

字符串池化,减少了三分之一的内存占用
source link: https://www.cnblogs.com/newbe36524/p/15259997.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

字符串池化,减少重复实例,内存降低,一切就是这样的轻松愉快。
本文通过一个简单的业务场景,来描述如何通过字符串池化来减少内存中的重复字符串实例,从而减少内存的占用。
在业务中,我们假设如下:
- 有一百万个商品,每个商品都有一个 ProductId 和 Color 列保存在数据库中
- 需要将所有的数据加载到内存中,作为缓存使用
- 每个产品都有 Color
- Color 的范围是一个有限的范围,我们假设大约为八十个左右
学习 dotMemory 度量内存
既然需要度量内存优化的可靠性,那么一个简单有效的度量工具自然必不可少。
本篇,我们介绍 Rider + dotMemory 的组合,如何进行简单的内存度量。读者也可以根据自己的实际,选择自己青睐的工具。
首先,我们创建一个单元测试项目,并且编写一个简单的内存字典构建过程:
public const int ProductCount = 1_000_000;
public static readonly List<string> Colors = new[]
{
"amber", // 此处实际上有80个左右的字符串,省略篇幅
}.OrderBy(x => x).ToList();
public static Dictionary<int, ProductInfo> CreateDict()
{
var random = new Random(36524);
var dict = new Dictionary<int, ProductInfo>(ProductCount);
for (int i = 0; i < ProductCount; i++)
{
dict.Add(i, new ProductInfo
{
ProductId = i,
Color = Colors[random.Next(0, Colors.Count)]
});
}
return dict;
}
从以上代码可以看出:
- 创建了一百万个商品对象,其中的 Color 通过随机数进行随机选取。
提前指定字典的大小的预期值,实际上也是一种优化。请参阅 https://docs.microsoft.com/dotnet/api/system.collections.generic.dictionary-2.-ctor?view=net-5.0&WT.mc_id=DX-MVP-5003606#System_Collections_Generic_Dictionary_2__ctor_System_Int32_
然后,我们引入 dotMemory 单元测试度量必要的 nuget 包,和其他一些无关紧要的包:
<ItemGroup>
<PackageReference Include="JetBrains.DotMemoryUnit" Version="3.1.20200127.214830" />
<PackageReference Include="Humanizer" Version="2.11.10" />
</ItemGroup>
接着,我们创建一个简单的测试来度量以上字典的创建前后,内存的变化:
public class NormalDictTest
{
[Test]
[DotMemoryUnit(FailIfRunWithoutSupport = false)]
public void CreateDictTest()
{
var beforeStart = dotMemory.Check();
var dict = HelperTest.CreateDict();
GC.Collect();
dotMemory.Check(memory =>
{
var snapshotDifference = memory.GetDifference(beforeStart);
Console.WriteLine(snapshotDifference.GetNewObjects().SizeInBytes.Bytes());
});
}
}
从以上代码可以看出:
- 在字典创建之前,我们通过
dotMemory.Check()来捕捉当前内存的快照,以便后续进行对比 - 字典创建完毕后,我们比对前后两次检查点中新增的对象的大小。
最后,点击如下图所示的按钮,运行这个测试:
 run dotMemory
run dotMemory
那么,就会到的如下这样的结果:
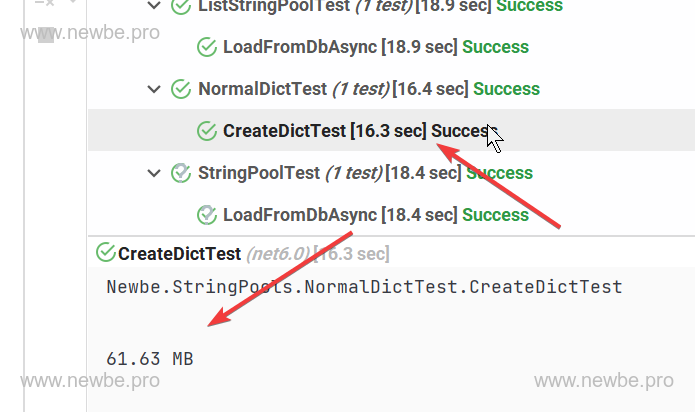 result
result
故而,我们可以得出这样一个简单的结论。这样一个字典,大约需要 61MB 的内存。
而这是理论上,这个字典占用了内存最小情况。因为,其中每个 Color 使用的都是上面的八十个范围之一。因此,他们达到了没有任何重复实例的目的。
这个数据将会作为后续代码的一个基准。
尝试从数据库载入到内存
实际业务肯定是从数据库之类的持久化存储载入到内存中的。因此,我们度量一下,没有经过优化情况下,这种载入方式大概需要多大的内存开销。
这里,我们使用 SQLite 作为演示的存储数据库,实际上用什么都可以,因为我们关心的是最终缓存的大小。
我们,引入一些无关紧要的包:
<ItemGroup>
<PackageReference Include="Dapper" Version="2.0.90" />
<PackageReference Include="System.Data.SQLite.Core" Version="1.0.115" />
</ItemGroup>
我们编写一个测试代码,将一百万测试数据写入到测试库中:
[Test]
public async Task CreateDb()
{
var fileName = "data.db";
if (File.Exists(fileName))
{
return;
}
var connectionString = GetConnectionString(fileName);
await using var sqlConnection = new SQLiteConnection(connectionString);
await sqlConnection.OpenAsync();
await using var transaction = await sqlConnection.BeginTransactionAsync();
await sqlConnection.ExecuteAsync(@"
CREATE TABLE Product(
ProductId int PRIMARY KEY,
Color TEXT
)", transaction);
var dict = CreateDict();
foreach (var (_, p) in dict)
{
await sqlConnection.ExecuteAsync(@"
INSERT INTO Product(ProductId,Color)
VALUES(@ProductId,@Color)", p, transaction);
}
await transaction.CommitAsync();
}
public static string GetConnectionString(string filename)
{
var re =
$"Data Source={filename};Cache Size=5000;Journal Mode=WAL;Pooling=True;Default IsolationLevel=ReadCommitted";
return re;
}
以上代码:
- 创建一个名为 data.db 的数据
- 在数据库中创建一个 Product 表,包含 ProductId 和 Color 两列
- 将字典中的所有数据插入到这两个表中,其实就是前文创建的那个字典
运行这个测试,大概十秒左右,测试数据也就准备好了。后续,我们将重复从这个数据库读取数据,作为我们的测试用例。
现在,我们编写一个从数据库读取数据,然后载入到字典的代码,并且度量一下内存的变化:
[Test]
[DotMemoryUnit(FailIfRunWithoutSupport = false)]
public async Task LoadFromDbAsync()
{
var beforeStart = dotMemory.Check();
var dict = new Dictionary<int, ProductInfo>(HelperTest.ProductCount);
await LoadCoreAsync(dict);
GC.Collect();
dotMemory.Check(memory =>
{
var snapshotDifference = memory.GetDifference(beforeStart);
Console.WriteLine(snapshotDifference.GetNewObjects().SizeInBytes.Bytes());
});
}
public static async Task LoadCoreAsync(Dictionary<int, ProductInfo> dict)
{
var connectionString = HelperTest.GetConnectionString();
await using var sqlConnection = new SQLiteConnection(connectionString);
await sqlConnection.OpenAsync();
await using var reader = await sqlConnection.ExecuteReaderAsync(
"SELECT ProductId, Color FROM Product");
var rowParser = reader.GetRowParser<ProductInfo>();
while (await reader.ReadAsync())
{
var productInfo = rowParser.Invoke(reader);
dict[productInfo.ProductId] = productInfo;
}
}
以上代码:
- 我们改变了字典的创建方式,将其中的数据从数据库中读取并载入
- 使用 Dapper 读取 DataReader 并且全部载入字典
同样,我们运行 dotMemory 度量变化,可以得到数据为:
95.1 MB
因此,我们得出,采用这种方式,多消耗了 30MB 左右的内存。看起来很少,但其实比前面多了 50%。(一千五工资加薪到三千,涨薪 100%的即时感)
当然,你可能会怀疑,多出来的这些开销实际上是数据库操作消耗的。但通过下文的优化,我们可以提前知道:
这些多出来的开销,实际上是因为存在重复的字符串消耗。
剔除重复的字符串实例
既然我们怀疑多出来的开销是重复的字符串,那么我们就可以考虑通过将它们转为同一个对象的方式,减少字典中重复的字符串。
所以,我们就有了下面这个版本的测试代码:
[Test]
[DotMemoryUnit(FailIfRunWithoutSupport = false)]
public async Task LoadFromDbAsync()
{
var beforeStart = dotMemory.Check();
var dict = new Dictionary<int, ProductInfo>(HelperTest.ProductCount);
await DbReadingTest.LoadCoreAsync(dict);
foreach (var (_, p) in dict)
{
var colorIndex = HelperTest.Colors.BinarySearch(p.Color);
var color = HelperTest.Colors[colorIndex];
p.Color = color;
}
GC.Collect();
dotMemory.Check(memory =>
{
var snapshotDifference = memory.GetDifference(beforeStart);
Console.WriteLine(snapshotDifference.GetNewObjects().SizeInBytes.Bytes());
});
}
以上代码:
- 我们仍然从数据库载入所有的数据到字典中,载入的代码和先前完全一样,因此没有展示
- 载入之后,我们再次遍历字典。并且从早在第一个版本就存在的 Color List 搜索到对应的字符串实例,并且赋值给字典中的 Color
- 通过这样一搜,一读,一换。我们使得字典中的 Color 全部来自 Color List
于是,我们再次运行 dotMemory 进行度量,结果非常的 Amazing:
61.69 MB
虽说,最终这个数字的开销对比,第一个版本略有上升,但其实已经到了相差无几的地步。
我们通过将相同字符串转为相同实例的方式,将字典中的相同 Color 转为了相同实例。而 30MB 的临时字符串则会由于没有对象引用它们,因此在最近的一次 GC 中会被立即回收,一切都是这样的轻松愉快。
直接引入 StringPool
前文我们已经找到了开销的原因,并且通过办法进行了优化。不过还存在一些问题实际上要考虑:
- 很多时候 Color List 并不是静态的列表,她可能早上还很开心,下午就生气了
- Color List 不可能无限大,我们需要一个淘汰算法,淘汰末尾的 10%,把他们输送给社会
因此,我们可以考虑直接使用 StringPool,别人写的代码很棒,现在是我们的了。
让我们再引入一些无关紧要的包:
<ItemGroup>
<PackageReference Include="Microsoft.Toolkit.HighPerformance" Version="7.0.2" />
</ItemGroup>
稍微改了一下,就有了新的版本:
[Test]
[DotMemoryUnit(FailIfRunWithoutSupport = false)]
public async Task LoadFromDbAsync()
{
var beforeStart = dotMemory.Check();
var dict = new Dictionary<int, ProductInfo>(HelperTest.ProductCount);
await DbReadingTest.LoadCoreAsync(dict);
var stringPool = StringPool.Shared;
foreach (var (_, p) in dict)
{
p.Color = stringPool.GetOrAdd(p.Color);
}
GC.Collect();
dotMemory.Check(memory =>
{
var snapshotDifference = memory.GetDifference(beforeStart);
Console.WriteLine(snapshotDifference.GetNewObjects().SizeInBytes.Bytes());
});
}
以上代码:
- 使用了 StringPool.Shared 实例存储字符串实例
- GetOrAdd 实际上就是实现了我们先前的一搜,一读,一换三步走战略
当然,结果也是毫无惊喜可言的惊喜:
61.81 MB
一切就是这样的轻松愉快。
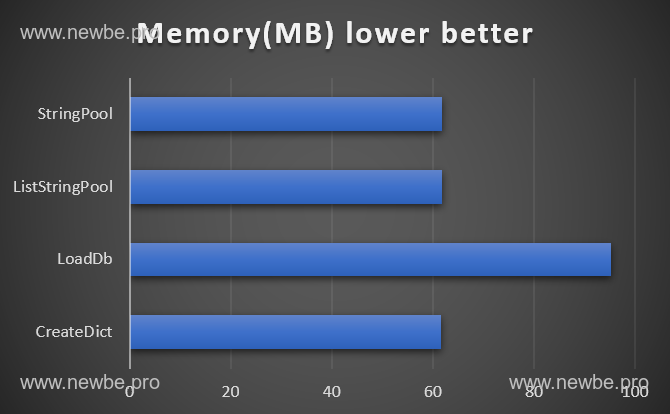 diff
diff
StringPool 和 string.Intern() 有什么异同?
它们都是为了解决重复字符串实例过多,导致浪费内存的情况。
效果上的区别,主要是生存期的区别。 string.Intern 是终生制的,一旦加入只要程序不重启,就会一直存在。这和 StringPool 很不一样。
因此,如果你有生存期上的考虑,请斟酌选择。
string.Intern 可以参阅 https://docs.microsoft.com/dotnet/api/system.string.intern?view=net-5.0&WT.mc_id=DX-MVP-5003606
StringPool 是怎么实现的?
咱也不懂,咱也不敢乱说。总的来说是一个带有使用计数标记的优先队列。源代码咱也读不懂。
前面的区域,就交给你探索吧:
我该在什么情况下考虑使用 StringPool?
笔者建议,考虑这些字符串入池:
- 这个字符串可能被很多实例引用
- 这个字符串需要长期驻留,或者持有它的对象,是长期对象
- 内存优化确实已经成为你要考虑的事情了
当然,其实存在一个最容易判断的依据。你可以直接把产线上的内存 dump 下来,查看里面是否存在很多重复的字符串,然后优化他们。 现在已经是 2021 年了,不会还有人不会 dump 内存吧,不会吧,不会吧?(手动狗头 如果你还不会 dump 内存,那么可以参阅黄老师在微软 Reactor 上分享的视频进行学习: https://www.bilibili.com/video/BV1jZ4y1P7EY
好耶!我可以用 StringPool 来存储枚举的 DisplayName
确实,也没有什么错。不过,其实还有更好的一些方案:
https://github.com/Spinnernicholas/EnumFastToStringDotNet
dotMemory 度量还有更多姿势,你可以多多尝试。
重复,池化。这是一种非常常见的优化方案。掌握它们,在你需要的时候,这或许就帮到了你。
本篇文章中代码实例,可以在以下地址找到,不要忘记为项目 star 哟:
https://github.com/newbe36524/Newbe.Demo/tree/main/src/BlogDemos/Newbe.StringPools
字符串池化,减少重复实例,内存降低,一切就是这样的轻松愉快。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK