

百度AI原生云实践: 基于容器云打造 AI 开发基础设施
source link: https://my.oschina.net/u/4657223/blog/5163936
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

导读:众所周知,AI的发展离不开三大要素:数据、算法和算力。
算法、算力、数据三者相互影响,组成了AI技术发展突破的基础,也推动了人工智能在产业场景下的应用。
同时,不同场景与应用,对底层资源提出了更高的要求,应用的多元化需要更完善的硬件与软件系统来提升开发效率,因此基础设施也在一定程度上制约着人工智能的发展。
如何构建包括硬件、平台、框架在内的AI开发基础设施,实现降本增效,满足当前人工智能落地应用的需求?
百度交出了一份名为『AI原生云』的答卷。

本文根据百度技术沙龙云原生专场贺龙华讲师的分享内容整理而成,主要包括三个部分: 1.AI 开发领域现状 2.打造基于容器云的企业 AI 开发基础设施 3.常见落地场景(开发、训练、推理)分享
1. AI 开发领域现状
目前,行业应用进入全面 AI 原生化阶段,智能家居、智能金融,自动驾驶、智慧医疗、智能零售、智能制造,工业的智能制造等行业,都在广泛应用深度学习和机器学习技术做AI场景的应用。
而在 AI 开发工程领域,挑战和趋势主要有以下三点:
-
更大的数据和模型。数据越来越多,比如我们经常接触到的百度的搜索数据,工业互联网涉及的机器数据等,这些数据都在呈现指数级增长;模型越来越大,自2018年谷歌提出 BERT 模型以来,以BERT、GPT等为代表的模型越来越往「大」这一方向发展,短短3年时间,模型参数已经从最初3亿,扩张到万亿规模。
-
有了大规模的数据之后需要更大规模的训练,如何实现更快的训练便成了一个亟待解决的问题。
-
企业在应用AI场景过程中投入的成本越来越高。
对应的,整个行业对 AI 开发基础设施的诉求也有三点:
-
高性能,数据模型越来越大,对性能要求越来越高。
-
Serverless 化,传统的算法工程师很少会用到基础设施平台,他们对模型训练和 AI 标注等方面的内容比较陌生,比较希望可以用 Serverless 化的方式来简单的完成 AI 的推理和训练。
-
高利用率,客户购买了几百张或者几千张卡,如何把这些卡的利用率提高?
针对以上三个挑战,百度提出了相应的解决方案,来解决如何快速、低成本的训练大规模数据与模型的问题。
2. 打造基于容器云的企业 AI 开发基础设施
2.1 百度 AI 异构计算平台
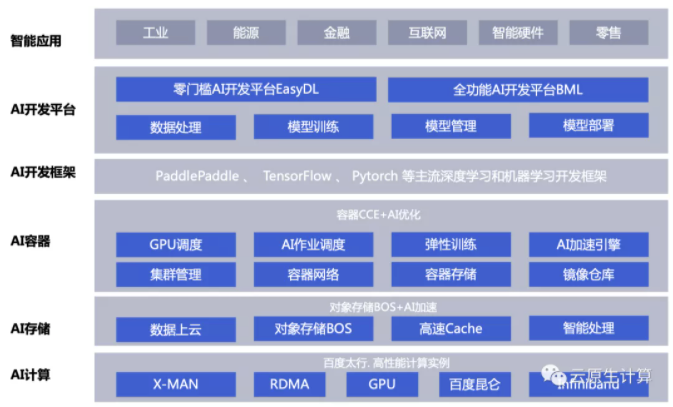
如上图所示,最底层是 AI 计算,百度提供特殊的机型支持大规模的训练和推理,比如自研的 X-MAN 是第一款4路 AI 服务器,支持8张 Nvidia A100 卡全互联。网络上主机之间通过 RDMA 网络实现高速通信,硬件加速卡方面,借助自研的昆仑卡进行硬件加速。
AI 存储层,训练任务需要高吞吐、低延迟读取数据;针对这个场景,百度自研了并行文件存储,搭载裸金属服务器、基于全闪存 SSD 介质,兼容以太网和 IB 网络;依靠并行架构,用户 I/O 在客户端和存储节点间完全并行访问,支持百万级 IOPS。
在 AI 容器方面,百度做了很多加强。例如 GPU 的精细化调度、AI 作业的优先级调度、AI开发框架层优化。这些再下面会详细介绍。
AI PaaS 平台,百度会提供包括数据标注、模型推理,数据的管理等能力;最上层就是AI具体落地的一些行业,包括工业、能源、金融等。
2.2 当 GPU 遇上容器
为什么 GPU+容器 能在上行业内大放异彩,而不是 GPU+虚机 的组合模式?原因很简单,在过去的几年里,使用容器来大规模部署数据中心应用程序的数量急剧增加。容器具有其特有的优势:封装了应用程序的依赖项,以提供可重复和可靠的应用程序和服务执行,而无需整个虚拟机的开销。
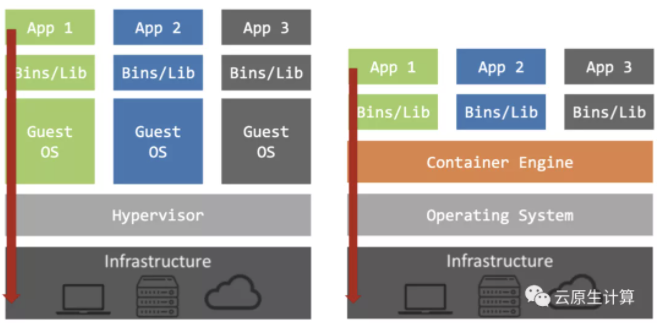
具体而言,首先,上图可以看到容器和虚机最大的区别没有一个 Hypervisor 层去隔离,我们可以在很多裸金属服务器上直接用容器挂载 GPU 设备进来直接用,这个效率是零损耗的。传统的虚机是虚拟化的状态,有一些损耗,而且弹性速度无法与容器比拟,并且无法共享 GPU 设备。
第二,容器是共享宿主机的内核以及关键库,比如如 cuDNN、硬件驱动库等。容器是利用操作系统的资源隔离特性而实现的轻量级虚拟化技术。同时把资源消耗降低到最小,甚至是没有消耗(因为它是同一个内核的)。
第三,神经网络中不同版本的差异性较大,容器为深度学习的应用提供了环境一致性。
2.3 百度 AI 容器服务全景图
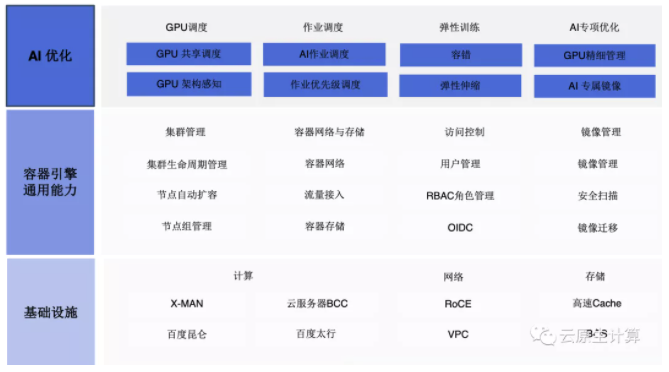
基础设施层的计算方面提供上文提到的百度自研的昆仑芯片,自研的服务器 X-Man服务器; 网络方面,包含 RoCE 网络、VPC 网络、RDMA 高性能网络等;存储方面也有高速 Cache 的方案。
再重点看一下 AI 优化层,GPU 调度方面,我们的方案能够支持从容器的场景下采集到GPU 的型号、算力、显存、NVLink等信息,当然还有 GPU 所在机器的网络位置信息。为什么需要感知 NVLink?NV-Link 特性使得 GPU 能够直接访问另一块 GPU 的内存数据,而不需要过 PCIe 设备。在训练场景,这是非常重要的。
AI 作业的 调度方面 ,我们 引入了 Volcano 调度框架进行批量 job 的调度; AI 加 速引擎百度在这块优化的比较多一些,比如 NCCL 通信库,百度在这之上做了一些优化,加速硬件和软件的通信。
AI开发框架层,支持主流的深度学习框架,包括PaddlePaddle、TensorFlow、Pytorch等,另外,在 Paddle 上面百度针对推理场景做了深度的算子优化。
GPU 虚拟化方面,能够支持 GPU 的共享技术以及 GPU 算力隔离, 还有编解码,因为 GPU 常见用于视频的编解码,百度的 cGPU 方案同样也可以做到隔离;
最后是AI的专项优化,GPU 精细管理和 AI 专属镜像,针对百度内部有常见的的推理,比如广告点击率,会用专门镜像做优化,使它的效率达到最高。
2.4 百度 AI 容器特性
第一, 软件定义GPU ,我们经常听见软件定义网络,软件定义存储。AI的场景下,软件可以定义GPU,可以定义GPU的算力,百度把GPU的资源分为二分之一或者四分之一粒度来管理,把GPU池化甚至云化,借助 remote CUDA 可以支持你通过RDMA网络的模式把数据发送到远端 GPU Server 进行计算。
第二, AI 容器调度 ,百度支持Gang、Spread、Binpack调度策略,支持 NVLink 等 GPU 架构感知调度。
第三, 加速引擎 ,支持通信库的优化还有多业务场景,目前在百度内部实践比较多,比如推荐,Feed流广告、NLP自然语言识别等。
2.5 百度自研容器化 GPU 共享技术方案
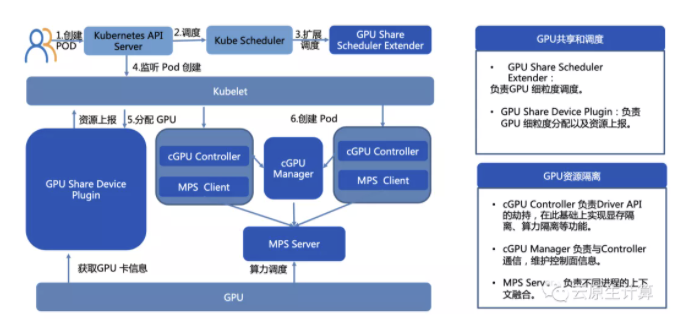
详细的流程可以理解为:用户创建一个 Pod,通过调用Kubernetes API Server,进行调度/扩展调度,比如 GPU 特殊的扩展调度器发给 Kubelet,Kuberlet 创建 GPU 的容器的时候挂载一个虚拟 GPU 卡,因此在容器内部看到的卡是二分之一卡或者四分之一卡,GPU 在使用的过程中会调 MPS 多进程服务,由这个多进程服务进行算力的调度和算力的隔离。
以上就是目前绝大部分企业和行业在用的技术方案,虽然有的企业可能做不到显存的共享,有的企业做不到算力的隔离,但是用 GPU 的方式都是用这个模式来实现:扩展的调度器在 K8S上,扩展的 Device Plugin 再到 GPU 硬件。
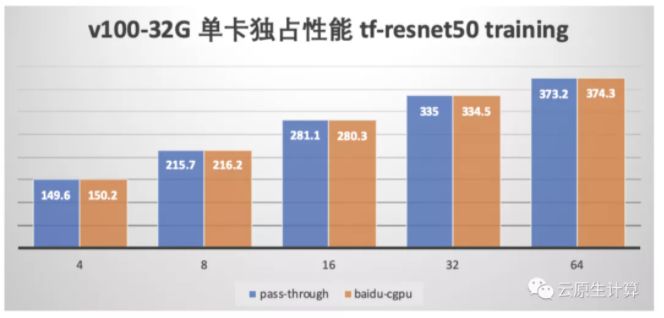
通过实践可以发现,使用 resnet50 验证训练场景的不同 batchsize 下, 百度自研共享方案与 GPU 直通方案对比,性能几乎无损。
总体来说,百度在 AI 容器服务方面提供的价值表现在以下四个方面:
第一, 高利用率 ,很多企业 GPU 成本越来越高,容器作为 AI 的 IaaS 会着力提高GPU 的利用率,比如 GPU 的云化,GPU 的池化,还有作业的优先级抢占级调度,GPU 的分层复用都是为了提高利用率。
第二, 灵活的配置 ,不同业务使用 GPU 不一样,英伟达的T4卡多用于推理和编解码,英伟达 V100 卡多用于训练,在调度这一层灵活配置,按需选择 GPU 即可。
第三, 规模化落地 ,在百度内外部都有相关的落地经验,尤其在百度外部,未来会大规模推广。
第四, AI 多场景的应用 ,在 AI 开发、训练和推理等场景均有应用。
3. 常见落地场景
3.1 AI 训练场景
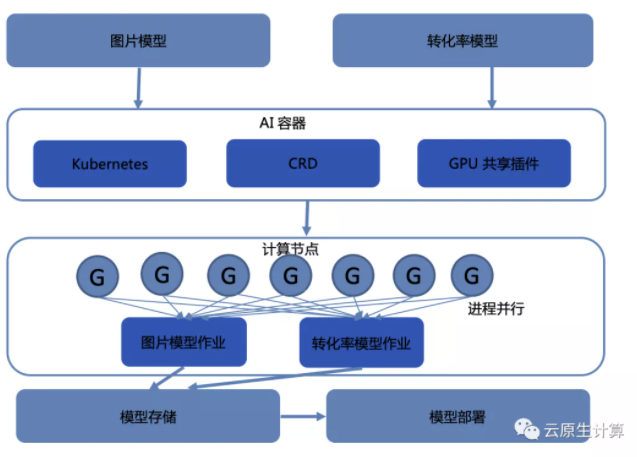
百度内部的广告推荐场景有许多轻量级的模型,比如我们在刷Feed流或者视频流的过程中都会涉及到训练,拿到用户的特征值后进行训练,图片模型、转化率模型等都是通过 Kubernetes 进行介入,到计算节点进行作业,生成模型进行模型部署。
这种场景的特性是模型结构比较简单,对资源的要求比较低,不需要大规格的GPU卡进行训练,内存占用比较小,GPU 资源利用率一般不超过50%,通过优化之后,可以实现并行任务执行总耗时缩减40%,推荐场景下,GPU 资源利用率可提升50%。
3.2 AI 推理场景
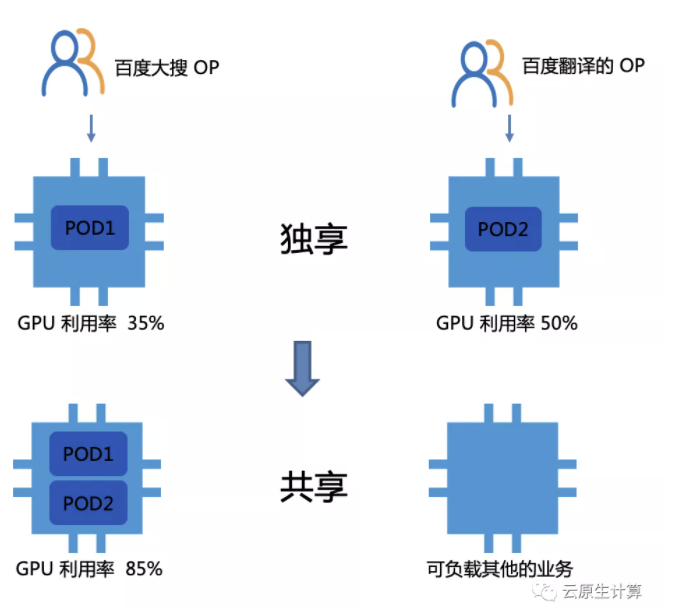
训练的目的就是为了推理,百度有些商业产品需要预估收入是多少,广告点击率是多少,这些都是典型推理场景,这类业务的特点是对延迟敏感(ms级)并且算力要求相对训练场景较低,目前我们在大商业落地百度的网盟,落地了点击率的预估,利用我们的容器和 AI 的解决方案,覆盖了千张级别的P4/T4卡,利用率提升了80%。
3.3 AI 开发场景
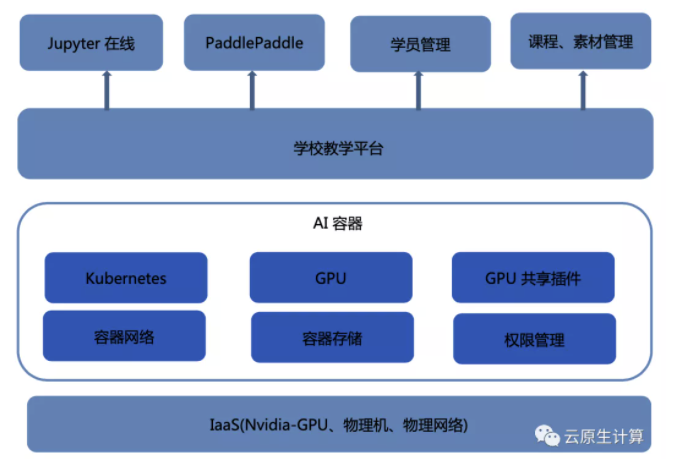
外部也有一些典型场景,比如现在人工智能火热发展,很多高校开设了AI相关课程,但是 GPU 卡价格昂贵,如果一个班平常三四十人上课,学校通常很难购买三四十张 GPU 卡来支持学生做实验,实现一卡多用就变得十分迫切,在这个场景利用百度的 GPU 共享技术,可以做到多个同学做AI作业的时候用同一张卡,提高并发率,实现资源成本的节约。
获取本次沙龙所有 PDF,请关注【云原生计算】公众号并回复 724
- End -
重磅!云原生计算交流群成立
扫码添加小助手即可申请加入,一定要备注:名字-公司/学校-地区,根据格式备注,才能通过且邀请进群。
了解更多微服务、云原生技术的相关信息,请关注我们的微信公众号【云原生计算】!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK