

西瓜视频稳定性治理体系建设三:Sliver 原理及实践
source link: https://blog.csdn.net/ByteDanceTech/article/details/119621240
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
西瓜视频稳定性治理体系系列文章
卡顿和 ANR 问题一直是 Android 性能优化的重点问题,直接关系到用户体验。当主线程的消息执行耗时过长时,轻则出现不流畅,不跟手,重则有肉眼可见的卡顿感,最严重则是发生 ANR,系统会弹出弹窗提示用户等待或关掉程序,严重影响用户体验。
对于卡顿的监控,现有的方案大多是在消息执行前埋点,当消息耗时过长时进行抓栈操作,ANR 的监控则是通过监听 SIGQUIT 信号并判断进程状态,在 ANR 时拿到各线程堆栈及各类辅助信息来定位问题。这种抓堆栈的方案对于单点长耗时是有效果的,比如锁等待和死锁,但是对于由多个消息和函数耗时累积造成的 ANR,一次堆栈是无法定位问题的,所以经常会出现 ANR 堆栈不准的情况。

西瓜视频的 Android TOP 1 ANR 就是聚类到了 nativePollOnce,根据 ANR 前的消息调度耗时可以看到存在许多长耗时消息,这些长消息是造成 ANR 的根本原因,而不是真的阻塞在了 nativePollOnce。分析发现其实这部分问题都是由于抓栈时机滞后导致的,从感知到 ANR 到完成抓栈存在一定的时间间隔,很容易错过现场,而 nativePollOnce 是主线程中执行频率最高的函数,抓栈很容易落到这里,所以导致很多 ANR 都是 nativePollOnce 的堆栈。另外传统的监控方案对于多个耗时消息累积导致的 ANR 也很难做到有效监控,单次抓栈大概率无法明确问题。所以如果能拿到 ANR 前的一段时间的 Method Trace,那么就能看到主线程到底在做什么,进而准确定位问题。
Android 可用的 trace 工具有很多,如 Android Studio 的 Profiler(与代码内的 Debug.startMethodTracing 效果类似),Uber 开源的 Nanoscope,Facebook 开源的 Profilo,Systrace 也可以统计一些关键节点的耗时。按照各个工具抓取函数耗时的实现原理,可以分为两类:埋点型和采样型。
Systrace、Debug.startMethodTracing 和 Nanoscope 都属于埋点型,埋点型就是在函数执行的出入口记录时间和方法名,这样就能获取到程序运行时都执行了哪些方法和对应的耗时。
Systrace 是分析系统性能的工具,包含了 CPU、IO、内核运行信息等。Systrace 通过一些关键路径上的埋点,抓取的时候拿到这些关键路径的耗时,将数据结合起来对性能做综合分析。Systrace 抓取 App 函数耗时需要额外进行埋点适配(Trace.traceBegin 与 Trace.traceEnd),且 Framework 的绝大部分函数无法抓取。
Debug.startMethodTracing 是在 ArtMethod 的解释器出入口做了埋点,在虚拟机内设置了一个 instrumentation 监听函数的进入与退出,当函数是解释执行时,就可以获取到函数执行耗时。但此方案仅限于解释执行,所以为了抓取到完整的 trace,开启该功能时,虚拟机会将目标应用设置成仅解释执行,禁用掉机器码执行和 JIT,这样会严重影响运行性能,得到的数据也会失真。
Nanoscope 不同于其他两类方案,它不仅在解释器中埋点,还对编译器做了修改,当函数被编译成机器码时,会在方法的出入口增加机器码逻辑,用来记录编译后的方法的执行。这样做的好处就是,无需限制程序为解释执行,性能得到了保障,但由于修改了编译器代码,所以需要刷定制后的 ROM 才能使用 Nanoscope,失去了通用性。
除了这三种方案外,直接通过字节码插桩对应用内方法加埋点也可以达到目的,但是插桩会导致性能损耗、占用内存以及包大小增加的问题,且无法支持 Framework 堆栈,这里不再详细讨论。
Debug.startMethodTracingSampling 和 Profilo 属于采样型,其原理是每隔一定的时间,抓取一次线程的堆栈,通过在程序运行时不断的抓取,最终组合形成 trace 数据。
Debug.startMethodTracingSampling 是通过创建一个独立线程,在循环内对所有线程进行抓栈并记录数据。该方案每次抓栈前都会 SuspendAll,等待所有线程抓栈完毕再 ResumeAll,并且在线程挂起时间内,还要进行堆栈的处理,以及文件的写入,导致每次采样所有线程都需要等待很长时间,性能损耗较大。
Profilo 的方案较为新颖,创建定时器不断的向目标线程发送 SIGPROF 信号,在注册的信号回调内执行抓栈操作。这样做的好处是性能损耗较低,可以直接在当前线程抓栈,损耗近似为抓栈耗时,缺点是方案复杂适配成本高,Profilo 的抓栈方案使用了大量的固定偏移,兼容性稳定性以及后续扩展性较差。
采样抓栈的限制也比较明显,采样间隔过大,trace 的精度会变低,而采样间隔过小,性能损耗就会增大。优点是可控性强,大部分情况下短耗时函数我们并不关心,而合适的采样间隔可以保证只监控长耗时函数。
我们的预期是通过 Method Trace 工具,达到解决线上性能问题的目的。通过对现场 trace 文件的解析来解决 ANR 和卡顿堆栈聚合及归因不准确的问题,进而提升此类问题发现和解决的效率。通过前面的分析,可以看到现有的工具或多或少都存在一些问题,而且大部分工具的设计就是面向线下的,存在不同程度的性能损耗与稳定性问题,无法上线使用。线上用户的设备环境复杂,遇到的很多性能问题是无法在本地模拟复现的,所以理想的 trace 工具需要能够在线上使用。
满足上线标准的 trace 工具需要达到:高性能、高稳定、低侵入、兼容性强等要求,所以需要针对现有问题设计一套方案,解决掉现有方案的问题。
埋点型方案如果想监控到 Framework 方法,就需要深入到 art 虚拟机,通过一些 hook 手段去修改运行时逻辑,而且还要兼顾到机器码执行等等,难度与风险都是巨大的,以现有的手段来看,埋点型基本无法实现。而采样型方案主要存在的问题就是采样精度与性能损耗之间的矛盾,ANR 和卡顿监控主要是监控长耗时函数,采样精度可以放低,所以我们只要保证单次抓栈时间最短,就可以对性能影响最小,同时保证稳定性兼容性,即可达到目标。
ART 抓栈原理
采样型 trace 方案的核心就是抓栈,大家最熟知的抓栈方法,应该是 Java Thread 类的 getStackTrace 方法,下面根据这个函数分析下抓栈原理。

getStackTrace 内调用了 VMStack.getThreadStackTrace,传入抓栈的目标线程。
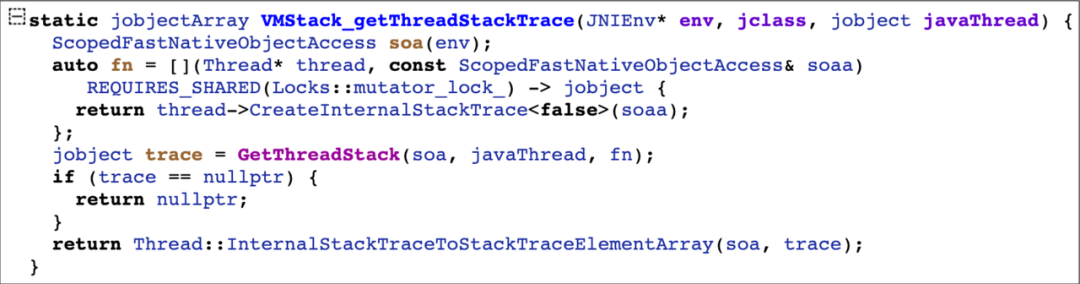
该函数是一个 native 函数,里面的工作分为三步:一是创建回调,内部会调用 native 层的 Thread::CreateInternalStackTrace 函数;二是调用 GetThreadStack 函数,传入 env,Java Thread 以及回调函数指针;三是将 GetThreadStack 的返回结果通过 Thread::InternalStackTraceToStackTraceElementArray 处理,得到 Java 层最终的返回值 StackTraceElement[]。
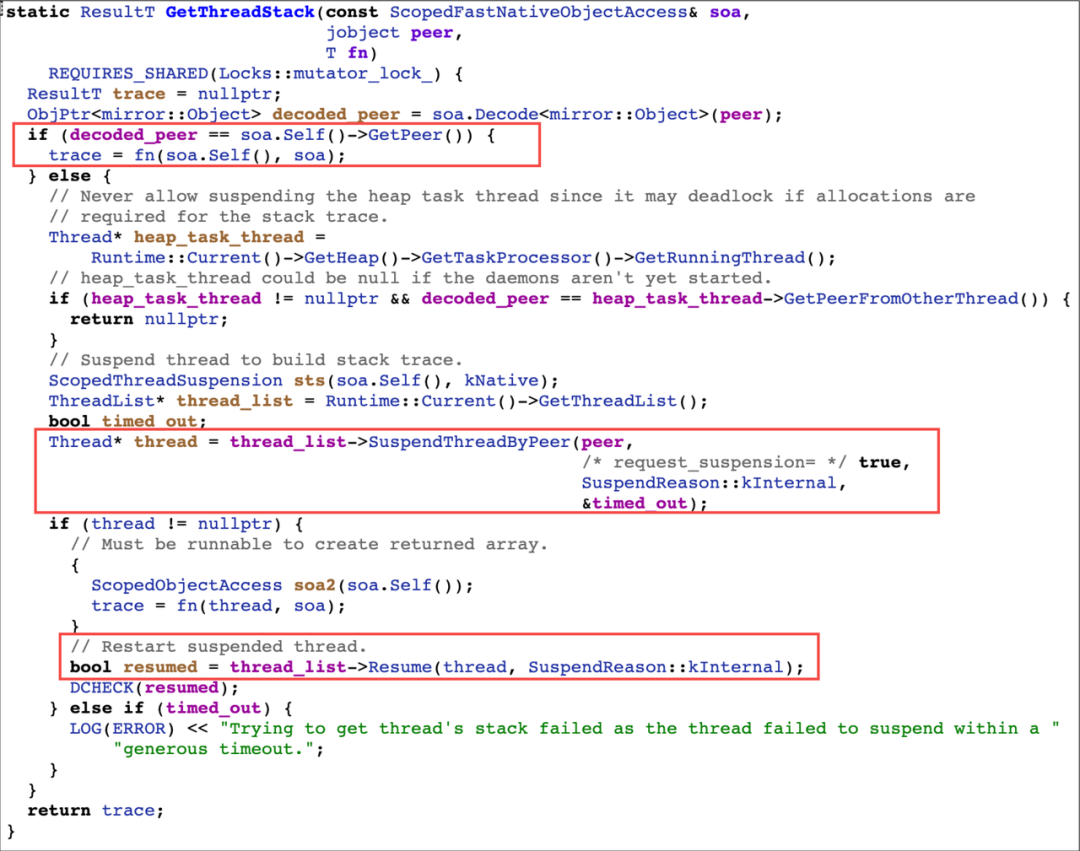
GetThreadStack 函数内,会先判断抓栈的目标线程和执行抓栈的当前线程是否是同一个线程,如果是的话,则可以直接运行传入的回调 fn;而如果要抓其他的函数栈,则要先将目标线程 Suspend,再执行 fn,抓栈完成后再将目标线程 Resume。因为按照虚拟机的 Java 函数栈的实现,抓栈是非线程安全的,在跨线程抓栈时,目标线程的函数栈发生变动,就会出现问题,所以跨线程抓栈时需要将目标线程挂起,保证安全。
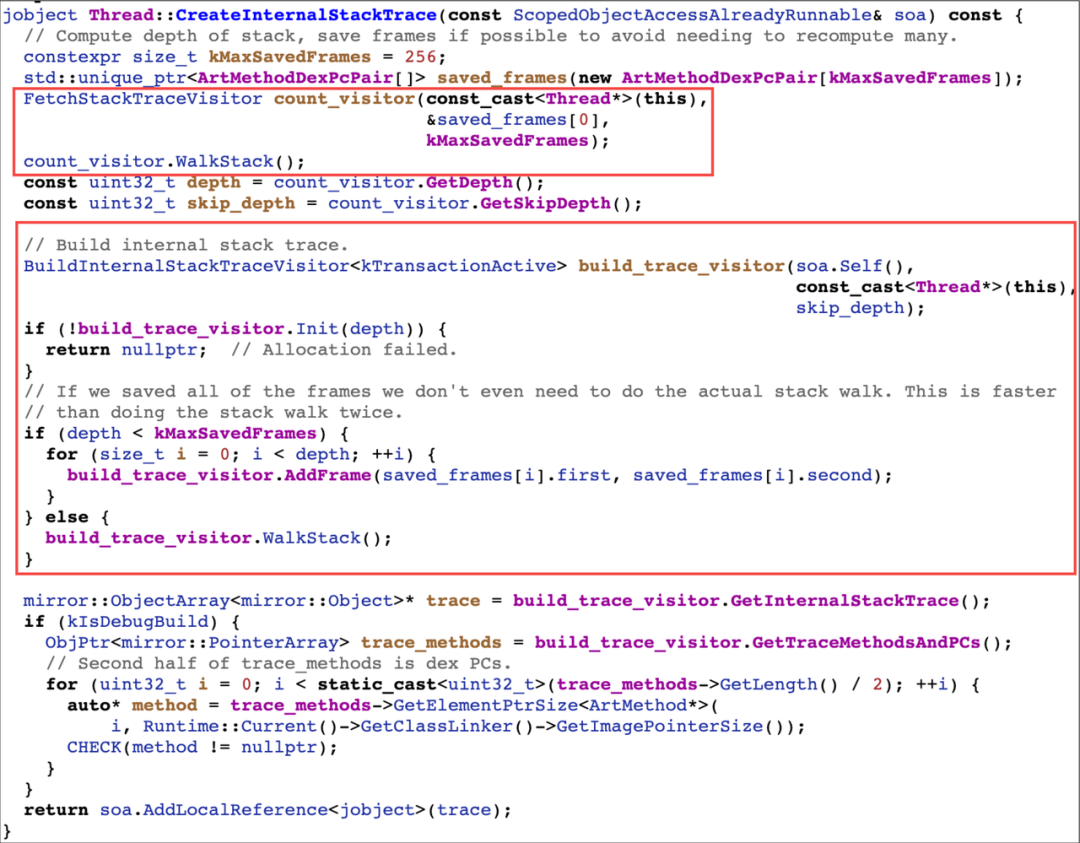
fn 回调内执行了 Thread::CreateInternalStackTrace 函数,该函数创建了两个 StackVisitor:FetchStackTraceVisitor 和 BuildInternalStackTraceVisitor。StackVisitor 就是栈回溯器,方法内先通过 FetchStackTraceVisitor 回溯,最大深度为 256,因为正常程序运行栈深度超过 256 的情况很少,这样做能够节省创建数组的开销。通过 WalkStack 回溯获取结果后,如果栈的深度小于 256,则添加到 BuildInternalStackTraceVisitor 中,否则再通过 BuildInternalStackTraceVisitor 回溯一次。最终将记录的方法数组返回,完成回溯。

StackVisitor 的核心函数是 WalkStack,其内部主要是一个遍历函数栈的操作。每个线程都管理着各自的 ManagedStack,是一个链表结构,每一个 ManagedStack 节点又管理着 cur_shadow_frame_ 和 cur_quick_frame_,分别表示解释执行帧与机器码执行帧。
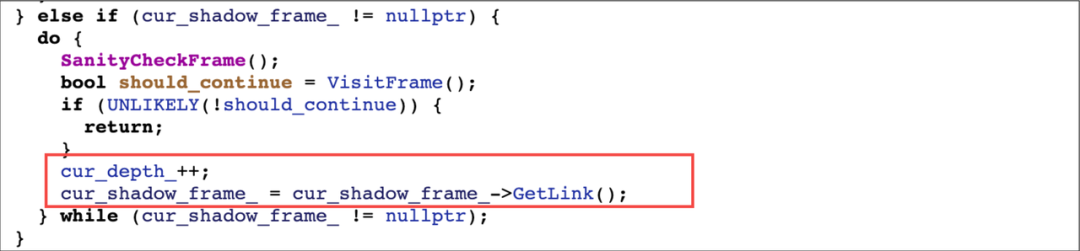

curshadow_frame 也是链表式结构,每个 ShadowFrame 节点对应一个 ArtMethod,通过遍历即可获取到对应的函数栈。
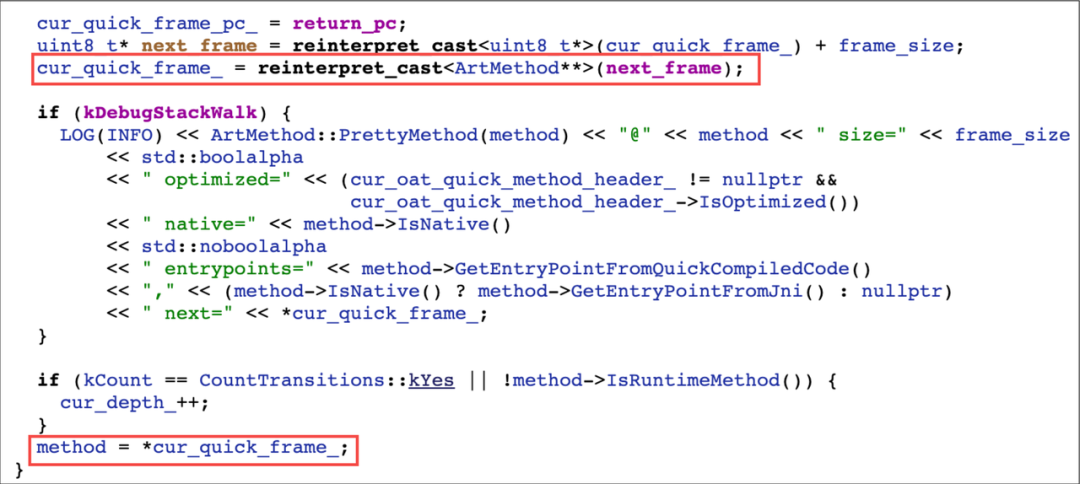
curquick_frame 则是 ArtMethod 指针数组,即 ArtMethod**,通过遍历计算偏移量 frame_size 来不断的得到对应的函数。

WalkStack 函数遍历 ManagedStack,每个 ManagedStack 节点只能存在一种 frame 类型,然后在循环里不断遍历 curshadow_frame 或 curquick_frame,每次得到一层函数栈,然后通过 StackVisitor 的虚函数 VisitFrame 来判断是否需要继续回溯。

art 里有许多 StackVisitor 的实现,在实现的 VisitFrame 内获取函数栈然后进行各种操作。比如上面提到的 FetchStackTraceVisitor 就在实现的 VisitFrame 内进行 ArtMethod 的筛选和记录等操作。
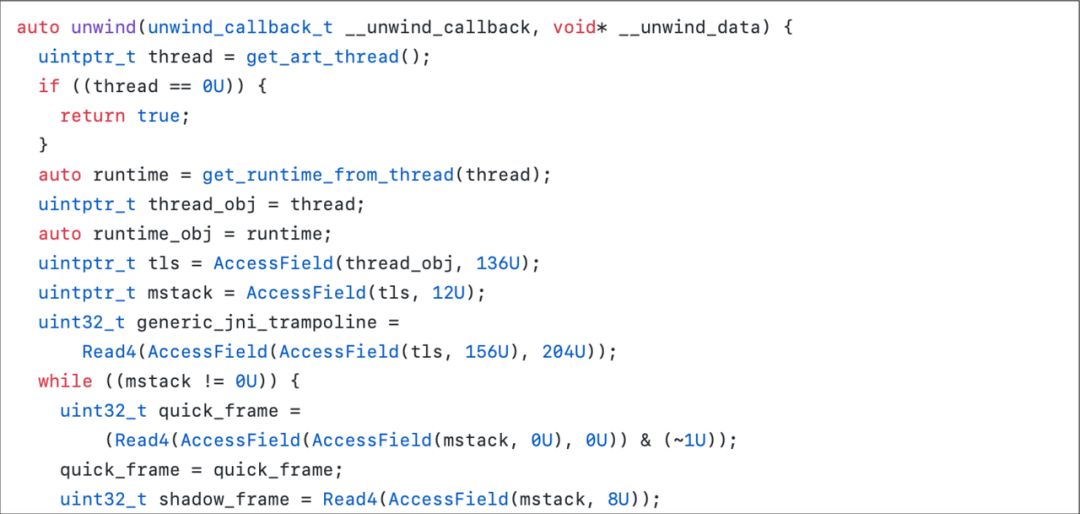
综上分析,抓取 Java 函数栈的核心函数就是 StackVisitor::WalkStack,art 内抓取函数栈的最终实现都是该函数。其实通过阅读 Profilo 的源码也可以发现,其抓栈的核心函数就是通过指针+偏移量的方案实现了 WalkStack,写死了大量偏移,并做了很多适配工作。这样做虽然可以实现功能,但稳定性就会变差,维护成本也会增高。Profilo 的开源版本截至目前仅适配到了 Android 9,适配 Android 10、11 和 12 的 32&64 位架构又是极大的工作量,而且厂商定制 ROM 若更改了任何一处源码,导致偏移量发生变化,那么轻则功能不可用,重则发生 Crash。
既然自己实现栈回溯十分复杂且风险较大,那就直接用系统的函数,通过 xDL 查找符号表拿到 WalkStack 的函数指针直接调用。

该函数只有一个 bool 型入参,但该函数是成员函数,编译后会增加一个入参即 this 指针,而且 StackVisitor 还包含虚函数 VisitFrame,所以需要构造出一个实现 VisitFrame 的 StackVisitor。最简单的方案就是利用内存布局的特性,直接复制 StackVisitor 的代码到工程内,使用时直接 new 即可。
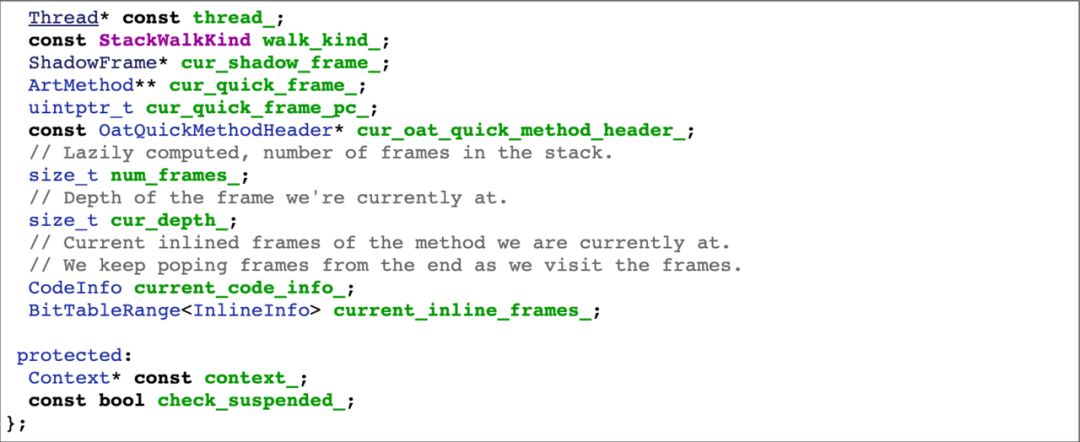
通过阅读源码发现,StackVisitor 的结构包含了如图中“CodeInfo”和“BitTableRange”这类变量,若直接采用复制的方案,一是复杂,二是厂商修改可能性大。通过上面对 WalkStack 的原理分析,回溯中的核心变量是 curshadow_frame 与 curquick_frame,至于行号在 trace 中是非必须的,解析行号只会徒增成本,所以作为调用方其实只关心前四个变量,后面的变量我们并不关心其值,只要保证运行时有足够的内存 get/set 即可。
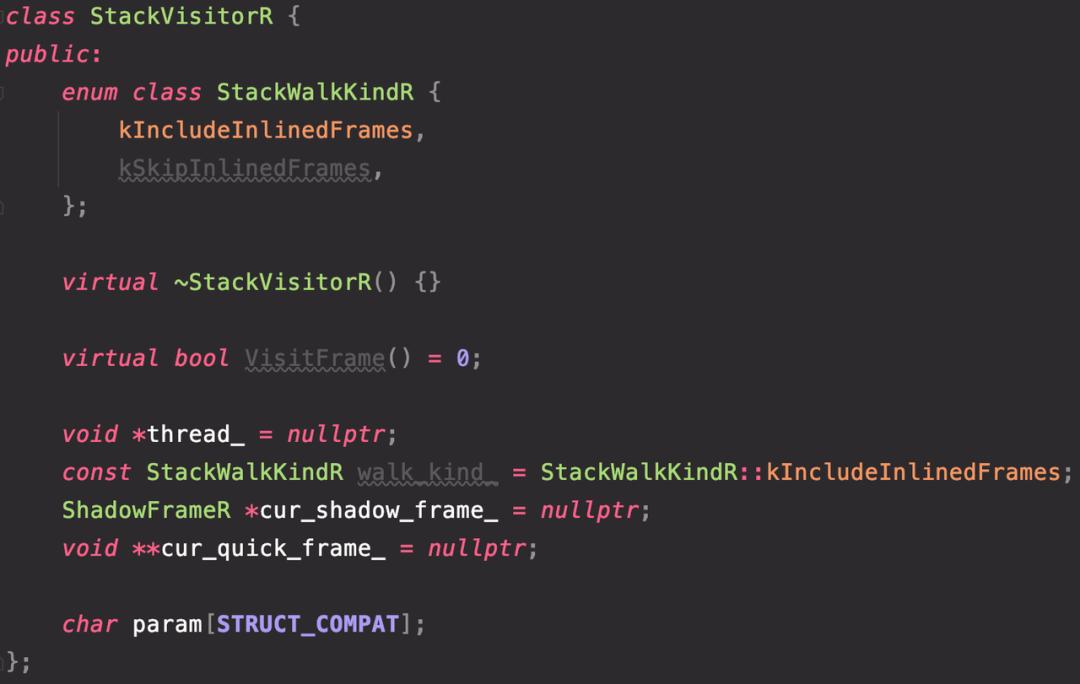
这里采用一种取巧的方案,自己构造的 StackVisitor 中,只写出虚函数和前四个核心变量,而后面的内容,使用长度足够的 char 数组占位,这样在运行时就有了足够的内存读写其他的变量,而且只使用前四个变量可以降低厂商定制带来问题的概率。

然后再实现一个继承自 StackVisitor 并实现了 VisitFrame 的函数,在其内部通过 curshadow_frame 与 curquick_frame 获取到每一帧对应的 ArtMethod,这样即可完成 StackVisitor 的构造。

通过函数指针调用 WalkStack,即可完成一次栈回溯的操作。

在 Callback 内将每一层的 ArtMethod* 保存到数组中,完成堆栈的记录。
实现了抓栈能力后,还需要选择暂停目标线程的方式,有两种方案,一是通过发送信号来实现中断,二是通过虚拟机的 Suspend 函数来实现挂起。
信号机制无论是实现还是性能都是要略优于挂起机制的,但在实际开发过程中,发现如果在信号回调中调用系统的 WalkStack,运行一段时间后会出现各类 Crash。
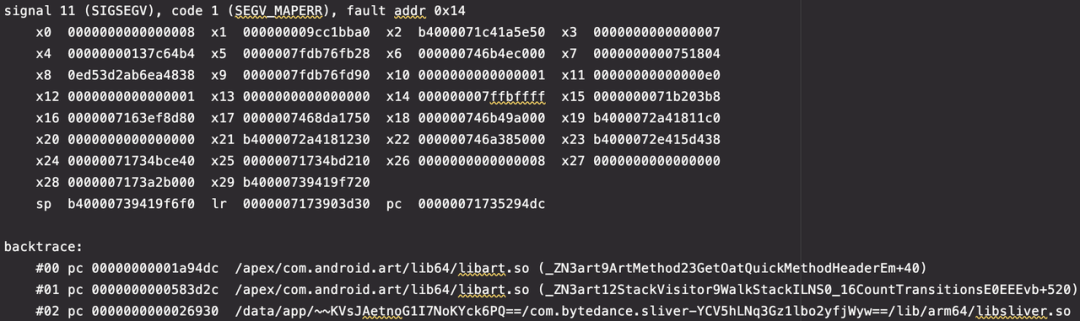
比如这一类在 WalkStack 内部调用 GetOatQuickMethodHeader 时的崩溃,x0 寄存器即该函数的 this 指针,ArtMethod 的值为 0x8 导致的非法指针问题。

还有 Didn't find oat method index for virtual method 的 abort 异常,以及各种各样的其他崩溃,堆栈不固定,但基本都是在解析机器码函数栈时发生了异常。
通过分析发现,这些崩溃在正常情况下是不应该出现的,经过测试,在非信号回调中频繁调用 WalkStack 确实没有发现任何异常。经过深入分析与阅读源码,推测是发生了重入问题。由于信号的机制,信号回调会在中断后调用,而目标线程被中断时,无法保证指令的位置,所以如果是中断在机器码函数栈记录过程中,而我们又在回调中执行 WalkStack,就会发生不可预期的崩溃。而机器码函数相关的代码十分复杂,暂未找到该问题的有效解决方案。既然信号机制的问题暂时无法规避,所以选择尝试线程挂起方案。

ThreadList 的 SuspendThreadByPeer 函数,可以通过传入目标线程的 Java Thread 对象的 jobject 完成对目标线程的挂起,刚好可以满足需求。但是该函数是成员函数,调用还需要拿到 ThreadList 指针,ThreadList 是全局唯一的,定义在 Runtime 中,翻遍源码也未找到安全可靠的获取方式,最终只能通过写死偏移的方式获取。

ThreadList 在 Runtime 中的位置比较靠后,单纯的写死偏移还是风险太高,所以决定采用偏移+校验的方式来保证读到的内存是 ThreadList。Android 10 的 Runtime 结构中,threadlist 再向后增加 4 个指针长度,即是 JavaVMExt,JavaVM 可以在 JNI_OnLoad 时获取到,所以只需要在初始化时对各个版本的偏移进行 JavaVM 的校验,就可大大降低出问题的概率。

获取到 ThreadList 和函数指针后,在栈回溯的前后调用 Suspend 和 Resume 即可完成一次跨线程栈回溯。在 Suspend 和 Resume 之间,仅执行 WalkStack 的操作,堆栈记录和其他操作则放在 Resume 后执行,保证线程被挂起的时间足够短,这样可以确保性能最优。
线程挂起机制经过实践验证可以满足现有需求,实际运行中也未发现无法攻克的问题。另外线程挂起相较于信号机制,可以将大部分操作放到 Resume 后执行,而信号机制记录堆栈等操作需要在回调内做,额外增加耗时,所以最后决定选用线程挂起方案。
调查 ANR 和卡顿问题,大部分时候只对主线程采样抓 trace 即可达到目的,但还是有些问题需要结合子线程的 trace 分析。

Android 提供的采样 trace 最大的问题是每次都需要挂起所有线程,等待全部线程抓栈完成后,才恢复线程,而且这样造成了很多无意义的等待。
为了避免性能损耗问题,采用了分组的方式来设计多线程 trace:主线程单独由一个采样线程抓栈,无其它干扰,子线程分布到一定数量的采样线程中,比如设置五个采样线程,目标子线程会被添加到这些采样线程中,每个采样线程对一定数量的子线程进行采样抓栈,且每个目标子线程通过 SuspendThread 独立挂起,而不是 SuspendAll,互不影响。
很多时候仅有 Method Trace 定位问题依然较为困难,一个函数的耗时可能有很多原因,知道耗时,还要知道为什么耗时,比如在等锁,进行 I/O,Binder 等情况。Java 层的 I/O 和 Binder 通信可以通过函数栈看出来,而锁信息就很难通过函数栈确定了。

在 ANR 日志中,经常可以看到类似的锁信息,能够非常清楚的看出主线程在等待子线程释放锁。如果能拿到这个锁信息并体现到 trace 中,就可以很轻易的知道当前主线程的阻塞原因。

ANR 日志是通过 DumpForSigQuit 输出的,获取 Java 函数栈是通过 Thread::DumpJavaStack 方法,该函数的核心代码是通过 StackDumpVisitor 进行栈回溯。

StackDumpVisitor 继承自 MonitorObjectsStackVisitor,最终也是继承自 StackVisitor,特点是实现了很多有关锁信息的函数。
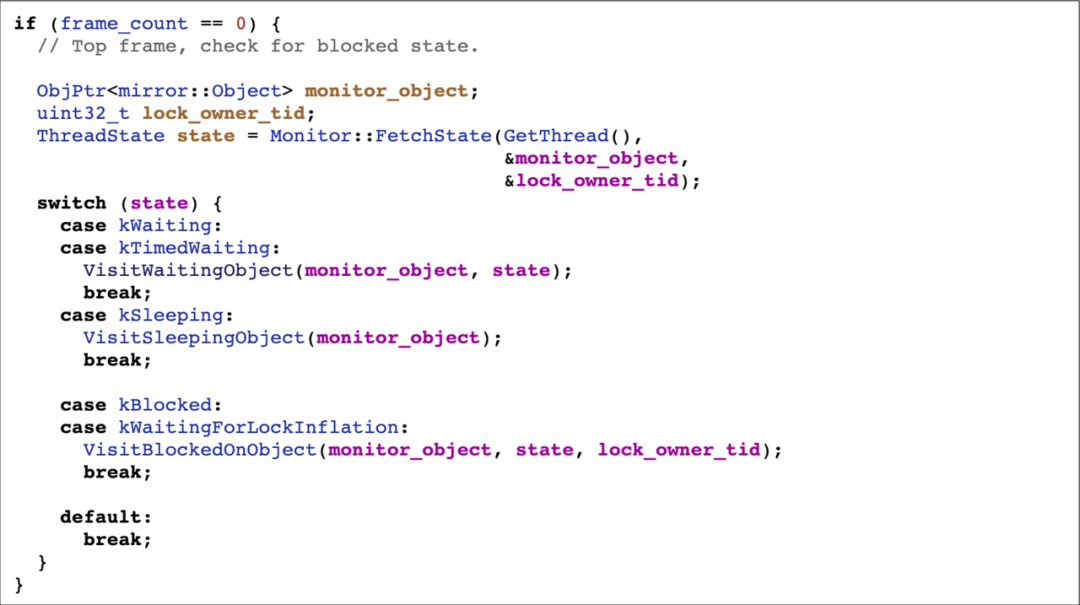
在其实现的 VisitFrame 函数中,会通过 Monitor::FetchState 拿到当前线程的锁信息,还可以拿到当前线程的状态,添加到堆栈中。所以只要在自实现的 VisitFrame 中,通过函数指针直接调用 Monitor::FetchState 函数,就能拿到锁信息。

在栈回溯时调用一次 FetchState,如果当前线程是 block 状态就保存拿到的锁指针和持锁的线程 id,与堆栈一同记录。
完成一次抓栈后,为了得到完整的 trace,需要将本次抓栈的结果与前一次抓栈的结果进行对比计算,得出函数出栈入栈的结果进行记录。方案为从栈底到栈顶遍历新旧两次堆栈,找到不相同的函数,理论上存在四种情况:
若找到不相同的函数,且旧栈是新栈的子集,则表示有新方法入栈,记录新方法 Enter。
若找到不相同的函数,且新栈是旧栈的子集,则表示有旧方法出栈,记录旧方法 Exit。
若找到不相同的函数,且旧栈和新栈存在 diff,则先记录旧方法 Exit,再记录新方法 Enter。
若新栈旧栈各层函数完全一致,则表示记录的函数均还在执行中,本次不用记录。
数据记录采用 ring buffer 的结构,每次入栈或者出栈事件用两个 uintptr_t 表示,记录时间戳与对应事件值。当入栈时,事件值为 ArtMethod 指针地址值;当出栈时,事件值为 0。
为了保证抓栈的高性能,在采样过程中,不进行堆栈的反解,即不进行 ArtMethod 转为 string 的过程,在 dump trace 时统一通过 ArtMethod 的 PrettyMethod 方法进行反解。

Sliver 使用了 Nanoscope 的文件格式记录 trace,易于解析,且能够清晰的表示栈结构。每一行开始的时间戳为纳秒级,表示事件发生的时间;时间戳后跟着对应时刻发生的事件,POP 表示出栈行为,其它表示对应函数的入栈行为。
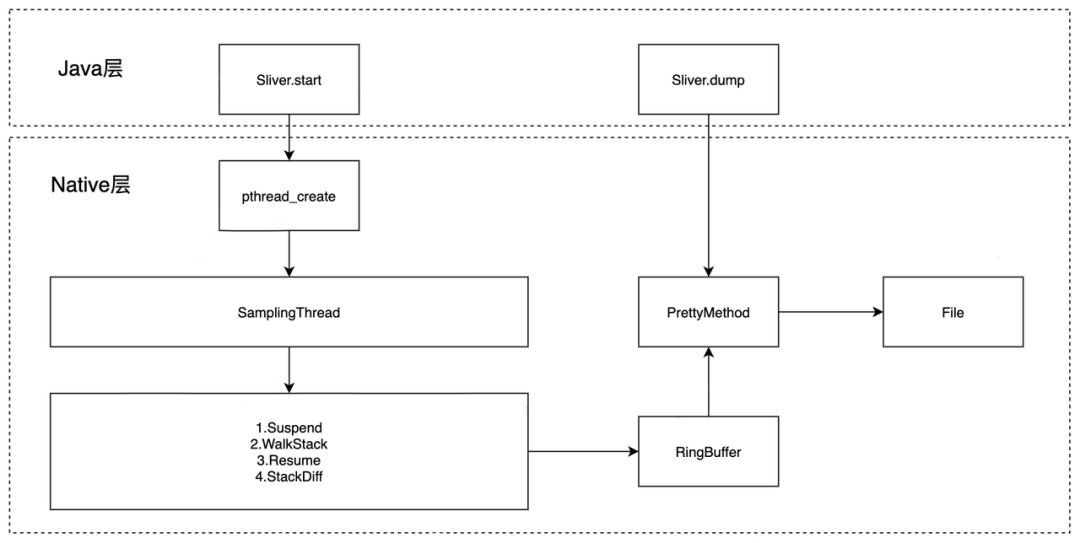
Sliver 在 Java 层提供 start 和 dump 方法,start 函数会传入目标线程,采样间隔等信息,在 native 层通过 pthread_create 创建采样线程 SamplingThread,采样线程循环执行 Suspend->WalkStack->Resume 对目标线程进行抓栈,抓栈完成后对比函数栈得到函数的出入栈信息,写入 RingBuffer 中。在 Java 层调用 dump 时,会读取 RingBuffer,通过 PrettyMethod 方法将 ArtMethod 转为函数名,输出到文件中。

拿到文件后可以通过脚本处理成 perfetto 的格式,在 perfetto trace viewer 上展示。
对单次栈回溯的耗时进行埋点,设置采样间隔为 10ms,接入到西瓜视频,程序运行中取连续的 1w 次耗时数据,在高端机与低端机分别进行分布统计,横轴为单次回溯耗时区间,单位 us,纵轴表示落在对应区间的样本量。

在高端机上,可以看出,约 93%的栈回溯耗时是小于 40us 的,1w 次耗时的平均值为 23.6us。在 10ms 采样间隔的情况下,按单次栈回溯耗时 25us 计算,每秒耗时增加 2.5ms,性能损耗为 2.5‰。
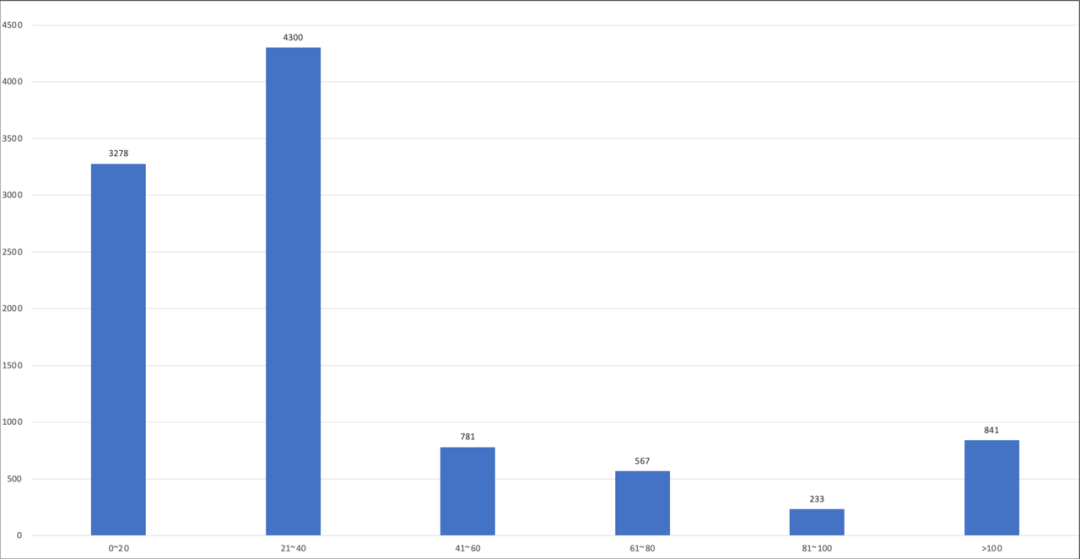
在低端机上,性能会稍差一些,但约 92%的栈回溯耗时是小于 100us 的,1w 次的平均值为 43.2us,在 10ms 采样间隔的情况下,按单次栈回溯耗时 50us 计算,每秒耗时增加 5ms,性能损耗为 5‰。实际使用中,在低端机上可以适当放大采样间隔,比如设置为 20ms 来降低损耗,一定程度的放大采样间隔对调查问题能力并无影响。
当然这样计算出的是理论损耗,受到 Suspend 机制的影响,在 Resume 后线程不会立即运行,而是处在等待调度的状态,所以实际运行中损耗是要大于理论值的,但总体可控制在 1%以内。
Sliver 在线上灰度验证时,出现了 ThreadSuspendTimeout 的崩溃,这类问题在线上经常发生在 GC 时的 SuspendAll 函数,而采样抓栈调用挂起太过频繁,增大了问题出现的概率。
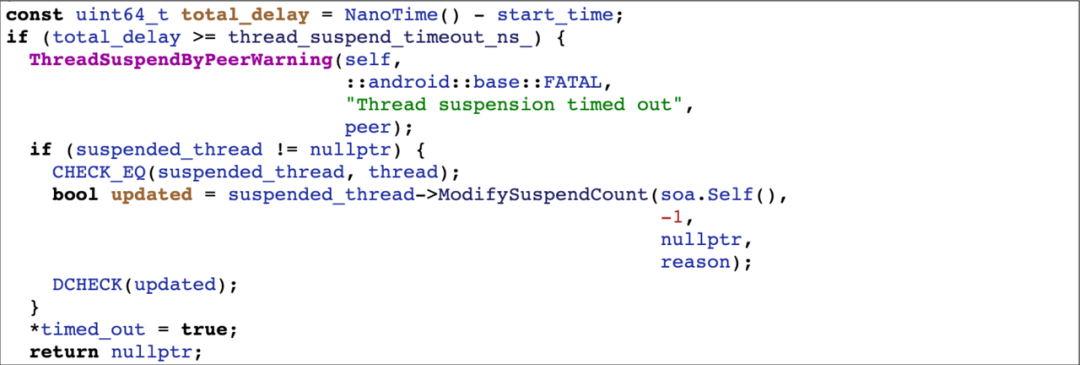
在通过 SuspendThreadByPeer 挂起线程时,会在循环内不断的调用 ModifySuspendCount 尝试挂起目标线程,每次挂起失败会检查一下是否超时,如果超时则会抛出 FATAL 异常。观察这段代码,可以发现 FATAL 后的逻辑是根本不会走到的,因为程序在 ThreadSuspendByPeerWarning 时会 abort 终止掉,那么后面的代码设计的就没有意义,比较奇怪。

通过搜索代码,发现了另外一个函数 SuspendThreadById,该函数的代码与 SuspendThreadByPeer 基本相同,功能同样是挂起线程,只不过是通过线程的 id 来挂起。而有一点不同是当线程挂起超时, ThreadSuspendByIdWarning 的 log 等级由 FATAL 变成了 WARNING,也就是仅打出 log,并不会崩溃,这样后面的逻辑也可以执行到了。在发现了这点后,把支持 SuspendThreadById 的版本均替换成了该函数,这样在发生挂起超时,不会发生崩溃,仅会丢失采样数据。在不支持 SuspendThreadById 的版本上,依然使用 SuspendThreadByPeer,通过采样时 hook 将此处的 log 等级替换成 WARNING 来避免崩溃。
除了这个问题以外,还陆续解决了一些由于自身代码或兼容适配产生的问题,另外由于少部分能力还是使用了风险较高的写死偏移,所以这部分代码统一使用 signal handler + siglongjmp 进行保护,在出错时及时停止采样。
通过在西瓜视频上的迭代,目前的版本已经很少有相关稳定性问题发生了,目前在西瓜视频的内测和灰度阶段全量开启,崩溃率小于十万分之一。
工具实现大部分都使用了符号查找的方案调用系统函数,在 Android 系统的升级中无需庞大的适配工作量,且针对 32 位和 64 位架构也没有过多需要注意的点,维护成本较低。
Sliver 开发完成后,很快就在西瓜视频的卡顿及 ANR 治理中进行了实践。在应用启动后开启 Sliver,在发生卡顿或 ANR 时 dump trace 并随着异常一同上报。
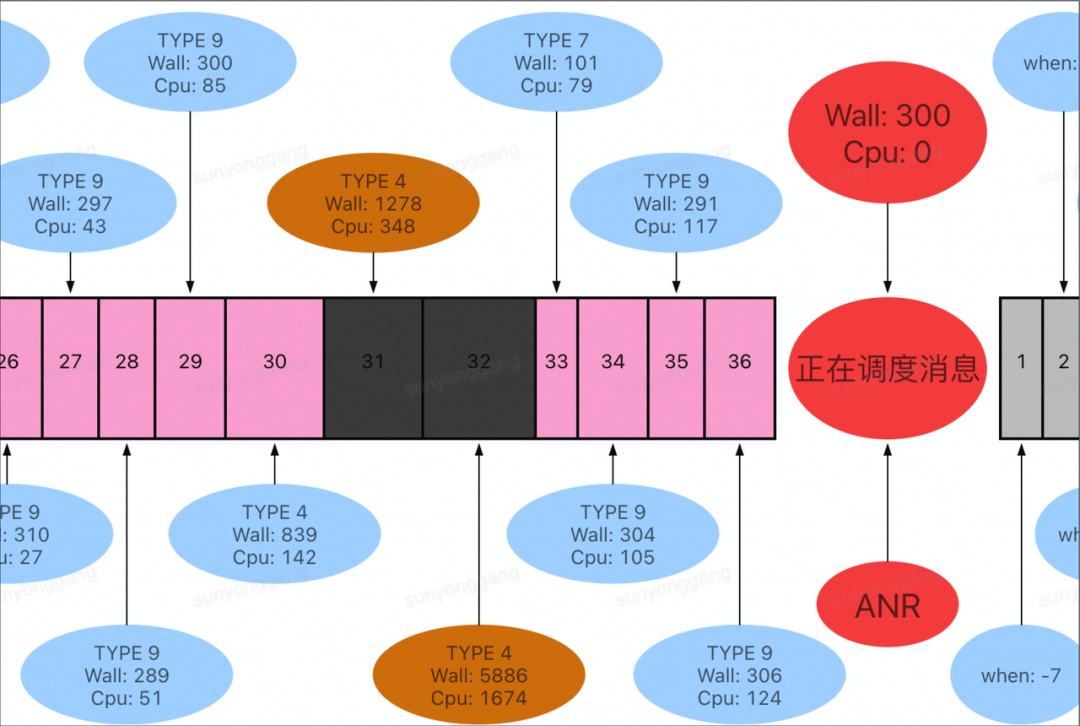
例如这次 ANR 问题,ANR 堆栈体现成 nativePollOnce,但是通过调度消息耗时记录可以看出在感知到 ANR 前有一个耗时 5.8 秒的消息,这个消息应该是造成 ANR 的根本原因,但传统的 ANR 监控手段很难看出这 5.8 秒是在做什么。

而通过随 ANR 上报的 trace 文件可以直观地看出这段时间的函数执行耗时,直接定位到问题原因。
对于卡顿问题,在检测到消息执行超过一定阈值时,dump trace 并直接在端上进行分析,快速找出卡顿点,拿到堆栈后与 trace 文件一同上报。在端上分析时,会根据设置的函数阈值对目标消息的 trace 进行过滤,每一层会留下大于阈值且耗时最长的函数,组成卡顿栈进行上报。经过实践验证,这套方案能够找到卡顿中真正的耗时函数,卡顿聚合准确度大大提升,降低了卡顿的排查成本。
trace 工具的原理虽然不算复杂,但如果想做到极致的性能与稳定性,还是非常困难的。大部分 trace 工具都是在功能或性能或稳定性上做了取舍,Sliver 也是一样,在保证了性能和稳定性的前提下,必然是失去了部分的能力。
Sliver 目前在全线程 trace 的精准度上有一些不足,由于没有使用信号回调的方案,所以必须要单独开启线程进行抓栈,而在抓全线程 trace 的情况下,子线程被分组添加到同一个采样线程进行抓栈,所以在额外创建线程数与子线程 trace 精准度之间存在无法调和的矛盾,只能尽量寻找平衡。我们也在探索如何稳定的切换到信号方案或探索更优秀的方案,优化这部分的能力。
众所周知,ANR 时函数执行变慢并不一定是这些函数在代码层面存在问题,CPU 负载过高,内存资源紧张等情况也会造成性能变差。Sliver 提供了线程状态和锁信息来辅助定位一些特殊情况的问题,但对于 CPU 占用和内存情况并没有体现在 trace 中,所以提供更完善的辅助信息也是后面的目标之一。
Sliver 目前具备了抓 Java Method Trace 的能力,但对于西瓜视频这类 native 代码较多的应用来说,经常会遇到 jni 方法调用耗时过长的情况,这时只依靠 Java 堆栈是无法定位问题的。所以后续会考虑通过增加 native 栈或其他方式来填补这方面的能力空缺。
Android 卡顿和 ANR 的治理是一个长期的事情,需要有完备的调查手段和方法论。业内针对性能问题的排查产出了如 Nanoscope 和 Profilo 这类优秀的工具,正是这些工具的出现,让我们能够开阔思路,吸取优点,拟补不足,在 trace 工具建设上做探索与尝试。
Sliver 目前已经投入到西瓜视频的卡顿与 ANR 治理中,实践中基于此工具开发了一些辅助能力也沉淀了一些方法论,帮助我们解决了很多问题,其能力经过了西瓜视频的长期迭代验证。
Sliver 的开源计划已经提上了日程,我们希望能够将此工具分享给更多的有性能治理需求的应用,同时也可以集思广益,探索出更优秀的方案。
Sliver 的技术方案还有很大的优化空间,后续会在此基础上继续探索,不断完善,努力打造性能更好,功能更全,更加稳定的 trace 工具。
Nanoscope 链接:
https://github.com/uber/nanoscope
Profilo 链接:
https://github.com/facebookincubator/profilo
PerfettoViewer 链接:
https://ui.perfetto.dev/#!/viewer
xDL 链接:
https://github.com/hexhacking/xDL
欢迎加入字节跳动西瓜视频客户端团队,我们专注于西瓜视频 App 的开发和基础技术建设,在客户端架构、性能、稳定性、编译构建、研发工具等方向都有投入。如果你也想一起攻克技术难题,迎接更大的技术挑战,欢迎加入我们!
西瓜视频客户端团队正在热招 Android、iOS 架构师和研发工程师,最 Nice 的工作氛围和成长机会,各种福利各种机遇,在北京、杭州、上海、厦门四地均有职位,欢迎投递简历!联系邮箱:[email protected];邮件标题:姓名-西瓜-工作年限-工作地点。
点个在看杀个 Bug ❤
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK