

决策树可视化方法与技巧
source link: https://www.biaodianfu.com/decision-tree-visualizations.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

决策树相对其他算法有一个优点是可以对决策树模型进行可视化。决策树又分为分类树和回归树,前者用于预测分类后者用于预测数值。决策树的可视化可以帮助我们非常直观的了解算法细节。但在具体使用过程中可能会遇到一些问题。以下是整理的一些注意事项。
可视化工具Graphviz
Graphviz是一个开源的图(Graph)可视化软件,采用抽象的图和网络来表示结构化的信息。在数据科学领域,Graphviz的一个用途就是实现决策树可视化。在使用Graphviz之间还是有些门道。如果使用pip install graphviz安装会出现如下报错:
ExecutableNotFound: failed to execute ‘dot’, make sure the Graphviz executables are on your systems’ PATH
解决方式是安装Graphviz的可执行包,并在环境变量的PATH添加安装路径。具体使用方法:
使用export_graphviz 将树导出为 Graphviz 格式
from sklearn import tree
from sklearn.datasets import load_iris
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf.fit(iris.data, iris.target)
with open("iris.dot", 'w') as f:
tree.export_graphviz(clf, out_file=f)
这里会生成一个纯文本文件iris.dot,你可以直接打开查看,具体内容类似:
digraph Tree {
node [shape=box] ;
0 [label="X[2] <= 2.45\ngini = 0.667\nsamples = 150\nvalue = [50, 50, 50]"] ;
1 [label="gini = 0.0\nsamples = 50\nvalue = [50, 0, 0]"] ;
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
2 [label="X[3] <= 1.75\ngini = 0.5\nsamples = 100\nvalue = [0, 50, 50]"] ;
0 -> 2 [labeldistance=2.5, labelangle=-45, headlabel="False"] ;
3 [label="X[2] <= 4.95\ngini = 0.168\nsamples = 54\nvalue = [0, 49, 5]"] ;
2 -> 3 ;
4 [label="X[3] <= 1.65\ngini = 0.041\nsamples = 48\nvalue = [0, 47, 1]"] ;
3 -> 4 ;
5 [label="gini = 0.0\nsamples = 47\nvalue = [0, 47, 0]"] ;
…
将.dot文件转换为可视化图形
为了有更好的可视化效果,可以使用graphviz可执行包中的dot程序将其转化为可视化的PDF文档。
具体方法为执行如下命令:
dot -Tpdf iris.dot -o iris.pdf
转化完PDF后打开的图形如下:
使用命令行非常的麻烦,可以采取的方式是安装pydotplus(pip install pydotplus)来生成PDF。另外在在使用tree.export_graphviz导出数据是还可以另外加一些参数,使得图片看起来更容易理解:
from sklearn import tree
from sklearn.datasets import load_iris
import pydotplus
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf.fit(iris.data, iris.target)
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf('iris.pdf')
sklearn.tree.export_graphviz(decision_tree, out_file=None, *, max_depth=None, feature_names=None, class_names=None, label='all', filled=False, leaves_parallel=False, impurity=True, node_ids=False, proportion=False, rotate=False, rounded=False, special_characters=False, precision=3)
传入参数:
- decision_tree:决策树对象
- out_file:输出文件的句柄或名称。
- max_depth:数的最大深度
- feature_names:特征名称列表
- class_names:类别名称列表,按升序排序
- label:显示纯度信息的选项{‘all’, ‘root’, ‘none’}
- filled:绘制节点以指示分类的多数类、回归值的极值或多输出的节点的纯度。
- leaves_parallel:在树的底部绘制所有叶节点。
- impurity:是否显示纯度显示
- node_ids:是否显示每个节点的ID号
- proportion:将“值”和 “样本量”的显示分别更改为比例。
- rotate:设置未True是从左往右绘制,False是从上往下绘制。
- rounded:设置未True时,使用圆角进行绘制。
- special_characters:设置为时False,忽略特殊字符以实现PostScrip兼容性
- precision:每个节点数值的精度
要是觉得生成PDF查看比较麻烦,可采取生成图片:
from sklearn import tree
from sklearn.datasets import load_iris
import pydotplus
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf.fit(iris.data, iris.target)
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png("dtree.png")
scikit-learn的tree.plot_tree
从scikit-learn 版本21.0开始,可以使用scikit-learn的tree.plot_tree方法来利用matplotlib将决策树可视化,而不再需要依赖于难以安装的dot库(无需安装Graphviz)。下面的Python代码展示了如何使用scikit-learn将决策树可视化:
from sklearn import tree
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf.fit(iris.data, iris.target)
plt.figure(figsize=(10, 8))
tree.plot_tree(clf,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
)
plt.show()
由于使用起来与tree.export_graphviz类似,这里就不再详述。
美化输出dtreeviz
dtreeviz是一个美化输出的组件,在使用起来非常的简单:
from sklearn import tree
from sklearn.datasets import load_iris
from dtreeviz.trees import dtreeviz
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf.fit(iris.data, iris.target)
viz = dtreeviz(clf,
x_data=iris.data,
y_data=iris.target,
target_name='class',
feature_names=iris.feature_names,
class_names=list(iris.target_names),
title="Decision Tree - Iris data set")
viz.save('dtreeviz.svg')
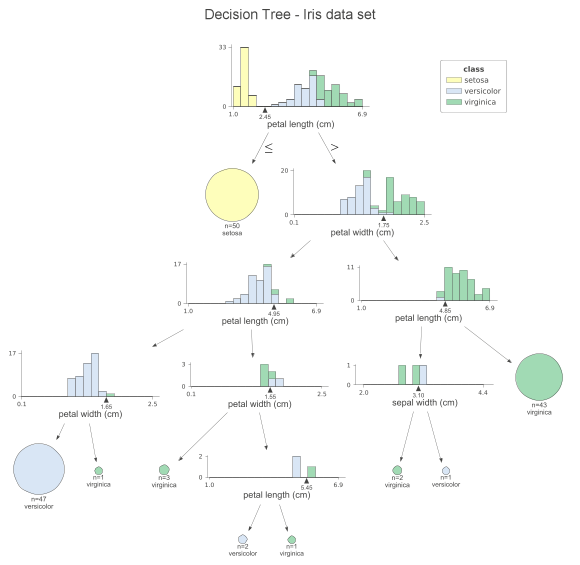
每个节点上,我们都可以看到用于分割观测值的特征的堆叠直方图,并按类别着色。通过这种方式,我们可以看到类是如何分割的。x轴的小三角形是拆分点。叶节点用饼图表示,饼图显示叶中的观察值属于哪个类。这样,我们就可以很容易地看到哪个类是最主要的,所以也可以看到模型的预测。我们也可以为测试集创建一个类似的可视化,只需要在调用函数时替换x_data和y_data参数。如果你不喜欢直方图并且希望简化绘图,可以指定fancy=False来接收以下简化绘图。

dtreeviz的另一个方便的功能是提高模型的可解释性,即在绘图上突出显示特定观测值的路径。通过这种方式,我们可以清楚地看到哪些特征有助于类预测。使用下面的代码片段,我们突出显示测试集的第一个样本的路径。
from sklearn import tree
from sklearn.datasets import load_iris
from dtreeviz.trees import dtreeviz
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf.fit(iris.data, iris.target)
viz = dtreeviz(clf,
x_data=iris.data,
y_data=iris.target,
target_name='class',
feature_names=iris.feature_names,
class_names=list(iris.target_names),
title="Decision Tree - Iris data set",
X=iris.data[0])
viz.save('dtreeviz.svg')
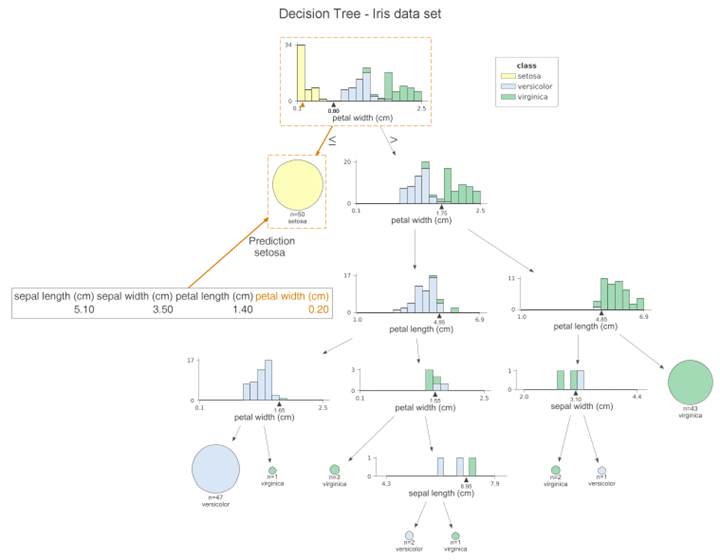
这张图与前一张非常相似,然而,橙色突出清楚地显示了样本所遵循的路径。此外,我们可以在每个直方图上看到橙色三角形。它表示给定特征的观察值。我们还可以通过设置orientation=“LR”从上到下再从左到右更改绘图的方向。
最后,我们可以用通俗易懂的英语打印这个观察预测所用的决定:
from sklearn import tree
from sklearn.datasets import load_iris
from dtreeviz.trees import dtreeviz
from dtreeviz.trees import explain_prediction_path
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf.fit(iris.data, iris.target)
viz = dtreeviz(clf,
x_data=iris.data,
y_data=iris.target,
target_name='class',
feature_names=iris.feature_names,
class_names=list(iris.target_names),
title="Decision Tree - Iris data set",
X=iris.data[0])
viz.save('dtreeviz.svg')
# 输出解释
print(explain_prediction_path(clf, iris.data[0], feature_names=iris.feature_names, explanation_type="plain_english"))
# petal width (cm) < 0.8
前文已经介绍了决策树分类示例,接下来需要的看下决策树回归:
from sklearn import tree
from sklearn.datasets import load_boston
from dtreeviz.trees import dtreeviz
boston = load_boston()
reg = tree.DecisionTreeRegressor(max_depth=3)
reg.fit(boston.data, boston.target)
viz = dtreeviz(reg,
x_data=boston.data,
y_data=boston.target,
target_name='price',
feature_names=boston.feature_names,
title="Decision Tree - Boston housing",
show_node_labels=True)
viz.save('dtreeviz.svg')
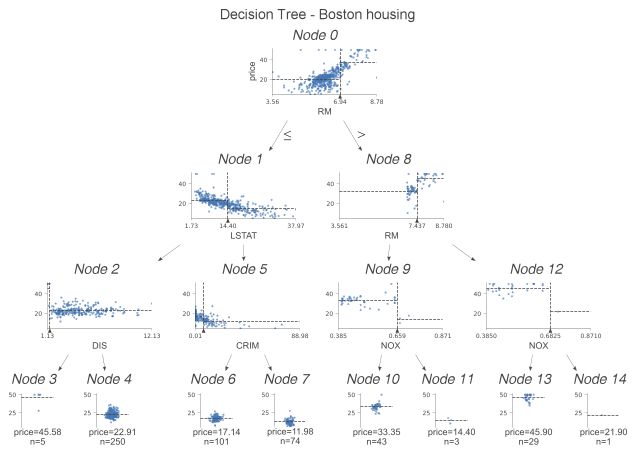
我们研究下分类树和回归树之间的区别。这一次不是直方图,而是检查用于分割和目标的特征散点图。我们在这些散点图上,看到一些虚线。其解释如下:
- 水平线是决策节点中左右边的目标平均值。
- 垂直线是分割点。它与黑色三角形表示的信息完全相同。
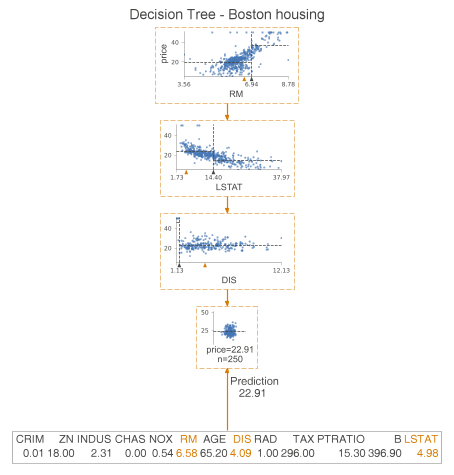
在叶节点中,虚线表示叶内目标的平均值,这也是模型的预测。我们可以更进一步,只绘制用于预测的节点。为此,我们指定show_just_path=True。下图仅显示上面树中选定的节点。
from sklearn import tree
from sklearn.datasets import load_boston
from dtreeviz.trees import dtreeviz
boston = load_boston()
reg = tree.DecisionTreeRegressor(max_depth=3)
reg.fit(boston.data, boston.target)
viz = dtreeviz(reg,
x_data=boston.data,
y_data=boston.target,
target_name='price',
feature_names=boston.feature_names,
title="Decision Tree - Boston housing",
X=boston.data[0],
show_just_path=True)
viz.save('dtreeviz.svg')
参考链接:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK