

Modern garbage collection: Part 2
source link: https://blog.plan99.net/modern-garbage-collection-part-2-1c88847abcfd?source=collection_home---4------7-----------------------&gi=7f592a4f5617
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Modern garbage collection: Part 2
A look at what the newest generation of Java GCs can do
Way back in 2016 I wrote about garbage collection theory and my views on how the Go garbage collector was being marketed. In the years since there have been some good advances in the field of garbage collection, and we’re well on the way to seeing GC finally disappear as a problem.
The advance I mean is the release of two new, cutting edge open source garbage collectors for the JVM. This is a big deal because the JVM is rapidly gaining the ability to run more and more languages with very high performance, thanks to the Graal & Truffle projects. So better GC engines in the JVM doesn’t just help Java, Scala and Kotlin users. It means better GC for many other languages too. This includes languages you would not expect, like C and C++, which can be made automatically memory safe and garbage collected (i.e. leak free) using Safe Sulong.
The two new GCs are called Shenandoah and ZGC, and come from Red Hat and Oracle respectively. They have similar goals but different approaches. They are both well explained in talks on YouTube, but for people who prefer reading to watching I figured I’d explain how they work and what they can do.
In my last article on GC I presented a list of things that matter in GC design. Here they are again:
- Program throughput: how much does your algorithm slow the program down? This is sometimes expressed as a percentage of CPU time spent doing collection vs useful work.
- GC throughput: how much garbage can the collector clear given a fixed amount of CPU time?
- Heap overhead: how much additional memory over the theoretical minimum does your collector require? If your algorithm allocates temporary structures whilst collecting, does that make memory usage of your program very spiky?
- Pause times: how long does your collector stop the world for?
- Pause frequency: how often does your collector stop the world?
- Pause distribution: do you typically have very short pauses but sometimes have very long pauses? Or do you prefer pauses to be a bit longer but consistent?
- Allocation performance: is allocation of new memory fast, slow, or unpredictable?
- Compaction: does your collector ever report an out-of-memory (OOM) error even if there’s sufficient free space to satisfy a request, because that space has become scattered over the heap in small chunks? If it doesn’t you may find your program slows down and eventually dies, even if it actually had enough memory to continue.
- Concurrency: how well does your collector use multi-core machines?
- Scaling: how well does your collector work as heaps get larger?
- Tuning: how complicated is the configuration of your collector, out of the box and to obtain optimal performance?
- Warmup time: does your algorithm self-adjust based on measured behaviour and if so, how long does it take to become optimal?
- Page release: does your algorithm ever release unused memory back to the OS? If so, when?
- Portability: does your GC work on CPU architectures that provide weaker memory consistency guarantees than x86?
- Compatibility: what languages and compilers does your collector work with? Can it be run with languages that weren’t designed for GC, like C++? Does it require compiler modifications? And if so, does changing GC algorithm require recompiling all your program and dependencies?
We’ll compare Shenandoah, ZGC and other popular GCs using some of these attributes.
Pause times. The metric people tend to judge GCs by these days is pause time, sometimes exclusively so. Both the new GCs successfully deliver ultra-low latency operation regardless of heap size.By ultra-low latency, what I mean is that pause times are so low that they effectively do not matter for any kind of app, regardless of how demanding. Typical pauses for both are less than a millisecond.
This fact may not be apparent at first because GC engineers are a rather humble group and are not usually incentivised to market their work, even if they’ve spent years developing a new collector. Thus the canonical presentation on ZGC claims “no worse than 10 msec pauses”, but if we go to the SPECjbb2015 benchmarks on slide 12 we see that in fact, average pause times are around 1msec, 99th percentile pauses are still around a millisecond or two and the absolute worst pause time seen in this benchmark was 8msec.
For a video game running at 60 frames per second each frame has 16 milliseconds in which to complete, so a pause of less than a millisecond is not going to be significant relative to other overheads.
Shenandoah has equally low pause times. In a recent talk on Shenandoah we can see GC logs with pauses of around 200 to 400 microseconds (not milliseconds). And it works even on slow hardware with small heaps — on a Raspberry Pi running a web server, pause times are still only 3–8 milliseconds. That’s pretty good for an embedded device.
Remember that these pause times are obtained regardless of heap size. That is, you can get millisecond-or-less pauses on heaps terabytes in size if you need them. Being able to automatically manage enormous heaps is a fundamental capability that can change how programs are written: if your dataset fits inside such a heap, you may no longer need to write distributed software at all.
It would be interesting to compare these latencies with the latencies imposed by native manual memory management. Unfortunately it’s surprisingly hard to find information on malloc latency distributions. This blog post describes a Redis load test in which glibc malloc latency has a worst case of around 10 milliseconds. That sounds very worst case, but unfortunately most benchmarks of mallocs use very unrealistic test scenarios like allocating and immediately freeing that allocation, so it’s hard to get real figures. JVM GCs are tested using SPECjbb, which is a benchmark implementing a supermarket logistics app.
Program throughput. ZGC aims for overhead no worse than 15% (vs no collector at all). This is comparable to the worst case overheads reported for mallocs. It’s difficult to compare throughput with the Go collector, because the performance impact of the Go collector depends on how much memory overhead you choose to have. But the throughput impact of Go’s approach can be pretty severe (useful spreadsheet here). Shenandoah’s throughput overhead is similar to ZGC as the barriers do roughly the same amount of work: between 0% and 15%.
Compaction. BothShenandoah and ZGC collectors actually move things around in memory whilst the program is running, without pausing it. This trick may initially appear impossible, but it’s actually the key idea behind all modern collectors (except in Go). Compaction is useful for three reasons:
- It eliminates heap fragmentation. Anti-fragmenting allocators are often found in manually managed apps, but they reduce fragmentation at the cost of increased overhead and can never eliminate the problem entirely.
- It can make programs faster by reorganising data in memory in ways that exploit caches better.
- It enables really huge amounts of garbage to be cleared at high speeds, which is useful for programs that are generational in nature (and almost all are, with big LRU caches being the primary case where program behaviour is not generational).
I’ll describe how these GCs are able to move data around in memory whilst the program is reading and writing to it below.
Allocation performance. One big reason to use compaction is that it clears out large contiguous regions of memory. That in turn means that allocation can be done incredible fast — once a thread has grabbed a chunk of a cleared heap region, it can allocate memory by simply increasing a single pointer and doing a comparison i.e. in just two or three instructions, inlined into the allocation site. Going back to claim another chunk is only slightly slower. In a fragmented heap allocation can involve searching for an empty chunk of the right size, so every allocation requires a call into the memory manager and this can cause slowdowns.
Page release. One of the reasons Java got a bad reputation for memory usage is that most of its garbage collectors don’t release memory back to the OS very often. On servers where one program may ‘own’ the machine, this is a win. But on desktops and especially developer desktops where many programs are competing for RAM, this sort of behaviour is anti-social. Shenandoah has a nice feature — it will proactively garbage collect even if the app is idle, and steadily release memory back to the OS. This makes it a potentially good choice for use with desktop apps like IDEs. The default G1 collector used by the JVM also learned how to do this in Java 12.
Update: ZGC has also gained this feature in recent Java releases.
Compatibility. The JVM runs many languages, perhaps more languages than any other runtime. The new GCs can benefit not just Java, but also JavaScript, Python, Ruby, Haskell (via Eta), Clojure, Scala, Kotlin, R, COBOL and — as mentioned — via the (unfortunately not open source) Safe Sulong project also C programs. In that mode malloc is converted to a garbage collected allocation and free is ignored.
How does it work?
For a GC to be able to move objects without pausing the app requires some sort of clever trick.
For Shenandoah that trick is called a Brooks forwarding pointer. Every object has a pointer in its header. It normally points to the object itself, but if the object is being moved, it’s updated to point to the new location. The compiler cooperates with the GC by emitting read and write ‘barriers’ — small bits of assembly that run as part of loading and storing pointers to the heap. The overhead of the pointer is not always as straightforward as it seems, because due to CPU data alignment requirements the heap sometimes has gaps in it anyway which can be used for the forwarding pointer. So it’s not as bad as adding 64 bits to every object, but it does add some overhead: about 10–15% for Shenandoah in the average case, and up to 50% in the worst case.
(edit: Shenandoah 2.0 doesn’t use a forwarding pointer anymore.)
ZGC uses a different approach that doesn’t require forwarding pointers. ZGC’s trick is called coloured pointers. A coloured pointer is one that stores some metadata bits in the value of the pointer itself. Thus each pointer in memory not only contains an address, but also some information about what it points to. This is possible because 64 bit pointers have far more space in them than is actually needed. If a way to use some of those bits can be found, they can be deployed effectively for GC purposes: ZGC uses four of them. Some architectures like ARM and SPARC allow programs to configure pointer masks that cause the CPU to ignore some bits during a load operation, but unfortunately x86–64 does not. So on these chips ZGC uses another clever trick — the metadata bits are put in the middle of the pointer, just above the bits that point into the heap itself. Then the heap is mapped into the address space multiple times, once for each combination of the metadata bits. In this way the pointer is always usable.
ZGC’s metadata is used to trigger work during a load barrier. Whenever the program reads a pointer from the heap, the metadata bits are examined to see if the pointer is “good” or “bad”. In practice pointers are almost always good. If bad, the thread will need to do some GC work before it can proceed and set the pointer to be good again: typically moving the object, but it may also involve flipping mark bits. To keep track of where an object has been moved to off-heap tables are used, this ensures that the evacuated region of the heap can immediately start being used again. The GC runs around repairing pointers (making them good again) concurrently with the app, so eventually all the pointers have been patched to refer to the new location of a moved object and these side tables can be deallocated.
How to get them?
Shenandoah has been integrated with OpenJDK as of Java 12, but the Oracle builds don’t include it, so you’ll have to use other builds for now. Of course if you use Red Hat Linux then you get this out of the box. Usefully, Red Hat also provide backports for Java 8 and 11.
ZGC comes with the default OpenJDK and Oracle builds. In Java 12 it’s pretty complete, but supports “only” a maximum heap size of 4 terabytes. In Java 13 they plan to increase the max heap size to a whopping 16 terabytes — as well as adding the increasingly vital ability to shrink the heap and release memory back to the OS.
Edit: Java 13 is out now and adds these features.
However, obtaining a JVM with the GC you want built in isn’t enough. You also have to enable it. Because these GCs are tuned for huge heaps at a cost of runtime throughput, and because they are new, you are expected to opt-in for now. Perhaps in future the JVM will automatically use these new GCs when the configured maximum heap size is big enough.
Comparisons
So how do these new GCs compare to other initiatives outside the Java world? That’s very hard to say because you can’t normally hold all other variables constant: other languages may put different amounts of pressure on the heap or GC algorithm. But I’d say they compare extremely well indeed.
In my previous article in 2016 about garbage collection, I observed that Go was advertising itself as somehow having a one-size-fits-all collector that was both better than ‘enterprise’ alternatives and sufficient to do everything into the foreseeable future. But this wasn’t true so I criticised their marketing approach. A couple of years later the Go team published this excellent talk called “Getting to Go” that I’d describe as almost the exact opposite — it’s remarkably honest.
It tells us that the Go GC was designed in the unusual way it was, largely due to previously unmentioned internal engineering constraints at Google, and in particular due to a surprising need for short term success.
The original plan was to do a read barrier free concurrent copying GC. That was the long term plan. There was a lot of uncertainty about the overhead of read barriers so Go wanted to avoid them.
But short term 2014 we had to get our act together … We also needed something quickly and focused on latency but the performance hit had to be less than the speedups provided by the compiler. So we were limited.
We were also concerned about compiler speed, that is the code the compiler generated … Go also desperately needed short term success in 2015.
There’s nothing wrong with designing to meet your time constraints. Some lucky projects are funded for as long as they need to be in order to achieve their goals (for instance it took the Kotlin team about 6 years to reach version 1.0). Some other projects need to obtain market success quicker. Go seems to have been in the latter category, although I have no idea why. Creating new languages is always a very long term endeavour — perhaps Google’s senior management were demanding to see adoption or else the project would be cancelled.
So it’s 2014 and Jeff Dean had just come out with his paper called ‘The Tail at Scale’ which this digs into this further. It was being widely read around Google since it had serious ramifications for Google going forward and trying to scale at Google scale.
And Go’s GC was designed with another constraint — in an environment in which their colleagues had become obsessed with the long tail of pause latencies. The Go team couldn’t ignore an important position paper by Jeff Dean.
Regardless of the causes, Go’s unusual design choices were clearly due to a combination of unusual constraints: they were in a company going through an obsession with tail latencies, they had limited programming time because they were simultaneously rewriting the standard library in Go, and most of all they needed to drive pause latency down very fast to obtain “short term success”.
Good for them — I’d say they achieved their goals splendidly. Go did drive down pause latencies albeit at huge cost in other areas, they did it very quickly with limited engineering budget, and they obtained the short term success they needed. It’s unfortunate that they claimed their quickly thrown together GC was “a future where applications scale effortlessly” and “good for the next decade and beyond” whilst immediately starting to experiment with other GC algorithms, but let’s let bygones be bygones.
Unfortunately, along the way they adopted some strange requirements, like the desire to not expose tuning knobs to users. And this led to them being pinned down badly by the wildly varying needs of different programs.
The Go compiler is a classic batch job. Pause times don’t matter at all for a compiler, only the total runtime does. But techniques to reduce pause times all increase total runtime, so that’s a problem. A good GC algorithm to use for a batch job is something like the JVM’s Parallel GC. Go doesn’t have any equivalent of that.
They experimented with a “request oriented collector” which scaled better for some kinds of important apps:
As you can see if you have ROC on and not a lot of sharing, things actually scale quite nicely. If you don’t have ROC on it wasn’t nearly as good.
But … it slowed down their compiler:
At that point there was a lot of concern about our compiler and we could not slow down our compilers. Unfortunately the compilers were exactly the programs that ROC did not do well at. We were seeing 30, 40, 50% and more slowdowns and that was unacceptable. Go is proud of how fast its compiler is.
Darn, GC design is hard! The Go guys could have gone the JVM route and just let the user pick the GC algorithm depending on whether they care about latency or throughput, but, that would have violated the “two knobs is perfect” policy they had:
We also do not intend to increase the GC API surface. We’ve had almost a decade now and we have two knobs and that feels about right. There is not an application that is important enough for us to add a new flag.
Why two knobs? Why not three? Everyone can agree fewer is better, but drawing the line at two feels totally arbitrary.
So they gave up and tried a new approach — a regular generational garbage collector (like their “enterprise” competitors). But they made this in a strange way too, because they insisted it not move things around in memory. That third try also failed:
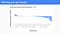
This is typical in performance tuning — you try something and it makes some programs faster, but others slower. This is the root of the tuning knobs problem.
Their position as of 2018 is therefore that they’re going to just wait for memory prices to drop and ask Go users to give Go apps huge heaps, to reduce the amount of GC work that needs to be done with the current algorithm (see the last slides).
If we compare this story to the equivalent in the JVM world, we can see things played out differently. In the SPECjbb 2015 benchmark (which simulates a warehouse management database app), ZGC imposes doesn’t really slow down the app but does significantly improve latency:
Pause times are almost always a millisecond or less, yet throughput isn’t significantly harmed. They aim for a max throughput impact of 15% but it appears they manage significantly better than their own goals in reality (ZGC is new so it’s hard to say exactly on what workloads this is true). Meanwhile, there are only three standard tuning flags — one to select ZGC instead of another algorithm, one to set the max heap size, and one you can normally leave alone as it’s automatically adjusted but which sets how much CPU time the collector gets. A few more obscure ones can be used to increase performance further by utilising the Linux kernel’s hugepages feature. This seems pretty good. In the case that the new algorithm does harm a specific program or benchmark, it is easy to go back to the old ones.
Overall, it looks to me like the Java guys are winning the low latency game.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK