页漫或条漫不能用以上讨论的标准进行区分,我们主要讨论一些比较常见的情景。
受限于手机设备的屏幕大小,在手机端,通常是条漫阅读体验会更好。
那么,我们的目标就是:有没有一种技术方案,可以把页漫转换为条漫呢?
第一个想法当然是直接对漫画原稿(PSD 文件)处理,但可惜的是,绝大部分页漫发表年限已久,是没有 PSD 原稿的,部分作品图片稿件,还是扫描生成的图片。受限于现实因素,我们考虑使用第二种方案,直接对图片内容进行识别后重新排版。
鉴于此,为了使重新排版后的内容更加准确,我们识别了漫画内的多种主体:
整个项目的主要流程及用到的模型:
跨页图片合并
在上文中介绍页漫分镜时提到,部分宏大场景在印刷体上会跨越两个页码,但提供给平台的图片稿件中,会被分成两张图片,需要提前识别出这种情况,并进行合并处理,我们针对这种情况训练了 MobileNetv2 模型,模型识别并合并后的效果如下图所示,还原了原始分镜。


正确识别漫画各结构,是保证整个项目成功的关键,针对不同结构的模型训练,我们搜集和标注了大量数据。
文本检测模型:CRAFT
气泡识别模型:Yolo v5
分镜(实例)分割模型:Mask-RCNN
对识别出的重叠的分镜、内嵌的分镜、连通的分镜进行整合,确保不会破坏原内容
日漫阅读方式是从上到下,从右到左,而国漫的阅读方式是从上到下,从左到右,所以排版任务需要提前告知漫画是日漫或是国漫
针对跨页漫画的情况,还需要判断合并后排版方式,我们专门训练了一个模型 ResNet18 来进行识别
因为涉及对内容的重组和生成,会影响到图片质量,在传统页漫图片本身质量不高的情况下,做一次图像增强是非常有必要的,我们选用的是开源 waifu2x 模型实现对图像的增强

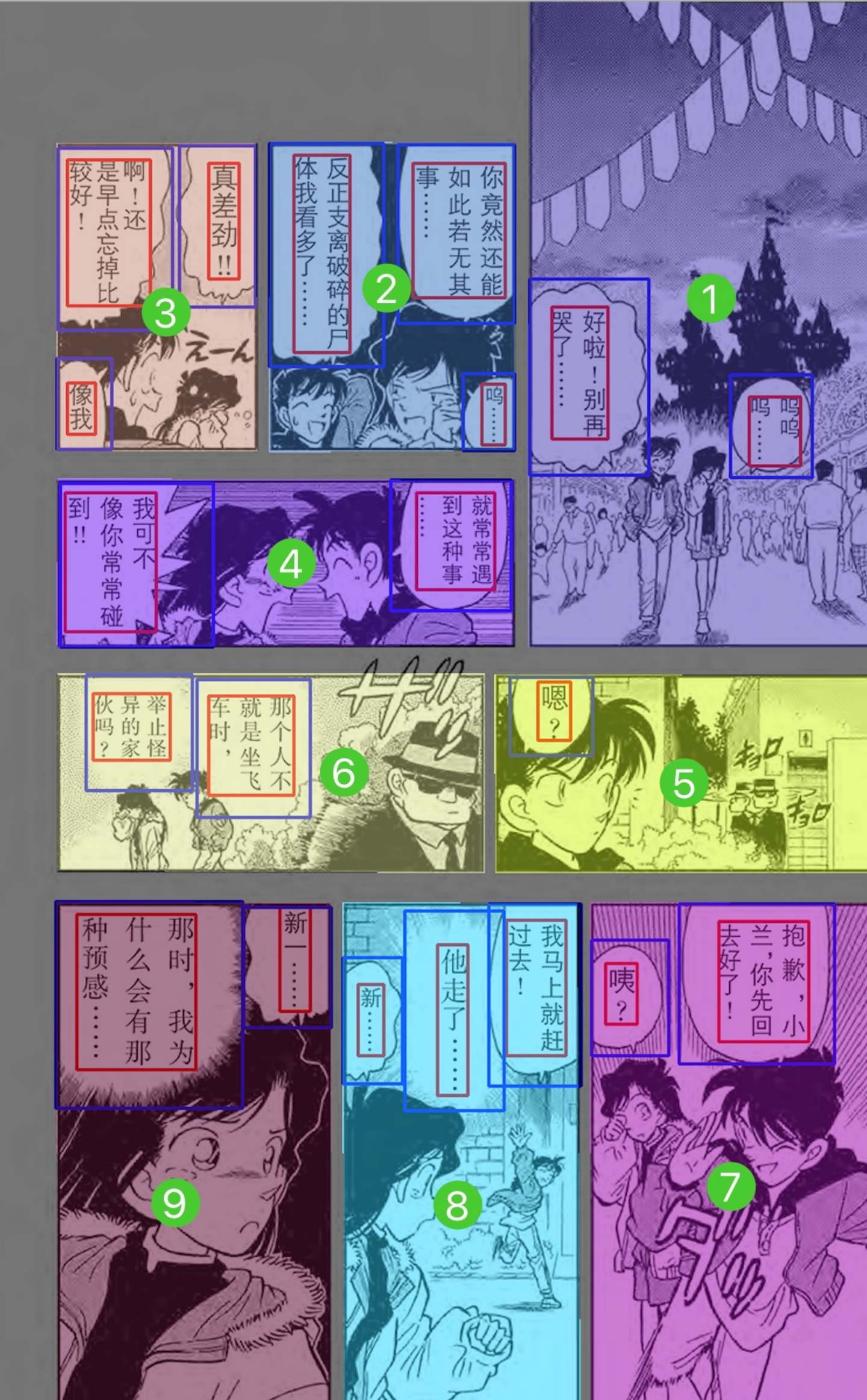
在实际技术落地的过程中,我们遇到的问题比想象中的复杂很多,为了不破坏内容的完整性以及连贯性,在分镜有重叠及联通区域时,我们保留了原始分镜布局,避免拆开分镜导致的文字缺失等问题。


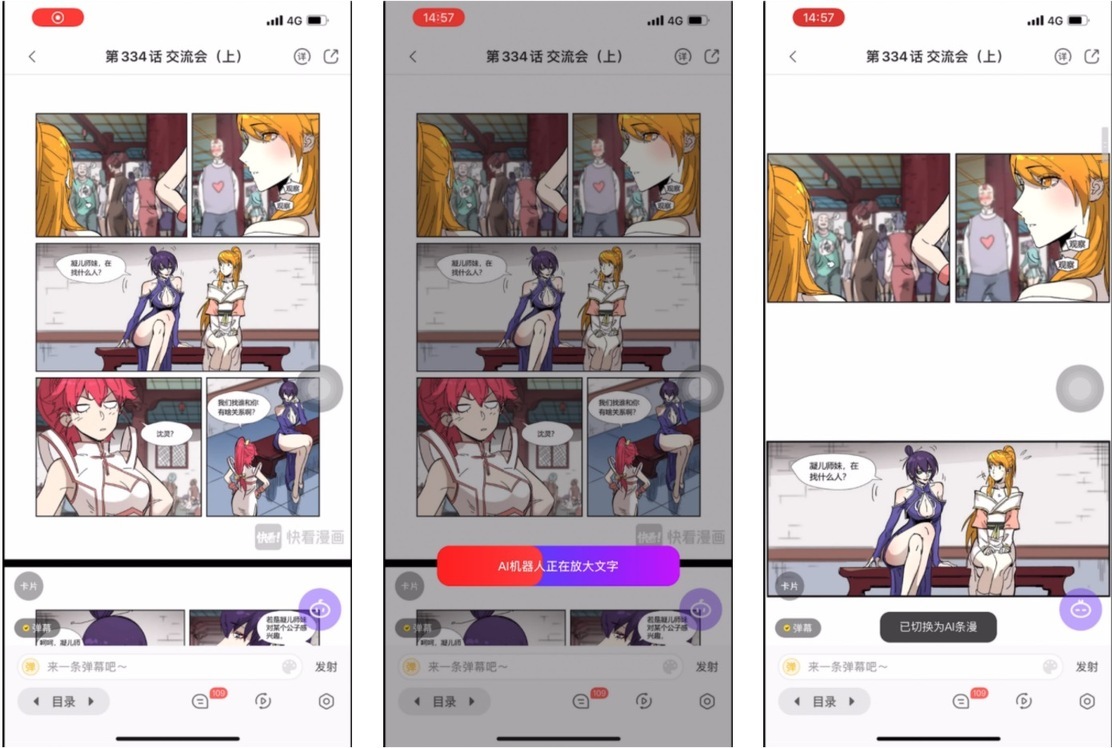
实际在客户端落地效果如下:
探索二:自动阅读
首先我们先来聊一下关于阅读成本这个话题,这里需要明确下概念,我们这里提到的“阅读”,更广义的来讲,是包含“观看”的,所以下文的阅读,我们取阅读+观看的意义。
互联网内容的展现形式,主要包括三种类型,即文字,图片,视频。下面让我们来探讨下阅读不同内容时的区别:
文字阅读,通常信息密度最大,理解成本最高,所需时间最长,所以产生的翻页动作会相对较少。
图文阅读,因为有了画面,理解成本会较低,信息密度适中,但需不断产生翻页滑动的动作,翻页较多
视频观看,动态画面,声音+画面+字幕,多种维度信息融合,用户理解成本最低,播放后无需进行任何操作
对比了以上三种阅读方式,我们可以看到,视频的优势是明显的,信息维度丰富,也无需用户任何操作。另外,当前手机都越来越大,也比较重,用户长时间滑动观看漫画时,手部会比较累。
我们思考的方向是,是否可以让用户无需任何操作,完全模拟人的阅读方式,让画面自己动起来呢?
于是我们调研了已有的一些自动阅读方案,主要有两种形式:
匀速滚动屏幕
滚动固定距离后停顿
第一种方式,阅读体验非常差,因为视觉焦点无法固定,时间稍长后会产生视觉疲劳及眩晕感
第二种方式,虽然体验会好一些,但比较生硬,无法对理解画面内容,经常会发生停留画面被分割的情况。
基于以上调研和思考,为了获得近似于人阅读习惯的无感阅读体验,我们确定了以下目标:
智能计算停留画面
智能计算停留时间
以上目标,也既是说:每次滑动距离不定,每个画面停留时间不定。
智能计算停留画面
为了达到这个目的,我们对漫画内容进行了识别,主要识别了漫画格子、气泡文字、动漫人脸等要素。
条漫的分镜识别,是一个重要难点,实际情况非常复杂,梳理场景、标注数据、模型训练,都花费比较大的精力,在此不进行展开。

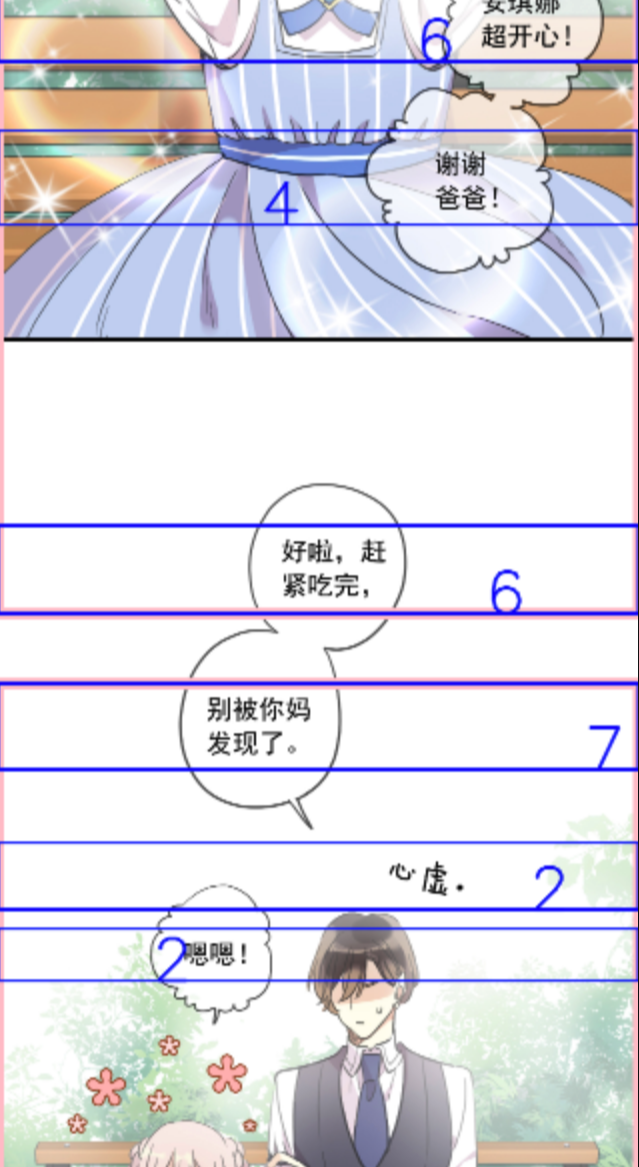
动漫人脸识别

识别出多种要素后,还会对各要素进行合并工作,使画面更完整,不至于产生多个过小的画面。
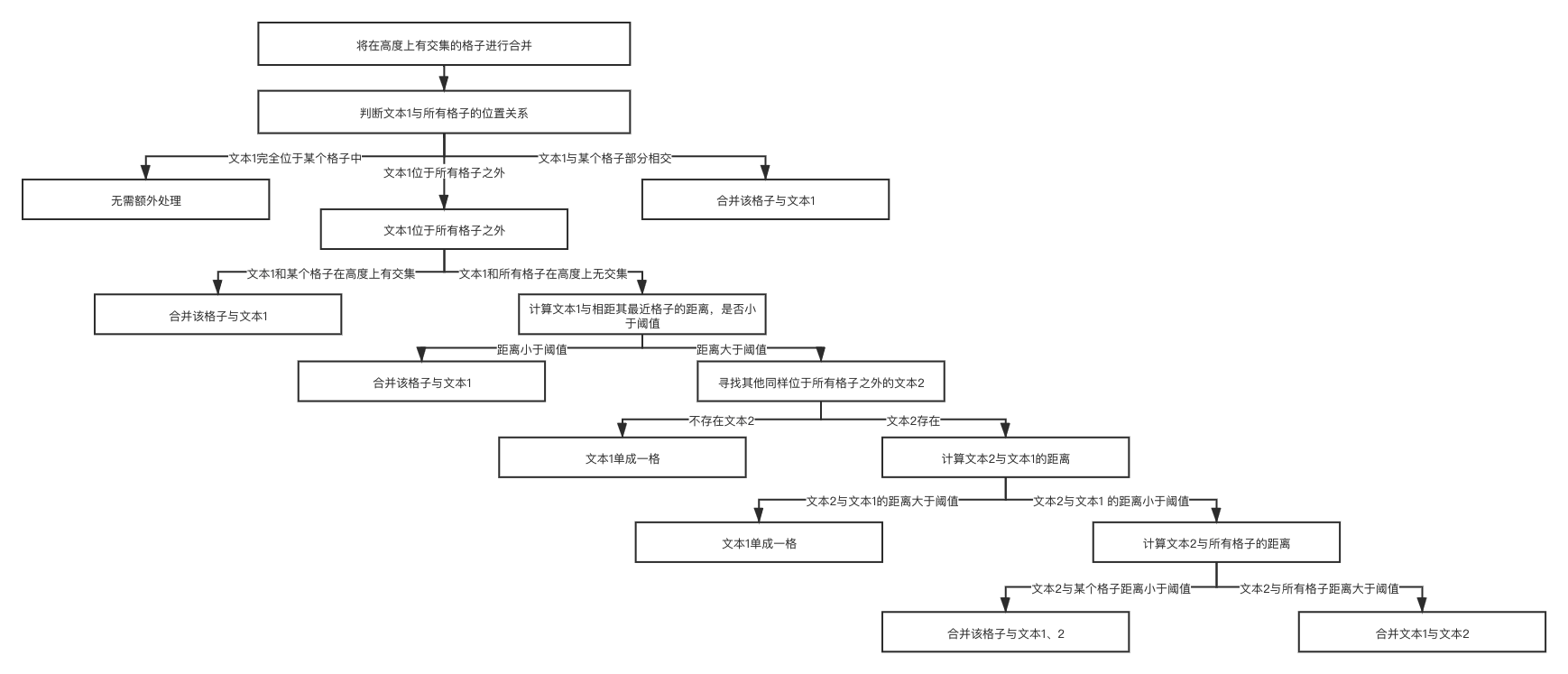
像素高度上有交集的分镜,进行合并
文本和分镜的合并,这里面分成三种情况
文本在分镜内,这种情况比较简单,视觉单元为分镜边缘
文本部分在分镜内,部分在分镜外,视觉单元边界取文本和分镜上下最大值
文本游离于分镜外,处理逻辑比较复杂
最终服务端返回的数据结构如下:

客户端在拿到服务端返回数据后,会根据实际用户设备屏幕大小,重新适配计算后端返回的视觉单元数据,对于较大的分镜,会进行拆分。对于较小的分镜,会进行再次合并。
智能计算停留时间
合适的画面停留时间,符合人直觉的停留时间,不让用户产生突兀感,是这项工作成功与否的关键。我们用信息密度来确定当前画面停留时间,信息密度越大,阅读成本越高,需要停留的时间越长。关于信息密度,主要涉及以下因子:
除了识别文字区域,我们也能识别出文字格数,文字个数越多,代表信息越多,需要停留的时间越长,通常人的阅读速度为 5-8 字/秒。
针对不同的文本内容,会设置不同的文本权重,默认文字权重为 1.0,而部分文字对于读者来说,是可以忽略,或快速略过的,比如漫画扉页中的作者、责编等信息,就像我们电影院看电影,我们也不会仔细看演职人员表一样。
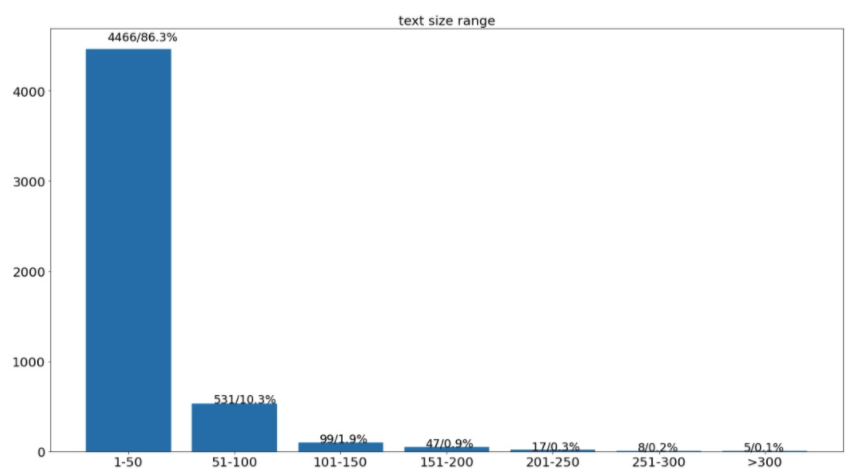
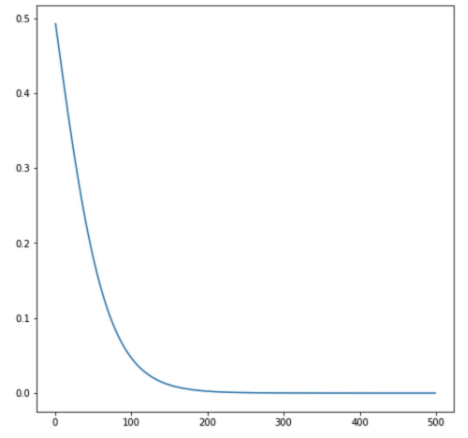
文字大小,也是影响阅读速度的一个重要因素,同样的文字个数,文字小,就会难以阅读,需要的时间也就会更多。我们统计并分析了部分漫画文字的大小分布情况,同时设计了文字大小的权重公式
某个画面内的弹幕数多少与否,通常能反映出当前画面的精彩程度,弹幕数越多,相应的也可以增加画面停留时间,让用户多欣赏一些时间
基础停留时间
即使某个画面无文字及弹幕,也会赋予画面基础停留时间
综合以上因子,图像算法团队和客户端团队,设计了智能画面停留时间公式,每个画面都有自己实时计算的停留时间。当然,每个用户阅读速度不同,在产品落地上,也允许用户调整到适合自己的阅读速度,提供了多挡可调选项。

探索三:漫画视频化
在漫画自动阅读的探索中,虽然基本实现了模拟人的阅读习惯,画面能够自己动起来,但和看视频的体验,差别还是较大的。自动阅读的顺序,还是自上向下的阅读方式,而视频,则是画面持续连贯的,同时还有声音、背景音乐等多种表现形式,虽然漫画限于图片的形态,无法做到视频的帧率,那是否可以以切入画面的形式,同时辅以背景音乐来实现“类视频”的阅读效果呢?或者更进一步,识别出内容的文本后,是否可以用 AI 来进行配音呢?我们正在持续的探索,Demo 也已初见雏形,期待未来的某一天和各位读者见面。
以上就是本文的全部内容了,如果您对我们的工作感兴趣,欢迎加入我们,让我们一起做些有趣的事情吧~ 我们公司正在大力招聘以下岗位,如果您感兴趣,欢迎发邮件到 [email protected]
图像算法工程师
搜索算法工程师
推荐算法工程师
服务端工程师
大数据工程师
前端工程师
客户端工程师
测试工程师
作者:chaooes,2017.11 加入快看,负责搜索、爬虫、图像算法方向的业务探索和相关开发工作
Recommend
-
31
去年年底自己搭了一个vue在移动端的开发框架,感觉体验不是很好。上个星期又要做移动端的项目了。所以我花了两天时间对之前的那个开发框架做了以下优化 自定义vuex-plugins-loading 路由切换动画 + keep alive 动态管理缓存组件 bet
-
38
差距都在细节上。 Serverless 要成就云计算的下一个 10 年,不仅需要在技术上持续精进,也需要在产品体...
-
7
教程 写作小白如何写出10w+阅读量的爆款文章? 写作小白如何写出10w+阅读量的爆款文章? ...
-
3
为什么5G投入巨大,最后体验上感觉和4G的差别不大?-51CTO.COM 为什么5G投入巨大,最后体验上感觉和4G的差别不大? 作者:墨池边溜鹅 2022-02-13 00:18:10 很多人说为什么大投入出来的5G在...
-
6
搜索关注微信公众号"捉虫大师",后端技术分享,架构设计、性能优化、源码阅读、问题排查、踩坑实践。hello 大家好,我是小楼,今天给大家分享一个关于 Agent 技术的话题,也是后端启示录的第 3 篇文章。通...
-
3
1. WebAssembly 技术介绍WebAssembly 是 2015 年诞生的一项新的技术,在 2015 年 7 月,Wasm 首次对外公开,并正式开始设计,同年,W3C 成立了 Wasm 社区小组(成员包括 Chrome、Edge、Firefox 和 WebKit),致力于推动 Wasm 技术的早期发展。
-
3
V2EX › macOS 2020 款 MacBook Pro 16+512 换成 2020 款 MacBook Air 会有体验上很大的改变吗?
-
6
一派·Podcast | 旅居、阅读、写作,以及身体和灵魂的自由 - 少数派
-
3
V2EX › 硬件 有没有用 lg gram 2022 16 寸的老哥?体验上怎么样?
-
9
提升文章阅读体验,我去年用了这 12 个写作秘诀
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK