

❤️数据科学-Pandas、Numpy、Matplotlib秘籍之精炼总结
source link: https://blog.csdn.net/acceptedday/article/details/120150373
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

❤️数据科学-Pandas、Numpy、Matplotlib秘籍之精炼总结

先感受一下数据科学的魅力,上图是在Smart Dubai 2017 GITEX科技周展台上推出Smart Decision-Making Platform(智能决策平台),于10月8日至12日在迪拜世界贸易中心举行。游客可以通过一个“沉浸式的空间”将数据可视化,让他们了解迪拜的未来。让参观者可以在现场查阅观看全市数据,这意味着迪拜将成为了世界上第一个与公众分享实时实时数据的城市,同时还可以预测未来十年的发展。
最近,很多小伙伴在后台私信我,咨询有没有数据处理及可视化的相关系统教程?我的回复是,这些库只是工具,无需花费很长的时间牢记这些命令的使用,学习一遍之后整理好笔记即可,遗忘之时再查找这些笔记使用即可。
本文是博主本人结合自己的使用经验以及各大博主的分享精炼汇总而成,耗时进半个月的时候,翻阅博客和参考资料无数,最后精选了最实用、常用、好用的“Pandas、Numpy、Matplotlib”三大神兵利器的方法使用攻略。

Pandas精炼总结
1.属性值中存在缺失,将变量转换成Pandas可操作类型数据的方法
当某个属性数据中存在空值(NaN),则该属性数据类型为object,使用convert_dtypes()将Series转换为支持的dtypes。
1.convert_dtypes()处理DataFrame类型数据,示例如下:
# dataframe 变量类型自动转换
df = pd.DataFrame(
{
"a": pd.Series([1, 2, 3], dtype=np.dtype("int32")),
"b": pd.Series(["x", "y", "z"], dtype=np.dtype("O")),
"c": pd.Series([True, False, np.nan], dtype=np.dtype("O")),
"d": pd.Series(["h", "i", np.nan], dtype=np.dtype("O")),
"e": pd.Series([10, np.nan, 20], dtype=np.dtype("float")),
"f": pd.Series([np.nan, 100.5, 200], dtype=np.dtype("float")),
}
)
print(df.dtypes)
dfn = df.convert_dtypes()
print(dfn.dtypes)
2.convert_dtypes()处理Series变量类型数据,示例如下:
# Series 变量类型自动转换
s = pd.Series(["a", "b", np.nan])
print(s.dtypes)
sn = s.convert_dtypes()
print(sn.dtypes)
2.为数据表格添加颜色特性,实现更好可视化的方法
pandas可通过添加颜色条件,让表格数据凸显出统计特性。
import pandas as pd
df = pd.read_csv("test.csv")
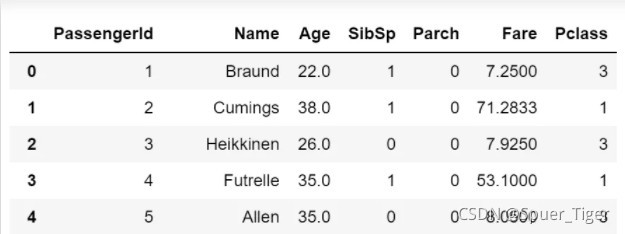
1.Fare变量值呈现条形图,以清楚看出各个值得大小比较,可直接使用bar,示例如下:
df.style.bar("Fare",vmin=0)

2.让Age变量呈现背景颜色的梯度变化,以体验映射的数值大小,那么可直接使用background_gradient,深颜色代表数值大,浅颜色代表数值小,示例如下:
df.style.background_gradient("Greens",subset="Age")

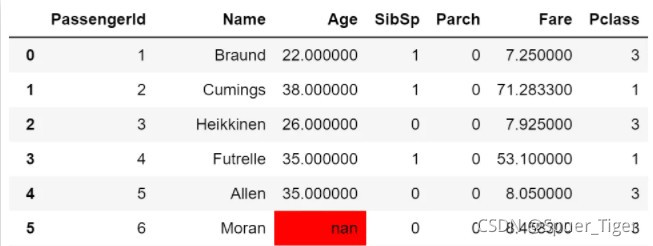
3.让所有缺失值都高亮出来,可使用highlight_null,示例如下:
df.style.highlight_null()
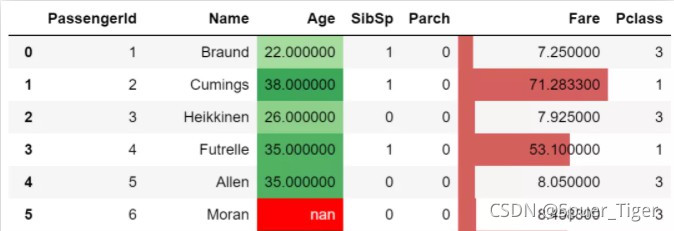
4.pandas的style条件格式,组合用法非常简单,示例如下:
df.style.bar("Fare",vmin=0).background_gradient("Greens",subset="Age").highlight_null()
3.Pandas中数值实现函数映射转换的方法
使用pd.transform(func,axis)函数:
func是指定用于处理数据的函数,它可以是普通函数、字符串函数名称、函数列表或轴标签映射函数的字典。axis是指要应用到哪个轴,0代表列,1代表行。
1.func=“普通函数”,示例如下:
df = pd.DataFrame({'A': [1,2,3], 'B': [10,20,30] })
def plus_10(x):
return x+10
df.transform(plus_10)
# df.transform(lambda x: x+10) 等价写法

2.func=“内置的字符串函数”,示例如下:
df = pd.DataFrame({'A': [1,2,3], 'B': [10,20,30] })
df.transform('sqrt')
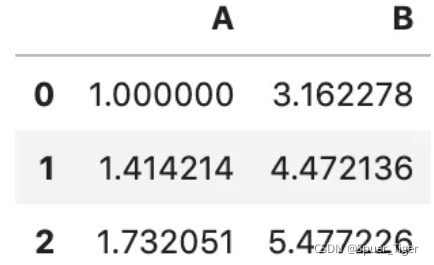
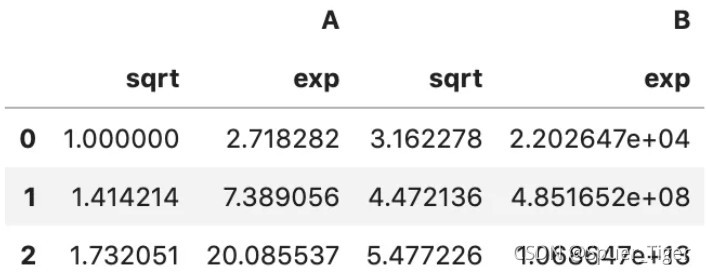
3.func=“多个映射函数”,示例如下:
df = pd.DataFrame({'A': [1,2,3], 'B': [10,20,30] })
df.transform([np.sqrt, np.exp])
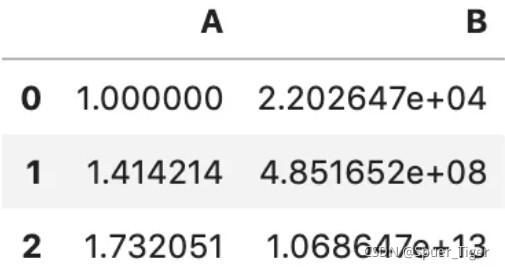
4.func=“指定轴位置的映射函数”,示例如下:
df = pd.DataFrame({'A': [1,2,3], 'B': [10,20,30] })
df.transform({
'A': np.sqrt,
'B': np.exp,
})
4.属性值中出现长列表或字符串形式的数据,实现分割处理的方法
工作中,比如用户画像的数据中也会遇到,客户使用的app类型就会以这种长列表的形式或者以逗号隔开的字符串形式展现出来。

1.使用explode()这个方法即可,一般我们会在后面跟一个去重的方法,explode()支持列表、元组、Series和numpy的ndarray类型数据,示例如下:
df.explode('爱好').drop_duplicates()

2.当长数据不是explode能够处理的数据类型时,使用Series.str.split()分割字符串的方法将其转换为列表格式后处理,然后再进行explode即可,示例如下:

df["爱好"] = df["爱好"].str.split()

df.explode('爱好').drop_duplicates()

5.DataFrame数据之间拼接的方法
源数据如下:
df1 = pd.DataFrame({
'name':['A','B','C','D'],
'math':[60,89,82,70],
'physics':[66, 95,83,66],
'chemistry':[61,91,77,70]
})
df2 = pd.DataFrame({
'name':['E','F','G','H'],
'math':[66,95,83,66],
'physics':[60, 89,82,70],
'chemistry':[90,81,78,90]
})
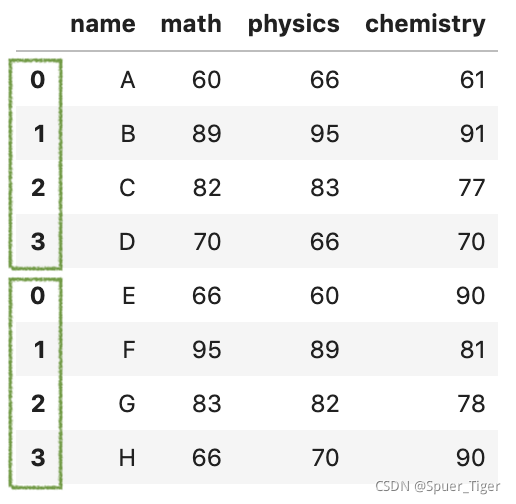
1.默认情况下,它是沿axis=0垂直连接的,并且默认情况下会保留df1和df2原来的索引。
pd.concat([df1,df2])
2.可以通过设置参数ignore_index=True,这样索引就可以从0到n-1自动排序了。
pd.concat([df1,df2],ignore_index = True)
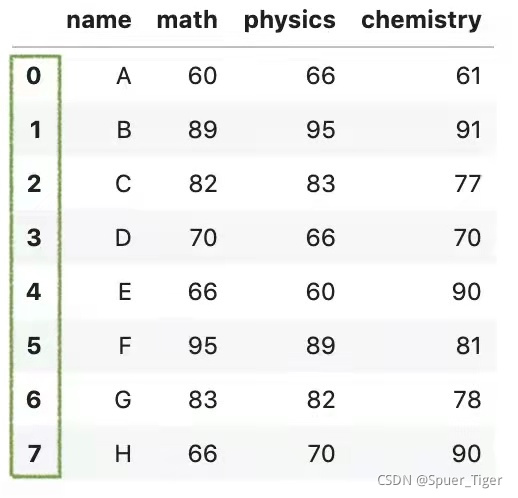
3.如果想要沿水平轴连接两个DataFrame,可以设置参数axis=1。
pd.concat([df1,df2],axis = 1)

4.可以通过设置参数verify_integrity=True,将此设置True为时,如果存在重复的索引,将会报错。
pd.concat([df1,df2], verify_integrity=True)

6.DataFrame数据转置的方法
dataframe都有的一个简单属性,实现转置功能。它在显示describe时可以很好的搭配。
boston.describe().T.head(10)

7.统计属性的数值分布频率的方法
在数据探索的时候,value_counts是使用很频繁的函数,它默认是不统计空值的,但空值往往也是我们很关心的。如果想统计空值,可以将参数dropna设置为False。
ames_housing = pd.read_csv("data/train.csv")
print(ames_housing["FireplaceQu"].value_counts(dropna=False, normalize=True))

8.Pandas替换异常值的方法
异常值检测是数据分析中常见的操作。使用clip函数可以很容易地找到变量范围之外的异常值,并替换它们。
age.clip(50, 60)
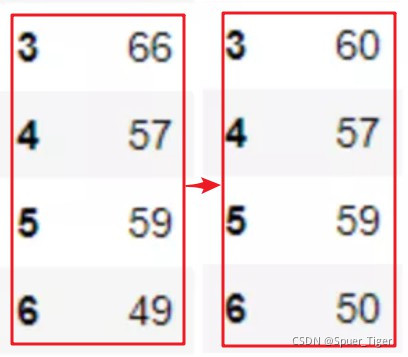
9.Pandas筛选数据的方法
源数据如下:
1.直接在dataframe的[]中写筛选的条件或者组合条件,示例如下:
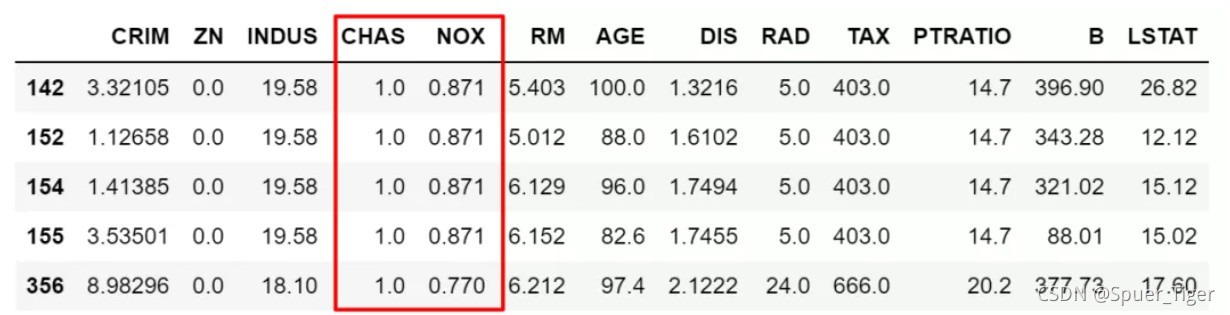
# 筛选出大于NOX这变量平均值的所有数据,然后按NOX降序排序。
df[df['NOX']>df['NOX'].mean()].sort_values(by='NOX',ascending=False).head()
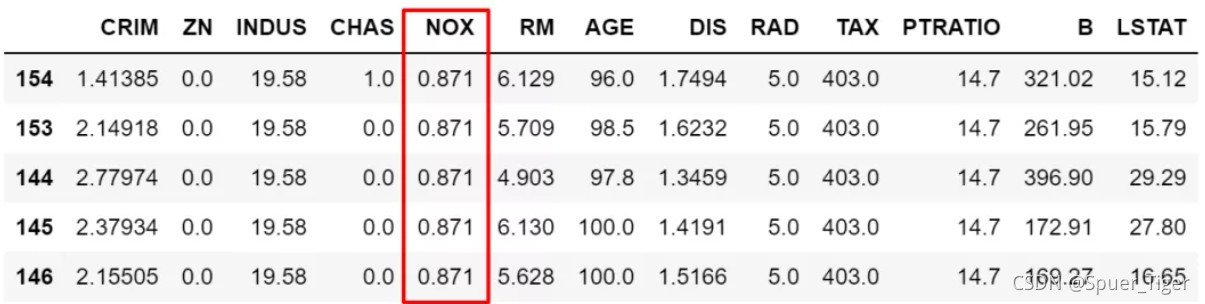
#筛选出大于NOX这变量平均值且CHAS属性值=1的所有数据,然后按NOX降序排序。
df[(df['NOX']>df['NOX'].mean())& (df['CHAS'] ==1)].sort_values(by='NOX',ascending=False).head()
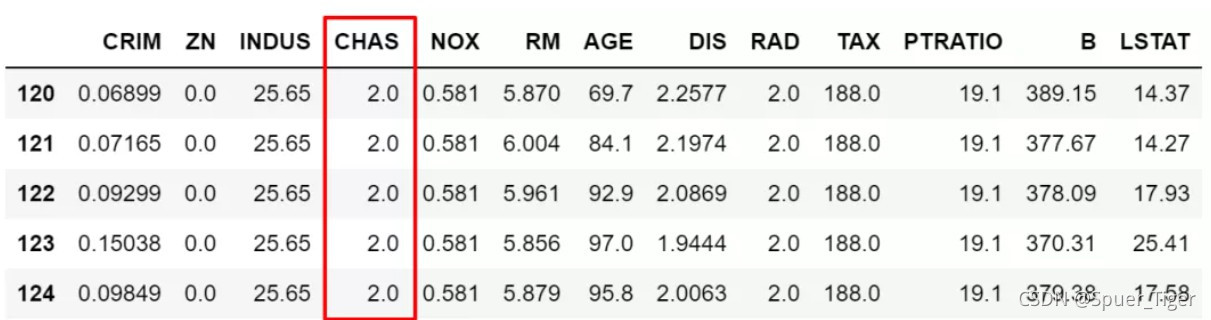
2.loc按标签值(列名和行索引取值)访问,iloc按数字索引访问,均支持单值访问或切片查询,loc还可以指定返回的列变量,示例如下:
# 按df['NOX']>df['NOX'].mean()条件筛选出数据,并筛选出指定CHAS变量,然后赋值=2
df.loc[(df['NOX']>df['NOX'].mean()),['CHAS']] = 2
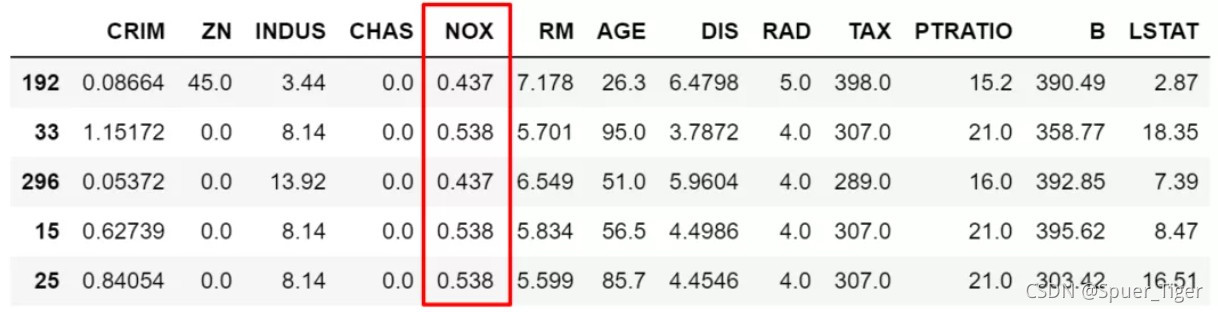
3.需要锁定某些具体的值的,这时候就需要isin了。比如我们要限定NOX取值只能为0.538,0.713,0.437中时,示例如下:
df.loc[df['NOX'].isin([0.538,0.713,0.437]),:].sample(5)
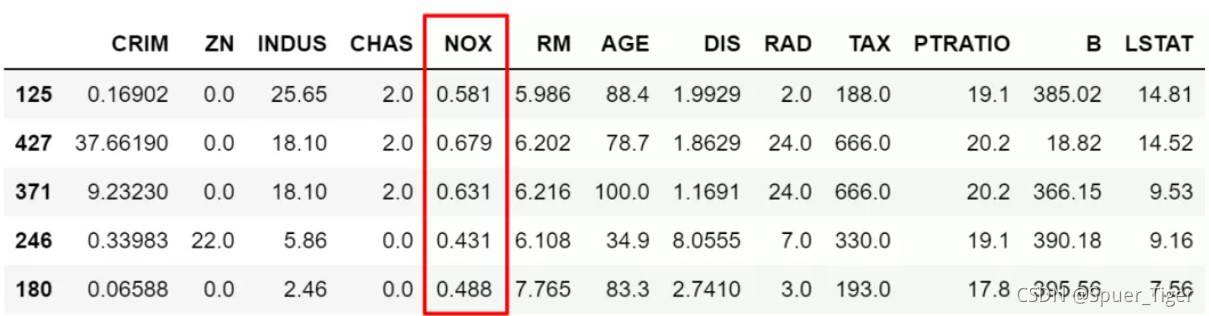
# 也可以做取反操作,在筛选条件前加`~`符号
df.loc[~df['NOX'].isin([0.538,0.713,0.437]),:].sample(5)
4.pandas里实现字符串的模糊筛选,可以用.str.contains()来实现,示例如下:
train.loc[train['Name'].str.contains('Mrs|Lily'),:].head()

10.DataFrame数据之间合并的方法
merge():对于拥有相同的键的两个DataFrame对象,需要将其进行有效的拼接,整合到一个对象。
def merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
主要参数介绍:
- left:DataFrame对象;
- right:DataFrame对象;
- how:
连接方式,inner或outer,默认是outer; - on:
指定用于连接的键,必须存在于左右两个DataFrame中; - left_on:左侧DataFrame中用于连接键的列名,当左右对象列名不同但含义相同时使用;
- right_on:右侧DataFrame中用于连接键的列名;
- left_index:
使用左侧DataFrame的行索引作为连接键(配合right_on); - right_index:使用右侧DataFrame的行索引作为连接键(配合left_on);
- sort:
对其按照连接键进行排序;
源数据为:
df1 = pd.DataFrame(np.random.randint(10, size=(3, 3)), columns=['A', 'B', 'C'])
df2 = pd.DataFrame(np.random.randint(10, size=(2, 2)), columns=['A', 'B'])


pd.merge(df1, df2, how='outer', on='B')

pd.merge(df1, df2, how='outer', left_on='B', right_on='A')

11.Pandas删除重复项的方法
1.drop_duplicates():删除对象dataframe中重复的行,重复通过参数subset指定。
def drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
主要参数介绍:
- subset:指定的键(列),
默认为所有的列(即每行全部相同); - keep:
删除重复项,除了第1个(first)或者最后一个(last); - inplace:是否直接对原来的对象进行修改,默认为False,生成一个拷贝`;
- ignore_index:是否重建索引;
df1 = pd.DataFrame(np.random.randint(10, size=(3, 3)), columns=['A', 'B', 'C'])
df1.drop_duplicates('A')
2.unique():相比于drop_duplicates方法,unique()只针对于Series对象,类似于Set。 通常是对dataframe中提取某一键,变成Series,再去重,统计个数。
print(len(df1['A'].unique().tolist()))
12.Pandas数据排序的方法
sort_values():按照某个键进行排序。 查看相同键时行的某些变化,如例子中在A相同时B、C的变化。
def sort_values(by, axis=0, ascending=True, kind='quicksort', na_position='last', ignore_index=False)
主要参数介绍:
- by:字符串或字符串列表,
指定按照哪个键/索引进行排序; - axis:指定排序的轴;
- ascending:升序或降序,
默认为升序; - kind:
指定排序方法,‘quicksort’, ‘mergesort’, ‘heapsort; - ignore_index:是否重建索引;
df1.sort_values(by='A')
13.Pandas数据采样的方法
sample():对对象进行采样。 当dataframe对象数据量太大,导致做实验过满时,可以抽取一部分进行实验,提高效率。
def sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
主要参数介绍:
- n:指定采样的数量;
- frac:指定采样的比例,与n只能选择其中一个;
- replace:
允许或不允许对同一行进行多次采样; - weights:
采样的权重,默认为“None”将导致相同的概率权重; - random_state:类似于seed作用;
- axis:
指定采样的轴,默认为行;
df1.sample(n=3)

df1.sample(frac=0.1)

14.Pandas判断和删除缺失值的方法
1.isna():isna方法返回一个布尔对象,每个元素是否为NaN。
df1.isna()

2.isnull():当数据量很大时,上述很难观察到某列是否存在缺失,此时可以用isnull()方法 。
df1.isnull().all() # 某列是否全部为NaN
df1.isnull().any() # 某列是否出现NaN
3.dropna():dropna方法删除含缺失值的行或列。
def dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
主要参数介绍:
- axis:指定轴;
- how:
参数为any时,行或列(axis决定)出现NaN时,就进行删除;为all时,行或列全为NaN时才进行删除; - thresh:阈值,要求不为NAN的个数;
- subset:
指定键(列)进行判断NAN删除; - inplace:
是否更改原对象;
df1.dropna(how='any', subset=['B'])

15.Pandas指定条件下值替换的方法
where():通过布尔序列选择一个返回的子集。对对象进行筛选,并且对于不满足的值,where方法可以对其进行替换。
例如若列为性别,元素为字符串,可将其进行替换为数值。
# 写法一
df1.where(df1 > 3, -1)
# 写法二
df1[df1.A <= 3] = -1

Numpy精炼总结
1.Numpy统计频数的方法
bincount()方法:计算非负整数数组中每个值出现的次数。返回一个输入数组的桶装(binning)结果。
numpy.bincount(x, weights=None, minlength=0)
参数介绍:
- x:1维的
非负整数数组; - weights:与x相同维度的权重数组;
- minlength:输出数组的最小桶数(bins);当行并未出现最大的值时,就可以指定该参数;
# 统计从0~max值的整数出现的频数
np.bincount([1,2,3,4,5,1,1,1,5,4])
# 设置每个值的权重,最终的频数由数据对应的权重相加得到
np.bincount([1,2,3,4,5,1,1,1,5,4], weights=[0.1,0.2,0.3,0.4,0.5,0.1,0.2,0.3,0.4,0.5])
# 指定输出数组的最小长度
np.bincount([1], minlength=4)
2.Numpy数组之间连接合并的方法
1.np.r_[]/np.c_[]分别为沿行/列进行连接,指定r /``c`可指定连接后数据的输出格式。数据挖掘中,最常用的就是为某个多维数组添加一行样本,或一列特征。
# 沿着行连接
np.r_[np.array([1,2,3]), np.array([4,5,6])]
# 沿着列连接
np.c_[np.array([[1,2], [3,7], [8, 9]]), np.array([4,5,6])]
# 沿着行连接,按行输出
np.r_['r', np.array([1,2,3]), np.array([4,5,6])]
# 沿着列连接,按列输出
np.r_['c', np.array([1,2,3]), np.array([4,5,6])]
2.np.concatenate(),它沿现有轴连接数组序列,它一次能实现多个数组拼接。
numpy.concatenate((a1, a2, ...), axis=0, out=None)
参数介绍:
- (a1, a2, …):数组序列,数组必须具有相同的形状,除了与axis对应的维度(默认情况下是第一个维度)。
- axis:整数,指定拼接的轴;若为None,则是将其展平为向量。
a = np.array([[1, 2],[3, 4]])
b = np.array([[5, 6]])
# 按数组的第一层数据拼接
np.concatenate((a, b), axis=0)
# 按数组的第二层数据拼接
np.concatenate((a, b.T), axis=1)
# 按数组最内层的数据元素依次拼接并返回一维数组
np.concatenate((a, b), axis=None)
3.Numpy生成随机数的方法
生成随机数的方法在数据挖掘中是必不可少的,在Numpy中,最常使用的有四种方法:np.random.rand()【返回一个0~1的均匀样本】、np.random.randint()【返回随机整数的均匀样本】、np.random.randn()【返回一个标准正态分布的样本】和np.random.normal()【返回一个标准正态分布的样本】。
1.np.random.rand():返回一个给定形状的使用[0, 1)的均匀分布的数组。
numpy.random.rand(d0, d1, ..., dn)
参数介绍:
- d0, d1, …, dn:返回数组的维度,必须非负。
若没有该参数,则返回单一随机值;
np.random.rand(2,2)

2.np.random.randint():返回从低(含)到高(不含)的随机整数。在半开区间从指定的dtype的离散均匀分布中返回随机整数,如果high为None(缺省值),则结果来自[0,low)。
numpy.random.randint(low, high=None, size=None, dtype=int)
参数介绍:
- low:整数或整数数组,指定下界。
若high=None,则为上界,即范围为[0, low); - high:整数或整数数组,指定上界(不取);
- size:整数或为一个整数元组(tuple),即定义的输出形状,
若为None,则返回一个单一随机值; - dtype:定义结果类型;
np.random.randint(5, size=(2, 2))

np.random.randint(2, 3, size=5)

3.np.random.randn():从标准正态分布中返回一个(或多个)样本。
numpy.random.randn(d0, d1, ..., dn)
参数介绍:
- d0, d1, …, dn:返回数组的维度,必须非负。若没有该参数,则返回单一随机值;
np.random.randn(2, 2)

4.numpy.random.normal():从正态(高斯)分布中随机抽取样本,默认为标准正态分布。
numpy.random.normal(loc=0.0, scale=1.0, size=None)
参数介绍:
- loc:float,分布的平均值;
- scale:float,分布的标准差,必须是非负数;
- size:整数或元组,输出形状。为None返回单一随机值;
mu, sigma = 0, 0.1 # mean and standard deviation
s = np.random.normal(mu, sigma, 1000)
4.Numpy数据排序的方法
Numpy中排序函数分为两种,一种是返回排序后的数组np.sort(),另一种为返回排序后的索引数组np.argsort()。
1.np.sort():Numpy中排序操作,通用函数为np.sort(),它返回一个被排序的数组。
numpy.sort(a, axis=-1, kind=None, order=None)
参数介绍:
- a:被排序的数组;
- axis:指定排序的轴,默认值为-1,则按照最后一个轴;
- kind:排序算法,默认为
quicksort,另外还有:mergesort、heapsort、stable; - order:字符串或字符串列表。a是一个定义了字段的数组时,这个参数指定首先比较哪个字段,然后比较哪个字段。
a = np.array([[1,4],
[3,1]])
np.sort(a)

a = np.array([[1,4],
[3,1]])
np.sort(a, axis=0)

a = np.array([[1,4],
[3,1]])
np.sort(a, axis=None)

2.np.argsort():返回将对数组排序的索引。通过获得索引可以指定数组按某行/列进行排序。
numpy.argsort(a, axis=-1, kind=None, order=None)
参数介绍:
- a:排序数组;
- axis:默认-1,即按最后一个轴排序;如果为None,则展平为向量;
- kind:排序算法,默认为
quicksort; - order:同
np.sort();
# axis=0,对x按列进行排序,小的在上面,大的在下面(升序)
x = np.array([[0, 3], [2, 2], [4, -1]])
np.argsort(x, axis=0)

# axis=0,对x按行进行排序,小的在左边,大的在右边(升序)
x[np.argsort(x, axis=0)[:,1]]

# 按第二列进行降序排序,添加一个负号即可(降序)
x[np.argsort(-x, axis=0)[:,1]]

5.Numpy多维数组展平的方法
np.flatten():这是在数据挖掘中非常常用的方法,有时得到一个N*1矩阵,经常将其转化为向量进行后续操作。类似方法还有ravel()。
ndarray.flatten(order='C')
参数介绍:
- order:{‘C’, ‘F’, ‘A’, ‘K’},默认为C,以行进行展平;F以列进行展平;【最主要就是这两个】
a = np.array([[1,2], [3,4]])
a.flatten('F')

6.Numpy改变多维素组的形状的方法
np.reshape() :主要用法是来改变维度(增删)。
numpy.reshape(a, newshape, order='C')
参数介绍:
- 改变形状的数组;
- 整数或元组,新的形状。若元组最后一个数为
-1,则表示最后一个维度是进行计算推断得出; - order:“C” 简单来讲就是横着读,横着写,优先读/写一行;“F” 竖着读,竖着写,优先读/写一列;默认是"C"。
a = np.array([[5,1,1],
[8,5,6],
[3,1,3],
[7,6,8]])
r1=a.reshape((3,4),order='C')

r2=a.reshape((3,4),order='F')

7.构造全0/1/Null数组的方法
1.np.zeros():返回填充为0的数组。
numpy.zeros(shape, dtype=float, order='C')
参数介绍:
- shape:
整数或元组,新数组的shape; - dtype:定义数组类型,默认为
np.float64; - order:同上,含
C、F;
np.zeros(5)

np.zeros((2, 2))

2.np.zeros_like():返回与某数组类型相同维度的全零数组。
numpy.zeros_like(a, dtype=None, order='K', subok=True, shape=None
主要参数介绍:
- a:
所参照该形状的数组; - dtype:
定义数组类型;
x = np.arange(6).reshape((2, 3))
np.zeros_like(x)

3.np.empty():用于创建空数组。
a=np.empty(2,3)#数据全为empty,3行4列
8.构造指定类型和区间的数组的方法
1.np.arange():用array创建连续数组。
a = np.arange(1,10,2)# 创建1到10的数据,步长=2
2.np.linspace():用linspace创建线段形数据。
a = np,linspace(1,10,20) #开始端1,结束端10,分割成20个等间距的数据
9.取最大/小值、平均值等常用参数值的方法
1.np.max():取最大值。
a = np.array([[1,2],[3,4]])
max = np.max(a,axis=0)
2.np.min():取最小值。
min = np.min(a,axis=1)
3.np.mean():取矩阵的平均值。
mean = np.mean(a)
4.np.argmax():取矩阵中最大元素的索引。
max_index = np.argmax(a)
5.np.argmin():取矩阵中最小元素的索引。
min_index = np.ragmin(a)
10.Numpy数组之间的运算法则的使用方法
1.加减法的计算:数组对应位置的元素相加减计算得到。
# 两个数组,维度相同
a = np.array([10, 20, 30, 401])
b = np.arange (4)
c = a+b
c1 = a-b

# 两个数组,维度不同(通过Numpy的广播机制实现计算)
aa = np.array([[1, 2, 3, 4],[11,22,33,44]])
bb = np.arange (4)
c = aa+bb

2.乘除法的计算:数组对应位置的元素乘除计算得到。
d = np.array([[1, 2],
[3, 4]])
e = np.arange(1, 8, 2).reshape((2, 2))
f = d*e #对应元素相乘
g = d/e #对应元素相除,因为是int64类型所以类似于2/3=0

3.平方、三角函数的计算:数组对应位置的元素进行计算得到。
a = np.array([10, 20, 30, 40])
b = np.arange(4)
c2 = b**2 # 平方
c3 = 10*np.sin(a) # sin函数

4.逻辑运算:数组对应位置的元素进行逻辑运算得到。
c4 = b<3
c5 = b==3

5.矩阵相乘:采用线性代数中的矩阵乘法规则进行运算得到。
d = np.array([[1, 2],[3, 4]])
e = np.arange(1, 8, 2).reshape((2, 2))
np.dot(d, e) # 等价于d.dot(e)

11.Numpy数组属性方法总结
Matplotlib精炼总结
【Tips】:建议使用Matplotlib的时候,采用Notebook以获得更好的可视化交互效果。
1.Matlpoylib绘制图形属性的基础方法
1.添加标题-title,matplotlib.pyplot 对象中有个 title() 可以设置表格的标题。
import numpy as np
import matplotlib.pyplot as plt
# 显示中文
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline
x=np.arange(0,10)
plt.title('这是一个示例标题')
plt.plot(x,x*x)
plt.show()
2.添加文字-text,设置坐标和文字,可以使用 matplotlib.pyplot 对象中 text() 接口。其中第一、二个参数来设置坐标,第三个参数是设置显示文本内容。
import numpy as np
import matplotlib.pyplot as plt
# 显示中文
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline
x=np.arange(-10,11,1)
y=x*x
plt.plot(x,y)
plt.title('这是一个示例标题')
# 添加文字
plt.text(-2.5,30,'function y=x*x')
plt.show()
3.添加注释-annotate,annotate() 接口可以在图中增加注释说明其中:
- xy 参数:
备注的坐标点 - xytext 参数:
备注文字的坐标(默认为xy的位置) - arrowprops 参数:
在 xy 和 xytext 之间绘制一个箭头
import numpy as np
import matplotlib.pyplot as plt
# 显示中文
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline
x=np.arange(-10,11,1)
y=x*x
plt.title('这是一个示例标题')
plt.plot(x,y)
# 添加注释
plt.annotate('这是一个示例注释',xy=(0,1),xytext=(-2,22),arrowprops={'headwidth':10,'facecolor':'r'})
plt.show()
4.设置坐标轴名称-xlabel/ylabel,二维坐标图形中,需要在横轴和竖轴注明名称以及数量单位。设置坐标轴名称使用的接口是 xlabel() 和 ylable()。
import numpy as np
import matplotlib.pyplot as plt
# 显示中文
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline
x=np.arange(1,20)
plt.xlabel('示例x轴')
plt.ylabel('示例y轴')
plt.plot(x,x*x)
plt.show()
5.添加图例-legend,当线条过多时,我们设置不同颜色来区分不同线条。因此,需要对不同颜色线条做下标注,我们实用 legend() 接口来实现。
import numpy as np
import matplotlib.pyplot as plt
# 显示中文
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline
plt.plot(x,x)
plt.plot(x,x*2)
plt.plot(x,x*3)
plt.plot(x,x*4)
# 直接传入legend
plt.legend(['生活','颜值','工作','金钱'])
plt.show()
6.调整颜色-color,传颜色参数,使用 plot() 中的 color 属性来设置,color 支持以下几种方式。
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
x=np.arange(1,5)
#颜色的几种方式
plt.plot(x,color='g')
plt.plot(x+1,color='0.5')
plt.plot(x+2,color='#FF00FF')
plt.plot(x+3,color=(0.1,0.2,0.3))
plt.show()

7.切换线条样式-marker,如果想改变线条的样式,我们可以使用修改 plot() 绘图接口中 mark 参数,具体实现效果:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
x=np.arange(1,5)
plt.plot(x,marker='o')
plt.plot(x+1,marker='>')
plt.plot(x+2,marker='s')
plt.show()
其中 marker 支持的类型:

8.显示网格-grid,grid() 接口可以用来设置背景图为网格。
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
x='a','b','c','d'
y=[15,30,45,10]
plt.grid()
# 也可以设置颜色、线条宽度、线条样式
# plt.grid(color='g',linewidth='1',linestyle='-.')
plt.plot(x,y)
plt.show()
9.调整坐标轴刻度-locator_params,坐标图的刻度我们可以使用 locator_params 接口来调整显示颗粒。
-
同时调整 x 轴和 y 轴:
plt.locator_params(nbins=20) -
只调整 x 轴:
plt.locator_params(‘'x',nbins=20) -
只调整 y 轴:
plt.locator_params(‘'y',nbins=20)
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
x=np.arange(0,30,1)
plt.plot(x,x)
# x轴和y轴分别显示20个
plt.locator_params(nbins=20)
plt.show()

10.调整坐标轴范围-axis/xlim/ylim,分别如下:
-
axis:[0,5,0,10],x从0到5,y从0到10
-
xlim:对应参数有xmin和xmax,分别能调整最大值最小值
-
ylim:同xlim用法
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
x=np.arange(0,30,1)
plt.plot(x,x*x)
#显示坐标轴,plt.axis(),4个数字分别代表x轴和y轴的最小坐标,最大坐标
#调整x为10到25
plt.xlim(xmin=10,xmax=25)
plt.plot(x,x*x)
plt.show()
11.调整日期自适应-autofmt_xdate,有时候显示日期会重叠在一起,非常不友好,调用plt.gcf().autofmt_xdate(),将自动调整角度。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
x=pd.date_range('2020/01/01',periods=30)
y=np.arange(0,30,1)
plt.plot(x,y)
plt.gcf().autofmt_xdate()
plt.show()
12.切换样式-plt.style.use,matplotlib支持多种样式,可以通过plt.style.use切换样式,例如:plt.style.use(‘ggplot’)输入plt.style.available 可以查看所有的样式。
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mptaches
%matplotlib inline
plt.style.use('ggplot')
# 新建4个子图
fig,axes=plt.subplots(2,2)
ax1,ax2,ax3,ax4=axes.ravel()
# 第一个图
x,y=np.random.normal(size=(2,100))
ax1.plot(x,y,'o')
# 第二个图
x=np.arange(0,10)
y=np.arange(0,10)
colors=plt.rcParams['axes.prop_cycle']
length=np.linspace(0,10,len(colors))
for s in length:
ax2.plot(x,y+s,'-')
# 第三个图
x=np.arange(5)
y1,y2,y3=np.random.randint(1,25,size=(3,5))
width=0.25
ax3.bar(x,y1,width)
ax3.bar(x+width,y2,width)
ax3.bar(x+2*width,y3,width)
# 第四个图
for i,color in enumerate(colors):
xy=np.random.normal(size=2)
ax4.add_patch(plt.Circle(xy,radius=0.3,color=color['color']))
ax4.axis('equal')
plt.show()

2.Matplotlib绘制2D、3D线形图的方法
线形图的意义是观察数据的变化特征,使用之前请务必明确这一点!
1.绘制2D折线图的方法:
首先,将需要的包载入到 notebook 中:
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
import numpy as np
然后,需要从创建图形和维度开始,图形和维度可以使用下面规则进行创建:
- plt.figure():在 Matplotlib 中,图形(类
plt.Figure的一个实例)可以被认为是一个包括所有维度、图像、文本和标签对象的容器。 - plt.axes():维度(类
plt.Axes的一个实例)就是一个有边界的格子包括刻度和标签,最终还有我们画在上面的图表元素。 - plt.plot():将数据绘制在图表上,通过指定
color关键字参数可以调整颜色(color=‘blue’ 、‘g’ 、’#FFDD44’、‘0.75’),通过linestyle关键字参数可以指定线条的风格。 - plt.xlim(xmin, xmax):
调整x坐标轴的范围。 - plt.ylim(ymin, ymax):
调整y坐标轴的范围。 - plt.axis([xmin, xmax, ymin, ymax]):可以在一个函数调用中就
完成 x 轴和 y 轴范围的设置。 - plt.xlabel():
设置x坐标轴的标签。 - plt.ylabel():
设置y坐标轴的标签。
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-np.pi, np.pi, 100)
y = np.sin(x)
linear_y = 0.2 * x + 0.1
plt.figure(figsize = (8, 6))
plt.plot(x, y)
plt.plot(x, linear_y, color = "red", linestyle = '--')
plt.title('y = sin(x) and y = 0.2x + 0.1')
plt.xlabel('x')
plt.ylabel('y')
plt.xlim(-np.pi, np.pi)
plt.ylim(-1, 1)
# plt.xticks(np.linspace(-np.pi, np.pi, 5))
x_value_range = np.linspace(-np.pi, np.pi, 5)
x_value_strs = [r'$\pi$', r'$-\frac{\pi}{2}$', r'$0$', r'$\frac{\pi}{2}$', r'$\pi$']
plt.xticks(x_value_range, x_value_strs)
ax = plt.gca() # 获取坐标轴
ax.spines['right'].set_color('none') # 隐藏上方和右方的坐标轴
ax.spines['top'].set_color('none')
# 设置左方和下方坐标轴的位置
ax.spines['bottom'].set_position(('data', 0)) # 将下方的坐标轴设置到y = 0的位置
ax.spines['left'].set_position(('data', 0)) # 将左方的坐标轴设置到 x = 0 的位置
plt.show() # 显示图像
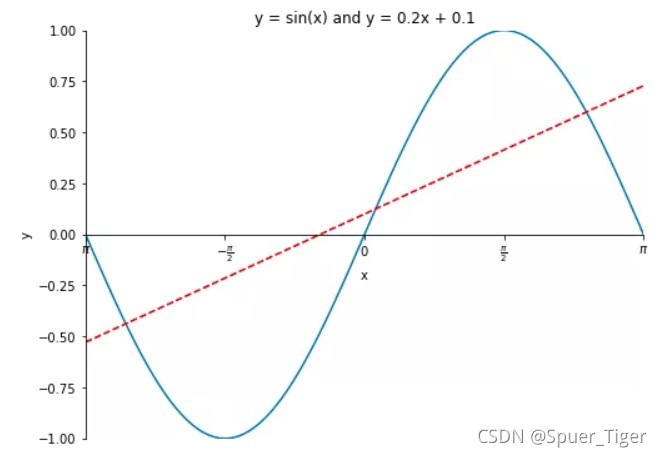
2.绘制3D折线图的方法:
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure()
ax = plt.axes(projection='3d')
theta = np.linspace(-4 * np.pi, 4 * np.pi, 100)
z = np.linspace(-2, 2, 100)
r = z ** 2 + 1
x = r * np.sin(theta)
y = r * np.cos(theta)
ax.plot(x, y, z)
mpl_toolkits.mplot3d.art3d.Line3D object at 0x095412C8>]
plt.show()

3.Matplotlib绘制2D、3D散点图的方法
散点图的意义是观察不同数据的分布特征,使用之前请务必明确这一点!
1.绘制2D散点图的方法:
不像折线图,图中的点连接起来组成连线,散点图中的点都是独立分布的点状、圆圈或其他形状。首先将需要用到的图表工具和函数导入到 notebook 中:
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
import numpy as np
绘制散点图的方法是使用plt.scatter函数,它的使用方法和plt.plot类似:
plt.scatter(x, y, marker='o')
为了更好的查看重叠的结果,还可以使用alpha关键字参数对点的透明度进行了调整,如果(x,y)隶属不同的类别,那么可通设定对应的colors数组进行不同类别颜色的配置:
import numpy as np
import matplotlib.pyplot as plt
N = 50
x = np.random.rand(N)
y = np.random.rand(N)
colors = np.random.rand(N)
area = np.pi * (15 * np.random.rand(N))**2
plt.scatter(x, y, s = area,c = colors, alpha = 0.8)
plt.show()
有的时候柱状图会出现在x轴的俩侧,方便进行比较,代码实现如下:
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize = (16, 12))
n = 12
x = np.arange(n) # 按顺序生成从12以内的数字
y1 = (1 - x / float(n)) * np.random.uniform(0.5, 1.0, n)
y2 = (1 - x / float(n)) * np.random.uniform(0.5, 1.0, n)
# 设置柱状图的颜色以及边界颜色
#+y表示在x轴的上方 -y表示在x轴的下方
plt.bar(x, +y1, facecolor = '#9999ff', edgecolor = 'white')
plt.bar(x, -y2, facecolor = '#ff9999', edgecolor = 'white')
plt.xlim(-0.5, n) # 设置x轴的范围,
plt.xticks(()) # 可以通过设置刻度为空,消除刻度
plt.ylim(-1.25, 1.25) # 设置y轴的范围
plt.yticks(())
# plt.text()在图像中写入文本,设置位置,设置文本,ha设置水平方向对其方式,va设置垂直方向对齐方式
for x1, y in zip(x, y2):
plt.text(x1, -y - 0.05, '%.2f' % y, ha = 'center', va = 'top')
for x1, y in zip(x, y1):
plt.text(x1, y + 0.05, '%.2f' % y, ha = 'center', va = 'bottom')
plt.show()

2.绘制3D散点图的方法:
fig = plt.figure()
ax = plt.axes(projection='3d')
for mark,start, end in (['o', 10, 20], ['^', 5, 30]):
xs = np.random.choice(np.arange(23, 32), 50)
ys = np.random.choice(np.arange(0, 100), 50)
zs = np.random.choice(np.arange(start, end), 50)
ax.scatter(xs, ys, zs, marker=mark)
plt.show()
4.Matplotlib绘制2D、3D直方图的方法
线形图的意义是观察不同属性值的统计频率特征,使用之前请务必明确这一点!
1.绘制2D直方图的方法:
首先需要将需要用的包导入 notebook:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
data = np.random.randn(1000)
1.1绘制单图的情况:
plt.hist(data)
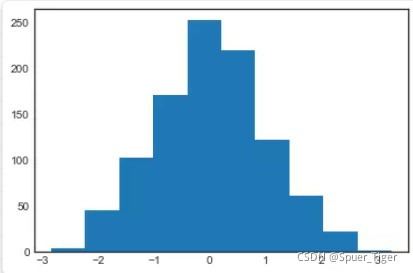
1.2绘制多图的情况:
x1 = np.random.normal(0, 0.8, 1000)
x2 = np.random.normal(-2, 1, 1000)
x3 = np.random.normal(3, 2, 1000)
kwargs = dict(histtype='stepfilled', alpha=0.3, density=True, bins=40)
plt.hist(x1, **kwargs)
plt.hist(x2, **kwargs)
plt.hist(x3, **kwargs)
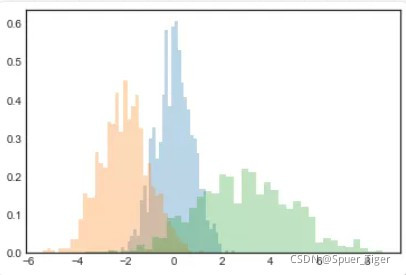
1.3如果只是需要计算直方图的数值(即每个桶的数据点数量)而不是展示图像,np.histogram()函数可以完成这个目标:
counts, bin_edges = np.histogram(data, bins=5)
print(counts)
2.绘制3D柱状图的方法:
fig = plt.figure()
ax = plt.axes(projection='3d')
yticks = [3, 2, 1]
for i in yticks:
x = np.arange(10)
y = np.random.rand(10)
ax.bar(x, y, zs=i, zdir='y')
plt.show()
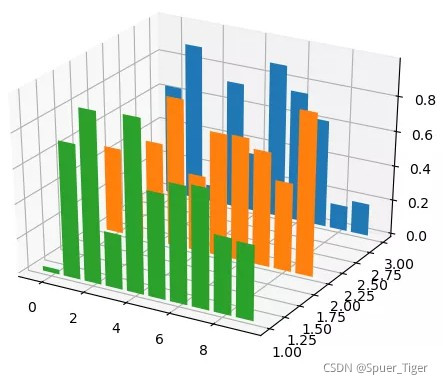
5.Matplotlib绘制2D、3D饼图的方法
1.绘制2D饼图的方法:
from matplotlib import pyplot as plt
#调节图形大小,宽,高
plt.figure(figsize=(6,9))
#定义饼状图的标签,标签是列表
labels = [u'第一部分',u'第二部分',u'第三部分']
#每个标签占多大,会自动去算百分比
sizes = [60,30,10]
colors = ['red','yellowgreen','lightskyblue']
#将某部分爆炸出来, 使用括号,将第一块分割出来,数值的大小是分割出来的与其他两块的间隙
explode = (0.05,0,0)
patches,l_text,p_text = plt.pie(sizes,explode=explode,labels=labels,colors=colors,
labeldistance = 1.1,autopct = '%3.1f%%',shadow = False,
startangle = 90,pctdistance = 0.6)
#labeldistance,文本的位置离远点有多远,1.1指1.1倍半径的位置
#autopct,圆里面的文本格式,%3.1f%%表示小数有三位,整数有一位的浮点数
#shadow,饼是否有阴影
#startangle,起始角度,0,表示从0开始逆时针转,为第一块。一般选择从90度开始比较好看
#pctdistance,百分比的text离圆心的距离
#patches, l_texts, p_texts,为了得到饼图的返回值,p_texts饼图内部文本的,l_texts饼图外label的文本
#改变文本的大小
#方法是把每一个text遍历。调用set_size方法设置它的属性
for t in l_text:
t.set_size=(30)
for t in p_text:
t.set_size=(20)
# 设置x,y轴刻度一致,这样饼图才能是圆的
plt.axis('equal')
plt.legend()
plt.show()
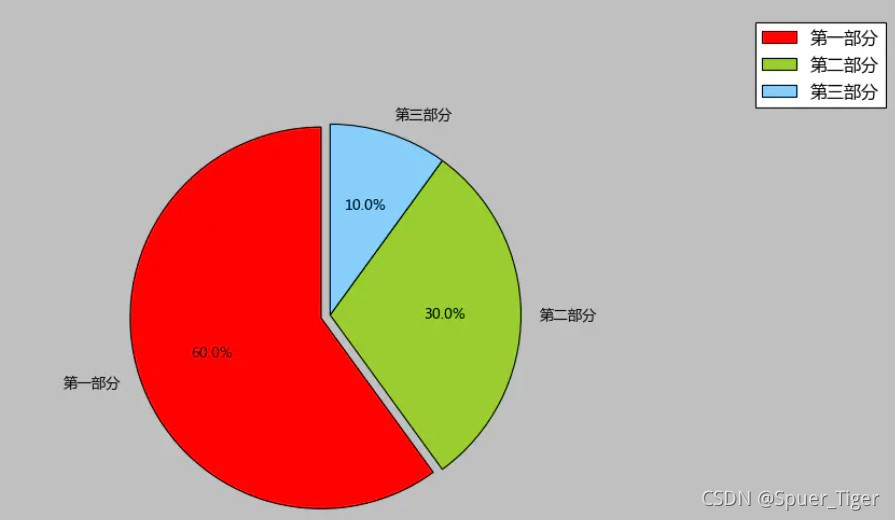
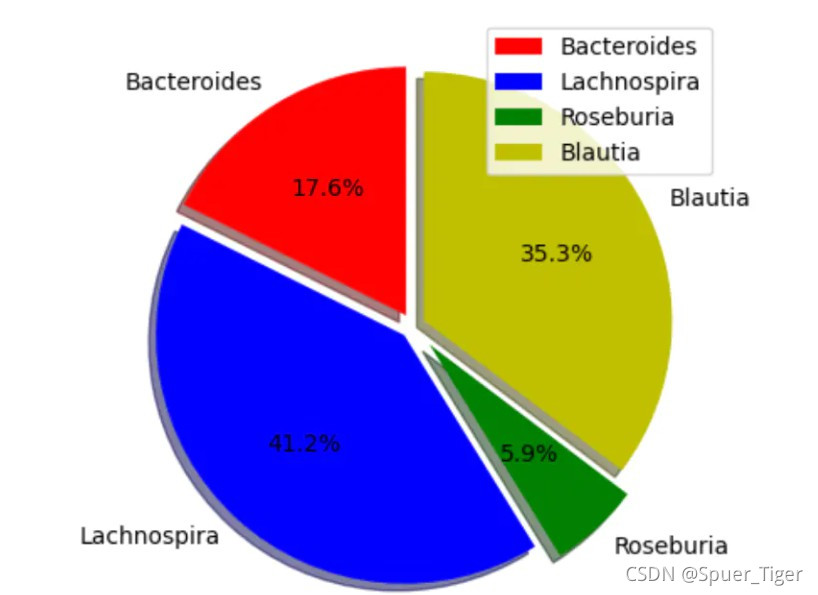
2.绘制3D饼图的方法:
import matplotlib.pyplot as plt
# defining labels
genus = ['Bacteroides', 'Lachnospira', 'Roseburia', 'Blautia']
# portion covered by each label
slices = [3, 7, 8, 6]
# color for each label
colors = ['r', 'b', 'g', 'y']
# plotting the pie chart
plt.pie(slices, labels=genus, colors=colors,
startangle=110, shadow=True, explode=(0.05, 0.05, 0.1, 0.05),
radius=1.0, autopct='%1.1f%%')
# plotting legend
plt.legend()
# showing the plot
plt.show()
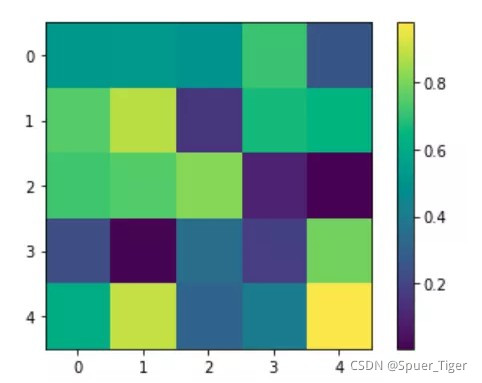
6.Matplolit绘制2D、3D热图的方法
1.绘制2D热图的方法:
在matplotlib中,imshow方法用于绘制热图,基本用法如下:
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(123456789)
data = np.random.rand(25).reshape(5, 5)
plt.imshow(data)
plt.colorbar()
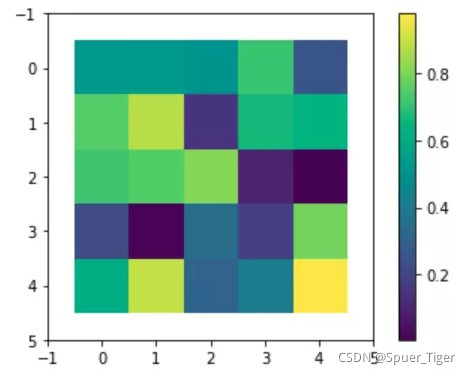
imshow方法常用的参数如下:
- cmap:cmap是colormap的简称,用于指定渐变色,默认的值为viridis, 在matplotlib中,内置了一系列的渐变色,例如:"
plt.imshow(data, cmap='Greens')"。 - aspect:aspect用于指定热图的单元格的大小,默认值为equal,此时单元格用于是一个方块,当设置为auto时,会根据画布的大小动态调整单元格的大小,例如:"
plt.imshow(data, aspect='auto')"。 - vmin和vmax:vmin和vmax参数用于限定数值的范围,只将vmin和vmax之间的值进行映射,例如:"
plt.imshow(data, vmin=-0.8, vmax=0.8)"。 - extent:extent参数指定热图x轴和y轴的极值,取值为一个长度为4的元组或列表,其中,前两个数值对应x轴的最小值和最大值,后两个参数对应y轴的最小值和最大值, 例如:"
plt.imshow(data, extent=(-0.5, 4.5, 4.5, -0.5))"。
plt.imshow(data)
plt.xlim(-1, 5)
plt.ylim(5, -1)
plt.colorbar()
3.绘制3D热图的方法:
fig = plt.figure()
ax = plt.axes(projection='3d')
X = np.arange(-5, 5, 0.25)
Y = np.arange(-5, 5, 0.25)
X, Y = np.meshgrid(X, Y)
R = np.sqrt(X ** 2 + Y ** 2)
Z = np.sin(R)
ax.plot_surface(X, Y, Z, cmap = 'RdBu')
plt.show()

7.Matplotlib绘制动态图效果的方法
在实际应用中, 希望观察到数据的变化过程而不仅仅是最终的结果,例如股票的实时变化、各国家疫情人数动态变化等。 在Matplotlib库中有一个子库animation,该库下定义了多种用于绘制动态效果图的类,例如FuncAnimation,ArtistAnimation等,我们这里主要介绍FuncAnimation的使用。该类通过重复调用某个功能函数从而实现动态绘图效果,在功能函数中会对图进行一些修改,只要调用时间间隔足够短,给人的感觉就是图在动态变化。创建FuncAnimation对象时,需要传递的主要参数及其含义如下:
- fig:用于显示动态效果的画布,即Figure对象;
- unc:函数名,重复调用的功能函数;
- frames:每一帧数据,通常是可迭代对象,依次取出每一个数据传递给功能函数;
- init_func:初始函数,用于执行初始化操作;
- fargs:传递给功能函数的额外参数;
- save_count:保存计数,默认为100;
- interval:重复调用功能函数的间隔时间,单位为毫秒,默认为200;
- repeat_delay:动画结束后,重复执行动画的间隔时间,单位为毫秒;
- repeat:动画执行结束后,是否重复,默认为True;
- blit:是否更新所有点,即更新所有点还是仅更新变化的点,默认为False;
- cache_frame_data:是否缓存数据,默认为True;
sinx()函数的动态图显示:

import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
fig = plt.figure(figsize=(10, 5)) # 创建图
plt.rcParams["font.family"] = "FangSong" # 支持中文显示
# 为了可以观察到整体效果,设置了X轴和Y轴的取值范围,如果不设置取值范围,程序会根据绘图的数据自动调整X轴和Y轴的取值范围
plt.ylim(-12, 12) # Y轴取值范围
plt.yticks([-12 + 2 * i for i in range(13)], [-12 + 2 * i for i in range(13)]) # Y轴刻度
plt.xlim(0, 2 * np.pi) # X轴取值范围
plt.xticks([0.5 * i for i in range(14)], [0.5 * i for i in range(14)]) # X轴刻度
plt.title("函数 y = 10 * sin(x) 在[0,2Π]区间的曲线") # 标题
plt.xlabel("X轴") # X轴标签
plt.ylabel("Y轴") # Y轴标签
x, y = [], [] # 用于保存绘图数据,最开始时什么都没有,默认为空
def update(n): # 更新函数
x.append(n) # 添加X轴坐标
y.append(10 * np.sin(n)) # 添加Y轴坐标
plt.plot(x, y, "r--") # 绘制折线图
ani = FuncAnimation(fig, update, frames=np.arange(0, 2 * np.pi, 0.1), interval=50, blit=False, repeat=False) # 创建动画效果,frames参数是一个可迭代对象,程序执行时,会依次取出该对象中的元素,然后传递给update函数
plt.show() # 显示图片
正弦曲线和余弦曲线交叉的动态图显示:

import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
fig, ax = plt.subplots() # 创建画布和绘图区
ax.set_axis_off() # 不显示坐标轴
x = np.arange(0, 2 * np.pi, 0.01) # 生成X轴坐标序列
line1, = ax.plot(x, np.sin(x)) # 获取折线图对象,逗号不可少,如果没有逗号,得到的是元组
line2, = ax.plot(x, np.cos(x)) # 获取折线图对象,逗号不可少
def update(n): # 动态更新函数
line1.set_ydata(np.sin(x + n / 10.0)) # 改变线条y的坐标值
line2.set_ydata(np.cos(x + n / 10.0)) # 改变线条y的坐标值
ani = FuncAnimation(fig, update, frames=100, interval=50, blit=False, repeat=False) # 创建动画效果
plt.show() # 显示图
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK