A Breakthrough On Matrix Product
November 29, 2011
Beating Coppersmith-Winograd
Virginia Vassilevska Williams is a theoretical computer scientist who has worked on a number of problems, including a very neat question about cheating in the setup of tournaments, and a bunch of novel papers exemplified by this one on graph and matrix problems with runtime exponents of  that have long been begging to be improved.
that have long been begging to be improved.
Today Ken and I want to discuss her latest breakthrough in improving our understanding of the matrix multiplication problem.
Of course Volker Strassen first showed in his famous paper in 1969 that the obvious cubic algorithm was suboptimal. Ever since then progress has been measured with one parameter  : if your algorithm runs in time
: if your algorithm runs in time  , then you are known by this one number. Strassen got
, then you are known by this one number. Strassen got  , and the race was off. A long series of improvements started to happen, which for a while seemed to be stuck above
, and the race was off. A long series of improvements started to happen, which for a while seemed to be stuck above  . Then, Don Coppersmith and Shmuel Winograd (CW) got
. Then, Don Coppersmith and Shmuel Winograd (CW) got  and everything changed. After a contribution by Strassen himself, CW finally obtained
and everything changed. After a contribution by Strassen himself, CW finally obtained  in 1987, with full details here. This has been the best known for decades.
in 1987, with full details here. This has been the best known for decades.
This has all changed now. Virginia has proved that she can beat the “barrier” of CW and get a new lower value for . Currently her paper gives 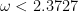 , an improvement of “only”
, an improvement of “only”  , but there is promise of more. This is also another case of proofs coming in twos, as a theorem
, but there is promise of more. This is also another case of proofs coming in twos, as a theorem  in PhD thesis work by Andrew Stothers was circulated to some in June 2010 but not very widely. All this is extremely exciting, and is one of the best results proved in years in all of theory. While these algorithms are unlikely to be usable in practice, they help shed light on one of the basic questions of complexity theory: how fast can we multiply matrices? What could be more fundamental than that?
in PhD thesis work by Andrew Stothers was circulated to some in June 2010 but not very widely. All this is extremely exciting, and is one of the best results proved in years in all of theory. While these algorithms are unlikely to be usable in practice, they help shed light on one of the basic questions of complexity theory: how fast can we multiply matrices? What could be more fundamental than that?
The Basic Idea
Matrix multiplication is bi-linear: the formula for the  entry of
entry of  is
is  . The first step in simplifying the problem is to make it more complicated: Let us have indicator variables
. The first step in simplifying the problem is to make it more complicated: Let us have indicator variables  and compute instead the tri-linear form
and compute instead the tri-linear form

This is a special case of a general tri-linear form

where  and we have re-mapped the indices. It looks like we have made order-of
and we have re-mapped the indices. It looks like we have made order-of  work for ourselves. The key, however, is to try to fit a representation of the form:
work for ourselves. The key, however, is to try to fit a representation of the form:

where  . The point is, suppose we can compute these products
. The point is, suppose we can compute these products  in total time
in total time  . Then we can compute (the coefficients for) all the desired entries
. Then we can compute (the coefficients for) all the desired entries

in  steps. Thus what we have are separate handles on the time for the products and the time for the
steps. Thus what we have are separate handles on the time for the products and the time for the 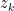 . The way to manage and balance these times involves recursion.
. The way to manage and balance these times involves recursion.
The Basis Idea
The recursion idea is nice to picture for matrices, though its implementation for the way we have unrolled matrices into vectors is not so nice. Picture  and
and  as each being
as each being  matrices. We can regard instead as a
matrices. We can regard instead as a 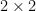 matrix of four matrices
matrix of four matrices 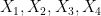 , and do the same for . Then the product can be written via products
, and do the same for . Then the product can be written via products  , and we can picture ourselves recursing on these products.
, and we can picture ourselves recursing on these products.
The reason why the vector case does not look so nice is that the tri-linear form  is so general—indeed we cannot expect to fit a general tri-linear form into a small number of products . What CW did, building on work by Arnold Schönhage, is relax the tri-linear form by introducing more than
is so general—indeed we cannot expect to fit a general tri-linear form into a small number of products . What CW did, building on work by Arnold Schönhage, is relax the tri-linear form by introducing more than  -many variables, supplying appropriate coefficients to set up the recursion, and most of all framing a strategy for setting variables to zero so that three goals are met: the recursion is furthered, the values of “
-many variables, supplying appropriate coefficients to set up the recursion, and most of all framing a strategy for setting variables to zero so that three goals are met: the recursion is furthered, the values of “ ” at each level stay relatively small, and the matrix product can be extracted from the variables left over. This involved a hashing scheme which used subsets of integers that are free of arithmetical progressions.
” at each level stay relatively small, and the matrix product can be extracted from the variables left over. This involved a hashing scheme which used subsets of integers that are free of arithmetical progressions.
The final step by CW was to choose a starting algorithm  for the basis case of the recursion. They devised one and got
for the basis case of the recursion. They devised one and got  . Then they noticed that if they bumped up the base case by manually expanding their algorithm to an
. Then they noticed that if they bumped up the base case by manually expanding their algorithm to an  handling the next-higher case, they got a better analysis and their famous result
handling the next-higher case, they got a better analysis and their famous result  . By their way of thinking, bumping the basis up once more to
. By their way of thinking, bumping the basis up once more to  was the way to do better, but they left analyzing this as a problem. Others attempted the analysis and…found it gave worse not better results. So
was the way to do better, but they left analyzing this as a problem. Others attempted the analysis and…found it gave worse not better results. So  , actually
, actually 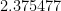 , stood.
, stood.
The insight for breaking through was to make a bigger jump in the basis. Vassilevska Williams was actually anticipated in this without her knowledge by Andrew Stothers, in his 2010 PhD thesis at the University of Edinburgh. Stothers used  and showed this method capable of achieving , though there has been some doubt in whether all details were worked out. Vassilevska Williams, however, used
and showed this method capable of achieving , though there has been some doubt in whether all details were worked out. Vassilevska Williams, however, used  and brought some powerful computing software to bear on a more-extensive framework for the plan. It is not clear whether there is anything necessary about jumping by a power of
and brought some powerful computing software to bear on a more-extensive framework for the plan. It is not clear whether there is anything necessary about jumping by a power of  —in any event her program and framework work for any exponent.
—in any event her program and framework work for any exponent.
The Proof
We cannot yet really give a good summary of the proof—further details are in her paper. One quick observation about her work is in order. She used the CW method, but extended it into a general schema can be used to find good matrix product algorithms, perhaps even better than the one in the paper. The algorithms themselves can be generated and examined, but as usual the task of analyzing them is very hard. The brilliant insight that she has is this task can be laid out automatically by a certain computer program. This allows her to do the analysis where previous others failed.
For example here is a sample of the overview of her main program, in pseudo-code:
The details are not as important as the fact that this program allows one to work on much larger schemas than anyone could previously.
What Does the Bound Mean?
Note that she has improved the bound of Stothers by  . For what threshold value of
. For what threshold value of  does an additive improvement of
does an additive improvement of  in the exponent halve the running time? The answer is
in the exponent halve the running time? The answer is  , which in this case is
, which in this case is  . This value is far above the Bekenstein Bound for the number of particles that could be fit into a volume the size of the observable universe without collapsing it into a black hole. In this sense the algorithm itself is even beyond galactic.
. This value is far above the Bekenstein Bound for the number of particles that could be fit into a volume the size of the observable universe without collapsing it into a black hole. In this sense the algorithm itself is even beyond galactic.
The meaning instead comes from this question: Is there a fundamental reason why could settle at a value strictly greater than ? Note that  is not taken to mean the existence of a quadratic-time algorithm, but rather that for all
is not taken to mean the existence of a quadratic-time algorithm, but rather that for all  there are algorithms that achieve time
there are algorithms that achieve time  . There was some reason to think could be a natural barrier, but it was breached. Perhaps
. There was some reason to think could be a natural barrier, but it was breached. Perhaps  , since this is connected to the golden ratio? Her paper notes a recent draft by Noga Alon, Amir Shpilka, and Christopher Umans that speaks somewhat against the optimism shared by many that .
, since this is connected to the golden ratio? Her paper notes a recent draft by Noga Alon, Amir Shpilka, and Christopher Umans that speaks somewhat against the optimism shared by many that .
Open Problems
Can the current bounds be improved by more computer computations? Are we about to see the solution to this classic question? Or will it be struggling over increments of ?
In any event congratulate Virginia—and Andrew—for their brilliant work.
Update: Markus Bläser, who externally reviewed Stothers’ thesis, has contributed an important comment on the blog of Scott Aaronson here. It evaluates the significance of the work in-context, and also removes the doubt going back to 2010 that was expressed here.


