

实现可扩展的流处理:Pulsar Key_Shared 订阅模式
source link: https://my.oschina.net/u/4299156/blog/5271582
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

实现可扩展的流处理:Pulsar Key_Shared 订阅模式
本文翻译自 StreamNative 博客《Scalable Stream Processing with Pulsar’s Key_Shared Subscription》[1],作者:David Kjerrumgaard。
译者:刘梓霖、段嘉
1.传统的消息系统通过一个 topic 上的多个并发消费者实现了高吞吐量、无状态处理。2.流系统为单个消费者提供有状态的处理,但在吞吐量上有所保留。3.Pulsar 的 Key_Shared 订阅类型允许对单个 topic 进行高吞吐量和有状态处理。4.Pulsar 的 Key_Shared 订阅类型适合需要对大量数据进行有状态处理的用户场景,例如个性化、实时营销、微定向广告和网络安全。
在建立 Pulsar 的 Key_Shared 订阅前,用户在使用传统流系统框架时须决定是在一个 topic 上拥有多个消费者以获得高吞吐量,还是拥有一个消费者以获得有状态的处理。本博客中将介绍如何使用 Pulsar 的 Key_Shared 订阅对点击流数据进行行为分析。
消息系统和流系统之区别
很多开发者认为消息系统和流系统本质上是一样的,因此经常混用这两个术语。然而,消息系统和流系统是截然不同的,了解它们之间的区别可以让用户根据自己的用户场景选择合适的系统。
本节内容比较了各自的消息消费和处理语义,帮助大家理解为什么有时单独的消息系统和流系统都不能满足你的场景,以及为什么有些场景需要统一的消息和流系统。
使用消息系统的核心数据结构是消息队列。传入的消息以先进先出(FIFO)的顺序存储。消息被保存在队列内,直到被消费。一旦消息被消费,消息就会被删除,以便为新传入的消息腾出空间。
从消费者处理的角度来看,消息传递是完全无状态的,因为每条消息都包含执行处理所需的所有信息。因此可以在不需要来自先前消息的任何信息的情况下进行操作,允许用户在多个消费者之间分配消息处理,减少处理延迟。
消息系统非常适合用户希望扩大某个 topic 的并发消费者数量以增加处理吞吐量的场景。很好的例子是传统的工作队列,即需要由一个订单执行的微服务来处理传入的电子商务订单。由于每个订单都是独立于其他订单的,通过增加从队列中消费的微服务实例的数量来满足需求。
Pulsar 的共享订阅就是为此类型的场景设计。如图 1 所示,它通过确保每条消息准确地传递给附加订阅的一个消费者来提供消息传递语义。

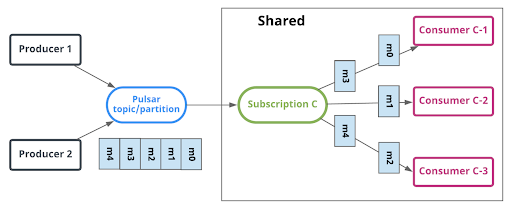
图示 1:Pulsar 的共享订阅类型支持多个消费者。
在流处理中,中心数据结构是日志,它是一个按时间排序的追加记录序列。消息被追加到日志的结尾,读取顺序依次从最早到最新。消息消费是一种非破坏性的流处理操作,因为消费者只是更新它在流中的位置。
从处理的角度来看,流是有状态的,因为流处理是在一连串的消息上进行的,这些消息通常根据时间或大小被分组为固定大小的 “窗口” (例如:每 5 分钟)。流处理依赖于窗口中所有消息的信息以产生正确的结果。
流系统非常适合聚合操作,例如计算传感器读数的简单移动平均值,因为所有传感器读数必须由同一个消费者组合处理,以便计算正确数值。
Pulsar 的独占订阅为这种类型的场景提供了正确的流处理语义。如图 2 所示,独占订阅模式确保所有消息都按照接收的时间顺序传递给单个消费者。

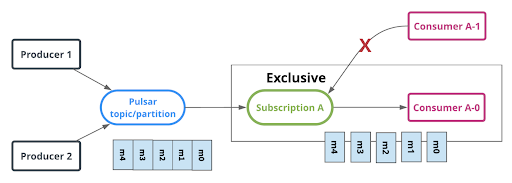
图示 2:Pulsar 的独占订阅模式支持单一消费者。
对比与取舍
如你所见,消息队列和流提供了不同的处理语义。消息系统通过支持多个并发消费者来达到支持高扩展。在处理需要快速处理的大量数据时,应该使用消息系统,这样每个消息从产生到被处理之间的延迟都很低。
流系统拥有更为复杂的分析处理能力,但以牺牲每个 topic 分区的可扩展性为代价。为了得到精确结果,只允许单个消费者处理数据,因此处理数据的速度会受到严重的限制,这导致流系统场景中出现更高的延迟。
尽管可以通过使用分片和分区来减少延迟,但可扩展性仍然有限。将处理的可扩展性与分区的数量做绑定会降低架构的灵活性。更改分区数量也会影响数据发布到 topic 的方式。因此,只有当你需要有状态的处理并且能够容忍较慢的处理时才应该使用流处理。
然而,如果你的场景是既需要低延迟又需要有状态处理应如何选择?如果你在使用 Apache Pulsar,那么你应该考虑 Key_Shared 订阅模式,它提供的处理语义将消息传递和流处理的合二为一。
Apache Pulsar’s Key_Shared 订阅模式
消息是 Pulsar 的基本单元,它们不仅仅包括生产者和消费者之间发送的原始字节,还包括一些元数据字段。如图 3 所示,每个 Pulsar 消息中的一个元数据字段是 “key” 字段,可以容纳一个字符串值。这就是 Key_Shared 订阅用来进行分组的字段。
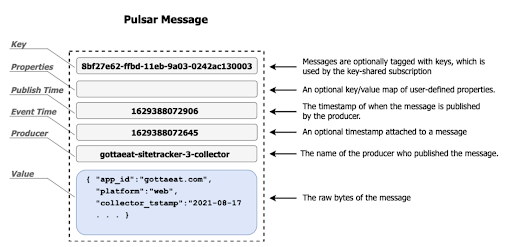
图示 3:一条 Pulsar 消息包含可选的元数据字段,其中包含一个名为 ”key” 的字段,是 Key_Shared 订阅用于分组的字段。
Pulsar Key_Shared 订阅模式支持多个并发消费者,因此你可以通过增加消费者的数量来轻松降低处理延迟。在此方面,它提供了消息队列类型的语义,因为每个消息都可以独立于其他消息进行处理。
然而,这种订阅类型与传统的 Shared 订阅类型的不同之处就在于它在消费者之间分发数据的方式。与任何消费者都可以处理任意消息的传统消息传递不同,在 Pulsar 的 Key_Shared 订阅中,消息被分配到消费者中,并保证具有相同 key 的消息被发送到同一个消费者。
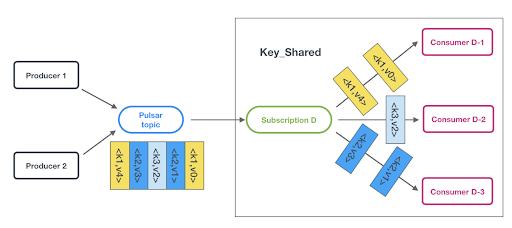
图示 4:Pulsar 的 Key_Shared 订阅类型确保具有相同 key 的消息按照收到的顺序发送到同一个消费者。
Pulsar 通过对传入的 key 值进行哈希并将哈希值平均分配给订阅的所有消费者来实现此等保证。因此,我们知道具有相同 key 的消息将产生相同的哈希值,并被发送到与先前具有相同 key 的同一个消费者。
通过确保所有具有相同 key 的消息都被发送到同一个消费者中,且消费者可以保证按照收到的顺序接收特定 key 的所有消息,这符合流式消费语义。让我们来探索一个可以有效使用 Pulsar 的 Key_Shared 订阅的真实用例。
场景案例:点击流数据(Clickstream Data)的行为分析
基于点击流数据在电子商务网站上提供实时有针对性的推荐是一个很好的案例。因为它需要低延迟地处理大量数据,我们通过点击流数据(Clickstream Data)的行为分析解释说明 Key_Shared 订阅模式。
点击流数据
点击流数据是指单个用户在与网站交互时执行的点击顺序。点击流包含了用户的所有交互,例如点击的位置、访问的页面以及在每个页面上花费的时间。
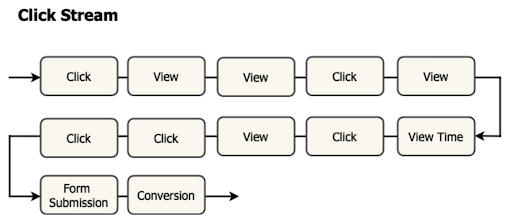
图示 5:点击流数据是代表个人与网站交互事件的时间序列。
该类数据可用于分析并报告特定网站上的用户行为,例如路由、粘性和通过网站的常见用户路径的跟踪。点击流行为基本上是用户与特定网站互动的序列。
为了接收点击流数据,需要将一些跟踪软件嵌入到网站中,以便收集点击流事件并将其转发到分析系统中。这些标签通常是一小段 JavaScript 代码,捕获个人级别用户行数据(例如 IP 地址和 cookie)。每次用户点击标记的网站时,跟踪软件都会检测到该事件,并通过 HTTP POST 请求以 JSON 格式将信息收集并转发到服务端。
列表 1 是一个跟踪库生成的 JSON 对象示例,这些点击流事件在消费分析之前就包括了做聚合、过滤和填充等处理用到的信息。
{"app_id":"gottaeat.com","platform":"web","collector_tstamp":"2021-08-17T23:46:46.818Z","dvce_created_tstamp":"2021-08-17T23:46:45.894Z","event":"page_view","event_id":"933b4974-ffbd-11eb-9a03-0242ac130003","user_ipaddress":"206.10.136.123","domain_userid":"8bf27e62-ffbd-11eb-9a03-0242ac130003","session_id":"7","page_url":"http://gottaeat.com/menu/shinjuku-ramen/zNiq_Q8-TaCZij1Prj9GGA"...}
列表 1:包含个人用户识别信息的点击流事件示例。
在任何时间都可能有数百万活跃的 JavaScript 跟踪器,每个跟踪器都在收集公司网站上单个访问者的点击流事件。这些事件被转发到单个标签收集器,该标签收集器将它们直接发布到 Pulsar topic 中。

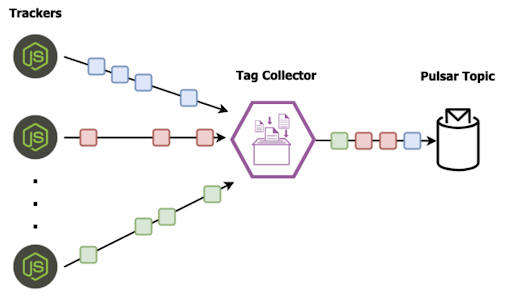
图 6:跟踪器收集单个用户的点击流事件,将其转发给单个收集器。一旦收到事件就会发布,导致来自多个用户的数据交叉在该 topic 中。
从图 6 中可以看出问题:由于这些 JavaScript 标签彼此不协调,来自多个用户的点击流数据最终会混合在 Pulsar 主题中。原因是我们只会对单个用户的点击流数据做行为分析。
为了正确分析数据,首先需要将每个用户的原始点击流事件组合在一起,以确保可以按照它们发生的顺序完整地了解他们的交互旅程。这种从混合数据重构每个用户点击流的过程称为身份拼接。它是通过基于尽可能多的用户唯一标识符将点击流事件关联在一起来完成的。
这就是 Key_Shared 订阅模式完美的用例:需要按照事件发生的顺序处理每个单独用户的完整事件流,因此需要流数据处理语义,并且需要扩展此处理以匹配公司网站上的流量。Pulsar 的 Key_Shared 订阅允许您同时进行这两个处理。
为了重建每个用户的点击流,在点击流事件中使用 domain_userid 字段,它是由 JavaScript 标记生成的唯一标识符。此字段是随机生成的通用唯一标识符 (UUID),用于唯一标识每个用户。因此所有具有相同 domain_userid 值的点击流事件都属于同一个用户。使用此值让 Pulsar 的 Key_Shared 订阅将所有用户的事件组合在一起。
使用 Key_Shared 订阅模式
为实现行为分析,需要全面了解用户与网站的交互情况,因此需要确保将单个用户的所有点击组合在一起,并将它们传递给同一个消费者。正如上一节中讨论的,每个点击流事件中的 domain_userid 字段都包含用户的唯一标识符。通过使用这个值作为消息键,当我们使用 Key_Shared 订阅时,Pulsar 可以保证将所有相同用户的事件传递给同一个消费者。
这个从 JavaScript 标签收集并转发的 JSON 对象,包含原始 JSON 字节(key 段为空)。因此,为了利用 Key_Shared 订阅,首先需要用每个 JSON 对象内的 domain_userid 字段的值填充消息键来丰富该消息。
import org.apache.pulsar.functions.api.Context;import org.apache.pulsar.functions.api.Function;import com.fasterxml.jackson.databind.ObjectMapper;import com.manning.pulsar.chapter4.types.TrackingTag;import org.apache.pulsar.client.impl.schema.JSONSchema;public class WebTagEnricher implements Function<String, Void> {static final String TOPIC = "persistent://tracking/web-activity/tags";@Overridepublic Void process(String json, Context ctx) throws Exception {ObjectMapper objectMapper = new ObjectMapper();TrackingTag tag = objectMapper.readValue(json, TrackingTag.class);ctx.newOutputMessage(TOPIC, JSONSchema.of(TrackingTag.class)).key(tag.getDomainUserId()).value(tag).send();return null;}}
列表 2:Pulsar Function将原始标签字节转换为 JSON 对象,并将 domain_userid 字段的值复制到传出消息的 key 字段中。
这可以通过一段相对简单的代码来完成,如列表 2 所示,它解析 JSON 对象、获取 domain_userid 字段的值,并输出一条包含原始点击流事件的新消息,该事件的键填充为用户的 UUID。这种类型的逻辑处理是 Pulsar Functions 的完美场景案例。此外,由于逻辑是无状态的,因此可以使用共享订阅类型并行执行,这将最大限度地减少执行此任务所需的处理耗时。
使用 Key_Shared 订阅进行身份拼接
一旦使用正确的键值将包含点击流事件的消息充实得当,下一步就是确认 Key_Shared 订阅处理执行身份拼接。列表 3 中的代码在 Key_Shared 订阅上启动了总共五个消费者。
public class ClickstreamAggregator {static final String PULSAR_SERVICE_URL = "pulsar://localhost:6650";static final String MY_TOPIC = "persistent://tracking/web-activity/tags\"";static final String SUBSCRIPTION = "aggregator-sub";public static void main() throws PulsarClientException {PulsarClient client = PulsarClient.builder().serviceUrl(PULSAR_SERVICE_URL).build();ConsumerBuilder<TrackingTag> consumerBuilder =client.newConsumer(JSONSchema.of(TrackingTag.class)).topic(MY_TOPIC).subscriptionName(SUBSCRIPTION).subscriptionType(SubscriptionType.Key_Shared).messageListener(new TagMessageListener());IntStream.range(0, 4).forEach(i -> {String name = String.format("mq-consumer-%d", i);try {consumerBuilder.consumerName(name).subscribe();} catch (PulsarClientException e) {e.printStackTrace();}});}}
列表 3:主类使用 MessageListener 接口在同一个 Key_Shared 订阅上启动消费者,该接口运行在内部线程池中。
新事件到达 TagMessageListener 类时,其处理逻辑为如下所示。由于消费者很可能会被分配多个键,因此传入的点击流事件需要存储在内部映射中,该映射使用每个网页访问者的 UUID 作为键。因此,通过使用 Apache Commons 库中的最近最少使用(LRU) 映射实现来实现,通过在事件变满时删除事件中最旧的元素来确保映射保持固定大小。
import org.apache.commons.collections4.map.LRUMap;import org.apache.pulsar.client.api.Consumer;import org.apache.pulsar.client.api.Message;import org.apache.pulsar.client.api.MessageListener;public class TagMessageListener implements MessageListener<TrackingTag> {private LRUMap<String, List<TrackingTag>> userActivity =new LRUMap<String, List<TrackingTag>>(100);@Overridepublic void received(Consumer<TrackingTag> consumer,Message<TrackingTag> msg) {try {recordEvent(msg.getValue());invokeML(msg.getValue().getDomainUserId());consumer.acknowledge(msg);} catch (PulsarClientException e) {e.printStackTrace();}}private void recordEvent(TrackingTag event) {if (!userActivity.containsKey(event.getDomainUserId())) {userActivity.put(event.getDomainUserId(),new ArrayList<TrackingTag> ());}userActivity.get(event.getDomainUserId()).add(event);}// Invokes the ML model with the collected events for the userprivate void invokeML(String domainUserId) {. . .}}
列表 4:负责聚合点击流事件的类使用 LRU 映射按用户 ID 对事件进行排序。每个新事件都会追加到以前的事件列表中。然后可以通过机器学习模型输入这些列表以生成推荐数据。
当新事件到达时,它会被添加到相应用户的点击流中,从而为已分配给消费者的用户 key 重构点击流。
实时行为分析
现在既已重构了点击流,可以将它们提供给机器学习模型,该模型将为公司网站的每个访问者提供有针对性的推荐,比如根据购物车中的商品、最近查看的商品或优惠券建议将商品添加到购物车。通过实时行为分析,能够通过个性化推荐来改善用户体验,有助于提高转化率和平均订单规模。
传统消息队列通过多个并发消费者对一个 topic 进行处理。典型的场景是订单微服务处理消费订单的传统工作队列。对于此类场景,可以使用 Pulsar 的共享订阅。
传统的流系统进行有状态的数据处理,一个主题上只有一个消费者,但在吞吐量上有限制。流系统可用于更复杂的分析处理能力。Pulsar 的 Exclusive 和 Failover 订阅模式旨在支持这种语义。
Pulsar 的 Key_Shared 订阅类型允许对单个 topic 进行高吞吐量和有状态处理。它非常适合需要对大量数据进行有状态处理的场景,例如个性化、实时营销、微定向广告和网络安全。
更多有关 Pulsar 的 Key_Shared 订阅的信息,可阅读 Apache Pulsar 文档[2]。
感谢 Apache Pulsar 社区志愿者刘梓霖 @珏衫、段嘉 @Janusjia 对本文的翻译。
[1] 《Scalable Stream Processing with Pulsar’s Key_Shared Subscription》: https://streamnative.io/en/blog/engineering/2021-08-25-scalable-stream-processing-with-pulsars-key-shared-subscription/[2] Apache Pulsar 文档: https://pulsar.apache.org/docs/en/concepts-messaging/#subscriptions
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK