

Kunpeng BoostKit 使能套件:大数据场景如何实现“大鹏一日同风起”倍级性能提升?
source link: https://my.oschina.net/bailu1024/blog/5194165
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Kunpeng BoostKit 使能套件:大数据场景如何实现“大鹏一日同风起”倍级性能提升?
- 一、开源大数据与鲲鹏多核结构渊源
-
- 1.1、海量数据处理的难题
- 1.2、大数据并行计算特点天然匹配鲲鹏多核架构
- 二、开源大数据整体与组件介绍
-
- 2.1、大数据组件:Hadoop-HDFS 模块
- 2.2、大数据组件:Hadoop-Yarn 模块
- 2.3、大数据组件:Hadoop-MapReduce 模块
- 2.4、大数据组件:Spark 平台
- 三、鲲鹏 BoostKit 使能套件介绍
-
- 3.1、鲲鹏 BoostKit 是什么?
- 3.2、开源使能:开源软件可用、好用
- 3.3、基础加速:超越业界水平的应用性能
- 3.4、应用加速:极致事务倍级应用性能
- 四、BoostKit 在开源使能上的结果
-
- 4.1、全面支持开源大数据
- 4.2、开源社区接纳 ARM 生态
- 五、鲲鹏 BoostKit 如何应对大数据关键挑战?
-
- 5.1、遇到的问题
- 5.2、如何应对关键挑战?
- 六、BoostKit 机器学习/图算法的深度优化
-
- 6.1、算法深度优化实例
- 6.2、鲲鹏算法库
- 七、BoostKit 做了哪些深度优化?
-
- 7.1、鲲鹏亲和性优化效果
- 7.2、机器学习算法优化方案:分布式 SVD 算法
- 7.3、图分析算法优化方案:分布式 PageRank 算法
- 八、鲲鹏 BoostKit 机器学习&图算法的 Spark 性能加速实践
-
- 8.1、环境准备
- 8.2、环境配置
- 8.3、部署 Hadoop、Spark 等组件
- 8.4、算法库优化效果运行实践
-
- 8.4.1、运行 SVD 算法
- 8.4.2、运行 PageRank 算法
- 九、相关材料获取
-
- 9.1、鲲鹏 BoostKit
- 9.2、机器学习算法加速库
- 9.3、图算法加速库
在数据和经济时代,业务和数据的多样性需要新的计算架构,海量的数据增长也带来了更高的计算需求。那么在这个过程中,鲲鹏计算产业也正在成为更多计算场景的新一代 IP 基座。基于华为鲲鹏处理器构建的鲲鹏全栈 IT 技术实施设施行业应用以及服务,致力于为智能世界持续提供我们的先进算力支持,使得各个行业可以实现数字化转型。应用软件的迁移与优化一直是鲲鹏软件生态的难点和关键。本次鲲鹏 BoostKit 训练营为开发者介绍如何基于鲲鹏 BoostKit 使能套件实现应用性能的加速,并重点剖析性能优化技术和关键能力。

一、开源大数据与鲲鹏多核结构渊源
1.1、海量数据处理的难题
随着科技的发展,越来越多的行业需要采集更多的数据,如何对海量数据进行分析并得出我们想要的结果就成为了我们所面临的难题,而大数据技术的迅速发展使得这个问题迎刃而解。
1.2、大数据并行计算特点天然匹配鲲鹏多核架构
海量数据需要更高的并发度来加速数据处理,在数据集非常大的情况下,如果我们跑在单核(或者是顺序化)的执行场景下,可能执行过程无法进行或者是效率极其低下,这是我们无法接受的,所以海量的数据需要更高的并发度来处理,那么鲲鹏多核计算的特点就可以完美匹配这个需求,加速大数据的计算性能,提升大数据任务的并发度。
我们以 MapReduce 模型为例进行处理和计算,如下图所示,我们所采集的源数据是一段英文,我们需要计算这段话中每一个单词所出现的次数。
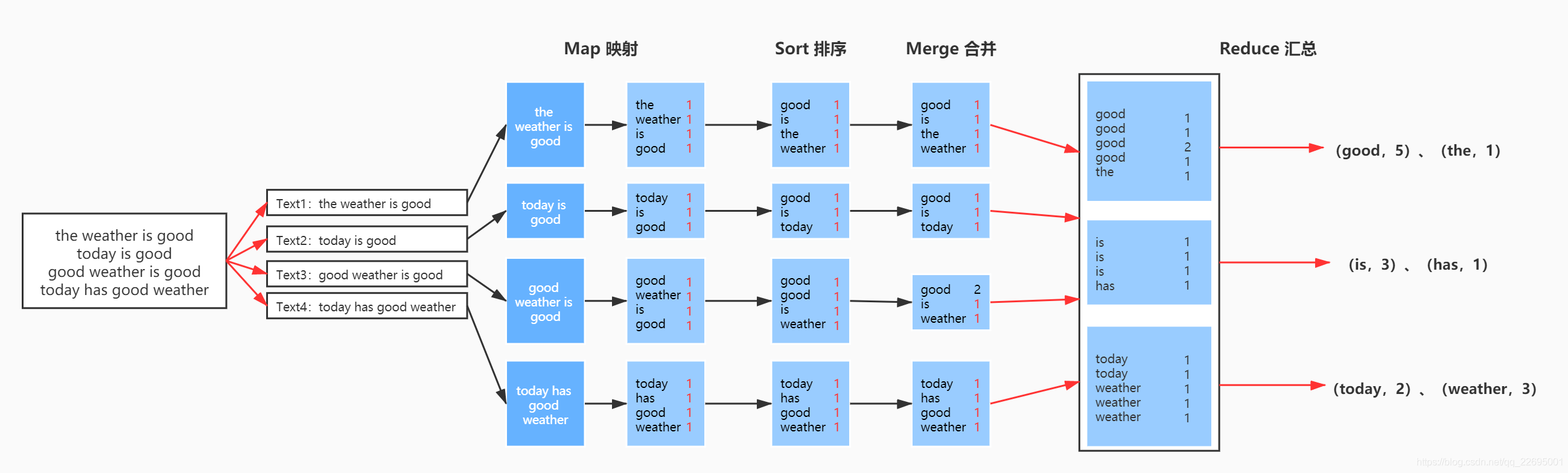
运行过程:首先我们对源数据进行拆分,然后 Map 映射到每一个节点上进行运算,之后进行 Sort 排序,Merge 合并,最后进行结果汇总 Reduce 以形成最终的结果。
可以看到,我们将大量的计算分发到各个节点之上,这就是分布式计算,也是我们所谓的“并发度”的概念。如果我们的并发度提高了,理论上来讲,我们整个模型的执行时间也会相应缩短。
二、开源大数据整体与组件介绍
上面我们介绍了开源大数据的概念以及相应的华为鲲鹏多核计算的特点,下面介绍我们在大数据开发中经常会使用到的一些组件。
2.1、大数据组件:Hadoop-HDFS 模块
HDFS 是 Hadoop 生态的三个核心模块组成之一,负责分布式存储。具体结构如下图所示:
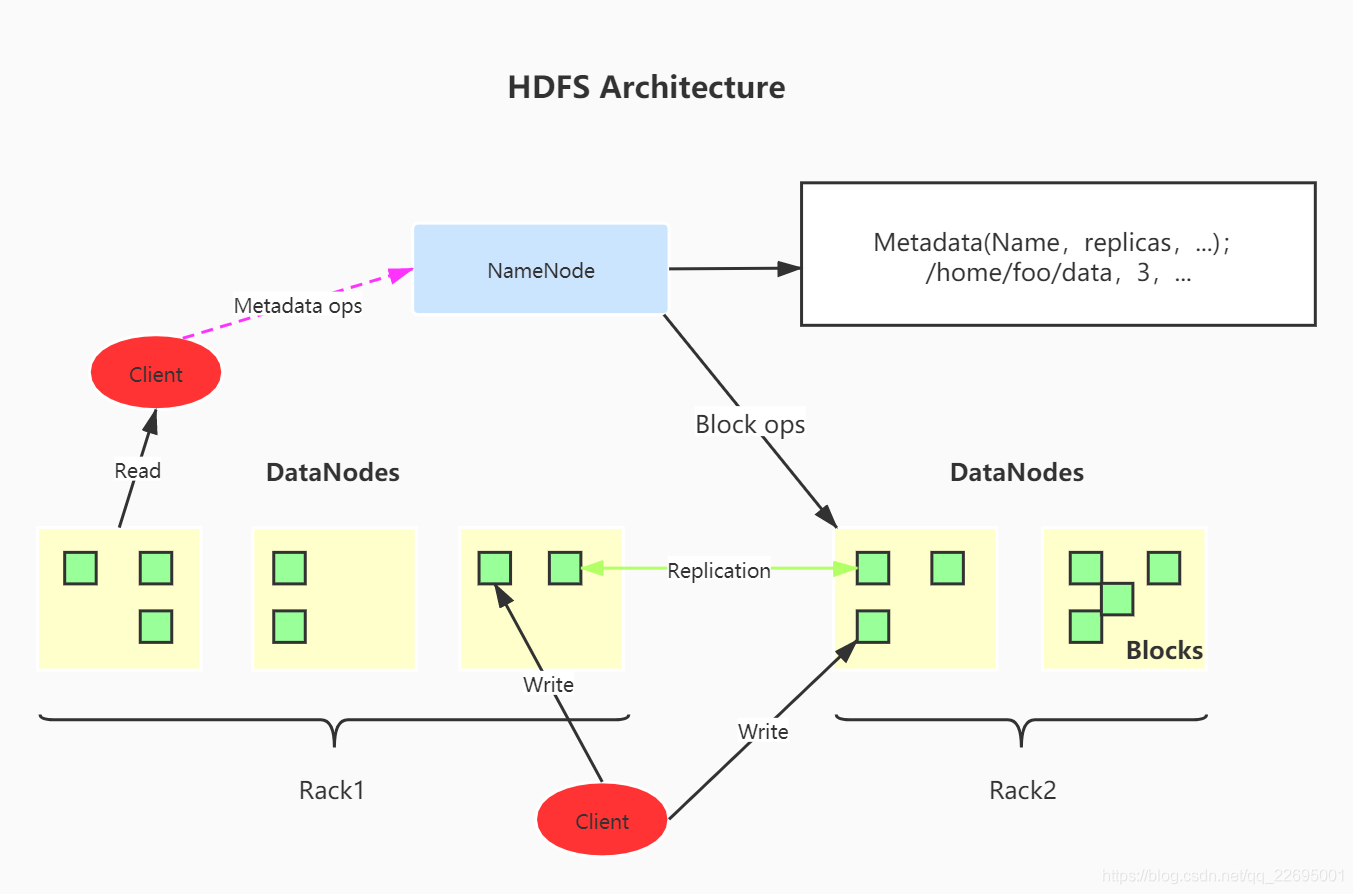
- HDFS:是一种分布式存储系统,采用 Master 和 Slave 的主从结构,主要由 NameNode 和 DataNode 组成。HDFS 会将文件按固定大小切成若干块,分布式存储在所有 DataNode 中,每个文件可以有多个副本,默认副本数为 3。
- NameNode:Master 节点,负责源数据的管理,处理客户端请求。
- DataNode:Slave 节点,负责数据的存储和读写操作。
使用流程:用户如果想要读取存储在 HDFS 中的数据,需要先找到 NameNode,通过 NameNode 来得知我们的数据存放在哪个 DataNode 之上,当 NameNode 找到具体的数据之后,将数据返回给用户。
2.2、大数据组件:Hadoop-Yarn 模块
Yarn 是 Hadoop 生态的三个核心模块组成之一,负责资源分配和管理。具体结构如下图所示:
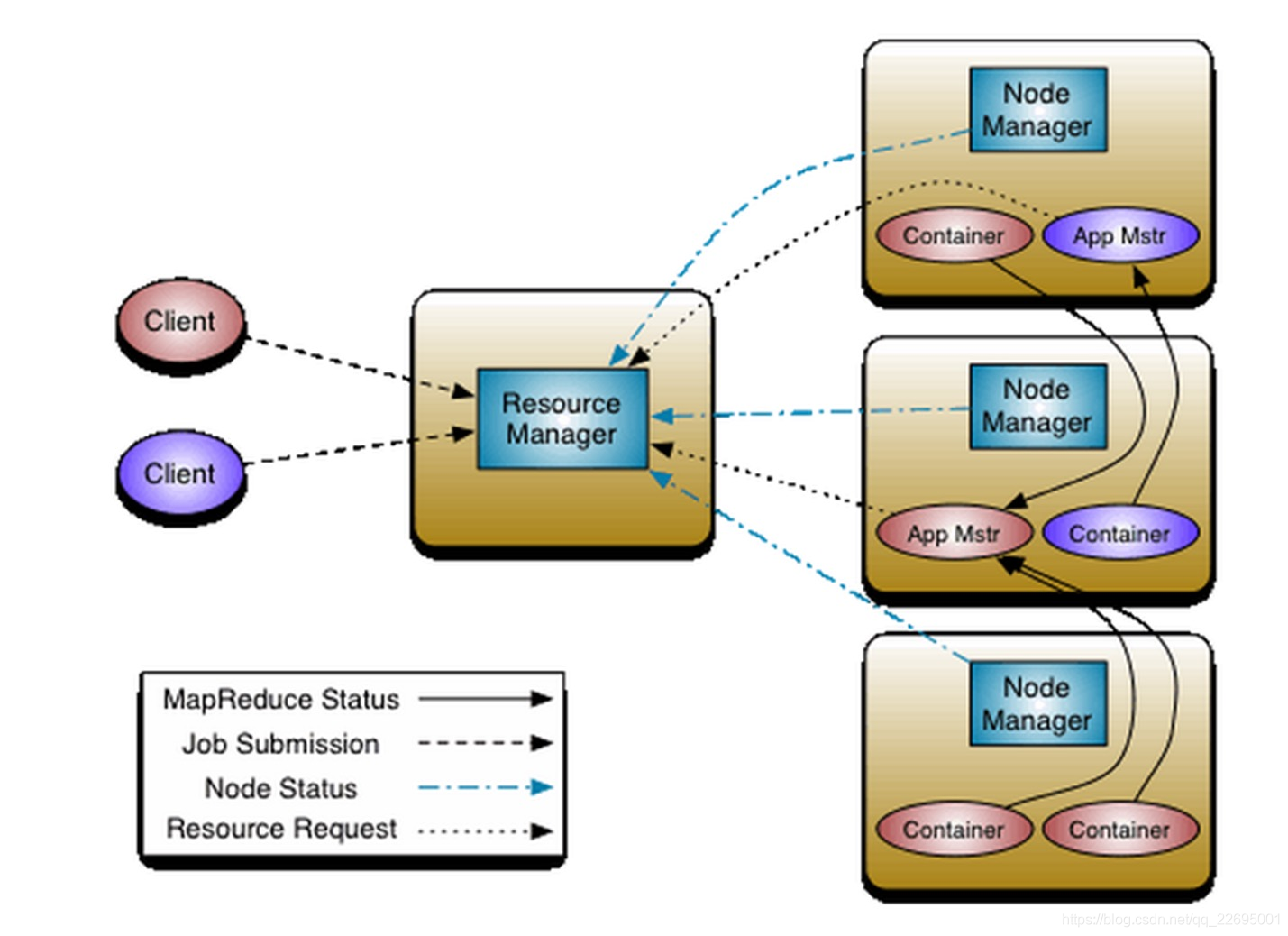
- Yarn:是一种分布式资源调度框架,采用 Master 和 Slave 的主从结构,主要由主节点 ResourceManager、ApplicationMaster 和从节点 NodeManager 组成,负责整个集群的资源管理和调度。
- ResourceManager:是一个全局的资源管理器,负责整个集群的资源管理和分配。
- NodeManager:运行在 Slave 节点,负责该节点的资源管理和使用。
- ApplicationMaster:当用户提交应用程序时启动,负责向 ResourceManager 申请资源和应用程序的管理,与 NodeManager 进行互动。用户在使用的情况下可以通过 ApplicationMaster 得知当前任务的进度、已经执行到哪些 Job。
- Container:Yarn 的资源抽象,是执行具体应用的基本单位,任何一个 Job 或应用程序必须运行在一个或多个 Container 中。
2.3、大数据组件:Hadoop-MapReduce 模块
MapReduce 是 Hadoop 生态的三个核心模块组成之一,负责分布式计算。具体结构如下图所示:
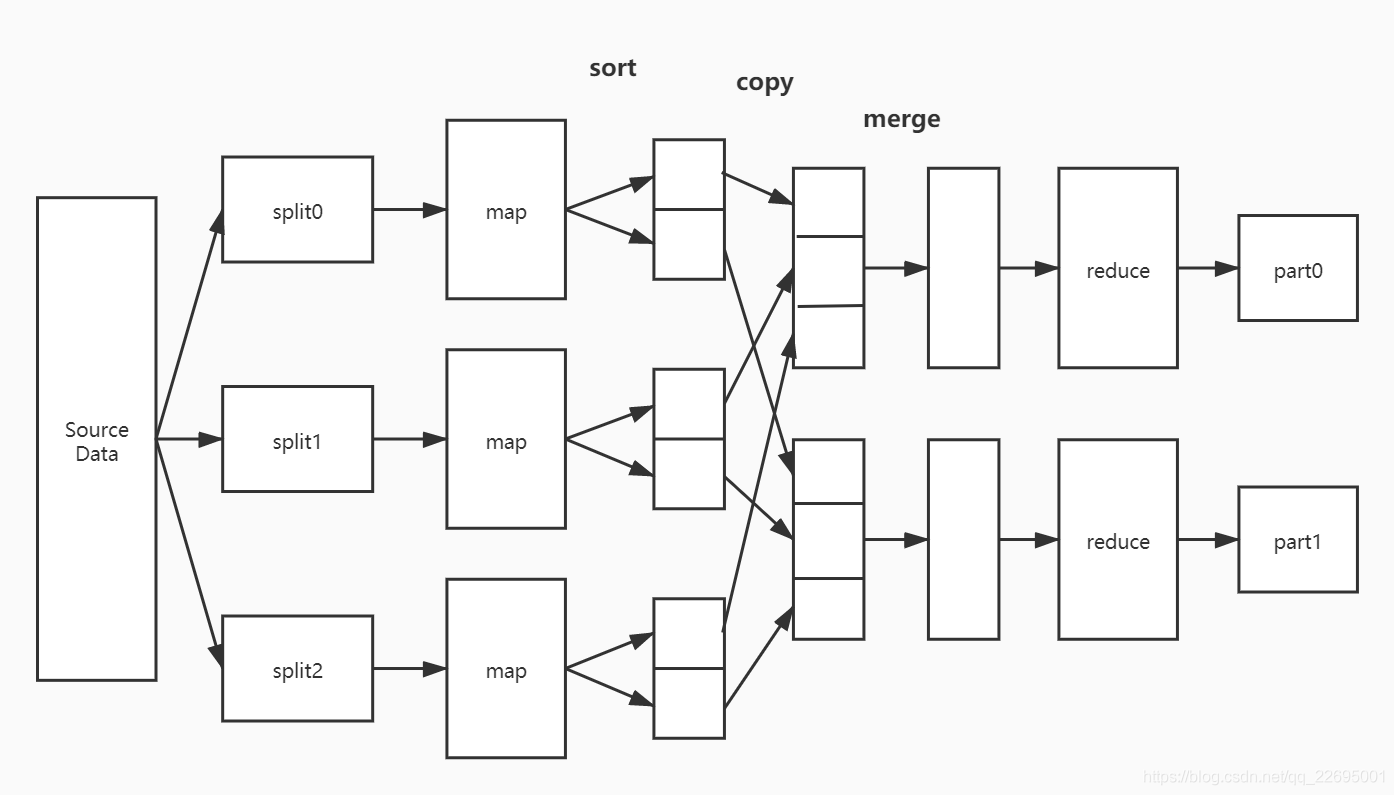
- MapReduce:是一种分布式计算框架,主要由 Map 和 Reduce 两个阶段组成。支持将一个计算任务划分为多个子任务,分散到各集群节点并行计算。
- Map 阶段:将初始数据分成多份,由多个 Map 任务并行处理。
- Reduce 阶段:收集多个 Map 任务的输出结果并进行合并,最终形成一个文件作为 Reduce 阶段的结果。
2.4、大数据组件:Spark 平台
Apache Spark 是用于大规模数据处理的统一分析引擎,具有可伸缩性、基于内存计算等特点,已经成为轻量级大数据快速处理的统一平台,各种不同的应用,如实时信息流处理、机器学习、交互式查询等,都可以通过 Spark 建立在不同的存储和运行系统上。具体结构如下图所示:

- Apache Spark 核心:Spark Core 是 Spark 平台的基础通用执行引擎,其所有其他功能都是基于该平台执行的。它提供了内存计算和外部存储系统中的参考数据集。
- Spark SQL:Spark SQL 是 Spark Core 之上的一个组件,它引入了一种名为 SchemaRDD 的新数据抽象,他提供了对结构化和半结构化数据的支持。
- Spark Streaming:Spark Streaming 利用 Spark Core 的快速调度功能来执行流式分析。它采用小批量采集数据,并对这些小批量数据执行 RDD(弹性分布式数据集)转换。
- MLlib:MLlib 是 Spark 上面的分布式机器学习框架,因为它是基于分布式内存的 Spark 体系结构。
- Graphx:Graphx 是 Spark 顶部的分布式图形处理框架。它提供了一个用于表达图形计算的 API,可以使用 Pregel 抽象 API 对用户定义的图形进行建模。它还为此抽象提供了优化的运行时。
三、鲲鹏 BoostKit 使能套件介绍
3.1、鲲鹏 BoostKit 是什么?
BoostKit 是一个应用使能套件,并不只是由一个软件包构成,而是由很多软件包组成的。
BoostKit 是部署在鲲鹏整机(服务器)环境之上,往上搭建的一个全栈优化的使能套件。具体结构如下图所示:
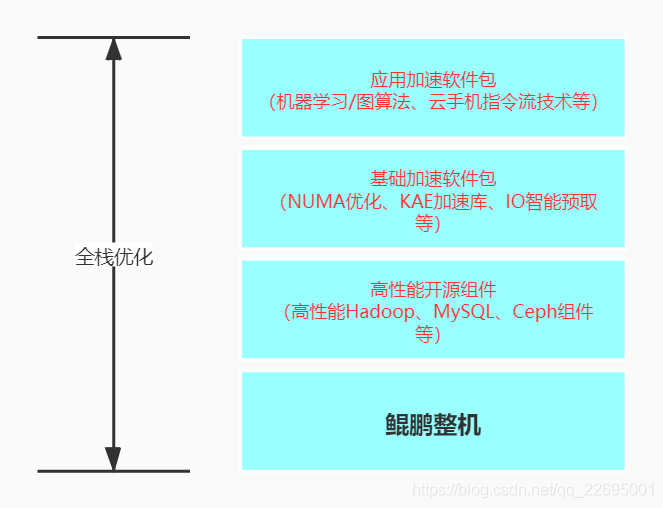
鲲鹏应用使能套件 BoostKit,释放倍级性能优势,提供八大场景化应用使能套件:大数据、分布式存储、数据库、虚拟化、ARM 原生、Web/CDN、NFV 和 HPC。在接下来的过程中,我们将其分为三个部分依次介绍。

3.2、开源使能:开源软件可用、好用

- 华为:贡献开源、主导开源,使能主流开源软件支持鲲鹏高性能。
- 伙伴:从开源社区、鲲鹏社区获取高性能开源组件,直接编译/部署。
我们以 Hadoop 为例,首先需要让 Hadoop 运行在鲲鹏服务器上,然而这远远不够,还需要根据需求开发相关特性,以促使 Hadoop 在鲲鹏之上可以运行得更加完美、便捷,同时我们将研发的产品新特性合入、贡献到开源社区。
3.3、基础加速:超越业界水平的应用性能
这一块之所以被称为基础,是因为很多应用都会使用到该加速包,比如:NUMA 优化、KAE 加速库、IO 智能预取等。

- 华为:提供基础性能优化、基础加速库和加速算法等基础加速软件包和文档,并对如何使用作出指导。
- 伙伴:从鲲鹏社区获取基础加速软件包,在鲲鹏创新中心指导下进行编译、部署和性能优化。
我们以 KAE 加速库为例,在使用过程中所使用到的如压缩、加解密等相关功能,我们会加速这个功能,如果我们的上层应用有使用到压缩、加解密等相关功能就都会有大幅的性能提升。
3.4、应用加速:极致事务倍级应用性能

- 华为:提供应用创新加速组件、算法创新组件等应用加速软件包和文档。
- 伙伴:伙伴与华为开展联合方案设计、开发和商业实践。合作方式的变化随加速功能而变。
四、BoostKit 在开源使能上的结果
BoostKit 在开源社区中做了大量的投入,主要针对如下两个方面,全面支持开源大数据组件,并实现了 ARM CI 在社区版本上的运行。
4.1、全面支持开源大数据
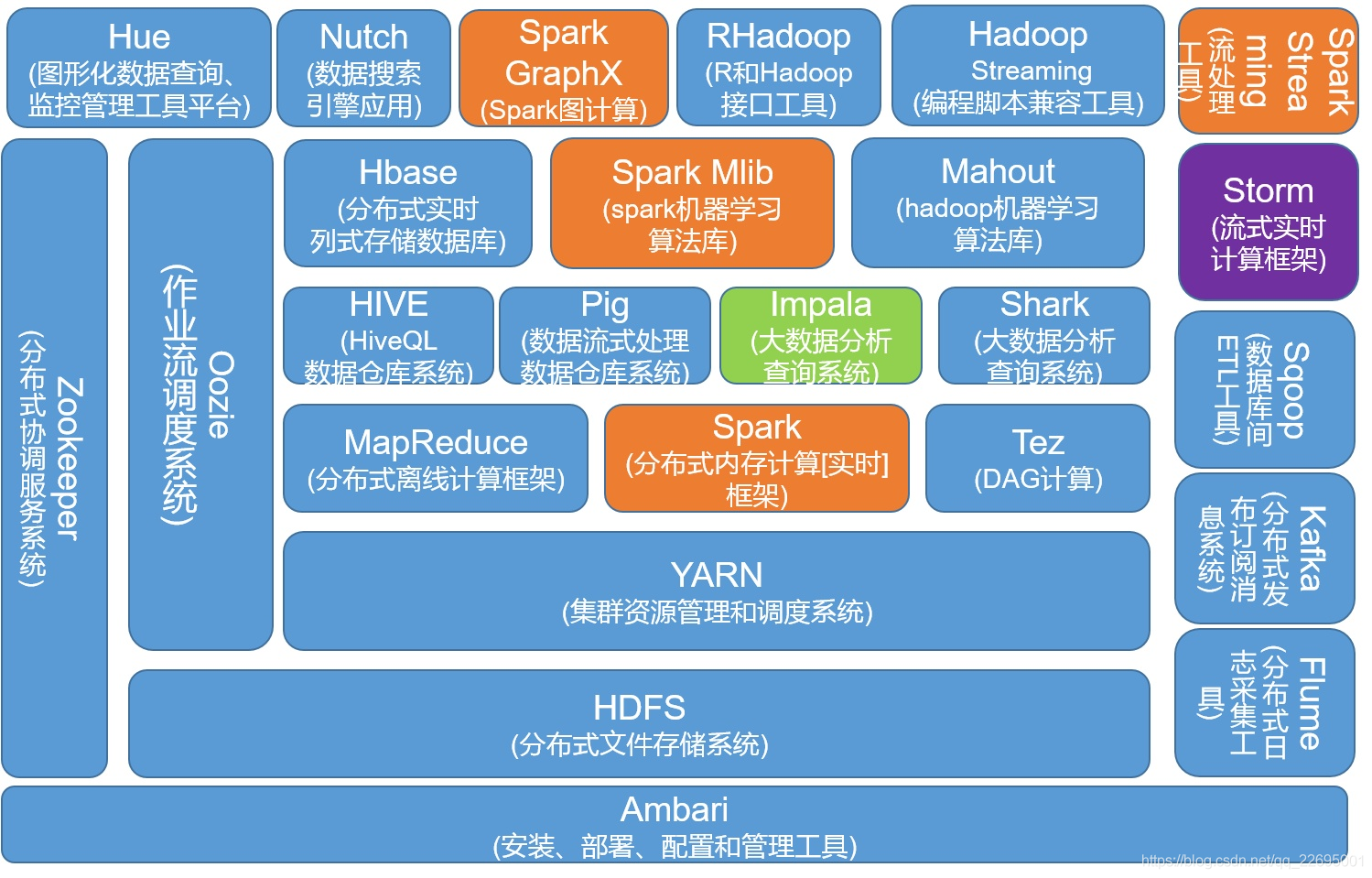
- 支持开源 Apache 大数据组件。
- 支持开源 HDP 大数据组件及管理组件 Ambari。
- 支持开源 CDH 大数据组件(注:CDH Manager 管理组件是闭源版本,当前不支持)。
4.2、开源社区接纳 ARM 生态
- Hadoop、Hive、Hbase、Spark 和 Flink、ElasticSearch、Kudu 等核心组件的开源社区支持 ARM(注:Hadoop、ElasticSearch 开源社区已经提供官方版本的 ARM 软件包)。推动了 ARM 开源软件生态的发展。
五、鲲鹏 BoostKit 如何应对大数据关键挑战?
聚焦大数据关键挑战,对于存在的痛点给出解决方案,让数据处理更快、更简单。
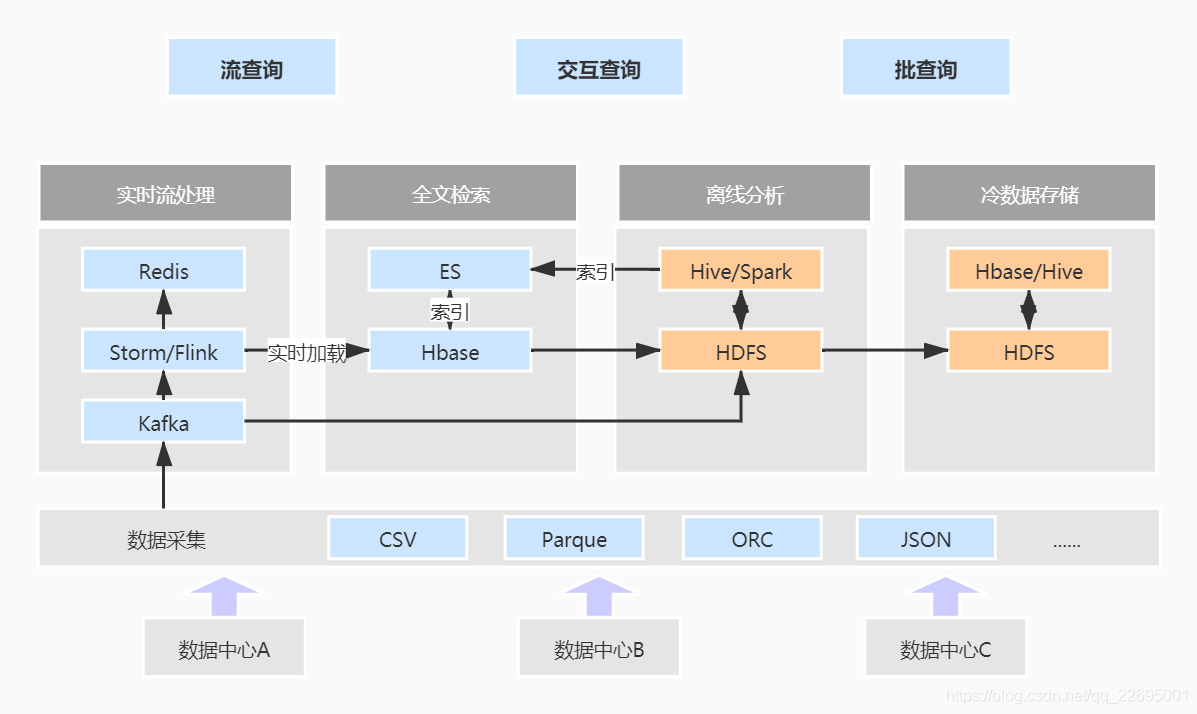
5.1、遇到的问题
- 多样化查询无法统一,效率低。Spark SQL、Hive 等查询方式的不统一,导致查询的效率降低。
- IO 密集型组件性能无法满足要求。
- 磁盘 IO 存在瓶颈,HDFS 性能提升困难。
- 在数据采集过程中,由于数据是多种多样的,多样化数据格式,导致跨数据源读取数据难。
- 数据非共享,跨数据中心取数难。在数据读取的过程中,数据多存储在不同的数据中心,无法实现共享,跨数据中心读取数据就是一个难题。
5.2、如何应对关键挑战?
- 针对问题 1、4、5。采用跨源跨域查询加速。采用 openLooKeng 虚拟化引擎统一数据入口,支持跨源、跨域分析,查询性能倍级提升。
- 针对问题 2。采用 Spark 性能加速。原生机器学习/图算法深度优化,Spark 性能倍级提升。
- 针对问题 3。采用 HDFS 性能加速。IO 智能预取,高效取数,Spark/Hbase 性能提升 20%。
六、BoostKit 机器学习/图算法的深度优化
6.1、算法深度优化实例
BoostKit 机器学习/图算法基于原生算法深度优化,促使 Spark 性能得到倍级提升,现在已经被应用到华为的伙伴业务之中,如下图所示的两个实际场景,在海量的数据集中,分别使用机器学习和图分析的算法进行建模,我们可以看到模型训练时长有大幅度的缩短,性能得到极大提升。
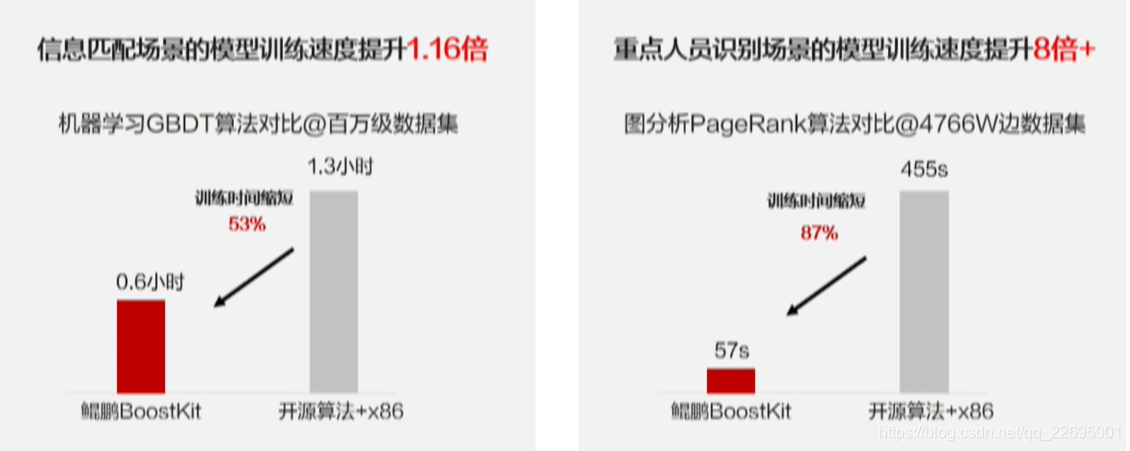
BoostKit 机器学习/图算法的优化使得在实际应用场景中,计算性能平均提升 5 倍,而上层应用无需修改!
6.2、鲲鹏算法库
- 包括上面所提到和使用的机器学习 GBDT 算法、图分析 PageRank 算法在内,鲲鹏算法库已交付 20+ 算法,涵盖常用算法类型。
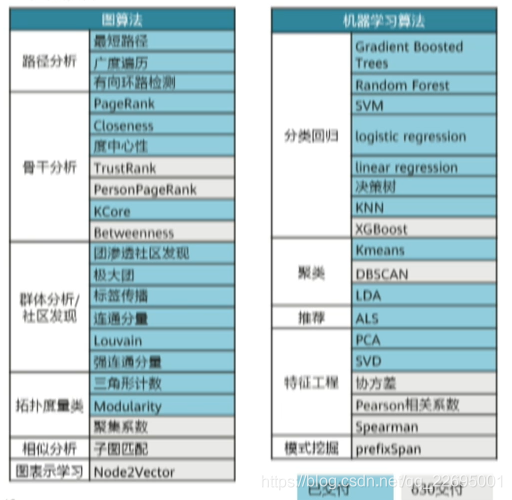
- 保持与原生 Spark 算法完全一致的类和接口定义,无需上层应用做任何修改,只需要在提交任务时加入算法包即可。
采用网络公开的多维度多规模数据集算法性能提升 50%~10 倍以上。
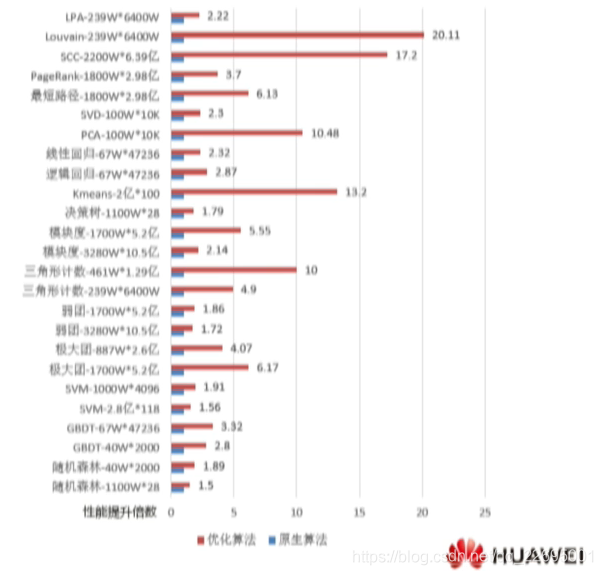
七、BoostKit 做了哪些深度优化?
7.1、鲲鹏亲和性优化效果
关键优化点:
- Communication-avoid,减少了不必要节点之间的数据通信。
- 多核并行计算。利用鲲鹏自身优势,提高了算法多核并行度,提高数据并行度与模型并行度,降低了通信 Shuffle 的瓶颈,以实现训练速度的提升。
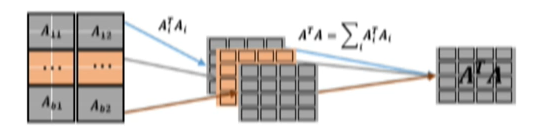
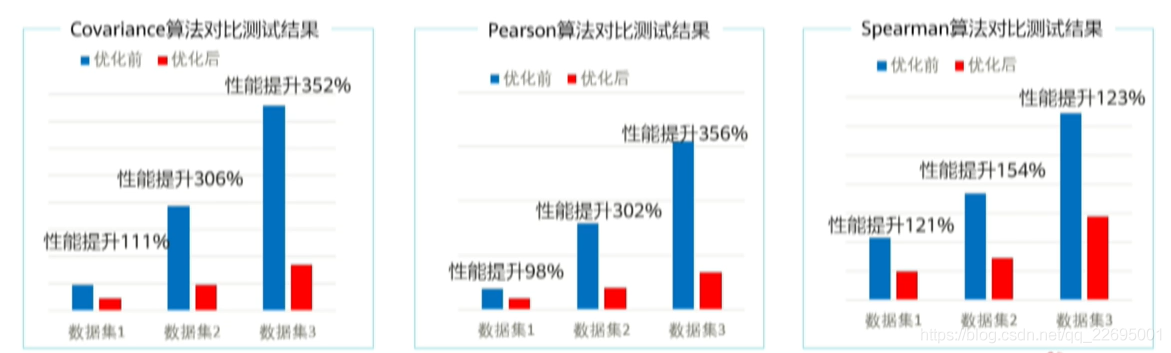
在同等计算精度,不同的数据集下,支撑机器学习算法(Covariance、Pearson、Spearman),性能提升超过 50+%,如下图所示:
7.2、机器学习算法优化方案:分布式 SVD 算法
SVD 算法即奇异值分解算法,是线性代数中常用的的矩阵分解算法。SVD 算法不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域,是很多机器学习算法的基石。
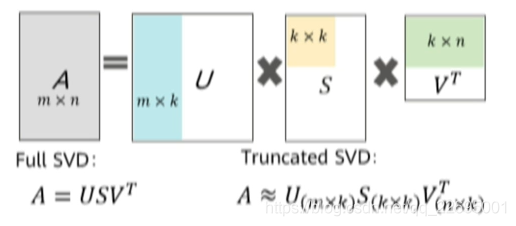
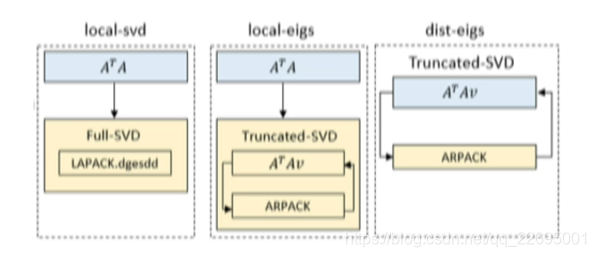
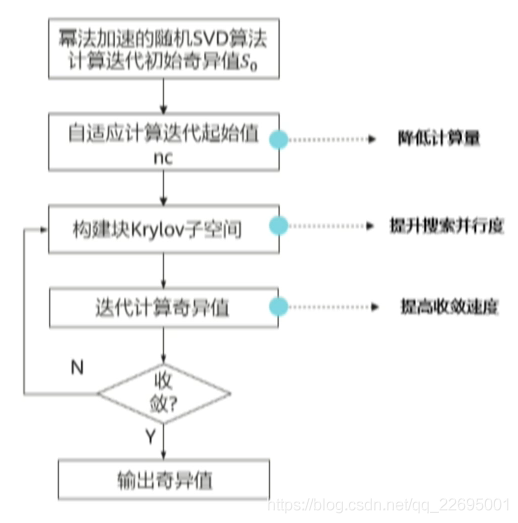
对于传统的 SVD 算法,我们也在之上进行了创新,如下图所示:
7.3、图分析算法优化方案:分布式 PageRank 算法
PageRank 算法,即网页排名算法,又称网页级别算法、Google 左侧排名算法或佩奇排名算法。该算法是对搜索引擎搜索出来的结果、网页进行排名的一种算法,本质上是一种以网页之间的超链接的个数和质量作为主要因素粗略地分析网页重要性的算法。即更重要的网页会被更多其他的网页所引用,根据引用的链接计算出每个网页的 PR 值。网页的 PR 值越高则说明该网页越重要。PageRank 是 Google 用于用来标识网页的等级/重要性的一种方法,是 Google 用来衡量一个网站的好坏的唯一标准。
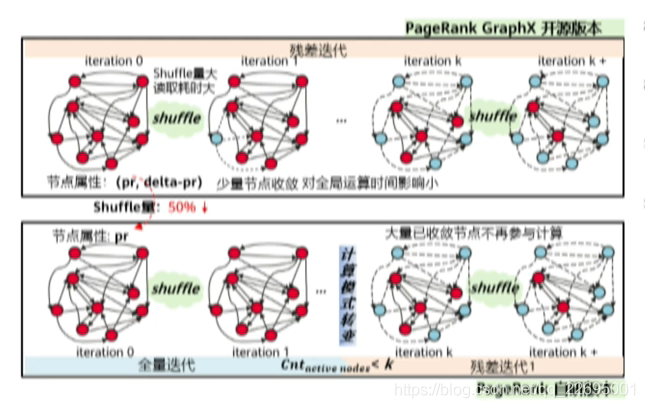
如上图所示,我们将每一个网页看做一个点,网页与网页之间的连接看成一条边,如此,便构成了图的数据结构。我们就将对这个图的数据结构进行处理。那么我们如何进行优化呢?
- 内存占用优化:基于稀疏压缩的数据表示,使得算法的内存占用下降 30%,有效解决大数据规模下的内存瓶颈问题。
- 收敛检测优化:简化收敛检测过程,使整体任务量减少 5%~10%。
- 全量迭代+残差迭代组合优化:有效降低前期数据膨胀带来的 shuffle 瓶颈,整体性能可提升 0.5X~2X。
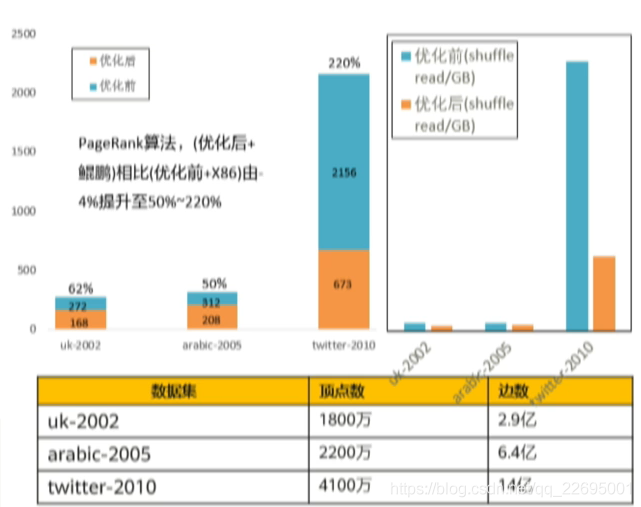
如上图所示,在优化之后,通过算法计算模式的自适应切换,整体 shuffle 量减少 50%,性能较优化前平均提升 50%+。
八、鲲鹏 BoostKit 机器学习&图算法的 Spark 性能加速实践
鲲鹏 BoostKit 机器学习&图算法的 Spark 性能加速实践可以在华为云平台上的“沙箱实验室”进行。
8.1、环境准备
在实验进行之前,首先会预制环境,如下图所示:
8.2、环境配置
由于我们的本算法是运行在 4 节点的集群上上,即运行在 4 台 ECS上,所以预制环境的过程可能较长,需要在云服务器上完成某些组件的配置,时间大概为三分钟左右。如下图所示,我们可以看到一个主节点和三个从节点。
8.3、部署 Hadoop、Spark 等组件
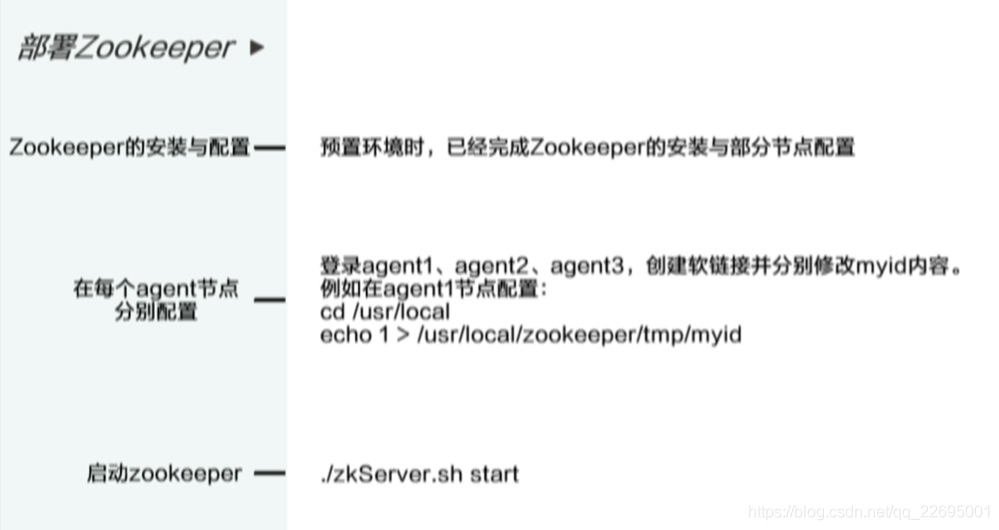
在预制环境的过程中,已经完成了部分 Zookeeper 的相关配置,我们只需要登陆每一个 agent 节点并进行少量的配置即可启动 Zookeeper,具体流程如下图所示:
对于 Hadoop 同理,预制环境时,已经完成 Hadoop 的安装与 Hadoop 在 server 节点的配置,对于 agent 节点,我们只需要在计算节点上少量配置,在 agent 端启动 JournalNode,在 server 端启动 Hadoop 其他组件即可,具体流程如下图所示:

对于 Spark,系统并没有作相关的部署,仅仅是把 Spark 下载到了集群上,之后需要我们添加 Spark 环境变量、修改 Spark 配置文件,同步到其他节点并进行任务提交,具体流程如下图所示:

8.4、算法库优化效果运行实践
8.4.1、运行 SVD 算法
调用算法库,代码如下:
sh bin/ml/svd_run.sh D10M1k不调用算法库,代码如下:
sh bin/ml/svd_run_raw.sh D10M1k8.4.2、运行 PageRank 算法
调用算法库,代码如下:
sh bin/graph/pr_run.sh cit_patents run不调用算法库,代码如下:
sh bin/graph/pr_run_raw.sh cit_patents run由于算法当前的默认参数没有完全利用 ECS 集群的资源,所以需要对 Spark 层的参数进行调优。
参数 含义 参考取值 numExectuors 用于设置该应用总共需要多少executors来执行,Driver根据此参数决定分配的Exectuors个数 9 executorMemory 设置每个executor的内存 10 executorCores 设置每个executor的cpu核数,其决定了每个executor并行执行task的能力 25G driverCores 运行sparkContext的Driver的cpu核数 3 driverMemory 运行sparkContext的Driver所在所占用的内存 10G九、相关材料获取
9.1、鲲鹏 BoostKit

9.2、机器学习算法加速库

9.3、图算法加速库

面向多样性计算时代,华为全面开放鲲鹏全栈能力,分享多样性计算工具套件:鲲鹏应用使能套件 Kunpeng BoostKit 和鲲鹏开发套件 Kunpeng DevKit,加速产业创新,使能极简开发,携手伙伴一起构建鲲鹏计算产业生态。本系列课程主要针对鲲鹏开发者及 ISV 合作伙伴,帮助您快速了解 BoostKit 鲲鹏应用使能套件支持下的 8 大场景的最佳能力和实践、鲲鹏全研发作业流程工具套件 Kunpeng DevKit 和鲲鹏基础软件开源等相关内容,与全球开发者一起共同点亮多样性计算新时代。

我是白鹿,一个不懈奋斗的程序猿。望本文能对你有所裨益,欢迎大家的一键三连!若有其他问题、建议或者补充可以留言在文章下方,感谢大家的支持!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK