

风险管理 | 因子有效性的评估和量化指标
source link: https://zhuanlan.zhihu.com/p/401407917
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

风险管理 | 因子有效性的评估和量化指标
一直以来,投资者普遍认为因子代表某种系统性风险,它能够解释投资组合的收益或帮助进行资产定价。追踪好有效因子,或许可以帮助获得额外的 alpha 收益。Smart Beta 遵循了这种思路,通过一系列历史数据测算结果来帮助编制因子指数,试图以现在的模型经验,去构造未来的收益图像,获得风险溢价。因子在量化投资中扮演着非常重要的角色。价值因子、质量因子、低波动因子等是被验证过的有效因子。在这些光鲜的、能对资产进行定价的“有效因子”的背后,仍旧有着无数的被验证过无效或者尚且待验证的因子。
在《风险管理 | 风险和收益中的取与舍》中,我们提到了 beta 因子和 alpha 因子。上述的这些有效因子是 beta 因子,用于资产定价、解释风险溢价,而 alpha 因子则更关注其带来 alpha 收益的能力。因此,在评估一个因子的有效性时,通常认为 beta 因子能够进行资产定价,或 alpha 因子在一定时间内能够解释未来的股票收益。学术届更关注的是 beta 因子的检验——解释风险溢价的能力,热衷于追逐因子测试的结果显著性;而将因子用于投资实践的人则更关注 alpha 因子的检验——带来 alpha 收益的能力,看重因子预测股票收益的能力及稳定性。因此,衡量一个新的因子最终走向有效或无效的方法在不同领域中是有所区别的。
学术角度,P值帮助判别因子有效性
01 P 值确定统计显著性
从学术的角度来看,衡量 beta 因子有效性的一把重要尺子是 p 值。p 值的作用是在假设检验中确定结果的统计显著性,这也是假设检验的最终目标。p 值表示在原假设 H0 下出现观察结果或比之更极端情形的概率(Fisher1925)。
通俗地讲,原假设 H0 就像是我们提出的声明,一系列的数据信息是我们要查找的证据,p 值代表的是支持这个“声明”成立的证据的强度。p 值小,证据强度小,说明在假设声明成立的情况下,这个证据不太能被看到(随机变量取值与观测值相差较多),推翻这个声明不会产生太大的错误——这个时候就应该怀疑这个声明错了,原假设不成立。但假如能看到这个证据(随机变量取值与观测值接近),说明声明很可能是成立的——无法拒绝原假设。所以,p 值并非是原假设成立的概率,而是支持原假设的证据被看到的概率。除了 p 值,通常还会有一个显著性水平,它是人们设定的阈值,是判定证据的有效和无效的边界。低于这个阈值,则认为声明无效。
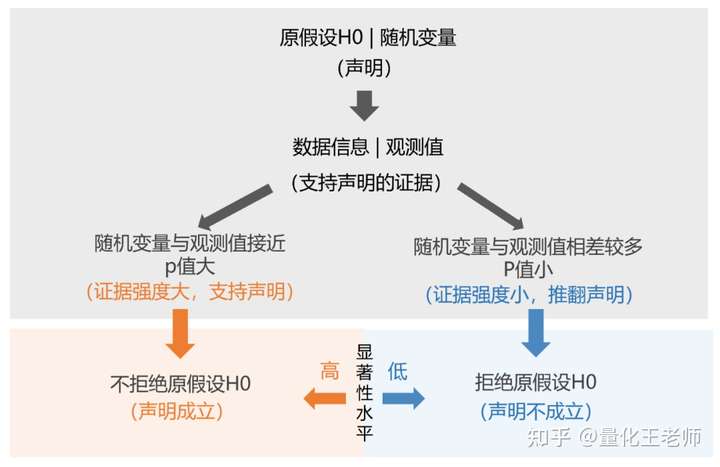
02 p 值评估因子有效性
因子走完构造流程后,需要对其有效性进行假设检验。学术界研究因子能否获得超额收益时,一般的流程如下:
- 首先提出原假设 H0:通过因子 A 选股无法获得超额收益。
- 使用因子 A 选股、配置多空投资组合,然后用某主流的多因子定价模型来检验该因子是否能够获得定价模型无法解释的超额收益。
- 比较因子 A 超额收益的 p 值是否小于给定的显著性水平,从而决定是否拒绝原假设。拒绝原假设意味着“因子 A 能够获得超额收益”。
可见,p 值出现在检验因子预期收益率时,表示在原假设 H0 下随机变量 X 取到比 x 更极端的数值的条件概率。
- 原假设H0:因子的预期超额收益率为零。
- 随机变量X :因子的预期收益率取值。
- x :观测值,是随机变量 X 在样本数据中观测到的值,我们希望在样本中观测到预期收益为 0 来支持原假设 H0,此时 x=0。
- 更极端的数值:因子的预期收益率为 0 甚至为负的情况。
如果随机变量 X 与观测值 x 越一致,说明检验现象与零假设越接近,则越没有理由拒绝零假设。p 值 =0.05 意味着在原假设 H0(因子的预期收益率为零)下观测到比 x 更极端的收益(因子的预期收益率为 0,甚至为负收益)的条件概率为 5%;假如 p 值 =0.01,意味着在原假设 H0 下观测到比 x 更极端的收益的条件概率仅有 1%,也就是观测到“因子预期收益为零甚至为负”这个事件和原假设 H0 越不相符,因而越倾向于拒绝原假设。
因此,p 值帮助人们评估何时拒绝“因子的预期收益率为零”这个原假设。p 值越低,越倾向于拒绝原假设,越说明这个因子越有效。在学术界,p 值越低,因子越显著,研究成果越抢眼,越有可能得到更高的引用,期刊的影响因子越高,期刊的学术声望越高。因此学术界普遍偏向于寻找“有效因子”,也就是超低 p 值因子。
03 有效与无效的边界
在 p 值如何判别因子有效性这个非黑即白的问题上,需要一个东西来进行界定,人为设定的显著性水平就是这个判定证据有效和无效的边界。高于这个阈值,不拒绝“因子的预期收益率为零”原假设,认为因子无效;低于这个阈值,则拒绝“因子的预期收益率为零”的原假设,认为因子能够产生收益,因子有效。投资思维和理念因人而异,每个人心中都有自己的显著性水平数值。通常认为 p 值小于 0.05 时非常显著,可以推翻原假设。
需要注意的是,p 值小,并不代表原假设就是假的,也不代表备择假设(与原假设方向相反的条件)就是真的,它表示的仅仅只是能够获取到的数据出现的概率,表现数据和假设之前的关系,而非假设本身,原假设这时候是一个已知条件。
以上方法通常用于检验 beta 因子资产定价的能力,在实践中投资者都希望赚钱,因此更关注因子获取 alpha 收益的能力——alpha 因子的风险溢价能力。
在金融量化领域,根据不同的测度和应用领域,有 P-Quant 和 Q-Quant 之分。
- P-Quant 是买方的心头好,专注于组合风险管理。P-Quant 基于真实的数据,测度是真实概率P,上述 p 值就是基于真实数据中统计得到的。在 P-Quant 的眼里,更重要的是“明确我要承担哪些风险”,重数据轻模型,希望能够根据历史真实数据去预测未来走势后确定交易策略。
- Q-Quant 是卖方的心头好,专注于衍生品定价。卖方卖出自己的产品时需要有一个定价,此时就做虚构的风险中性概率Q测度。假设投资者不关心风险,对风险资产和无风险资产的偏好是一样的,卖方在这样的“风险中性”的理论假设下用无风险利率测算资产价格。在 Q-Quant 眼里,更重要的是“我如何不承担风险”,重模型轻数据,希望利用数据模型来了解资产当前价值,支持产品的售出。
实践角度,因子预测股票收益的能力更被重视
在投资实践中,因子有效则希望因子能够帮助在未来获得收益,从这个角度来看,IC、IR 是评估 alpha 因子有效性的一把尺子。
- IC:Information Coefficient,信息系数
- IR:Information Ratio,信息比率
01 IC 评估因子的选股能力
IC 值是因子暴露与股票下期收益的截面相关系数。
Normal IC:又称为皮尔逊相关系数,给定股票池,t-1 期的因子暴露和 t 期的因子收益之间的截面相关系数。
Rank IC:又称为斯皮尔曼相关系数,给定股票池,t-1 期的因子暴露的排序值和 t 期的因子收益的排序值之间的截面相关系数。
进行 IC 分析前需要根据因子进行选股,用于分析的股票数量最好是大于 30支,过少的数据信息得到的结果没有太多统计意义。选股时,将股票池中的股票按照因子暴露(因子值)高低进行排序然后分组,即可得到每个分组的收益情况。
股票收益率分组展示 图片来源:RicequantIC 分析通常的做法是取一段时间为调仓周期,计算该期的因子暴露(因子值)和对应的下期收益,比如取 20 个交易日为一期,那下期就是下一个 20 个交易日,这样就有 20 个该期因子值(若是 RankIC 则是因子值排名)和 20 个对应的下期收益(或排名),将这两个数列求一个相关系数,这个系数就是该期的 IC。从某个历史时间点到目前,有多个调仓周期,就有多个 IC 值,由此算出 IC 均值来衡量该因子对过去整个时间段的有效性。
IC 值介于 -1 和 1 之间,反映出因子对下期收益率的预测能力,IC 值越高,该因子在该期对股票收益的预测能力越强。当 IC 为 1 时,表示该因子选出来的股票,分数最高的股票在下个调仓周期中涨幅最大。若一个因子的 IC 值 >0.05,则可以视为有效因子,IC 值 >0.1 时, 就可以认为因子是特别好的阿尔法因子;当 IC 均值接近 0,可视为无效因子。
图源:米筐在线量化协作平台02 IR 评估因子选股能力的稳定性
IC 可以反映因子的选股能力,而 IR 用来表示选股能力的稳定性。我们在进行回测时,有多个调仓周期,每个调仓期可以计算出一个 IC 值,这多个调仓周期的 IC 均值与标准方差的比值就是 IR。
IC 数值浮动越小,IC 的标准差越小,IR 越大,说明在这多个调仓周期内 IC 值的预测能力越稳定。当 IR 大于 0.5 时,因子稳定获取超额收益的能力较强。
图源:米筐在线量化协作平台米筐本地量化投研套件 RQSDK 的组件之一——因子投研框架 RQFactor 提供了因子检验 API,设定好因子的定义、起止日期、调仓周期等条件后可以直接获取 IC 和 IR 数值,有效加快因子开发和检验。感兴趣的用户可以查看《量化因子投研 | 从因子编写到有效性检验》。
追踪有效因子,规避非有效因子
一个 beta 因子被评估为有效后,将被越来越多人熟知并应用,这将让它在市场中越来越有效,意在获取 alpha 收益的投资者也在此基础上去挖掘更多 alpha 因子,进一步评估因子在实践中获取的风险溢价能力。如今,学术界已经挖出了超过 400 个因子,这背后不免部分存在错误定价(股价偏离内在价值)和数据窥探(样本内过拟合,因子在样本外明显失效)等的嫌疑,可能会混淆因子风险溢价的范围。学术界发表的因子并非完全可用于投资,正如上篇文章讲到,因子暴露和可投资性不可兼得,实际投资时需要更多地考虑做空限制等。目前投资领域中常见的有价值因子、质量因子、低波动因子等。
资料来源:《因子投资:方法与实践》一个因子被验证为有效,是某历史时间段内的数据所呈现出来的规律,并无法代表它在未来的市场中也一定会按照该规律发展。以上只是众多检验方式中较常来评估选股效果的方法,其他的方法还有 t 值评估、换手率分析等。这些评估方法也应当避免因子在样本内过拟合,否则将导致样本外失效的风险。
有效因子可以让收益变得明朗,而正确识别非有效因子也是一项重要工作。在检验错误定价因子时,可以观察到在投资组合构建后的一段时间内,其累计收益会持续上升,说明这是一个价格发现的过程,睿智的投资者在其中的某些时点可以通过套利操作获得短期收益,但随着因子逐渐被曝光,错误定价效应也逐渐减弱甚至消失。对于通过数据窥探获得的“虚假”因子,考虑用样本外的新数据去对因子进行再次检验,有效识别“样本外失效”的因子,躲开过拟合,有利于在样本外摒弃它们,防止在实际投资中遭受损失。对于无效因子,则考虑做好规避工作。
在实盘中,通过因子应该选多少股票、仓位是多少、调仓频率如何、适应怎样的市场条件等问题是因子投资能否成功的关键。此外,投资者情绪也会影响到市场表现,短期内的“因子有效”背后可能是投资者情绪的干扰。投资策略没有标准答案,对于难以捉摸的市场,我们应该时刻跟踪因子在实际投资中的表现,重视因子的作用范围和时效,注意因子失效。
多个单因子之间存在相关性
一个 alpha 因子被市场熟知、变得有效之后,就会变成 beta 因子被用于资产定价,解释投资组合收益。但解释投资组合收益只有一个因子是不充分的,因为其收益受到多个因素影响,是多个因子作用的结果,这就需要多个因子作为选股标准。多个因子之间会产生复杂的互动效应,称为“相关性”,单纯地用多个因子叠加所进行的测试结果可能会有误差。单因子的表现与多因子模型之间并非机械的 “1+1=2” 关系,一个单因子单独测试表现不好,但放在多因子模型中可能也会发挥出它的作用,一个检验效果好的因子放在多因子模型中却也可能表现差强人意。因此,构建一个多因子模型时需要考虑因子之间的联动,多做测试,这样才能更好地选因子和选资产,进而提高整个多因子模型的收益。
参考资料:《因子投资:方法与实践》
针对因子,米筐提供了不同的投研工具以契合投资者的不同投资风格:
- RQBeta 风险模型
契合市场情况的风险测量和控制工具。投资者能够通过 RQBeta 快速获取风险因子暴露度、协方差及收益率,掌握投资组合的风格暴露、风险贡献和业绩归因,及时有效地进行风险管理。
- RQFactor 因子挖掘
灵活可靠的 alpha 因子投研框架。投资者能够借助 RQFactor 编写更复杂的函数进行因子开发和检验,更快地挖掘 alpha 因子。
以上投研工具与 RQData 金融数据 API、RQAlpha Plus 回测工具组成了米筐本地量化投研套件 RQSDK,欢迎各机构用户点击此处进行试用。
投资行为的盈亏依赖于您的独立思考和决策,本文所述观点并不构成投资或任何其他建议,Ricequant 不提供或推荐任何投资品种。股市有风险,投资需谨慎。
原创文章除特别声明外,欢迎非商业转载,敬请注明出处。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK