

g1源码之Mixed GC与ConcurrentMark细节详解
source link: https://www.heapdump.cn/article/2669369
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

继上次全面剖析了youngGC的源码后,这次笔者又阅读了关于Mixed GC的部分源码,相对于youngGC,Mixed GC部分更好阅读和理解一些(ps:不知道是不是因为已经有了读youngGC代码的基础),好了话不多说,我们直接来学代码。
首先我们来简单介绍下Mixed GC,之前笔者在介绍youngGC时,将gc的策略分为:
- youngGC
- ConcurrentMark——老年代并发GC(又叫并发模式gc,本文都先称之为老年代并发gc)
- Mixed GC(混合gc)
- FullGC
一.Mixed GC的开始时机
网上关于Mixed GC(混合GC)的解释比较多,但是对其过程描述的比较少,笔者这里将其阶段做个简单的概括,Mixed GC真正开始于YoungGC之后,当这次youngGC结束后回收集合选择器中待回收的总字节数大于阈值,若下一次gc还是youngGC(应该叫Mixed GC了,不过是和youngGC复用了代码,我们先惩治为youngGC),则会将回收集合选择器中的部分回收效率高得老年代和下次youngGC中要回收的region一起回收。
网上很多文件说到mixed gc是一次youngGC和老年代并发gc的循环,其实是不准确的,再源码中真正的mixed gc启动标记其实是再一次young gc结束之后设置的,笔者再这里先把这部分代码贴出来,方便大家对mixed gc的几个关键flag有所认识:
//这个方法笔者之前的young gc的博客中讲到过,是youngGC结束后记录暂停结束的方法
//这个方法中有涉及mixed gc开启的标记
//这个方法笔者后面也会再次提到
void G1CollectorPolicy::record_collection_pause_end(double pause_time_ms, EvacuationInfo& evacuation_info) {
......
//_last_young_gc只有在老年代并发gc的cleanup阶段结束后会设置为true
if (_last_young_gc) {
//如果是youngGC且不是老年代并发GC的初次标记阶段,则判断下次gc是否进行mixed gc
//这里可以看出mixed gc和老年代并发gc不是同时进行的
if (!last_pause_included_initial_mark) {
//判断下次gc是否应该执行mixed gc(这里主要是判断回收集合选择器CollectionSetChooser上待回收的
//字节数是否大于设定的阈值)
if (next_gc_should_be_mixed("start mixed GCs",
"do not start mixed GCs")) {
//gcs_are_young=false标志着mixed gc的开始
set_gcs_are_young(false);
}
} else {
......
}
_last_young_gc = false;
}
//如果上次gc不是youngGC 即是mixed gc
if (!_last_gc_was_young) {
// 证明正在进行mixed gc 判断是否需要继续执行mixed gc
if (!next_gc_should_be_mixed("continue mixed GCs",
"do not continue mixed GCs")) {
//如果不需要继续进行,则设置gcs_are_young=true结束mixed gc
set_gcs_are_young(true);
}
}
......
}
从源码我们可以看出 gcs_are_young这个标记其实就是是否开启mixed gc的关键,当gcs_are_young为true则表示要进行youngGC,当gcs_are_young为false则证明要进行mixed GC。
这里我们画张图来方便理解下:
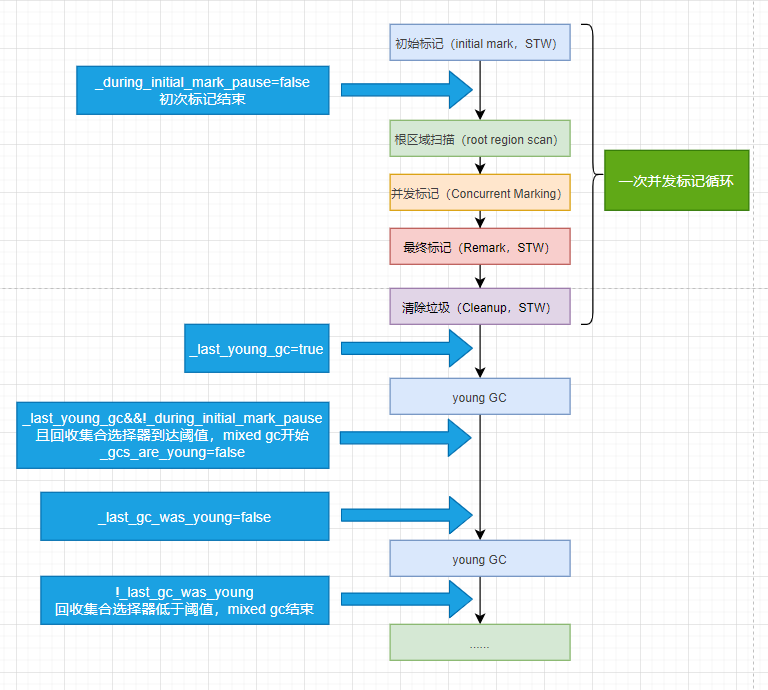
图中我们可以看出mixed GC是在两次youngGC(第二次youngGC其实是Mixed GC)之间进行的,大家可能有疑问了,为什么笔者画还要在图中画出一次老年代GC呢?
因为在老年代并发GC的时候,JVM会将回收效率比较高的但还有存活对象的old region放入回收集合选择器中,方便下次mixed gc回收。笔者这样画主要想表达,mixed gc和老年代并发gc虽然不是同时进行,但是也是相互关联的,只有老年代并发gc扫描完老年代发现回收效率高的但还有存活对象的old region时,才能在下次mixed gc时将存活对象copy到其他old region中,并进行回收。可以理解为更高效率更精准的回收部分老年代的策略。
二.ConcurrentMark与Mixed GC
刚刚我们提到了,mixed gc和老年代并发gc是有相互关联的,所以要想了解mixed gc我们还得从老年代并发gc说起。老年代并发GC顾名思义,主要是用来回收old region的gc策略。老年代并发gc是由ConcurrentMarkThread线程并发执行的,ConcurrentMarkThread线程是在g1 heap初始化的时候创建的,关于ConcurrentMarkThread的线程创建笔者这里就不过多阐述,我们主要来看看其相关启动标记和执行任务的run()方法。
1.ConcurrentMark启动相关标记
关于ConcurrentMark的启动相关标记开启的两个关键方法是need_to_start_conc_mark()和set_initiate_conc_mark_if_possible() 我们来一起看下源码:
//第一个参数是开始并发标记的原因,第二个参数是需要
bool G1CollectorPolicy::need_to_start_conc_mark(const char* source, size_t alloc_word_size) {
//判断是否正在一个并发标记周期中,如果在则直接返回
if (_g1->concurrent_mark()->cmThread()->during_cycle()) {
return false;
}
size_t marking_initiating_used_threshold =
(_g1->capacity() / 100) * InitiatingHeapOccupancyPercent;
//获取当前使用的非young region总字节数
size_t cur_used_bytes = _g1->non_young_capacity_bytes();
//需要申请的空间大小
size_t alloc_byte_size = alloc_word_size * HeapWordSize;
//非young region的总字节数和需要申请的空间大于阈值
if ((cur_used_bytes + alloc_byte_size) > marking_initiating_used_threshold) {
//熟悉的gcs_are_young和_last_young_gc
//gcs_are_young表示当前是youngGC阶段
//_last_young_gc表示当前是否是mixed gc之前的最后一次youngGC
if (gcs_are_young() && !_last_young_gc) {
return true;
} else {
}
}
return false;
}
//当need_to_start_conc_mark返回true时会调用这个方法,表示如果由必要的化就初始化并发标记
void set_initiate_conc_mark_if_possible() { _initiate_conc_mark_if_possible = true; }
笔者这里画个图将老年代并发gc标记启动的场景表示出来:
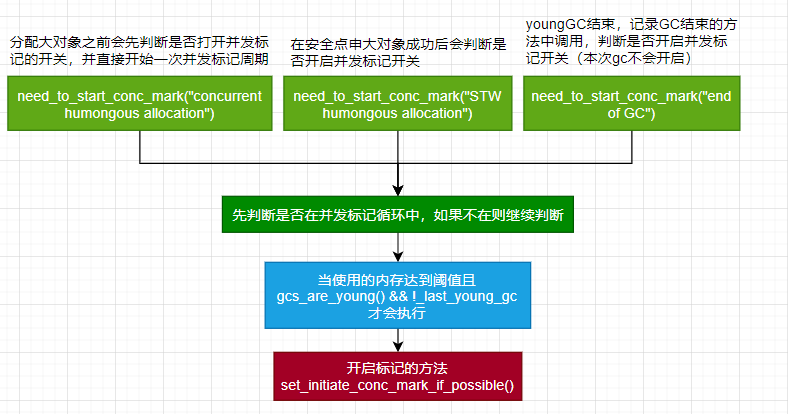
我们可以看出老年代并发gc是否开启的关键是need_to_start_conc_mark()方法,其若返回true,之后会调用set_initiate_conc_mark_if_possible()方法表示下次gc会开启老年代并发gc。
2.ConcurrentMark的启动
知道了ConcurrentMark的启动标记,我们就可以看ConcurrentMark的相关源码了,众所周知ConcurrentMark周期中包括初次标记,我们通常认为初次标记和youngGC是大体一样的,事实上在源码中他们也相互共用了部分代码,之前的笔者的讲述youngGC博客(https://my.oschina.net/u/3645114/blog/5119362)中已经提到了(不得不感叹,youngGC才是g1源码中的基础,强烈推荐大家去看),本篇博客中笔者只把youngGC中关于是否开启ConcurrentMark的内容贴出来,其他部分就先忽略:
//Younggc和初次标记共用的方法
bool
G1CollectedHeap::do_collection_pause_at_safepoint(double target_pause_time_ms) {
......
///这个方法将会决定此次youngGC是不是一次初次标记
//(即老年代并发垃圾回收时,会伴随一次youngGC,此时会返回true)
g1_policy()->decide_on_conc_mark_initiation();
......
//获取本次gc是否是老年代并发gc的初次标记
bool should_start_conc_mark = g1_policy()->during_initial_mark_pause();
......
//初次标记方法
evacuate_collection_set(evacuation_info);
......
//获取本次gc是否是老年代并发gc的初次标记
if (g1_policy()->during_initial_mark_pause()) {
//这个方法会后面还会提到,会判断是否有需要扫描的根区域,这里我们先注意一下
concurrent_mark()->checkpointRootsInitialPost();
//如果是则标记开始标记 _mark_in_progress = true;
set_marking_started();
}
......
//记录回收结束的方法
g1_policy()->record_collection_pause_end(pause_time_ms, evacuation_info);
......
//根据should_start_conc_mark判断是否开始并发标记
if (should_start_conc_mark) {
doConcurrentMark();
}
return true;
}
//我们先看看记录回收结束的方法,这个方法比较长,笔者将其中的部分贴出来
//这是youngGC(初次标记)结束后调用的
void G1CollectorPolicy::record_collection_pause_end(double pause_time_ms, EvacuationInfo& evacuation_info) {
//熟悉的方法
last_pause_included_initial_mark = during_initial_mark_pause();
if (last_pause_included_initial_mark) {
record_concurrent_mark_init_end(0.0);
//如果last_pause_included_initial_mark=false表示当前gc为youngGC
//这个方法就是笔者刚刚图中标注的youngGC结束后调用的need_to_start_conc_mark方法
} else if (need_to_start_conc_mark("end of GC")) {
//这个方法即表示下次gc会开启并发标记
set_initiate_conc_mark_if_possible();
}
......
//可以看到这里出现了 _last_young_gc和 gcs_are_young
//这里表示的是mixed gc和young gc策略之间的切换,发生在youngGC(初次标记后)
//这部分前面讲过笔者就不继续论述
if (_last_young_gc) {
if (!last_pause_included_initial_mark) {
if (next_gc_should_be_mixed("start mixed GCs",
"do not start mixed GCs")) {
set_gcs_are_young(false);
}
} else {
}
_last_young_gc = false;
}
if (!_last_gc_was_young) {
if (!next_gc_should_be_mixed("continue mixed GCs",
"do not continue mixed GCs")) {
set_gcs_are_young(true);
}
}
......
}
//之后我们看看这个方法decide_on_conc_mark_initiation
//这个是YoungGC(初次标记)前调用的
void
G1CollectorPolicy::decide_on_conc_mark_initiation() {
//可以看到这里判断的是initiate_conc_mark_if_possible标记
//如果为true才会继续
if (initiate_conc_mark_if_possible()) {
bool during_cycle = _g1->concurrent_mark()->cmThread()->during_cycle();
//当前如果不在并发标记周期则继续
if (!during_cycle) {
//将during_initial_mark_pause设置为true表示当前为初次标记,即并发标记周期
//我们可以看到之后所有调during_initial_mark_pause()的方法都返回true
set_during_initial_mark_pause();
//这里表示如果我们当前是mixedGC则将设置gcs_are_young=true
//即老年代并发标记和mixed GC不同时进行
if (!gcs_are_young()) {
set_gcs_are_young(true);
}
//重置initiate_conc_mark_if_possible标记
clear_initiate_conc_mark_if_possible();
} else {
//打日志
}
}
}
看到这里,就可以映证笔者开篇描述的几个关于mixed gc的标记了。
之前提到过ConcurrentMark是由ConcurrentMarkThread线程并发执行的,而ConcurrentMark分为以下几个步骤:
- 初始标记(initial mark,STW)
- 根区域扫描(root region scan)
- 并发标记(Concurrent Marking)
- 最终标记(Remark,STW)
- 清除垃圾(Cleanup,STW)
- 并发清除(Concurrent Cleanup)
2.1 根区域扫描(root region scan)
初始标记和youngGC是共用的方法,这里就不过多阐述,我们直接来看后面的代码:
//先看doConcurrentMark的方法
void
G1CollectedHeap::doConcurrentMark() {
MutexLockerEx x(CGC_lock, Mutex::_no_safepoint_check_flag);
//如果工作线程不在执行则将启动标记改为true,_cmThread是ConcurrentMarkThread线程
if (!_cmThread->in_progress()) {
_cmThread->set_started();
//这里可以理解为将线程唤醒
CGC_lock->notify();
}
}
//ConcurrentMarkThread的run方法执行并发Gc任务的方法
void ConcurrentMarkThread::run() {
//初始化线程
//主要是初始化栈和 thread_local_storage(不是java的threadLocal)
initialize_in_thread();
_vtime_start = os::elapsedVTime();
//等待universe(即jvm初始化类,防止jvm还未初始化线程就启动)初始化完毕
wait_for_universe_init();
G1CollectedHeap* g1h = G1CollectedHeap::heap();
G1CollectorPolicy* g1_policy = g1h->g1_policy();
G1MMUTracker *mmu_tracker = g1_policy->mmu_tracker();
Thread *current_thread = Thread::current();
//_should_terminate=true表示线程停止了
while (!_should_terminate) {
// 在下一个循环到来之前Sleep
sleepBeforeNextCycle();
{
ResourceMark rm;
HandleMark hm;
double cycle_start = os::elapsedVTime();
double scan_start = os::elapsedTime();
//在老年代并发线程的运行过程中会经常判断这个方法
//其意义是判断老年代并发标记是否被其他工作终止(比如发生了full gc)
//has_aborted()返回true则证明被终止
if (!cm()->has_aborted()) {
......
//第二步 根区域扫描(root region scan)
_cm->scanRootRegions();
......
}
......
int iter = 0;
do {
iter++;
//如果没被终止则进行并发标记(Concurrent Marking)
if (!cm()->has_aborted()) {
_cm->markFromRoots();
}
......
if (!cm()->has_aborted()) {
......
//最终标记(Remark,STW)
CMCheckpointRootsFinalClosure final_cl(_cm);
VM_CGC_Operation op(&final_cl, "GC remark", true /* needs_pll */);
VMThread::execute(&op);
}
......
//restart_for_overflow这个标记判断全局栈是否溢出,如果溢出则应该启动
//另一个并发标记(Concurrent Marking)阶段即再循环
} while (cm()->restart_for_overflow());
......
if (!cm()->has_aborted()) {
if (g1_policy->adaptive_young_list_length()) {
double now = os::elapsedTime();
double cleanup_prediction_ms = g1_policy->predict_cleanup_time_ms();
jlong sleep_time_ms = mmu_tracker->when_ms(now, cleanup_prediction_ms);
os::sleep(current_thread, sleep_time_ms, false);
}
//清除垃圾(Cleanup,STW)
CMCleanUp cl_cl(_cm);
VM_CGC_Operation op(&cl_cl, "GC cleanup", false /* needs_pll */);
VMThread::execute(&op);
} else {
_sts.join();
g1h->set_marking_complete();
_sts.leave();
}
//free_regions_coming()表示是否有region被回收,判断你是否需要并发cleanup
if (g1h->free_regions_coming()) {
......
//并发真正完成cleanup
_cm->completeCleanup();
//重置标记
g1h->reset_free_regions_coming();
......
}
......
//记录老年代并发gc清理结束的方法
if (!cm()->has_aborted()) {
g1_policy->record_concurrent_mark_cleanup_completed();
}
......
//清理NTAMS bitMap
_cm->clearNextBitmap();
......
}
......
//这个方法会做一些统计并清理_in_progress标记
g1h->increment_old_marking_cycles_completed(true /* concurrent */);
g1h->register_concurrent_cycle_end();
......
}
terminate();
}
上面就是老年代并发gc的整个执行任务的方法,其包括了ConcurrentMark除初次标记的整个流程,下面笔者会把几个主要的方法全部展开看看。
首先是sleepBeforeNextCycle()方法,这个方法可以理解为在并发标记任务触发前线程先等待的逻辑:
//这个方法的意义是根据标记判断是否启动任务
//如果启动则暂时挂起
void ConcurrentMarkThread::sleepBeforeNextCycle() {
MutexLockerEx x(CGC_lock, Mutex::_no_safepoint_check_flag);
//判断started标记,如果为false则sleep等待唤醒
while (!started()) {
//这里是等待方法和之前笔者doConcurrentMark方法中的唤醒方法呼应
//doConcurrentMark方法会先设置started=true并唤醒线程去判断started标记
CGC_lock->wait(Mutex::_no_safepoint_check_flag);
}
//设置progress标记为true
set_in_progress();
//重置started标记
clear_started();
}
然后我们来看看ConcurrentMark(老年代并发gc)周期中的第二步根区域扫描(root region scan):
void ConcurrentMark::scanRootRegions() {
//当至少又一个根区域需要进行扫描时
//scan_in_progress会被设置为true(在初次标记的checkpointRootsInitialPost方法中会判断并设置)
if (root_regions()->scan_in_progress()) {
_parallel_marking_threads = calc_parallel_marking_threads();
uint active_workers = MAX2(1U, parallel_marking_threads());
//创建并运行扫描任务
CMRootRegionScanTask task(this);
if (use_parallel_marking_threads()) {
_parallel_workers->set_active_workers((int) active_workers);
_parallel_workers->run_task(&task);
} else {
task.work(0);
}
root_regions()->scan_finished();
}
}
这里涉及到一个概念根区域,笔者在这里做下解释:我们都知道在初次标记阶段,jvm会扫描整个eden区,并把存活的对象copy到survior区,而根区域即所有的survior区。
我们继续看CMRootRegionScanTask的扫描任务方法:
//CMRootRegionScanTask的扫描方法
void work(uint worker_id) {
//_cm是创建CMRootRegionScanTask传入的ConcurrentMark类,其包含了ConcurrentMarkThread线程类
//也包含了根区域的引用,这里就是获取全部region
CMRootRegions* root_regions = _cm->root_regions();
//遍历所有根区域region
HeapRegion* hr = root_regions->claim_next();
while (hr != NULL) {
//我们看看这个扫描region的方法
_cm->scanRootRegion(hr, worker_id);
hr = root_regions->claim_next();
}
}
//扫描region的方法
void ConcurrentMark::scanRootRegion(HeapRegion* hr, uint worker_id) {
//创建扫描根区域region对象的闭包
G1RootRegionScanClosure cl(_g1h, this, worker_id);
//计算region范围
......
while (curr < end) {
Prefetch::read(curr, interval);
oop obj = oop(curr);
//这个迭代方法会调用一系列宏命令遍历对象,最终会用我们传入的闭包遍历,我们直接看下闭包的处理方法
int size = obj->oop_iterate(&cl);
curr += size;
}
}
//最后调用G1RootRegionScanClosure的do_oop_nv方法
template <class T>
inline void G1RootRegionScanClosure::do_oop_nv(T* p) {
T heap_oop = oopDesc::load_heap_oop(p);
if (!oopDesc::is_null(heap_oop)) {
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
HeapRegion* hr = _g1h->heap_region_containing((HeapWord*) obj);
if (hr != NULL) {
//标记成会灰色
_cm->grayRoot(obj, obj->size(), _worker_id, hr);
}
}
}
最终定位到了grayRoot方法,这个方法是用来将对象染灰(即三色表记法中的染灰),我们来看看这个方法:
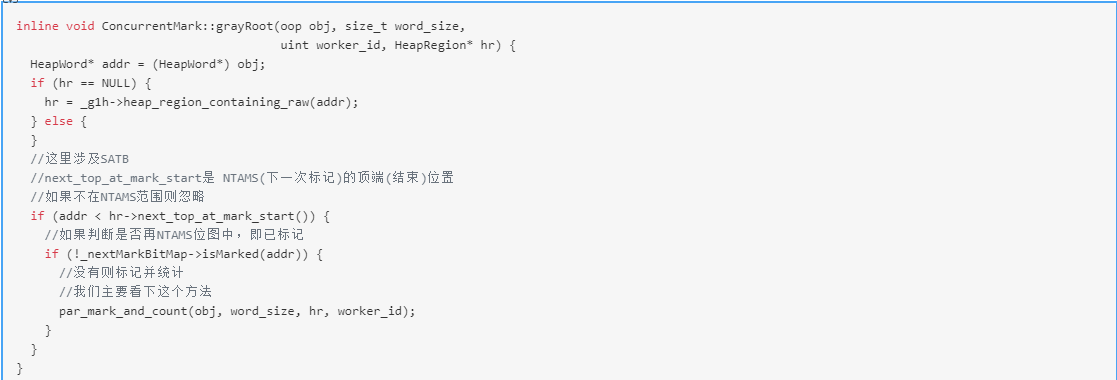
inline bool ConcurrentMark::par_mark_and_count(oop obj,size_t word_size,HeapRegion* hr,
uint worker_id) {
HeapWord* addr = (HeapWord*)obj;
//在NTAMS位图中进行标记
if (_nextMarkBitMap->parMark(addr)) {
MemRegion mr(addr, word_size);
//这个方法会根据worker_id找到当前的任务类,会记录当前任务类标记处理的统计数据
//包括一个全局card位图和一个标记byte数组
count_region(mr, hr, worker_id);
return true;
}
return false;
}
我们可以看到在jvm中标记成灰色的概念就是在NTAMS位图中进行标记,这个NTAMS位图是全局维度的。这里先做一个小总结,从源码中我们看到ConcurrentMark类会判断是否并行创建CMRootRegionScanTask任务类,用工作线程去执行CMRootRegionScanTask任务类去扫描所有的根区域的对象并进行标记,标记体现在全局的NTAMS位图中。
2.2 并发标记(Concurrent Marking)
我们继续回归主线,看老年代并发gc的第三步并发标记(Concurrent Marking):
void ConcurrentMark::markFromRoots() {
//重置溢出重新启动标记
_restart_for_overflow = false;
force_overflow_conc()->init();
_parallel_marking_threads = calc_parallel_marking_threads();
uint active_workers = MAX2(1U, parallel_marking_threads());
// 在这个方法中设置并行任务结束符
set_concurrency_and_phase(active_workers, true /* concurrent */);
//并发标记(Concurrent Marking)任务类
CMConcurrentMarkingTask markingTask(this, cmThread());
//根据并行策略执行
if (use_parallel_marking_threads()) {
_parallel_workers->set_active_workers((int)active_workers);
_parallel_workers->run_task(&markingTask);
} else {
markingTask.work(0);
}
print_stats();
}
和根区域扫描(root region scan)类似,也是通过创建任务类,然后执行,我们直接跳到任务类的work()方法:
//CMConcurrentMarkingTask的work方法
void work(uint worker_id) {
ResourceMark rm;
double start_vtime = os::elapsedVTime();
ConcurrentGCThread::stsJoin();
//这里根据worder_id获取并发标记任务
CMTask* the_task = _cm->task(worker_id);
the_task->record_start_time();
if (!_cm->has_aborted()) {
do {
......
//执行标记步骤,第一个参数是标记超时时间
the_task->do_marking_step(mark_step_duration_ms,
true /* do_termination */,
false /* is_serial*/);
......
//清理溢出标记
_cm->clear_has_overflown();
......
//这里的两个条件一个是代表老年代并发gc是否终止,一个代表并发标记任务是否终止
} while (!_cm->has_aborted() && the_task->has_aborted());
}
......
}
//这个方法是标记的主要方法,在remark阶段也会调用
void CMTask::do_marking_step(double time_target_ms,
bool do_termination,
bool is_serial) {
......
//清除并发任务终止的flag和其他flag
clear_has_aborted();
_has_timed_out = false;
_draining_satb_buffers = false;
++_calls;
//后面的所有情况都是用这两个闭包遍历对象
CMBitMapClosure bitmap_closure(this, _cm, _nextMarkBitMap);
G1CMOopClosure cm_oop_closure(_g1h, _cm, this);
set_cm_oop_closure(&cm_oop_closure);
//判断是否溢出,如果溢出则设置任务终止标记
if (_cm->has_overflown()) {
set_has_aborted();
}
//处理satb缓冲区
drain_satb_buffers();
//处理标记任务的本地队列和所有标记任务的全局栈
//这里可以理解为
drain_local_queue(true);
drain_global_stack(true);
do {
//未扫描前这里 _curr_region是Null,会先执行后面的代码,选择一个姚遍历的region
if (!has_aborted() && _curr_region != NULL) {
update_region_limit();
//从finger开始到结束
MemRegion mr = MemRegion(_finger, _region_limit);
//根据region的不同处理
//为空
if (mr.is_empty()) {
giveup_current_region();
regular_clock_call();
//大region
} else if (_curr_region->isHumongous() && ......) {
if (_nextMarkBitMap->isMarked(mr.start())) {
BitMap::idx_t offset = _nextMarkBitMap->heapWordToOffset(mr.start());
bitmap_closure.do_bit(offset);
}
giveup_current_region();
regular_clock_call();
//其他情况
} else if (_nextMarkBitMap->iterate(&bitmap_closure, mr)) {
giveup_current_region();
regular_clock_call();
} else {
HeapWord* new_finger = _nextMarkBitMap->nextObject(_finger);
if (new_finger >= _region_limit) {
giveup_current_region();
} else {
move_finger_to(new_finger);
}
}
}
//到这里要不然就是被终止,要不然已经处理完当前region
//之后处理完本地队列和全局栈
drain_local_queue(true);
drain_global_stack(true);
//获取一个region
while (!has_aborted() && _curr_region == NULL && !_cm->out_of_regions()) {
//这个方法会根据全局finger获取一个region
//范围是整个堆的region
HeapRegion* claimed_region = _cm->claim_region(_worker_id);
if (claimed_region != NULL) {
statsOnly( ++_regions_claimed );
//将新的region加载到标记任务类中
setup_for_region(claimed_region);
}
regular_clock_call();
}
//遍历直到_curr_region为空或者被终止
} while ( _curr_region != NULL && !has_aborted());
if (!has_aborted()) {
//处理satb
drain_satb_buffers();
}
//再处理本地队列和全局栈
drain_local_queue(false);
drain_global_stack(false);
//自己的任务处理完了,判断是否可以去偷别的线程的任务,我们跳过不看
......
//到这里还没有被终止,则执行终止操作
if (do_termination && !has_aborted()) {
_termination_start_time_ms = os::elapsedVTime() * 1000.0;
bool finished = (is_serial ||
_cm->terminator()->offer_termination(this));
double termination_end_time_ms = os::elapsedVTime() * 1000.0;
_termination_time_ms +=
termination_end_time_ms - _termination_start_time_ms;
//成功终止
if (finished) {
if (_worker_id == 0) {
if (concurrent()) {
_cm->clear_concurrent_marking_in_progress();
}
}
} else {
//终止失败,证明还有任务需要处理,我们先终止它,之后会重新启动
set_has_aborted();
statsOnly( ++_aborted_termination );
}
}
//清除闭包
set_cm_oop_closure(NULL);
......
//完成后的一些收尾工作
if (has_aborted()) {
statsOnly( ++_aborted );
//判断是否超时
if (_has_timed_out) {
double diff_ms = elapsed_time_ms - _time_target_ms;
_marking_step_diffs_ms.add(diff_ms);
}
//判断是否全局栈是否溢出
if (_cm->has_overflown()) {
if (!is_serial) {
_cm->enter_first_sync_barrier(_worker_id);
}
statsOnly( ++_aborted_overflow );
clear_region_fields();
if (!is_serial) {
_cm->enter_second_sync_barrier(_worker_id);
}
}
_claimed = false;
}
这一段代码比较长,分别是处理stab队列和遍历所有的region,最终使用的处理方法都是一样的,我们先看看如何处理stab队列:
//处理Satb缓冲区
void CMTask::drain_satb_buffers() {
if (has_aborted()) return;
//设置标记表示正在处理satb缓冲区,即队列
_draining_satb_buffers = true;
//遍历的闭包
CMObjectClosure oc(this);
//SATB标记队列和Dcqs(不清楚的可以看笔者的上篇博客)构造差不多
//我们直接看遍历闭包
SATBMarkQueueSet& satb_mq_set = JavaThread::satb_mark_queue_set();
if (G1CollectedHeap::use_parallel_gc_threads()) {
satb_mq_set.set_par_closure(_worker_id, &oc);
} else {
satb_mq_set.set_closure(&oc);
}
//处理satb队列
if (G1CollectedHeap::use_parallel_gc_threads()) {
while (!has_aborted() &&
satb_mq_set.par_apply_closure_to_completed_buffer(_worker_id)) {
if (_cm->verbose_medium()) {
gclog_or_tty->print_cr("[%u] processed an SATB buffer", _worker_id);
}
statsOnly( ++_satb_buffers_processed );
regular_clock_call();
}
} else {
while (!has_aborted() &&
satb_mq_set.apply_closure_to_completed_buffer()) {
if (_cm->verbose_medium()) {
gclog_or_tty->print_cr("[%u] processed an SATB buffer", _worker_id);
}
statsOnly( ++_satb_buffers_processed );
regular_clock_call();
}
}
//前面提到CMTask::do_marking_step这个方法在remark阶段也会调用
//这里只有remark阶段会进行,清空satb缓冲区
if (!concurrent() && !has_aborted()) {
if (G1CollectedHeap::use_parallel_gc_threads()) {
satb_mq_set.par_iterate_closure_all_threads(_worker_id);
} else {
satb_mq_set.iterate_closure_all_threads();
}
}
......
}
//CMObjectClosure闭包的遍历方法
void do_object(oop obj) {
//调用这个方法进行对象的遍历
_task->deal_with_reference(obj);
}
再来看看遍历region的闭包,其实也是调用这个方法deal_with_reference():
//CMBitMapClosure遍历的闭包方法
bool do_bit(size_t offset) {
......
_task->move_finger_to(addr);
//这个方法会调用G1CMOopClosure闭包遍历
_task->scan_object(oop(addr));
_task->drain_local_queue(true);
_task->drain_global_stack(true);
return !_task->has_aborted();
}
//G1CMOopClosure闭包遍历
template <class T>
inline void G1CMOopClosure::do_oop_nv(T* p) {
oop obj = oopDesc::load_decode_heap_oop(p);
//处理obj
_task->deal_with_reference(obj);
}
而deal_with_reference()方法是这样的:
inline void CMTask::deal_with_reference(oop obj) {
++_refs_reached;
HeapWord* objAddr = (HeapWord*) obj;
if (_g1h->is_in_g1_reserved(objAddr)) {
//判断是否被NTAMS标记
if (!_nextMarkBitMap->isMarked(objAddr)) {
HeapRegion* hr = _g1h->heap_region_containing_raw(obj);
//这个判断是否大于NTAMS的top,即结束位置
//如果不大于则继续
if (!hr->obj_allocated_since_next_marking(obj)) {
//再NTAMS中标记并计数
//这个方法之前也讲过了,主要是把对象染灰即加入在NTAMS位图中进行标记
if (_cm->par_mark_and_count(obj, hr, _marked_bytes_array, _card_bm)) {
HeapWord* global_finger = _cm->finger();
//finger可以理解为一个标记,记录着遍历region的位置,有一个全局finger和每个region的局部finger
//每个CMTask都负责遍历一个region,其中有一个局部finger
//当小于本地finger时将对象入列本地任务队列
//若本地任务队列满了会将起加入所有任务的全局栈
//本地finger默认从region的开始位置移动,所以一般情况下不会进入
if (_finger != NULL && objAddr < _finger) {
push(obj);
} else if (_curr_region != NULL && objAddr < _region_limit) {
// do nothing
} else if (objAddr < global_finger) {
//小于全局finger时也入列
//这里可能会进入,在处理全局队列的时候也会再处理一次,造成重复处理,但是不影响结果
push(obj);
} else {
// do nothing
}
}
}
}
}
}
至此所有的region(包括survior,老年代,还有大对象region)都已经遍历过一次,并且已经再NATMS位图中进行标记,即染色成灰色。
2.3 最终标记(Remark,STW)
接下来我们下第四步,最终标记(Remark),这个阶段是会STW的,主要逻辑在CMCheckpointRootsFinalClosure这个任务类中和youngGC的任务类执行模式相似,笔者在youngGC的文章中讲过这部分,大家可以看下,我们直接来看CMCheckpointRootsFinalClosure的任务执行方法:
//CMCheckpointRootsFinalClosure任务类处理remark
void do_void(){
//参数是是否清理所有软引用
_cm->checkpointRootsFinal(false); // !clear_all_soft_refs
}
void ConcurrentMark::checkpointRootsFinal(bool clear_all_soft_refs) {
......
//这个方法会调用remark任务
checkpointRootsFinalWork();
double mark_work_end = os::elapsedTime();
//处理虚引用
weakRefsWork(clear_all_soft_refs);
//判断标记栈是否溢出
if (has_overflown()) {
//溢出则设置重启标志,之后会重新进行一次并发标记和remark
_restart_for_overflow = true;
......
// 溢出则重置标记状态
reset_marking_state();
} else {
// 聚合每个任务数据,进行统计
//统计每个region中的_next_marked_bytes
aggregate_count_data();
SATBMarkQueueSet& satb_mq_set = JavaThread::satb_mark_queue_set();
satb_mq_set.set_active_all_threads(false, /* new active value */
true /* expected_active */);
......
// 完成标记重置标记状态
set_non_marking_state();
}
//如果有必要,则对全局栈进行扩容
if (_markStack.should_expand()) {
_markStack.expand();
}
......
}
//remark方法
void ConcurrentMark::checkpointRootsFinalWork() {
ResourceMark rm;
HandleMark hm;
G1CollectedHeap* g1h = G1CollectedHeap::heap();
g1h->ensure_parsability(false);
//并行模式
if (G1CollectedHeap::use_parallel_gc_threads()) {
G1CollectedHeap::StrongRootsScope srs(g1h);
uint active_workers = g1h->workers()->active_workers();
if (active_workers == 0) {
active_workers = (uint) ParallelGCThreads;
g1h->workers()->set_active_workers(active_workers);
}
set_concurrency_and_phase(active_workers, false /* concurrent */);
//主要看这个类,remark任务
CMRemarkTask remarkTask(this, active_workers, false /* is_serial */);
g1h->set_par_threads(active_workers);
g1h->workers()->run_task(&remarkTask);
g1h->set_par_threads(0);
} else {
//单线程
G1CollectedHeap::StrongRootsScope srs(g1h);
uint active_workers = 1;
set_concurrency_and_phase(active_workers, false /* concurrent */);
/主要看这个类,remark任务
CMRemarkTask remarkTask(this, active_workers, true /* is_serial*/);
remarkTask.work(0);
}
......
}
关键还是再CMRemarkTask任务类,我们来看看它的work方法:
//CMRemarkTask的work方法
void work(uint worker_id) {
if (worker_id < _cm->active_tasks()) {
CMTask* task = _cm->task(worker_id);
task->record_start_time();
do {
//熟悉的do_marking_step方法,第一个参数可以理解为是超时时间
//刚刚我们已经分析过这个方法,笔者这里就不过多论述
//和并发标记阶段不一样的是,最终标记阶段这个方法会处理调所有的satb缓冲区
task->do_marking_step(1000000000.0 /* something very large */,
true /* do_termination */,
_is_serial);
} while (task->has_aborted() && !_cm->has_overflown());
task->record_end_time();
}
}
2.4 清除垃圾(Cleanup,STW)
继续回归主线,当进行完最终标记且全局标记栈没有溢出,则会进入最后的阶段Cleanup阶段,我们直接看代码:
//CMCleanUp类的处理方法,这个阶段也是STW的和Remark阶段类似,我们直接看任务类
void do_void(){
_cm->cleanup();
}
void ConcurrentMark::cleanup() {
G1CollectedHeap* g1h = G1CollectedHeap::heap();
if (has_aborted()) {
g1h->set_marking_complete(); // So bitmap clearing isn't confused
return;
}
HRSPhaseSetter x(HRSPhaseCleanup);
g1h->verify_region_sets_optional();
......
G1CollectorPolicy* g1p = G1CollectedHeap::heap()->g1_policy();
g1p->record_concurrent_mark_cleanup_start();
double start = os::elapsedTime();
HeapRegionRemSet::reset_for_cleanup_tasks();
uint n_workers;
// 传入的是全局region位图和card位图
// gc结束后统计数据的任务,统计所有region和card的存活信息
G1ParFinalCountTask g1_par_count_task(g1h, &_region_bm, &_card_bm);
// 是否并行
if (G1CollectedHeap::use_parallel_gc_threads()) {
g1h->set_par_threads();
n_workers = g1h->n_par_threads();
g1h->workers()->run_task(&g1_par_count_task);
g1h->set_par_threads(0);
} else {
n_workers = 1;
g1_par_count_task.work(0);
}
......
//设置标记完成flag
size_t start_used_bytes = g1h->used();
g1h->set_marking_complete();
double count_end = os::elapsedTime();
double this_final_counting_time = (count_end - start);
_total_counting_time += this_final_counting_time;
//打印一些region的存活情况
if (G1PrintRegionLivenessInfo) {
G1PrintRegionLivenessInfoClosure cl(gclog_or_tty, "Post-Marking");
_g1h->heap_region_iterate(&cl);
}
// 交换 NTAMS和PTAMS的bitMaps
swapMarkBitMaps();
g1h->reset_gc_time_stamp();
// 第二个参数是ConcurrentMark的cleanup_list
// 我们来看看这个任务类
G1ParNoteEndTask g1_par_note_end_task(g1h, &_cleanup_list);
if (G1CollectedHeap::use_parallel_gc_threads()) {
g1h->set_par_threads((int)n_workers);
g1h->workers()->run_task(&g1_par_note_end_task);
g1h->set_par_threads(0);
} else {
g1_par_note_end_task.work(0);
}
g1h->check_gc_time_stamps();
//判断cleanup_list是否为空
if (!cleanup_list_is_empty()) {
g1h->set_free_regions_coming();
}
......
//这个方法会把一些老年代region加入到回收集合选择器中
//方便下次mixed gc加入到回收集合中
//再下次的Mixed gc的初次标记中将存活对象copy到其他老年代中,最后进行回收
g1h->g1_policy()->record_concurrent_mark_cleanup_end((int)n_workers);
double end = os::elapsedTime();
_cleanup_times.add((end - start) * 1000.0);
......
}
这个方法的重点再G1ParNoteEndTask任务类和record_concurrent_mark_cleanup_end()记录cleanup结束的方法,我们分别来看下:
//G1ParNoteEndTask的work方法
void work(uint worker_id) {
double start = os::elapsedTime();
//创建 临时的freeRegionList和oldRegionSet,humongousRegionSet
FreeRegionList local_cleanup_list("Local Cleanup List");
OldRegionSet old_proxy_set("Local Cleanup Old Proxy Set");
HumongousRegionSet humongous_proxy_set("Local Cleanup Humongous Proxy Set");
HRRSCleanupTask hrrs_cleanup_task;
//记录并发标记结束的闭包,包含清理region的逻辑并将region加入刚刚创建的三个代理清理集合中
//我们先看看这个任务类
G1NoteEndOfConcMarkClosure g1_note_end(_g1h, worker_id, &local_cleanup_list,
&old_proxy_set,
&humongous_proxy_set,
&hrrs_cleanup_task);
//并发或者单线程对所有region用闭包处理
if (G1CollectedHeap::use_parallel_gc_threads()) {
_g1h->heap_region_par_iterate_chunked(&g1_note_end, worker_id,
_g1h->workers()->active_workers(),
HeapRegion::NoteEndClaimValue);
} else {
_g1h->heap_region_iterate(&g1_note_end);
}
// 在这里更新old和humongous集合
_g1h->update_sets_after_freeing_regions(g1_note_end.freed_bytes(),
NULL /* free_list */,
&old_proxy_set,
&humongous_proxy_set,
true /* par */);
{
MutexLockerEx x(ParGCRareEvent_lock, Mutex::_no_safepoint_check_flag);
// 获取之前计算的最大存活Byte数和释放的byte数
_max_live_bytes += g1_note_end.max_live_bytes();
_freed_bytes += g1_note_end.freed_bytes();
......
//将刚刚释放的region加入到G1ParNoteEndTask的cleanup_list中即ConcurrentMark
//传入的cleanup_list,这里会等到cleanup结束
_cleanup_list->add_as_tail(&local_cleanup_list);
//完成Rset清除任务
HeapRegionRemSet::finish_cleanup_task(&hrrs_cleanup_task);
}
}
//G1NoteEndOfConcMarkClosure的遍历方法,遍历所有region
bool doHeapRegion(HeapRegion *hr) {
//如果是大对象region的中间region则直接跳过
if (hr->continuesHumongous()) {
return false;
}
_g1->reset_gc_time_stamps(hr);
double start = os::elapsedTime();
_regions_claimed++;
//这个方法会交换 每个region的
// _prev_top_at_mark_start和_next_top_at_mark_start
//_prev_marked_bytes和_next_marked_bytes
//并将_next_marked_bytes置空
//至此 PATMS和NATMS的所有标记为都替换完毕
hr->note_end_of_marking();
//累加最大存活bytes
_max_live_bytes += hr->max_live_bytes();
//如果是没有存活对象则释放region
//第二个参数是释放的空间数
//我们看下这个释放region的方法
_g1->free_region_if_empty(hr,
&_freed_bytes,
_local_cleanup_list,
_old_proxy_set,
_humongous_proxy_set,
_hrrs_cleanup_task,
true /* par */);
double region_time = (os::elapsedTime() - start);
_claimed_region_time += region_time;
if (region_time > _max_region_time) {
_max_region_time = region_time;
}
return false;
}
//这个方法会将没存活对象的region的部分属性重置,之后在并发清理阶段释放空间
void G1CollectedHeap::free_region_if_empty(HeapRegion* hr,
size_t* pre_used,
FreeRegionList* free_list,
OldRegionSet* old_proxy_set,
HumongousRegionSet* humongous_proxy_set,
HRRSCleanupTask* hrrs_cleanup_task,
bool par) {
//这个方法不会清除region,先将其加入到临时集合中,即传入的参数
//这里的三个条件分别是
//1.region有使用 2.不是young 3.只有region完全没有存活对象时才会进行清理
if (hr->used() > 0 && hr->max_live_bytes() == 0 && !hr->is_young()) {
//是巨型对象region
if (hr->isHumongous()) {
//释放巨型对象region,这里只是将region的部分属性重置
free_humongous_region(hr, pre_used, free_list, humongous_proxy_set, par);
} else {
//是老年代region
//记录老年代region的信息,并加入到老年代代理集合中
_old_set.remove_with_proxy(hr, old_proxy_set);
//释放region,这里只是将region的部分属性重置
free_region(hr, pre_used, free_list, par);
}
} else {
//young region只清除Rset
hr->rem_set()->do_cleanup_work(hrrs_cleanup_task);
}
}
到这里,如果region中完全没有存活对象的old region和大对象region则会将属性重置,等待并发清理阶段释放空间,年轻代会被清理记忆集合。
之后我们来看看这个方法record_concurrent_mark_cleanup_end():
void
G1CollectorPolicy::record_concurrent_mark_cleanup_end(int no_of_gc_threads) {
//清除回收集合选择器
_collectionSetChooser->clear();
uint region_num = _g1->n_regions();
if (G1CollectedHeap::use_parallel_gc_threads()) {
const uint OverpartitionFactor = 4;
uint WorkUnit;
if (no_of_gc_threads > 0) {
const uint MinWorkUnit = MAX2(region_num / no_of_gc_threads, 1U);
WorkUnit = MAX2(region_num / (no_of_gc_threads * OverpartitionFactor),
MinWorkUnit);
} else {
assert(no_of_gc_threads > 0,
"The active gc workers should be greater than 0");
// In a product build do something reasonable to avoid a crash.
const uint MinWorkUnit = MAX2(region_num / (uint) ParallelGCThreads, 1U);
WorkUnit =
MAX2(region_num / (uint) (ParallelGCThreads * OverpartitionFactor),
MinWorkUnit);
}
//回收集合选择器为添加region做准备
_collectionSetChooser->prepare_for_par_region_addition(_g1->n_regions(),
WorkUnit);
//迭代并选择合适的region添加到回收集合选择器中的任务类
//回收集合选择器是和mixedGC相关的
ParKnownGarbageTask parKnownGarbageTask(_collectionSetChooser,
(int) WorkUnit);
_g1->workers()->run_task(&parKnownGarbageTask);
} else {
KnownGarbageClosure knownGarbagecl(_collectionSetChooser);
_g1->heap_region_iterate(&knownGarbagecl);
}
//回收集合选择器中的Region排序
_collectionSetChooser->sort_regions();
}
//ParKnownGarbageTask 任务类的work方法
void work(uint worker_id) {
//创建遍历的闭包,我们直接看这个闭包的遍历方法
ParKnownGarbageHRClosure parKnownGarbageCl(_hrSorted, _chunk_size);
//遍历region
_g1->heap_region_par_iterate_chunked(&parKnownGarbageCl, worker_id,
_g1->workers()->active_workers(),
HeapRegion::InitialClaimValue);
}
//ParKnownGarbageHRClosure 遍历方法
bool doHeapRegion(HeapRegion* r) {
//判断region是否被标记,这个方法实际看
//_prev_top_at_mark_start(其实是_next_top_at_mark_start,已经被交换了)是不是初始值,如果不是即标记过
if (r->is_marked()) {
//这两个条件分别是
//1.不是大对象regin且存活对象小于阈值
//2.且不是我们gc前正在使用的region
if (_cset_updater.should_add(r) && !_g1h->is_old_gc_alloc_region(r)) {
_cset_updater.add_region(r);
}
}
return false;
}
这里我们可以看到在这个阶段已经再向回收集合选择器中添加old region了,如果触发了mixed gc则在下次mixed gc中会一起把具有回收价值(即存活对象数量小)的old region随年轻代一起处理并回收。
2.5 并发清除(Concurrent Cleanup)
最后就是并发清理的阶段,之前没有存活对象的region只是将其部分属性进行了重置,到了并发清理阶段才会进行清理:
void ConcurrentMark::completeCleanup() {
if (has_aborted()) return;
G1CollectedHeap* g1h = G1CollectedHeap::heap();
_cleanup_list.verify_optional();
FreeRegionList tmp_free_list("Tmp Free List");
......
//判断cleanup_list是否为空
while (!_cleanup_list.is_empty()) {
//从头获取一个region
HeapRegion* hr = _cleanup_list.remove_head();
//清除Rset和region
hr->par_clear();
//加入到临时释放region集合中
tmp_free_list.add_as_tail(hr);
if ((tmp_free_list.length() % G1SecondaryFreeListAppendLength == 0) ||
_cleanup_list.is_empty()) {
{
MutexLockerEx x(SecondaryFreeList_lock, Mutex::_no_safepoint_check_flag);
//将临时free_list加入到second_free_list中
g1h->secondary_free_list_add_as_tail(&tmp_free_list);
SecondaryFreeList_lock->notify_all();
}
if (G1StressConcRegionFreeing) {
for (uintx i = 0; i < G1StressConcRegionFreeingDelayMillis; ++i) {
os::sleep(Thread::current(), (jlong) 1, false);
}
}
}
}
}
关于satb和PTAMS,NTAMS
在老年代并发GC中PTAMS和NTAMS是关于satb的概念,我们来画个图梳理下这部分内容:
初始标记(initial mark)结束后:
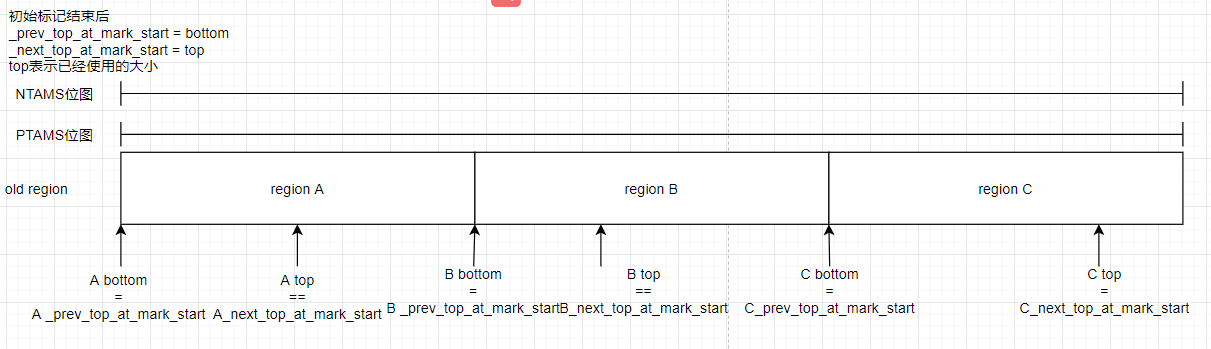
注:_next_top_at_mark_start = top是在初始标记的checkpointRootsInitialPre()方法中设置的,有兴趣的读者可以看下
并发标记(Concurrent Marking)到最终标记阶段(Remark):
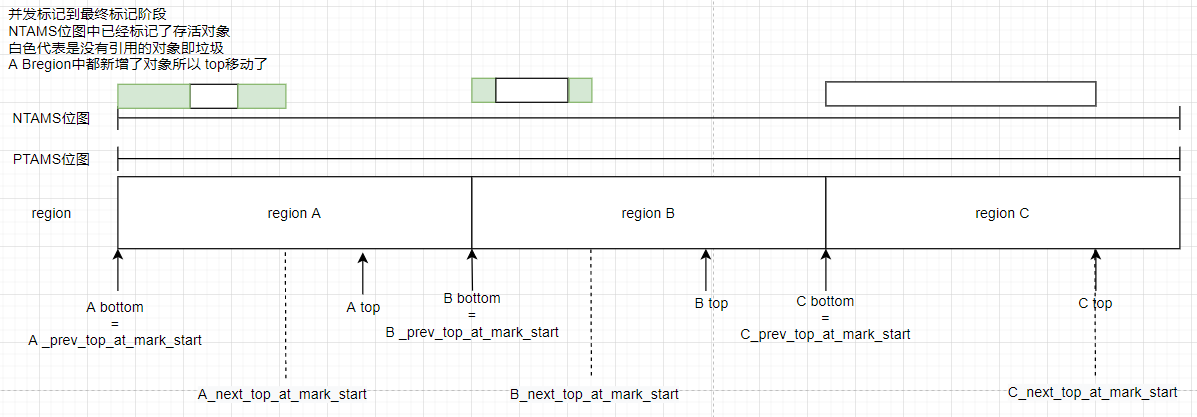
从图中我们可以看出NTAMS和PTAMS位图都是全局维度的,regionC中已经全是垃圾了
清除垃圾(Cleanup):
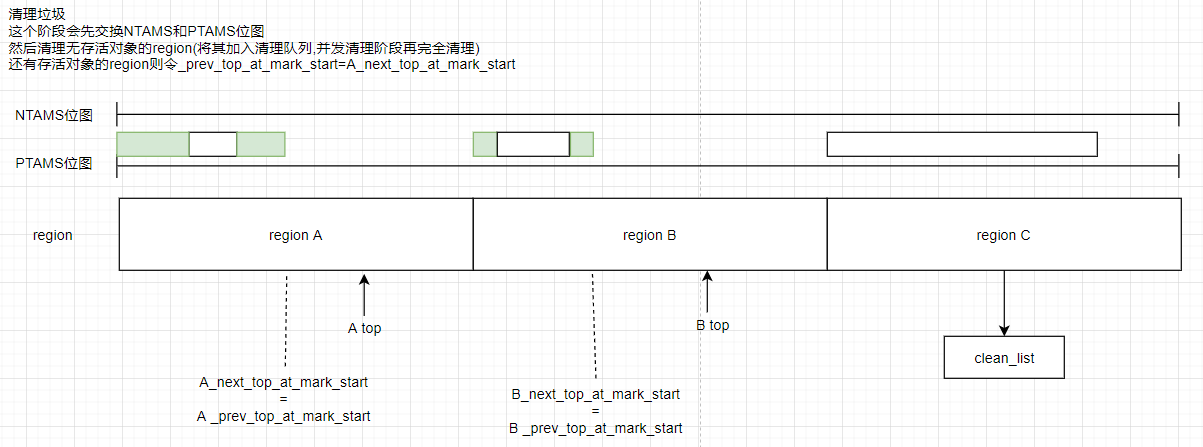
至此一个老年代并发Gc循环结束了,下一次初次标记来临时,_next_top_at_mark_start又会被设置到top的位置,重复上述步骤。
到这里整个老年代并发gc的所有流程结束了,我们继续看关于mixed GC的部分。
3.Mixed GC
笔者前面说过,Mixed GC和老年代并发GC是分不开的,从之前的源码中我们也看到jvm会在cleanup阶段将old region中的一些存活对象小,回收价值高得放入回收集合选择器中,而这个选择器则会在下次Mixed gc(本质上是一次youngGC)开始前将这些region添加到回收集合中参与处理和回收:
//我们还是来看这个方法,这次笔者只将关于回收集合选择器得部分贴出来
void G1CollectorPolicy::finalize_cset(double target_pause_time_ms, EvacuationInfo& evacuation_info) {
......
//前面讲过这个标记即如果是mixed gc
if (!gcs_are_young()) {
//获取回收集合选择器
CollectionSetChooser* cset_chooser = _collectionSetChooser;
......
HeapRegion* hr = cset_chooser->peek();
while (hr != NULL) {
//经过一系列判断
......
cset_chooser->remove_and_move_to_next(hr);
_g1->old_set_remove(hr);
//加入到回收集合中
add_old_region_to_cset(hr);
hr = cset_chooser->peek();
}
......
}
当加入回收集合中时,之后会复用youngGC得代码,将这部分old region中存活得对象copy到其他old region中(关于这部分可以看笔者之前讲述youngGC的博客,这里就不在叙述),处理完成后再进行回收。
不知不觉,这已经是关于G1的第三篇文章了,下一篇应该是关于G1的最后一篇FullGC相关的文章,这个坑就填上了,当然以后可能会更新一些g1的其他部分文章,笔者如果发现比较有意思的功能或者方向也会继续研究。对于笔者来说学习源码是一种兴趣,当然笔者水平有限,如果有写的有出入的地方,欢迎大家指出相互学习。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK