

Comparing BigQuery Processing and Spark Dataproc
source link: https://medium.com/paypal-tech/comparing-bigquery-processing-and-spark-dataproc-4c90c10e31ac
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Comparing BigQuery Processing and Spark Dataproc
By Aride Chettali, Vignesh Raj, Sneha Prabhu and Vivek Pathane
Photo by Shahadat Rahman on UnsplashIntroduction
Currently, PayPal is in the process of migrating its analytical workloads to Google Cloud Processing (GCP). In this post, I will cover the different approaches we evaluated for migrating our processes from on-prem to GCP.

We run a number of Spark jobs for processing analytical data in PayPal. These jobs collect behavioral data from the website and repackage them in a consumable format for Data Analysts and Data Scientists. As a part of the GCP migration, we evaluated different approaches like streaming the data to BigQuery (BQ), moving the entire processing into BigQuery, running our existing spark job in a DataProc cluster using BigQuery data, and using our Google Cloud Storage (GCS) Data. Let’s dig deep into different approaches evaluated for one such process — sessionization.
What is the sessionization process ?
Let’s say a user visits the PayPal website, logs into their account, and transfers some money to a friend. They check their account balance and log out. These are some of the user’s actions (events) that occur within a session and an event is fired for each one of them. The sessionization process combines all the events from a single user session and provides a consolidated view of them. It comprises of information like session start time, session end time, and number of events in the session.
How is it handled on-prem ?
All the processed behavioral data are available in Hadoop Distributed File System (HDFS). These events are batched at an hourly level based on the event time. A spark job reads the batched client-side data and performs a group by operation based on user ID and session ID. User ID uniquely identifies the user and session ID is used to identify each session.
Based on the session end time, the grouped events are segregated as completed sessions and in-progress sessions. All the completed sessions are written to the final output and the in-progress sessions are written to a temporary location. At the start of each run, a union is performed for the in-progress dataset and the new batch of behavioral data. An SQL database is used for state management of this job.
Options considered for GCP
Running a Dataproc Job on BigQuery Data
Running a Dataproc job on GCS Data
Running a BigQuery SQL Job
Running a Dataproc job on BigQuery data
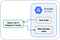
All the user data are available in BigQuery tables. This data can be pumped into a DataProc cluster using the Spark-BigQuery connector library (Github). The same spark job which was running on-prem can be repurposed to run on a DataProc cluster. The same connector library can be used to write data back to BigQuery.
The advantage of this option is that we can reuse the existing spark job. But there is an additional Input/Output step and cost involved to move data out of BigQuery for processing. Since the DataProc cluster is ephemeral, additional time is taken to provision a cluster for every run.
Running a Dataproc job on GCS data

In addition to BigQuery, the user data is available in GCS as well. A spark job can be run on this GCS data in a DataProc cluster using DataProc Hadoop connectors (Github). The processed data can be written back to BigQuery.
This option is very similar to the last approach and shares the same advantages. The only cost involved in this approach will be running a DataProc job.
Running a BigQuery SQL Job

Existing Spark SQL jobs must be rewritten using BQ SQL for this option. BQ SQL takes advantage of the existing BigQuery infrastructure to do the processing. If BigQuery jobs are billed with on-demand pricing, this approach would be costlier than above options.
Performance Comparison
We ran the three options discussed above on different batches of data. Each batch of data contains ~75 GB of user data stored either in BigQuery or GCS. Time taken by each approach can be seen in the graph below.

Running a BQ SQL job has the best performance among the three options. On an average it takes ~2 mins to process one batch of data using BQ SQL. DataProc on GCS has better performance than DataProc on BigQuery.
Cost Comparison
The cost of each of the three options to process the same data can be seen in the image below. The cost for DataProc-BQ comprises of cost associated with both running a DataProc job and extracting data out of BigQuery. BQ SQL cost is calculated as per on demand pricing. In case dedicated slots are provided in BigQuery, the cost for running BQ SQL would be lesser.

Conclusion
BQ SQL is much faster than DataProc in terms of performance and would be best if dedicated slots are provisioned already. A DataProc job with GCS read can be considered as a viable option if cost is a concern.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK