

5.深入TiDB:Insert 语句
source link: https://www.luozhiyun.com/archives/605
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文基于 TiDB release-5.1进行分析,需要用到 Go 1.16以后的版本
这篇文章我们看一下 TiDB 是插入数据是如何封装的,索引是如何维护的,如果插入的数据发生了冲突会如何处理,类似INSERT IGNORE 与 INSERT ON DUPLICATE KEY UPDATE插入语句是如何处理。
下面我们先构造一个表结构:
CREATE TABLE test_insert (a int primary key, b int, c int,d int,index b_index(b),unique index c_index(c) );这个表结构中有一个主键、普通索引、唯一索引。
普通 Insert
构建执行计划
普通插入 SQL 考虑的是类似下面这样的语句:
INSERT INTO test.test_insert (a, b, c) VALUES (1, 1, 1);首先会和 select 语法一样先进行语法解析构建 ast 语法树:
type InsertStmt struct {
dmlNode
// sql 中的表信息
Table *TableRefsClause
// 字段信息
Columns []*ColumnName
// 要插入的数据
Lists [][]ExprNode
...
}我这里展示的是几个比较重要的字段,因为在插入数据的时候可以使用 :INSERT INTO t VALUES(),(),()... 这样的语法,所以要插入的数据是一个切片:Lists。
然后制定查询计划,在制定查询计划的时候同样会走到 PlanBuilder 的 Build 方法中,然后根据 ast 语法树的类型 进入到 buildInsert 分支中:
func (b *PlanBuilder) Build(ctx context.Context, node ast.Node) (Plan, error) {
b.optFlag |= flagPrunColumns
switch x := node.(type) {
case *ast.InsertStmt:
return b.buildInsert(ctx, x)
...
}
func (b *PlanBuilder) buildInsert(ctx context.Context, insert *ast.InsertStmt) (Plan, error) {
// 获取ast树中表节点
ts, ok := insert.Table.TableRefs.Left.(*ast.TableSource)
if !ok {
return nil, infoschema.ErrTableNotExists.GenWithStackByArgs()
}
// 获取表的相关信息
// 包含了表信息,库信息,分区信息等
tn, ok := ts.Source.(*ast.TableName)
if !ok {
return nil, infoschema.ErrTableNotExists.GenWithStackByArgs()
}
// 获取其中表信息
tableInfo := tn.TableInfo
...
// Build Schema with DBName otherwise ColumnRef with DBName cannot match any Column in Schema.
// schema包含表的字段信息,主键字段等,names是表的字段信息切片
schema, names, err := expression.TableInfo2SchemaAndNames(b.ctx, tn.Schema, tableInfo)
if err != nil {
return nil, err
}
// 根据表的id从缓存中获取表的元数据
// 这里包含的信息比较多,有表名、字段信息、隐藏字段、所有索引、表的字符集编码等
tableInPlan, ok := b.is.TableByID(tableInfo.ID)
if !ok {
return nil, errors.Errorf("Can't get table %s.", tableInfo.Name.O)
}
// 构建插入执行计划
insertPlan := Insert{
Table: tableInPlan,
Columns: insert.Columns,
tableSchema: schema,
tableColNames: names,
IsReplace: insert.IsReplace,
}.Init(b.ctx)
...
// 根据不同的语法执行不同的分支
// Branch for `INSERT ... SET ...`.
if len(insert.Setlist) > 0 {
// Branch for `INSERT ... VALUES ...`.
} else if len(insert.Lists) > 0 {
// 根据ast语法树中的= ast.ExprNode 转换成执行计划的 expression.Expression
err := b.buildValuesListOfInsert(ctx, insert, insertPlan, mockTablePlan, checkRefColumn)
if err != nil {
return nil, err
}
// Branch for `INSERT ... SELECT ...`.
} else {
}
...
return insertPlan, err
}buildInsert 这个方法主要涉及两个部分:
- 补全表相关的元数据信息,包括 Database/Table/Column/Index 信息;
- 处理 ast 语法树中要插入的 Lists 中的数据,将 ast.ExprNode 转换成 expression.Expression。
然后将构建好的 Insert 执行计划返回。
需要注意的是,由于 Insert 语句比较简单,没什么优化的空间,所以不会走 DoOptimize 进行物理优化:
finalPlan, cost, err := plannercore.DoOptimize(ctx, sctx, builder.GetOptFlag(), logic)执行 Insert 计划
func (a *ExecStmt) Exec(ctx context.Context) (_ sqlexec.RecordSet, err error) {
...
// 生成执行器
e, err := a.buildExecutor()
if err != nil {
return nil, err
}
// ExecuteExec will rewrite `a.Plan`, so set plan label should be executed after `a.buildExecutor`.
ctx = a.setPlanLabelForTopSQL(ctx)
// handleNoDelay负责执行像 Insert 这种不需要返回数据的语句,只需要把语句执行完成即可
if handled, result, err := a.handleNoDelay(ctx, e, isPessimistic); handled {
return result, err
}
...
return &recordSet{
executor: e,
stmt: a,
txnStartTS: txnStartTS,
}, nil
}这里根据执行计划生成执行器的过程和 Select 是一致的,我们简单看一下。buildExecutor 方法最后会将执行计划转化成 InsertExec 结构体,后续的执行都由这个结构进行。

在生成完执行计划之后会进入到 handleNoDelay 执行 SQL 语句。后面的执行流程比较长,我们省略一些中间环节:

insertRows 会主要做的就是根据字段类型,获取数据之后做数据填充。
func insertRows(ctx context.Context, base insertCommon) (err error) {
// 获取 InsertValues 实例
e := base.insertCommon()
...
// 设置填充函数
evalRowFunc := e.fastEvalRow
// 如果要插入的数据不是常量,那么会使用evalRow函数
if !e.allAssignmentsAreConstant {
evalRowFunc = e.evalRow
}
rows := make([][]types.Datum, 0, len(e.Lists))
for i, list := range e.Lists {
e.rowCount++
var row []types.Datum
row, err = evalRowFunc(ctx, list, i)
if err != nil {
return err
}
...
}
// 批量设置自增id
rows, err = e.lazyAdjustAutoIncrementDatum(ctx, rows)
if err != nil {
return err
}
// 将数据写入存储引擎中
err = base.exec(ctx, rows)
if err != nil {
return err
}
return nil
}insertRows 在填充数据的时候会判断数据类型,如果要处理的数据有非常量,比如有需要依赖其他字段设值、函数等等,这个时候会使用 evalRow 方法进行填充,否则使用 fastEvalRow 进行填充。最后将数据处理好之后会调用 InsertExec 的 exec 方法将数据写入存储引擎中。
func (e *InsertExec) exec(ctx context.Context, rows [][]types.Datum) error {
...
for i, row := range rows {
...
err := e.addRecord(ctx, row)
if err != nil {
return err
}
}
...
return nil
}在 exec 方法中会遍历所有的数据,然后调用 addRecord 方法进行处理。

InsertExec 的 addRecord 方法最终会调用到 TableCommon 的 AddRecord。
func (t *TableCommon) AddRecord(sctx sessionctx.Context, r []types.Datum, opts ...table.AddRecordOption) (recordID kv.Handle, err error) {
txn, err := sctx.Txn(true)
if err != nil {
return nil, err
}
...
writeBufs := sessVars.GetWriteStmtBufs()
// 获取记录行的key
key := t.RecordKey(recordID)
// 格式化数据行
writeBufs.RowValBuf, err = tablecodec.EncodeRow(sc, row, colIDs, writeBufs.RowValBuf, writeBufs.AddRowValues, rd)
if err != nil {
return nil, err
}
value := writeBufs.RowValBuf
// 检测该key在本地缓存中是否存在
var setPresume bool
skipCheck := sctx.GetSessionVars().StmtCtx.BatchCheck
if (t.meta.IsCommonHandle || t.meta.PKIsHandle) && !skipCheck && !opt.SkipHandleCheck {
// 如果是 LazyCheck ,那么只读取本地缓存判断是否存在
if sctx.GetSessionVars().LazyCheckKeyNotExists() {
var v []byte
//只读取本地缓存判断是否存在
v, err = txn.GetMemBuffer().Get(ctx, key)
if err != nil {
setPresume = true
}
if err == nil && len(v) == 0 {
err = kv.ErrNotExist
}
} else {
//否则会通过rpc请求tikv从集群中校验数据是否存在
_, err = txn.Get(ctx, key)
}
if err == nil {
handleStr := getDuplicateErrorHandleString(t, recordID, r)
return recordID, kv.ErrKeyExists.FastGenByArgs(handleStr, "PRIMARY")
} else if !kv.ErrNotExist.Equal(err) {
return recordID, err
}
}
// 将 Key-Value 写到当前事务的缓存中
if setPresume {
err = memBuffer.SetWithFlags(key, value, kv.SetPresumeKeyNotExists)
} else {
err = memBuffer.Set(key, value)
}
if err != nil {
return nil, err
}
// 构造 Index 数据
h, err := t.addIndices(sctx, recordID, r, txn, createIdxOpts)
if err != nil {
return h, err
}
...
return recordID, nil
}AddRecord 主要做这么几件事:
- 获取记录行的key,序列化 value,将 Key-Value 写到当前事务的缓存中;
- 构造 Index 数据;
TiDB 中存储的数据是全局有序 的,并且数据会以 Key-Value的形式存储在 TiDB 中。
所以 TiDB 对每个表分配一个 TableID,每一个索引都会分配一个 IndexID,每一行分配一个 RowID(如果表有整数型的 Primary Key,那么会用 Primary Key 的值当做 RowID),其中 TableID 在整个集群内唯一,IndexID/RowID 在表内唯一,这些 ID 都是 int64 类型。
每行数据按照如下规则进行编码成 Key-Value pair:
Key: tablePrefix{tableID}_recordPrefixSep{rowID}
Value: [col1, col2, col3, col4]那么对应的代码实现则会调用 RecordKey 方法获得一个这样的 Key:
t.indexPrefix = tablecodec.GenTableIndexPrefix(physicalTableID)
func (t *TableCommon) RecordKey(h kv.Handle) kv.Key {
return tablecodec.EncodeRecordKey(t.recordPrefix, h)
}这个 Key 分别由 tableID 与 rowID 构成;
对于 Unique Index 数据,会按照如下规则编码成 Key-Value pair:
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: rowID对于非Unique Index 数据,可能有多行数据的 ColumnsValue是一样的,所以会按照如下规则编码成 Key-Value pair:
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID
Value: null对应的 Index 实现则会调用 addIndices 方法,最后调用到 GenIndexKey 生成Key:

func GenIndexKey(sc *stmtctx.StatementContext, tblInfo *model.TableInfo, idxInfo *model.IndexInfo,
phyTblID int64, indexedValues []types.Datum, h kv.Handle, buf []byte) (key []byte, distinct bool, err error) {
// 校验是否是唯一键
if idxInfo.Unique {
distinct = true
// 唯一键是允许 null 值的
for _, cv := range indexedValues {
if cv.IsNull() {
distinct = false
break
}
}
}
//如果是字符串,那么需要按字段长度裁切
TruncateIndexValues(tblInfo, idxInfo, indexedValues)
// 按 tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue 拼接
key = GetIndexKeyBuf(buf, RecordRowKeyLen+len(indexedValues)*9+9)
key = appendTableIndexPrefix(key, phyTblID)
key = codec.EncodeInt(key, idxInfo.ID)
key, err = codec.EncodeKey(sc, key, indexedValues...)
if err != nil {
return nil, false, err
}
if !distinct && h != nil {
// 如果是非Unique Index 数据,还需要拼接上 rowID
if h.IsInt() {
key, err = codec.EncodeKey(sc, key, types.NewDatum(h.IntValue()))
} else {
key = append(key, h.Encoded()...)
}
}
return
}GenIndexKey 这里会按照上面说到的规则进行拼接。
最后所有的 Key Value 构造完毕之后会将值写入到当前事务缓存中,等待提交。
func (t *TableCommon) AddRecord(sctx sessionctx.Context, r []types.Datum, opts ...table.AddRecordOption) (recordID kv.Handle, err error) {
...
var setPresume bool
skipCheck := sctx.GetSessionVars().StmtCtx.BatchCheck
if (t.meta.IsCommonHandle || t.meta.PKIsHandle) && !skipCheck && !opt.SkipHandleCheck {
// 如果是 LazyCheck ,那么只读取本地缓存判断是否存在
if sctx.GetSessionVars().LazyCheckKeyNotExists() {
var v []byte
//只读取本地缓存判断是否存在
v, err = txn.GetMemBuffer().Get(ctx, key)
if err != nil {
setPresume = true
}
if err == nil && len(v) == 0 {
err = kv.ErrNotExist
}
} else {
//否则会通过rpc请求tikv从集群中校验数据是否存在
_, err = txn.Get(ctx, key)
}
if err == nil {
handleStr := getDuplicateErrorHandleString(t, recordID, r)
return recordID, kv.ErrKeyExists.FastGenByArgs(handleStr, "PRIMARY")
} else if !kv.ErrNotExist.Equal(err) {
return recordID, err
}
}
//将 Key-Value 写到当前事务的缓存中
if setPresume {
// 表示假定数据不存在
err = memBuffer.SetWithFlags(key, value, kv.SetPresumeKeyNotExists)
} else {
err = memBuffer.Set(key, value)
}
if err != nil {
return nil, err
}
...
}由于在设计上,TiDB 与 TiKV 是分层的结构,为了保证高效率的执行,在 LazyCheck 模式下,在事务内只有读操作是必须从存储引擎获取数据,而所有的写操作都事先放在单 TiDB 实例内事务自有的 memDbBuffer 中,在事务提交时才一次性将事务写入 TiKV。
如上面代码所示,在调用 AddRecord 时,会根据 Key 从 MemBuffer 中判断是否存在,不存在那么在操作 memBuffer 的时候会打上标记 SetPresumeKeyNotExists 表示假设插入不会发生冲突,不需要去 TiKV 中检查冲突数据是否存在,只将这些数据标记为待检测状态。最后到提交过程中,统一将整个事务里待检测数据做一次批量检测。
下面通过一个官方的例子来说明一下 LazyCheck 模式下 MySQL 和 TiDB 的区别:
MySQL:
mysql> CREATE TABLE t (i INT UNIQUE);
Query OK, 0 rows affected (0.15 sec)
mysql> INSERT INTO t VALUES (1);
Query OK, 1 row affected (0.01 sec)
mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO t VALUES (1);
ERROR 1062 (23000): Duplicate entry '1' for key 'i'
mysql> COMMIT;
Query OK, 0 rows affected (0.11 sec)TiDB:
mysql> CREATE TABLE t (i INT UNIQUE);
Query OK, 0 rows affected (1.04 sec)
mysql> INSERT INTO t VALUES (1);
Query OK, 1 row affected (0.12 sec)
mysql> BEGIN;
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO t VALUES (1);
Query OK, 1 row affected (0.00 sec)
mysql> COMMIT;
ERROR 1062 (23000): Duplicate entry '1' for key 'i'可以看出来,对于 INSERT 语句 TiDB 是在事务提交的时候才做冲突检测而 MySQL 是在语句执行的时候做的检测。
最后让我们用一幅图来再回顾一下整个流程:
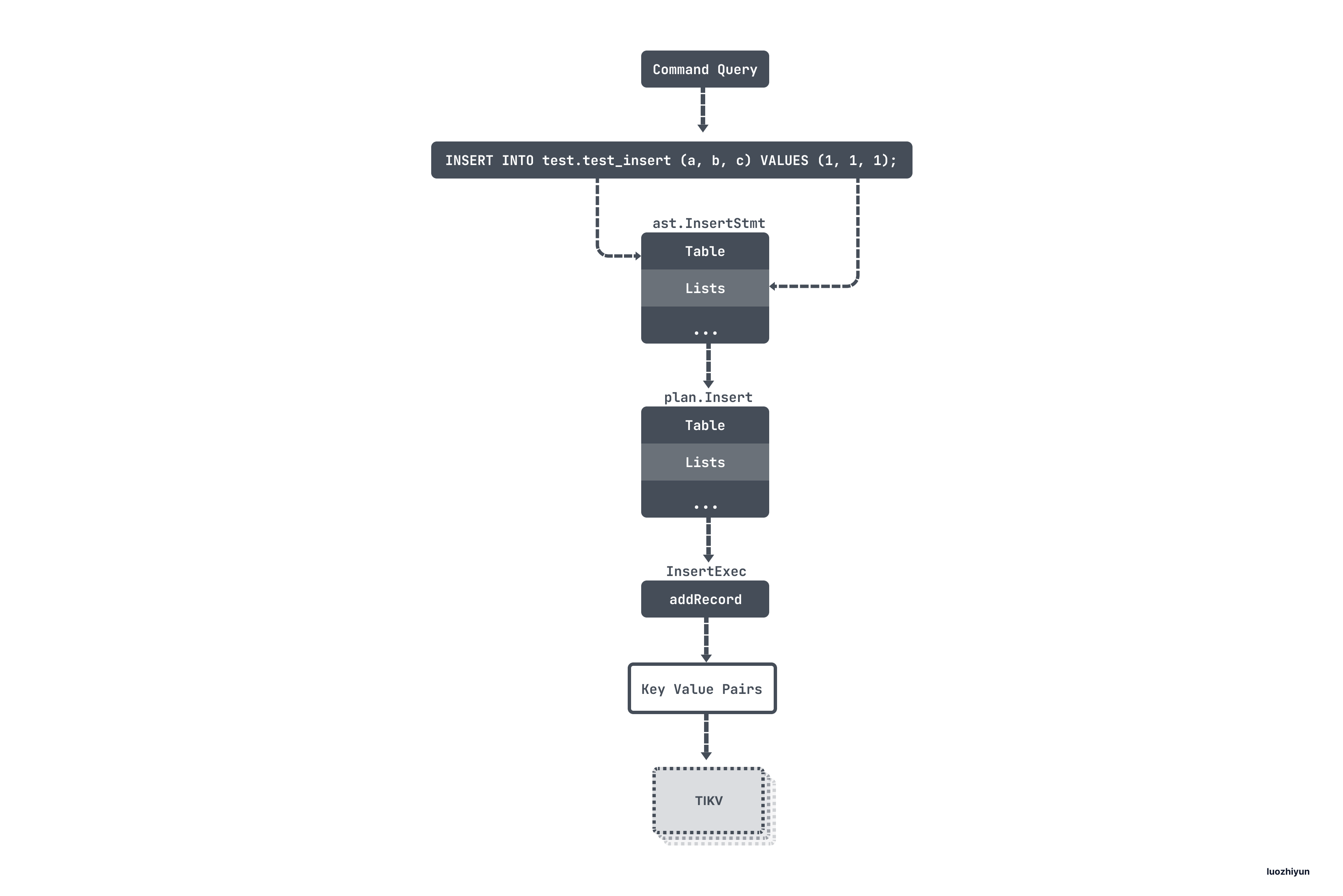
INSERT IGNORE
INSERT IGNORE和普通 Insert 不同的是当 INSERT 的时候遇到唯一约束冲突后,忽略当前 INSERT 的行,并记一个 warning。当语句执行结束后,可以通过 SHOW WARNINGS看到哪些行没有被插入。
为了实现这个目的又不影响性能,TiDB 通过 batchCheckAndInsert 批量检测来校验数据是否冲突:
func (e *InsertExec) exec(ctx context.Context, rows [][]types.Datum) error {
...
sessVars := e.ctx.GetSessionVars()
defer sessVars.CleanBuffers()
ignoreErr := sessVars.StmtCtx.DupKeyAsWarning
// 判断是否有 OnDuplicate 语句
if len(e.OnDuplicate) > 0 {
...
// 判断是否包含 IGNORE 语句
} else if ignoreErr {
// 判断是否重复,不重复则插入
err := e.batchCheckAndInsert(ctx, rows, e.addRecord)
if err != nil {
return err
}
// 普通 Insert
} else {
...
}
return nil
}在 InsertExec 的 exec 方法中如果 SQL 语句包含 IGNORE 会进入到 IF 判断的第二个分支中调用 batchCheckAndInsert 方法进行冲突校验。
func (e *InsertValues) batchCheckAndInsert(ctx context.Context, rows [][]types.Datum, addRecord func(ctx context.Context, row []types.Datum) error) error {
...
start := time.Now()
// 获取行数据中需要校验的key,如主键,唯一键
toBeCheckedRows, err := getKeysNeedCheck(ctx, e.ctx, e.Table, rows)
if err != nil {
return err
}
// 获取事务处理器
txn, err := e.ctx.Txn(true)
if err != nil {
return err
}
// 批量从 tikv 中根据传入的 key 获取数据,存入到缓存中
if _, err = prefetchUniqueIndices(ctx, txn, toBeCheckedRows); err != nil {
return err
}
for i, r := range toBeCheckedRows {
if r.ignored {
continue
}
skip := false
// 判断主键
if r.handleKey != nil {
// 从缓存中判断key是否存在,存在则重复
_, err := txn.Get(ctx, r.handleKey.newKey)
if err == nil {
e.ctx.GetSessionVars().StmtCtx.AppendWarning(r.handleKey.dupErr)
continue
}
if !kv.IsErrNotFound(err) {
return err
}
}
// 判断唯一键
for _, uk := range r.uniqueKeys {
// 从缓存中判断key是否存在,存在则重复
_, err := txn.Get(ctx, uk.newKey)
if err == nil {
// If duplicate keys were found in BatchGet, mark row = nil.
e.ctx.GetSessionVars().StmtCtx.AppendWarning(uk.dupErr)
skip = true
break
}
if !kv.IsErrNotFound(err) {
return err
}
}
// 没有冲突,调用 addRecord 添加数据
if !skip {
e.ctx.GetSessionVars().StmtCtx.AddCopiedRows(1)
err = addRecord(ctx, rows[i])
if err != nil {
return err
}
}
}
return nil
}这一段代码比较长,但是也很好理解。
- getKeysNeedCheck 作用是根据所有的 rows 数据封装好里面唯一键和主键的key,按照 TiKV 中存储的格式封装,我在上面普通 Insert 已经讲过了,这里就不再重复贴出 Key 的规则;
- prefetchUniqueIndices 是根据 toBeCheckedRows 里面封装好的 Key 通过 BatchGet 发送 RPC 请求批量去 TiKV 获取数据,然后存入到缓存中;
- 然后会遍历 toBeCheckedRows 这里面的主键和唯一键,通过
txn.Get从缓存中判断key是否存在,存在则重复; - 最后如果不冲突,那么会调用 addRecord 将数据缓存到本地事务中。
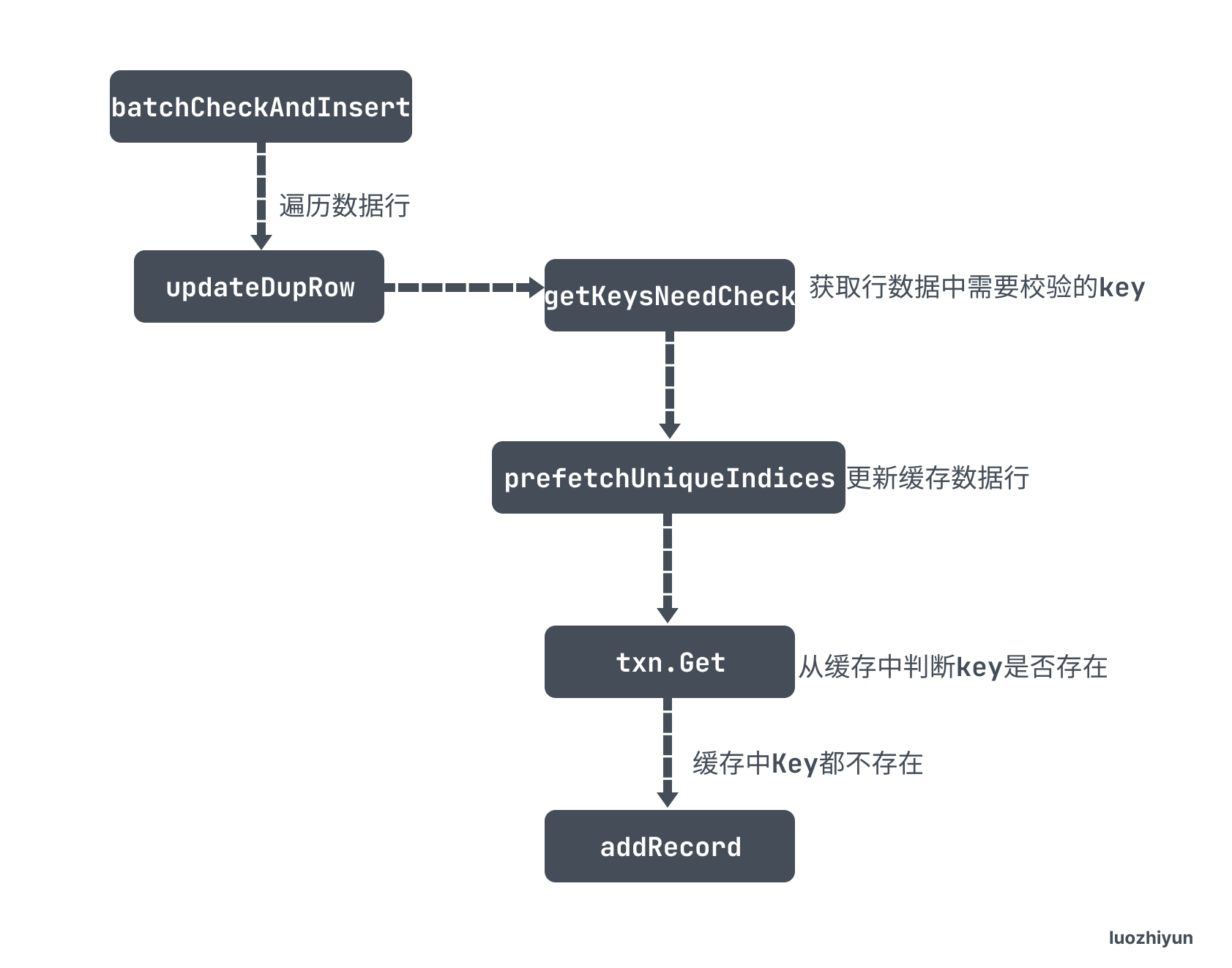
ON DUPLICATE
ON DUPLICATE 指的是INSERT ON DUPLICATE KEY UPDATE语句,它是几种 INSERT 语句中最为复杂的。其语义的本质是包含了一个 INSERT 和 一个 UPDATE。
它的入口在 InsertExec 执行 exec 方法的时候:
func (e *InsertExec) exec(ctx context.Context, rows [][]types.Datum) error {
...
sessVars := e.ctx.GetSessionVars()
defer sessVars.CleanBuffers()
ignoreErr := sessVars.StmtCtx.DupKeyAsWarning
// 判断是否有 OnDuplicate 语句
if len(e.OnDuplicate) > 0 {
err := e.batchUpdateDupRows(ctx, rows)
if err != nil {
return err
}
// 判断是否包含 IGNORE 语句
} else if ignoreErr {
...
// 普通 Insert
} else {
...
}
return nil
}与 INSERT IGNORE相同,首先会进入 IF 分支,判断是否包含 ON DUPLICATE执行语句,然后执行 batchUpdateDupRows 方法。
func (e *InsertExec) batchUpdateDupRows(ctx context.Context, newRows [][]types.Datum) error {
...
// 构造唯一键和主键的key
toBeCheckedRows, err := getKeysNeedCheck(ctx, e.ctx, e.Table, newRows)
if err != nil {
return err
}
txn, err := e.ctx.Txn(true)
if err != nil {
return err
}
// 根据key填充对应的缓存
if err = prefetchDataCache(ctx, txn, toBeCheckedRows); err != nil {
return err
}
for i, r := range toBeCheckedRows {
if r.handleKey != nil {
handle, err := tablecodec.DecodeRowKey(r.handleKey.newKey)
if err != nil {
return err
}
// 根据主键判断是否有冲突,如果有冲突 err 则为 nil
err = e.updateDupRow(ctx, i, txn, r, handle, e.OnDuplicate)
if err == nil {
continue
}
if !kv.IsErrNotFound(err) {
return err
}
}
// 如果主键没有冲突,那么判断唯一键是否有冲突
for _, uk := range r.uniqueKeys {
val, err := txn.Get(ctx, uk.newKey)
if err != nil {
if kv.IsErrNotFound(err) {
continue
}
return err
}
handle, err := tablecodec.DecodeHandleInUniqueIndexValue(val, uk.commonHandle)
if err != nil {
return err
}
err = e.updateDupRow(ctx, i, txn, r, handle, e.OnDuplicate)
if err != nil {
return err
}
newRows[i] = nil
break
}
// 如果主键和唯一键都没有冲突,那么执行正常插入逻辑
if newRows[i] != nil {
err := e.addRecord(ctx, newRows[i])
if err != nil {
return err
}
}
}
if e.stats != nil {
e.stats.CheckInsertTime += time.Since(start)
}
return nil
}batchUpdateDupRows 方法首先会构造唯一键和主键的 key ,然后调用 prefetchDataCache 方法根据 Key 值一次性获取 TiKV 对应值填充缓存。
之后遍历构造好的 toBeCheckedRows ,先调用 updateDupRow 方法判断主键判断是否有冲突,如果主键没有冲突,那么判断唯一键是否有冲突,都没有冲突则执行正常插入逻辑。

updateDupRow 会判断 Key 值在缓存中是否存在,存在则调用 doDupRowUpdate ;doDupRowUpdate 中会根据 ON DUPLICATE 中的字段更新新的数据行中的值,并将被更新过的字段打上 flag 之后调用 updateRecord 函数。
func updateRecord(ctx context.Context, sctx sessionctx.Context, h kv.Handle, oldData, newData []types.Datum, modified []bool, t table.Table,
onDup bool, memTracker *memory.Tracker) (bool, error) {
txn, err := sctx.Txn(false)
if err != nil {
return false, err
}
changed, handleChanged := false, false
...
for i, col := range t.Cols() {
// 这里是新旧数据进行比较,如果相同返回0
cmp, err := newData[i].CompareDatum(sc, &oldData[i])
if err != nil {
return false, err
}
//这里表明新旧数据不同
if cmp != 0 {
changed = true //设置标记位,表示有数据被修改
modified[i] = true
...
// 如果是主键更改,设置 handleChanged
if col.IsPKHandleColumn(t.Meta()) {
handleChanged = true
if err := rebaseAutoRandomValue(sctx, t, &newData[i], col); err != nil {
return false, err
}
}
// 如果是主键更改,设置 handleChanged
if col.IsCommonHandleColumn(t.Meta()) {
handleChanged = true
}
// 表示该字段没有被更改
} else {
if mysql.HasOnUpdateNowFlag(col.Flag) && modified[i] {
onUpdateSpecified[i] = true
}
modified[i] = false
}
}
// 如果数据行没有变化,直接返回
if !changed {
...
return false, nil
}
// 这里如果是主键被更改了,那么会先将原数据删除,再添加一条新的数据
if handleChanged {
if updated, err := func() (bool, error) {
txn, err := sctx.Txn(true)
if err != nil {
return false, err
}
memBuffer := txn.GetMemBuffer()
sh := memBuffer.Staging()
defer memBuffer.Cleanup(sh)
if err = t.RemoveRecord(sctx, h, oldData); err != nil {
return false, err
}
_, err = t.AddRecord(sctx, newData, table.IsUpdate, table.WithCtx(ctx))
if err != nil {
return false, err
}
memBuffer.Release(sh)
return true, nil
}(); err != nil {
if terr, ok := errors.Cause(err).(*terror.Error); sctx.GetSessionVars().StmtCtx.IgnoreNoPartition && ok && terr.Code() == errno.ErrNoPartitionForGivenValue {
return false, nil
}
return updated, err
}
} else {
// 更新记录行
if err = t.UpdateRecord(ctx, sctx, h, oldData, newData, modified); err != nil {
if terr, ok := errors.Cause(err).(*terror.Error); sctx.GetSessionVars().StmtCtx.IgnoreNoPartition && ok && terr.Code() == errno.ErrNoPartitionForGivenValue {
return false, nil
}
return false, err
}
}
...
return true, nil
}updateRecord 会判断行数据有没有被更改,如果有被更改,那么分为两种情况:
- 主键被更改了,那么会先将原数据删除,再添加一条新的数据;
- 唯一键被更改会调用 UpdateRecord 更新记录行;
func (t *TableCommon) UpdateRecord(ctx context.Context, sctx sessionctx.Context, h kv.Handle, oldData, newData []types.Datum, touched []bool) error {
txn, err := sctx.Txn(true)
if err != nil {
return err
}
memBuffer := txn.GetMemBuffer()
...
// 重建索引记录
err = t.rebuildIndices(sctx, txn, h, touched, oldData, newData, table.WithCtx(ctx))
if err != nil {
return err
}
// 构建行记录key
key := t.RecordKey(h)
sc, rd := sessVars.StmtCtx, &sessVars.RowEncoder
// 构建行记录value
value, err := tablecodec.EncodeRow(sc, row, colIDs, nil, nil, rd)
if err != nil {
return err
}
// 将数据添加到事务缓存中
if err = memBuffer.Set(key, value); err != nil {
return err
}
memBuffer.Release(sh)
...
return nil
}UpdateRecord 中执行的逻辑和 AddRecord 有点类似,首先会调用 rebuildIndices 将旧的索引记录删除,重新构建新的索引;然后根据当前的行记录构建 key-value 添加到事务缓存中。
最后用一张图总结一下这个过程:
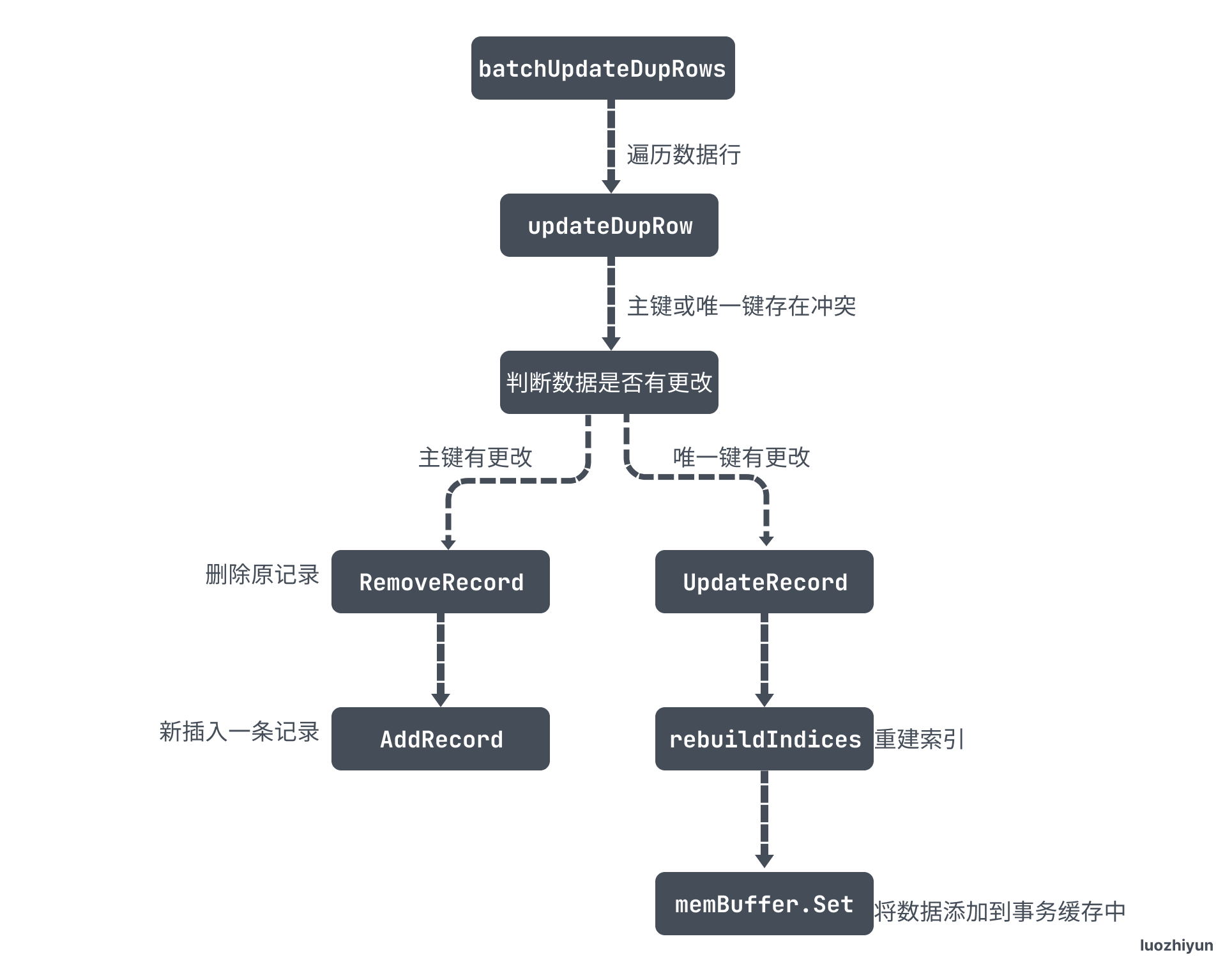
这篇文章 debug 用了蛮长时间的,想要弄清楚其中的逻辑非常不容易,但是还有一些地方没弄明白,如在执行 ON DUPLICATE会更新数据行,那么数据一致性怎么保证的?这些疑问我想到时候留给事务章节去弄明白。
Reference
https://pingcap.com/zh/blog/tidb-source-code-reading-4
https://pingcap.com/zh/blog/tidb-source-code-reading-16

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK