

OpenAnolis龙蜥社区的个人空间
source link: https://my.oschina.net/u/5265430/blog/5220160
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


在系列文章上篇和中篇(参考相关阅读),我们介绍了优化效果,并且评估了影响。而在本文中,我们将进一步展示详细的模拟结果,通过分析这些不同场景的结果给出结论和建议;我们还会介绍采集和模拟工具,使读者能针对自己的业务场景进行评估。
相关阅读:
上篇:干掉讨厌的 CPU 限流,让容器跑得更快 | 龙蜥技术
中篇:CPU Burst 有副作用吗?让数学来回答!| 龙蜥技术
场景和参数设定
我们设定整个系统存在 m 个 cgroup,每个 cgroup 公平瓜分总量为 100% 的 CPU 资源,即 quota=1/m 。每个 cgoup 按相同规律(独立同分布)产生计算需求并交给 CPU 执行。
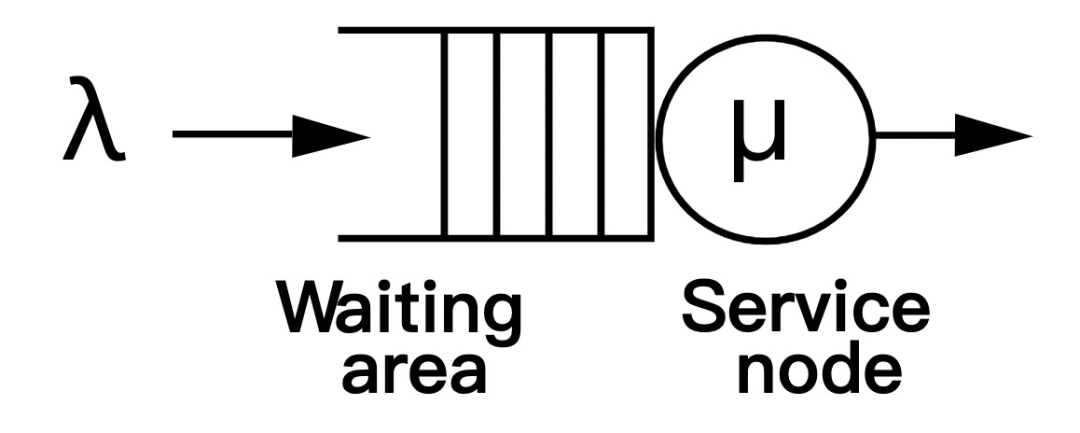
我们参考排队论的模型,将每个 cgroup 视为一位顾客,CPU 即为服务台,每位顾客的服务时间受到 quota 的限制。为了简化模型,我们离散化地定义所有顾客的到达时间间隔为常数,然后在该间隔内 CPU 最多能服务 100% 的计算需求,这个时间间隔即为一个周期。
然后我们需要定义每位顾客在一个周期内的 服务时间 。我们假定顾客产生的计算需求是独立同分布的,其平均值是自身 quota 的 u_avg 倍。顾客在每个周期得不到满足的计算需求会一直累积,它每个周期向服务台提交的服务时间取决于它自身的计算需求和系统允许的最大 CPU time(即其 quota 加上之前周期累积的 token)。
最后, CPU Burst 技术中有一项可调参数 buffer ,表示允许累积的 token 上限。它决定了每个 cgroup 的瞬时突发能力,我们将其 大小用 quota 的 b 倍 表示。
我们对上述定义的参数作出了如下设置:
distribution
计算需求产生的分布
负指数、帕累托
u_avg
平均产生的计算需求
10%-90%
cgroup(容器)个数
10、20、30
令牌桶的buffer大小(相对于其quota的倍率)
100%、200%、∞
负指数分布是排队论模型中最常见、最多被使用的分布之一。其密度函数为 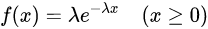 ,其中
,其中 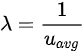 。
。
帕累托分布是计算机调度系统中比较常见的分布,且它能够模拟出较大的延迟长尾,从而体现 CPU Burst 的效果。其密度函数为 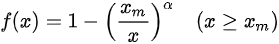 。为了抑制尾部的概率分布使其不至于过于夸张,我们设置了
。为了抑制尾部的概率分布使其不至于过于夸张,我们设置了 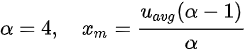 ,此时当 u_avg=30% 时可能产生的最大计算需求约为 500%。
,此时当 u_avg=30% 时可能产生的最大计算需求约为 500%。
数据展示
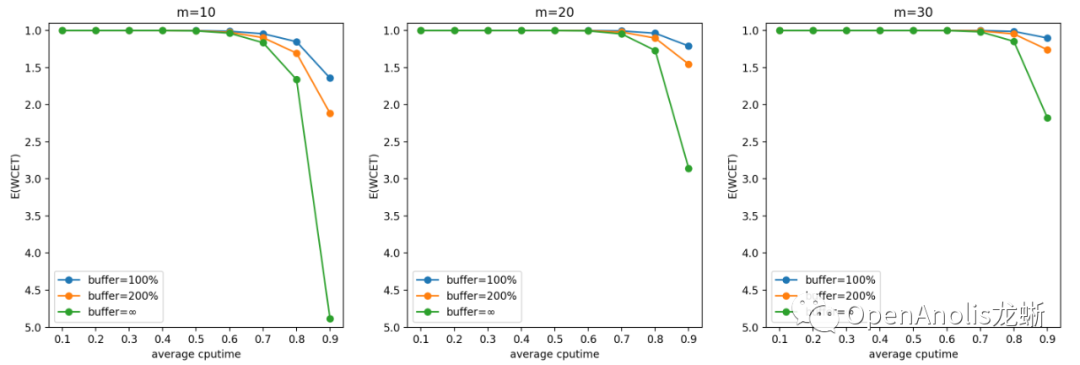
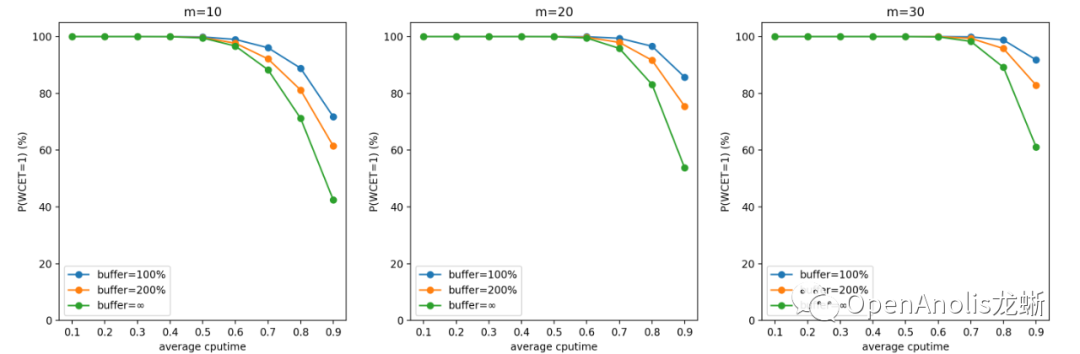
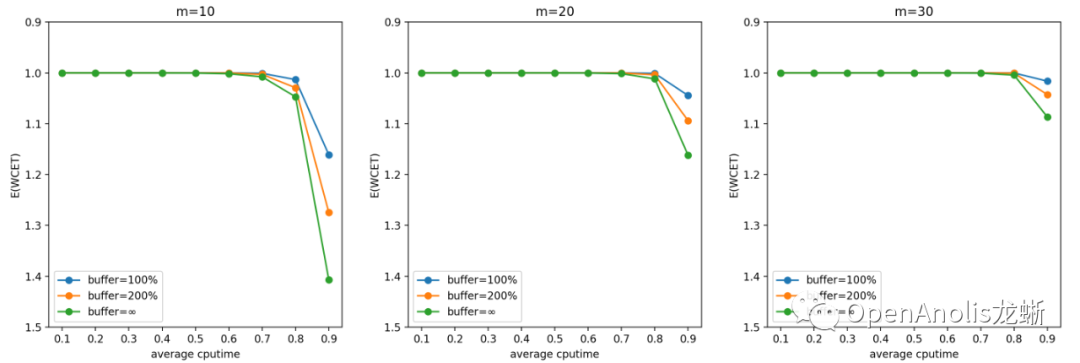
按上述参数设置进行蒙特卡洛模拟的结果如下所示。我们将第一张(WCET 期望)的图表 y 轴进行颠倒来更好地符合直觉。同样地,第二张图表(WCET 等于 1 的概率) 表示调度的实时性得到保证的概率,以百分制表示 。
负指数分布
帕累托分布
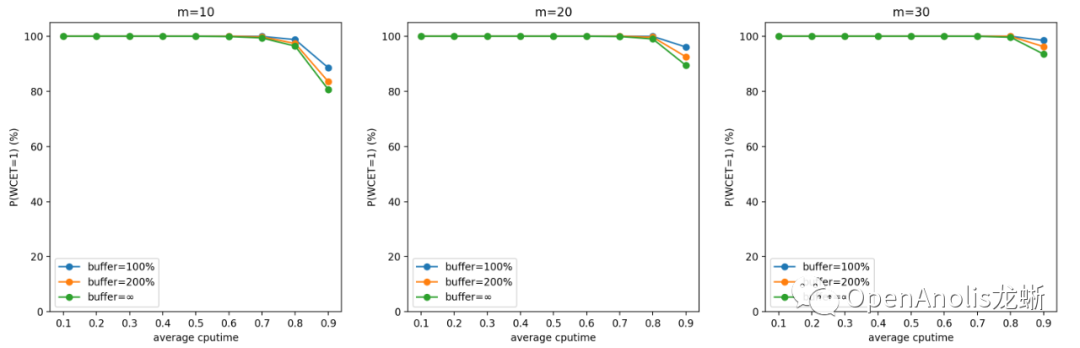
结论
一般来说,u_avg(计算需求的负荷)越高,m(cgroup数量)越少,WCET 越大 。前者是显然的结论,后者是因为独立同分布情况下任务数量越多,整体产生需求越趋于平均,超出 quota 需求的任务和低于 quota 从而空出 cpu 时间的任务更容易互补。
提高 buffer 会使得 CPU Burst 发挥更好的效果, 对单个任务的优化收益更明显;但同时也会增大 WCET,意味着增加对相邻任务的干扰。这也是符合直觉的结论。
在设置 buffer 大小时,我们建议根据具体业务场景的计算需求(包括分布和均值)和容器数量,以及自身需求来决定。 如果希望增加整体系统的吞吐量,以及在平均负荷不高的情况下优化容器性能, 可以增大 buffer;反之如果希望保证调度的稳定性和公平性,在整体负荷较高的情况下减少容器受到的影响,可以适当减小 buffer。
一般而言,在低于 70% 平均 CPU 利用率的场景中,CPU Burst 不会对相邻容器造成较大影响。
模拟工具与使用方法
说完了枯燥的数据和结论,接下来介绍可能有许多读者关心的问题:CPU Burst 会不会对我的实际业务场景造成影响?为了解决这个疑惑,我们将蒙特卡洛模拟方法所用工具稍加改造,从而能帮助大家在自己的实际场景中测试具体的影响~
工具可以在这里获取:
https://codeup.openanolis.cn/codeup/yingyu/cpuburst-simulator
详细的使用说明也附在 README 中了,下面让我们看一个具体的例子吧。
小A想在他的服务器上部署 10 台容器用于相同业务。为了获取准确的测量数据,他先启动了一台容器正常运行业务,绑定到名为 cg1 的 cgroup 中,不设限流以获取该业务的真实表现。
然后调用 sample.py 进行数据采集:(演示效果只采集了 1000 次,实际建议有条件的情况下采集次数越大越好)

这些数据被存储到了./data/cg1_data.npy 中。最后输出的提示说明该业务平均占用了约 6.5% 的 CPU,部署 10 台容器的情况下总的平均 CPU 利用率约为 65%。(PS:方差数据同样打印出来作为参考,也许方差越大,越能从 CPU Burst 中受益哦)
接下来,他利用 simu_from_data.py 计算配置 10个 和 cg1 相同场景的 cgroup 时,将 buffer 设置为 200% 的影响:

根据模拟结果,开启 CPU Burst 功能对该业务场景下的容器几乎没有负面影响,小A可以放心使用啦。
想要进一步了解该工具的用法,或是出于对理论的兴趣去改变分布查看模拟结果,都可以访问上面的仓库链接找到答案~
关于作者
常怀鑫(一斋),阿里云内核组工程师,擅长CPU调度领域。
丁天琛(鹰羽),2021年加入阿里云内核组,目前在调度领域等方面学习研究
加入社区 SIG
SIG 地址:
官网:https://openanolis.cn/sig/java/doc/216166872482840581

—— 完 ——
加入龙蜥社群
加入微信群:添加社区助理-龙蜥社区小龙(微信:openanolis_assis),备注【龙蜥】拉你入群;加入钉钉群:扫描下方钉钉群二维码。欢迎开发者/用户加入龙蜥社区(OpenAnolis)交流,共同推进龙蜥社区的发展,一起打造一个活跃的、健康的开源操作系统生态!
关于龙蜥社区
龙蜥社区(OpenAnolis)是由企事业单位、高等院校、科研单位、非营利性组织、个人等按照自愿、平等、开源、协作的基础上组成的非盈利性开源社区。龙蜥社区成立于2020年9月,旨在构建一个开源、中立、开放的Linux上游发行版社区及创新平台。
短期目标是开发龙蜥操作系统(Anolis OS)作为CentOS替代版,重新构建一个兼容国际Linux主流厂商发行版。中长期目标是探索打造一个面向未来的操作系统,建立统一的开源操作系统生态,孵化创新开源项目,繁荣开源生态。
龙蜥OS 8.4已发布,支持x86_64和ARM64架构,完善适配Intel、飞腾、海光、兆芯、鲲鹏芯片。
欢迎下载:
https://openanolis.cn/download
加入我们,一起打造面向未来的开源操作系统!
https://openanolis.cn
本文分享自微信公众号 - OpenAnolis龙蜥(OpenAnolis)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK